Recognition: 2 theorem links
· Lean TheoremLost in the Hype: Revealing and Dissecting the Performance Degradation of Medical Multimodal Large Language Models in Image Classification
Pith reviewed 2026-05-10 18:07 UTC · model grok-4.3
The pith
Medical multimodal large language models underperform traditional deep learning models in medical image classification due to specific failures in their processing pipeline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
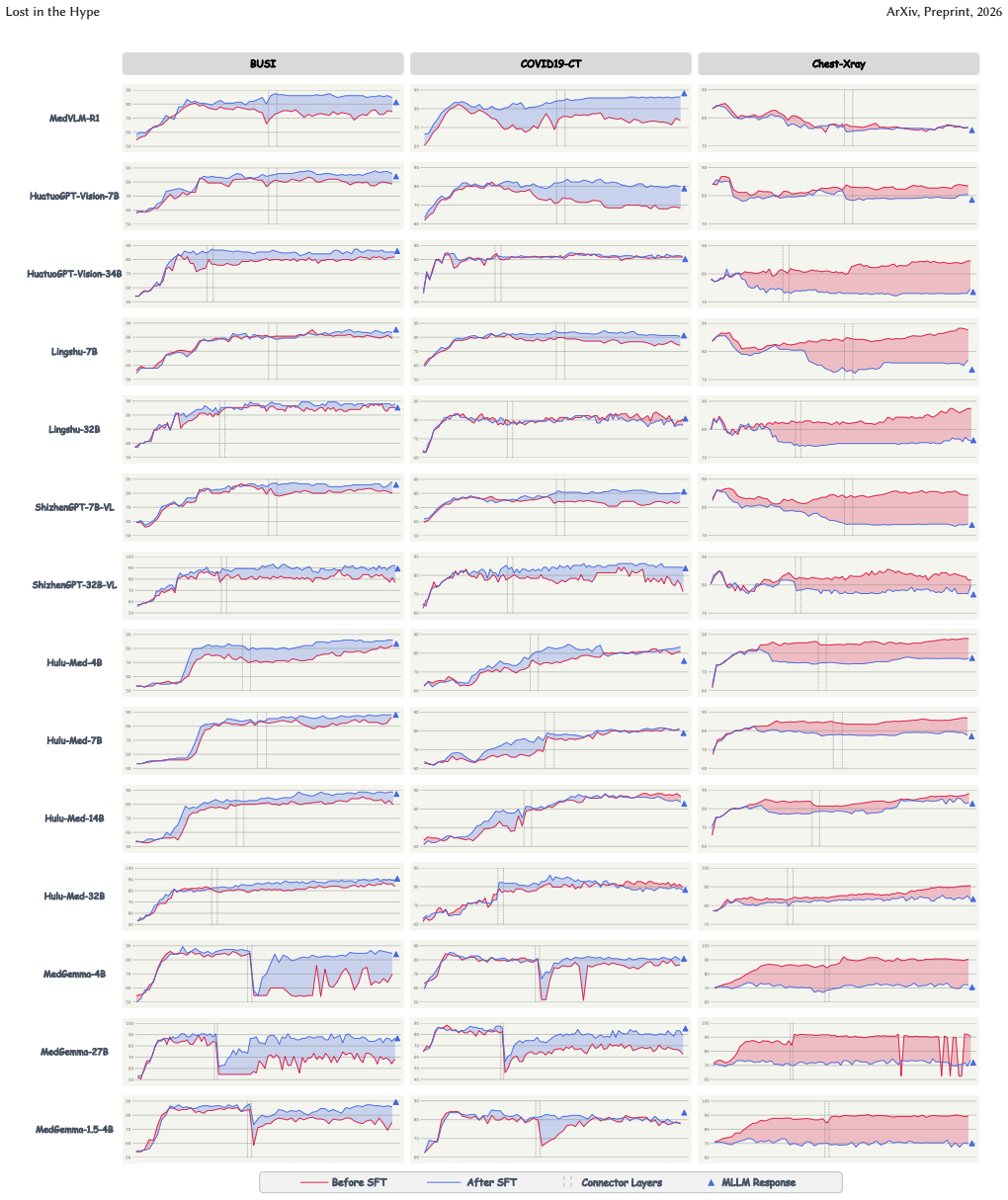
By tracking visual features module-by-module and layer-by-layer in 14 medical MLLMs across three datasets, the work reveals four distinct failure modes that degrade classification performance: quality limitation in visual representation, fidelity loss in connector projection, comprehension deficit in LLM reasoning, and misalignment of semantic mapping.
