Recognition: 2 theorem links
· Lean TheoremInstAP: Instance-Aware Vision-Language Pre-Train for Spatial-Temporal Understanding
Pith reviewed 2026-05-10 18:01 UTC · model grok-4.3
The pith
Instance-aware pre-training adds grounded instance contrastive alignment to improve both local retrieval and global understanding in vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
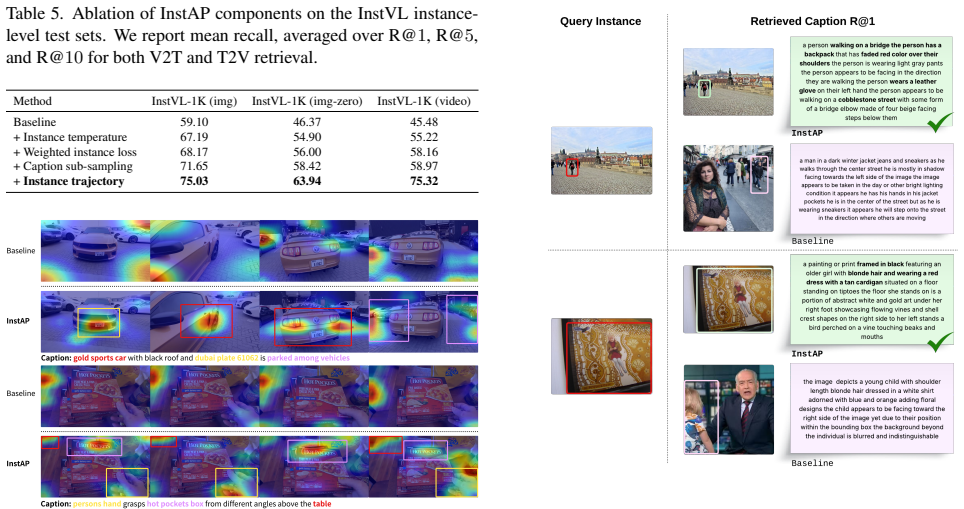
By jointly optimizing global vision-text alignment and instance-level contrastive alignment through grounding textual mentions to specific spatial-temporal regions in a dual-granularity dataset, the method achieves better instance-level retrieval than prior models and a same-data baseline, while delivering competitive zero-shot performance on video benchmarks.
What carries the argument
The instance-aware pre-training objective that performs fine-grained contrastive alignment by linking textual descriptions to particular spatial-temporal instance regions alongside global scene matching.
If this is right
- Substantially better performance on instance-level retrieval compared to existing vision-language pre-training models.
- Outperformance of a strong baseline trained on the identical data corpus, confirming the advantage of the instance-aware component.
- Competitive zero-shot results on video understanding benchmarks including MSR-VTT and DiDeMo.
- More precise localization of text mentions to the correct instances rather than diffuse scene-level attention.
Where Pith is reading between the lines
- Instance grounding may enable new applications in interactive video querying where users refer to specific objects or actions over time.
- Similar instance-aware objectives could be tested in other domains like audio-visual or 3D scene understanding to see if the benefits transfer.
- The dual-granularity annotation approach might reduce the need for task-specific fine-tuning in some retrieval scenarios.
Load-bearing premise
The dense grounded instance descriptions in the dataset can be produced at scale with sufficient accuracy to provide useful supervision without adding significant noise or errors.
What would settle it
Observing no improvement or a decline in instance-level retrieval accuracy when using the instance-aware objective compared to a global-only model trained on the same dataset would falsify the central benefit claimed.
Figures



read the original abstract
Current vision-language pre-training (VLP) paradigms excel at global scene understanding but struggle with instance-level reasoning due to global-only supervision. We introduce InstAP, an Instance-Aware Pre-training framework that jointly optimizes global vision-text alignment and fine-grained, instance-level contrastive alignment by grounding textual mentions to specific spatial-temporal regions. To support this, we present InstVL, a large-scale dataset (2 million images, 50,000 videos) with dual-granularity annotations: holistic scene captions and dense, grounded instance descriptions. On the InstVL benchmark, InstAP substantially outperforms existing VLP models on instance-level retrieval, and also surpasses a strong VLP baseline trained on the exact same data corpus, isolating the benefit of our instance-aware objective. Moreover, instance-centric pre-training improves global understanding: InstAP achieves competitive zero-shot performance on multiple video benchmarks, including MSR-VTT and DiDeMo. Qualitative visualizations further show that InstAP localizes textual mentions to the correct instances, while global-only models exhibit more diffuse, scene-level attention.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces InstAP, an instance-aware vision-language pre-training framework that jointly optimizes global vision-text alignment and fine-grained instance-level contrastive alignment by grounding textual mentions to specific spatial-temporal regions. It is supported by the new InstVL dataset (2M images, 50k videos) with dual-granularity annotations consisting of holistic scene captions and dense grounded instance descriptions. The central claims are that InstAP substantially outperforms existing VLP models and a same-data baseline on instance-level retrieval while also achieving competitive zero-shot performance on global video benchmarks such as MSR-VTT and DiDeMo.