What carries the argument
Feature probing, which visualizes and quantifies how classification signals evolve or distort through the vision encoder, connector, and LLM components.
If this is right
- Improvements to medical MLLMs should prioritize better visual encoders to capture higher quality representations.
- Connector modules between vision and language parts must be redesigned to reduce information loss during projection.
- LLM components need specialized training or fine-tuning to better comprehend and reason about medical image features for classification.
- Semantic mapping techniques should align image features more accurately with textual class labels to avoid mismatches.
Where Pith is reading between the lines
- These bottlenecks likely contribute to similar performance issues in other medical multimodal tasks such as report generation or visual question answering.
- Developers may achieve better clinical results by hybridizing MLLMs with traditional classifiers until the identified issues are resolved.
- Quantitative health scores for feature evolution could serve as a new evaluation metric for future MLLM designs.
Load-bearing premise
That the feature probing technique can isolate the sources of performance loss without the probing process itself distorting the model's normal behavior or introducing new artifacts.
What would settle it
Compare classification accuracy of an MLLM against a traditional CNN on the same medical datasets while measuring if the probed feature qualities match the observed accuracy differences.
Figures



read the original abstract
The rise of multimodal large language models (MLLMs) has sparked an unprecedented wave of applications in the field of medical imaging analysis. However, as one of the earliest and most fundamental tasks integrated into this paradigm, medical image classification reveals a sobering reality: state-of-the-art medical MLLMs consistently underperform compared to traditional deep learning models, despite their overwhelming advantages in pre-training data and model parameters. This paradox prompts a critical rethinking: where exactly does the performance degradation originate? In this paper, we conduct extensive experiments on 14 open-source medical MLLMs across three representative image classification datasets. Moving beyond superficial performance benchmarking, we employ feature probing to track the information flow of visual features module-by-module and layer-by-layer throughout the entire MLLM pipeline, enabling explicit visualization of where and how classification signals are distorted, diluted, or overridden. As the first attempt to dissect classification performance degradation in medical MLLMs, our findings reveal four failure modes: 1) quality limitation in visual representation, 2) fidelity loss in connector projection, 3) comprehension deficit in LLM reasoning, and 4) misalignment of semantic mapping. Meanwhile, we introduce quantitative scores that characterize the healthiness of feature evolution, enabling principled comparisons across diverse MLLMs and datasets. Furthermore, we provide insightful discussions centered on the critical barriers that prevent current medical MLLMs from fulfilling their promised clinical potential. We hope that our work provokes rethinking within the community-highlighting that the road from high expectations to clinically deployable MLLMs remains long and winding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that state-of-the-art medical MLLMs underperform traditional deep learning models on image classification despite larger scale and pre-training data. Using feature probing to track visual features module-by-module and layer-by-layer across 14 open-source medical MLLMs and three representative datasets, the authors identify four failure modes: quality limitation in visual representation, fidelity loss in connector projection, comprehension deficit in LLM reasoning, and misalignment of semantic mapping. They introduce quantitative scores characterizing the healthiness of feature evolution and discuss barriers to clinical use.
Significance. If the results hold, the work is significant for providing the first systematic module-by-module dissection of where classification signals degrade in medical MLLMs rather than relying on end-to-end benchmarking alone. The scale (14 models, 3 datasets) and the new quantitative feature-health scores enable cross-model comparisons and could inform targeted architectural fixes. The empirical focus on information flow through vision encoder, connector, and LLM stages directly addresses a practical gap between MLLM hype and deployable medical performance.
major comments (2)
- The central attribution of degradation to the four named failure modes depends on feature probing faithfully revealing intrinsic distortions without itself altering activations or forward dynamics. The manuscript provides no validation (e.g., ablation of probe impact on end-to-end accuracy, comparison of probed vs. unprobed feature statistics, or gradient-flow checks) that the probing process is measurement-neutral. Without such controls, observed distortions could be probing artifacts rather than pipeline-intrinsic, weakening the causal claims for each failure mode.