Significance. If the results hold with clean supervision, this work addresses an important gap in VLP by improving instance-level reasoning alongside global understanding, which is relevant for spatial-temporal tasks. The use of a same-data baseline to isolate the benefit of the instance-aware objective is a methodological strength that supports causal attribution to the proposed loss. The approach could influence future pre-training designs if the grounding annotations prove reliable at scale.
major comments (2)
- [InstVL Dataset] InstVL Dataset section: The manuscript provides no validation metrics (e.g., inter-annotator agreement, spot-check error rates, or comparison to human ground truth) for the accuracy of the dense grounded instance descriptions. This is load-bearing for the central empirical claim because the instance-level contrastive objective depends on correct spatial-temporal grounding; systematic misalignment or description errors would introduce noisy supervision that could artifactually inflate instance-retrieval gains or degrade the global alignment term.
- [Results] Results section: The abstract reports outperformance on instance retrieval and competitive global results, but the provided text contains no quantitative tables, error bars, training hyperparameters, or statistical significance tests. Without these, the claim that InstAP surpasses the same-data baseline cannot be verified, undermining assessment of whether the instance-aware objective provides a genuine benefit.
minor comments (1)
- [Abstract] Abstract: The claims are stated at a high level; adding one sentence on how InstVL annotations were generated (human, automated, or hybrid) would improve clarity without lengthening the abstract excessively.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the InstVL dataset and results presentation. These comments highlight important aspects for strengthening the manuscript's rigor. We address each point below and will make the corresponding revisions.
read point-by-point responses
-
Referee: [InstVL Dataset] InstVL Dataset section: The manuscript provides no validation metrics (e.g., inter-annotator agreement, spot-check error rates, or comparison to human ground truth) for the accuracy of the dense grounded instance descriptions. This is load-bearing for the central empirical claim because the instance-level contrastive objective depends on correct spatial-temporal grounding; systematic misalignment or description errors would introduce noisy supervision that could artifactually inflate instance-retrieval gains or degrade the global alignment term.
Authors: We agree that explicit validation metrics are necessary to support the reliability of the grounded annotations used in the instance-level contrastive loss. In the revised manuscript, we will add a new subsection to the InstVL Dataset description reporting inter-annotator agreement scores (computed on a pilot set of 1,000 instances) and spot-check error rates from manual verification of a random sample of 500 descriptions against human ground truth. These additions will quantify annotation quality and address concerns about potential noise in the supervision. revision: yes
-
Referee: [Results] Results section: The abstract reports outperformance on instance retrieval and competitive global results, but the provided text contains no quantitative tables, error bars, training hyperparameters, or statistical significance tests. Without these, the claim that InstAP surpasses the same-data baseline cannot be verified, undermining assessment of whether the instance-aware objective provides a genuine benefit.
Authors: We acknowledge the need for complete quantitative reporting to allow verification of the claims. In the revised manuscript, we will expand the Results section to include the main comparison tables with all metrics, standard error bars (from multiple random seeds), a full list of training hyperparameters, and statistical significance tests (e.g., paired t-tests) against the same-data baseline. This will make the performance gains and the benefit of the instance-aware objective directly verifiable. revision: yes
Circularity Check
No circularity: purely empirical claims with independent dataset and baselines
full rationale
The paper introduces a new pre-training framework (InstAP) and supporting dataset (InstVL) with dual-granularity annotations, then reports empirical performance gains on instance-level retrieval and zero-shot video tasks. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text or abstract. The central claims rest on direct comparisons to prior VLP models and a same-data baseline, which are externally verifiable and do not reduce to self-definition or input fitting by construction. This is the expected non-finding for an empirical CV paper.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
InstAP jointly optimizes global vision-text alignment and fine-grained, instance-level contrastive alignment by grounding textual mentions to specific spatial-temporal regions.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The complete loss integrates masked-video reconstruction, global video-text alignment, and the three instance-level objectives: L = L_rec + L_global + L_inst
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Localizing mo- ments in video with natural language
Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan Russell. Localizing mo- ments in video with natural language. InProceedings of the IEEE international conference on computer vision, pages 5803–5812, 2017. 6