- Experiments section: details on baseline fairness, statistical rigor (number of runs, significance testing), and exact probing implementation (probe architecture, training protocol, layer selection) are insufficient to confirm that the reported performance gaps and feature-health scores are robust and not sensitive to implementation choices.
minor comments (2)
- Abstract: the phrase 'healthiness of feature evolution' is used without a concise definition or formula; adding one sentence would improve immediate readability.
- Figure captions and axis labels for the module-by-module visualizations should explicitly state the probe type and normalization used so readers can interpret the distortion plots without returning to the methods text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive evaluation of the work's significance. We address each major comment point by point below, providing the strongest honest defense of the manuscript while incorporating revisions where the concerns are valid and require additional evidence or detail.
read point-by-point responses
-
Referee: The central attribution of degradation to the four named failure modes depends on feature probing faithfully revealing intrinsic distortions without itself altering activations or forward dynamics. The manuscript provides no validation (e.g., ablation of probe impact on end-to-end accuracy, comparison of probed vs. unprobed feature statistics, or gradient-flow checks) that the probing process is measurement-neutral. Without such controls, observed distortions could be probing artifacts rather than pipeline-intrinsic, weakening the causal claims for each failure mode.
Authors: We agree that explicit validation of probing neutrality is necessary to support causal claims about the four failure modes. In the revised manuscript we add a dedicated validation subsection with three controls: (1) end-to-end accuracy ablation comparing probed versus unprobed forward passes on all 14 models and 3 datasets, (2) quantitative comparison of feature statistics (mean, variance, and distribution divergence) between probed and original activations at each stage, and (3) gradient-flow checks confirming that probe insertion does not materially alter back-propagation or activation magnitudes. These results demonstrate that probing functions as a non-invasive readout, thereby preserving the attribution of observed distortions to the vision encoder, connector, and LLM stages. revision: yes
-
Referee: Experiments section: details on baseline fairness, statistical rigor (number of runs, significance testing), and exact probing implementation (probe architecture, training protocol, layer selection) are insufficient to confirm that the reported performance gaps and feature-health scores are robust and not sensitive to implementation choices.
Authors: We concur that greater experimental transparency is required for reproducibility and robustness assessment. The revised Experiments section now includes: (1) explicit justification of baseline fairness, including parameter-scale matching and pre-training regime comparisons; (2) statistical protocol specifying five independent runs per configuration with different random seeds, reporting of mean ± standard deviation, and paired t-test p-values for all performance gaps; and (3) complete probing implementation details—probe architecture (two-layer MLP with ReLU), training protocol (Adam optimizer, learning rate 1e-3, 20 epochs, early stopping), and layer selection (outputs of every major module plus uniformly sampled intermediate layers). These additions allow readers to evaluate sensitivity to implementation choices. revision: yes
Circularity Check
No circularity: purely empirical analysis with direct observations
full rationale
The paper conducts experimental benchmarking and feature probing across 14 MLLMs on three datasets to identify performance degradation modes. No derivations, equations, fitted parameters renamed as predictions, or self-referential definitions appear in the provided text. Claims rest on module-by-module tracking of visual features via probing, with quantitative healthiness scores derived from observed data rather than by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The work is self-contained against external benchmarks (traditional DL models) and does not reduce any central result to its own inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we employ feature probing to track the information flow of visual features module-by-module and layer-by-layer... four failure modes: 1) quality limitation in visual representation, 2) fidelity loss in connector projection...
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
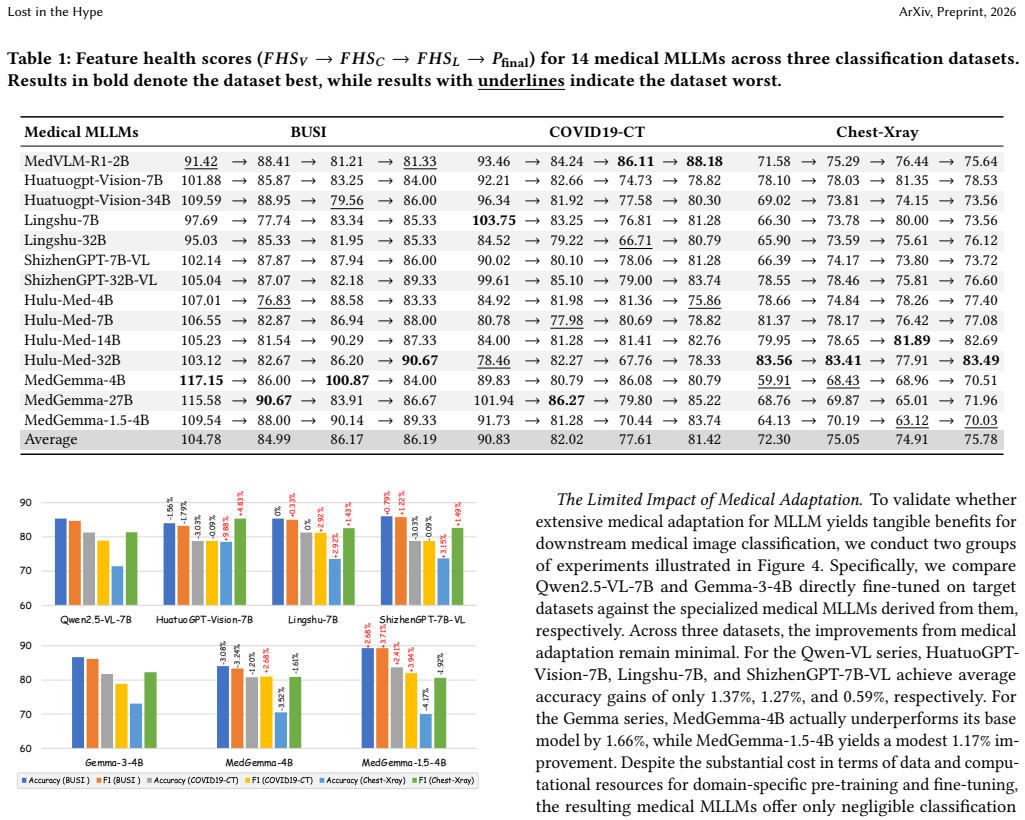
we introduce quantitative scores that characterize the healthiness of feature evolution (FHS_M = P(end) · (1+GF_M) · VP_M)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Walid Al-Dhabyani, Mohammed Gomaa, Hussien Khaled, and Aly Fahmy. 2020. Dataset of breast ultrasound images.Data in brief28 (2020), 104863
2020
-
[2]
Guillaume Alain and Yoshua Bengio. 2016. Understanding intermediate layers using linear classifier probes.arXiv preprint arXiv:1610.01644(2016)
work page Pith review arXiv 2016
-
[3]
Chun-Fu Richard Chen, Quanfu Fan, and Rameswar Panda. 2021. Crossvit: Cross- attention multi-scale vision transformer for image classification. InProceedings of the IEEE/CVF international conference on computer vision. 357–366
2021
- [4]
-
[5]
Junying Chen, Chi Gui, Ruyi Ouyang, Anningzhe Gao, Shunian Chen, Guim- ing Hardy Chen, Xidong Wang, Zhenyang Cai, Ke Ji, Xiang Wan, et al . 2024. Towards injecting medical visual knowledge into multimodal llms at scale. InPro- ceedings of the 2024 conference on empirical methods in natural language processing. 7346–7370
2024
-
[6]
Jierun Chen, Shiu-hong Kao, Hao He, Weipeng Zhuo, Song Wen, Chul-Ho Lee, and S-H Gary Chan. 2023. Run, don’t walk: chasing higher FLOPS for faster neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 12021–12031
2023
-
[7]
Wei-Lin Chiang, Zhuohan Li, Ziqing Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. 2023. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna. lmsys. org (accessed 14 April 2023)2, 3 (2023), 6
2023
-
[8]
Alexis Conneau, German Kruszewski, Guillaume Lample, Loïc Barrault, and Marco Baroni. 2018. What you can cram into a single $&!#* vector: Probing sentence embeddings for linguistic properties. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2126–2136
2018
-
[9]
Yuxin Fang, Wen Wang, Binhui Xie, Quan Sun, Ledell Wu, Xinggang Wang, Tiejun Huang, Xinlong Wang, and Yue Cao. 2023. Eva: Exploring the limits of masked visual representation learning at scale. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 19358–19369. Lost in the Hype ArXiv, Preprint, 2026
2023
-
[10]
George Fisher. 2025. Vision-Language Foundation Models Do Not Transfer to Medical Imaging Classification: A Negative Result on Chest X-ray Diagnosis. medRxiv(2025), 2025–12
2025
- [11]
- [12]
-
[13]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition. 770–778
2016
-
[14]
John Hewitt and Percy Liang. 2019. Designing and interpreting probes with control tasks. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (emnlp-ijcnlp). 2733–2743
2019
-
[15]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. LoRA: Low-Rank Adaptation of Large Language Models.arXiv preprint arXiv:2106.09685(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Xiangzuo Huo, Gang Sun, Shengwei Tian, Yan Wang, Long Yu, Jun Long, Wen- dong Zhang, and Aolun Li. 2024. HiFuse: Hierarchical multi-scale feature fusion network for medical image classification.Biomedical signal processing and control 87 (2024), 105534
2024
-
[17]
Daniel P Jeong, Saurabh Garg, Zachary Chase Lipton, and Michael Oberst. 2024. Medical adaptation of large language and vision-language models: Are we making progress?. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 12143–12170
2024
- [18]
-
[19]
Daniel S Kermany, Michael Goldbaum, Wenjia Cai, Carolina CS Valentim, Huiying Liang, Sally L Baxter, Alex McKeown, Ge Yang, Xiaokang Wu, Fangbing Yan, et al. 2018. Identifying medical diagnoses and treatable diseases by image-based deep learning.cell172, 5 (2018), 1122–1131
2018
-
[20]
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. 2023. Llava-med: Train- ing a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems36 (2023), 28541–28564
2023
-
[21]
Jiachen Li, Ali Hassani, Steven Walton, and Humphrey Shi. 2023. Convmlp: Hier- archical convolutional mlps for vision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6307–6316
2023
-
[22]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning. PMLR, 19730–19742
2023
-
[23]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in neural information processing systems36 (2023), 34892–34916
2023
-
[24]
Ming Y Lu, Bowen Chen, Drew FK Williamson, Richard J Chen, Ivy Liang, Tong Ding, Guillaume Jaume, Igor Odintsov, Long Phi Le, Georg Gerber, et al. 2024. A visual-language foundation model for computational pathology.Nature medicine 30, 3 (2024), 863–874
2024
-
[25]
Yoojin Nam, Dong Yeong Kim, Sunggu Kyung, Jinyoung Seo, Jeong Min Song, Jimin Kwon, Jihyun Kim, Wooyoung Jo, Hyungbin Park, Jimin Sung, et al. 2025. Multimodal large language models in medical imaging: current state and future directions.Korean Journal of Radiology26, 10 (2025), 900
2025
-
[26]
Jiazhen Pan, Che Liu, Junde Wu, Fenglin Liu, Jiayuan Zhu, Hongwei Bran Li, Chen Chen, Cheng Ouyang, and Daniel Rueckert. 2025. Medvlm-r1: Incentivizing medical reasoning capability of vision-language models (vlms) via reinforcement learning. InInternational Conference on Medical Image Computing and Computer- Assisted Intervention. Springer, 337–347
2025
-
[27]
Maithra Raghu, Thomas Unterthiner, Simon Kornblith, Chiyuan Zhang, and Alexey Dosovitskiy. 2021. Do vision transformers see like convolutional neural networks?Advances in neural information processing systems34 (2021), 12116– 12128
2021
- [28]
-
[29]
Zitong Ren, Shiwei Liu, Liejun Wang, and Zhiqing Guo. 2025. Conv-SdMLPMixer: A hybrid medical image classification network based on multi-branch CNN and multi-scale multi-dimensional MLP.Information Fusion118 (2025), 102937
2025
-
[30]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. 2025. Medgemma technical report.arXiv preprint arXiv:2507.05201(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Pooja Singh, Siddhant Ujjain, Tapan Kumar Gandhi, and Sandeep Kumar. 2025. CrossMed: A Multimodal Cross-Task Benchmark for Compositional Generaliza- tion in Medical Imaging. In2025 IEEE EMBS International Conference on Biomedical and Health Informatics (BHI). IEEE, 1–7
2025
-
[32]
Mingxing Tan and Quoc Le. 2019. Efficientnet: Rethinking model scaling for convolutional neural networks. InInternational conference on machine learning. PMLR, 6105–6114
2019
-
[33]
Omkar Chakradhar Thawakar, Abdelrahman M Shaker, Sahal Shaji Mullappilly, Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan, Jorma Laaksonen, and Fahad Khan. 2024. Xraygpt: Chest radiographs summarization using large medical vision-language models. InProceedings of the 23rd workshop on biomedical natural language processing. 440–448
2024
-
[34]
Ilya O Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, et al. 2021. Mlp-mixer: An all-mlp architecture for vision.Advances in neural information processing systems34 (2021), 24261–24272
2021
-
[35]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Betty Van Aken, Benjamin Winter, Alexander Löser, and Felix A Gers. 2019. How does bert answer questions? a layer-wise analysis of transformer representa- tions. InProceedings of the 28th ACM international conference on information and knowledge management. 1823–1832
2019
-
[37]
Gaurav Verma, Minje Choi, Kartik Sharma, Jamelle Watson-Daniels, Sejoon Oh, and Srijan Kumar. 2024. Cross-modal projection in multimodal llms doesn’t really project visual attributes to textual space. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 657–664
2024
- [38]
-
[39]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. 2024. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Tianshi Wang, Fengling Li, Lei Zhu, Jingjing Li, Zheng Zhang, and Heng Tao Shen. 2025. Cross-modal retrieval: a systematic review of methods and future directions.Proc. IEEE112, 11 (2025), 1716–1754
2025
-
[41]
Yinuo Wang, Kai Chen, Yue Zeng, Cai Meng, Chao Pan, and Zhouping Tang. 2025. Zero-Shot Multi-modal Large Language Models vs Supervised Deep Learning: A Comparative Analysis on CT-Based Intracranial Hemorrhage Subtyping.Brain Hemorrhages(2025)
2025
-
[42]
Zifeng Wang, Zhenbang Wu, Dinesh Agarwal, and Jimeng Sun. 2022. Medclip: Contrastive learning from unpaired medical images and text. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 3876–3887
2022
-
[43]
Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Hui Hui, Yanfeng Wang, and Weidi Xie
-
[44]
Towards generalist foundation model for radiology by leveraging web-scale 2d&3d medical data.Nature Communications16, 1 (2025), 7866
2025
-
[45]
Weiwen Xu, Hou Pong Chan, Long Li, Mahani Aljunied, Ruifeng Yuan, Jianyu Wang, Chenghao Xiao, Guizhen Chen, Chaoqun Liu, Zhaodonghui Li, et al
- [46]
- [47]
- [48]
-
[49]
Tan Yu, Xu Li, Yunfeng Cai, Mingming Sun, and Ping Li. 2022. S2-mlp: Spatial- shift mlp architecture for vision. InProceedings of the IEEE/CVF winter conference on applications of computer vision. 297–306
2022
-
[50]
Weihao Yu, Pan Zhou, Shuicheng Yan, and Xinchao Wang. 2024. Inceptionnext: When inception meets convnext. InProceedings of the IEEE/cvf conference on computer vision and pattern recognition. 5672–5683
2024
-
[51]
Yuhui Zhang, Alyssa Unell, Xiaohan Wang, Dhruba Ghosh, Yuchang Su, Ludwig Schmidt, and Serena Yeung-Levy. 2024. Why are visually-grounded language models bad at image classification?Advances in Neural Information Processing Systems37 (2024), 51727–51753
2024
-
[52]
Xun Zhu, Ying Hu, Fanbin Mo, Miao Li, and Ji Wu. 2024. Uni-med: a unified medical generalist foundation model for multi-task learning via connector-MoE. Advances in Neural Information Processing Systems37 (2024), 81225–81256
2024
-
[53]
Xun Zhu, Fanbin Mo, Zheng Zhang, Jiaxi Wang, Yiming Shi, Ming Wu, Chuang Zhang, Miao Li, and Ji Wu. 2025. Enhancing Multi-task Learning Capability of Medical Generalist Foundation Model via Image-centric Multi-annotation Data. InProceedings of the 33rd ACM International Conference on Multimedia. 2693–2702
2025
-
[54]
Four Diagnostic Methods
Xun Zhu, Zheng Zhang, Xi Chen, Yiming Shi, Miao Li, and Ji Wu. 2025. Connector- S: a survey of connectors in multi-modal large language models. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence. 10836– 10844. ArXiv, Preprint, 2026 Xun Zhu, Fanbin Mo, Xi Chen, Kaili Zheng, Shaoshuai Yang, Yiming Shi, Jian Gao, Mia...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.