2017
-
[2]
Jinbin Bai, Chunhui Liu, Feiyue Ni, Haofan Wang, Mengy- ing Hu, Xiaofeng Guo, and Lele Cheng. Lat: latent trans- lation with cycle-consistency for video-text retrieval.arXiv preprint arXiv:2207.04858, 2022. 7
-
[3]
Frozen in time: A joint video and image encoder for end-to-end retrieval
Max Bain, Arsha Nagrani, G ¨ul Varol, and Andrew Zisser- man. Frozen in time: A joint video and image encoder for end-to-end retrieval. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 1728–1738,
-
[4]
Videocon: Robust video- language alignment via contrast captions
Hritik Bansal, Yonatan Bitton, Idan Szpektor, Kai-Wei Chang, and Aditya Grover. Videocon: Robust video- language alignment via contrast captions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13927–13937, 2024. 2
2024
-
[5]
Coyo-700m: Image-text pair dataset.https : / / github
Minwoo Byeon, Beomhee Park, Haecheon Kim, Sungjun Lee, Woonhyuk Baek, and Saehoon Kim. Coyo-700m: Image-text pair dataset.https : / / github . com / kakaobrain/coyo-dataset, 2022. 3
2022
-
[6]
Activitynet: A large-scale video benchmark for human activity understanding
Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activitynet: A large-scale video benchmark for human activity understanding. InProceed- ings of the ieee conference on computer vision and pattern recognition, pages 961–970, 2015. 6
2015
-
[7]
nuscenes: A multi- modal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom. nuscenes: A multi- modal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020. 2
2020
-
[8]
Conceptual 12m: Pushing web-scale image-text pre- training to recognize long-tail visual concepts
Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12m: Pushing web-scale image-text pre- training to recognize long-tail visual concepts. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3558–3568, 2021. 6
2021
-
[9]
Collecting highly paral- lel data for paraphrase evaluation
David Chen and William B Dolan. Collecting highly paral- lel data for paraphrase evaluation. InProceedings of the 49th annual meeting of the association for computational linguis- tics: human language technologies, pages 190–200, 2011. 6
2011
-
[10]
Sharegpt4v: Improving large multi-modal models with better captions
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. Sharegpt4v: Improving large multi-modal models with better captions. In European Conference on Computer Vision, pages 370–387. Springer, 2024. 6
2024
-
[11]
Reproducible scal- ing laws for contrastive language-image learning
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuh- mann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scal- ing laws for contrastive language-image learning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2818–2829, 2023. 6, 7
2023
-
[12]
Bert: Pre-training of deep bidirectional trans- formers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional trans- formers for language understanding. InProceedings of the 2019 conference of the North American chapter of the asso- ciation for computational linguistics: human language tech- nologies, volume 1 (long and short papers), pages 4171– 4186, 2019. 3, 4
2019
-
[13]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, et al. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 5
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[14]
arXiv preprint arXiv:2309.17425 (2023) 3, 4, 9, 11, 20, 21, 22
Alex Fang, Albin Madappally Jose, Amit Jain, Ludwig Schmidt, Alexander Toshev, and Vaishaal Shankar. Data fil- tering networks.arXiv preprint arXiv:2309.17425, 2023. 6
-
[15]
Masked autoencoders as spatiotemporal learners.Advances in neural information processing systems, 35:35946–35958,
Christoph Feichtenhofer, Yanghao Li, Kaiming He, et al. Masked autoencoders as spatiotemporal learners.Advances in neural information processing systems, 35:35946–35958,
-
[16]
Violet: End- to-end video-language transformers with masked visual-token modeling
Tsu-Jui Fu, Linjie Li, Zhe Gan, Kevin Lin, William Yang Wang, Lijuan Wang, and Zicheng Liu. Violet: End-to-end video-language transformers with masked visual-token mod- eling.arXiv preprint arXiv:2111.12681, 2021. 7
-
[17]
Bridging video-text retrieval with multiple choice questions
Yuying Ge, Yixiao Ge, Xihui Liu, Dian Li, Ying Shan, Xi- aohu Qie, and Ping Luo. Bridging video-text retrieval with multiple choice questions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16167–16176, 2022. 7
2022
-
[18]
Miles: Visual bert pre-training with injected language semantics for video- text retrieval
Yuying Ge, Yixiao Ge, Xihui Liu, Jinpeng Wang, Jianping Wu, Ying Shan, Xiaohu Qie, and Ping Luo. Miles: Visual bert pre-training with injected language semantics for video- text retrieval. InEuropean conference on computer vision, pages 691–708. Springer, 2022. 7
2022
-
[19]
Vignesh Gopinathan, Urs Zimmermann, Michael Arnold, and Matthias Rottmann. Temporal object captioning for street scene videos from lidar tracks.arXiv preprint arXiv:2505.16594, 2025. 2
-
[20]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000– 16009, 2022. 3
2022
-
[21]
Clover: Towards a unified video-language alignment and fusion model
Jingjia Huang, Yinan Li, Jiashi Feng, Xinglong Wu, Xi- aoshuai Sun, and Rongrong Ji. Clover: Towards a unified video-language alignment and fusion model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 14856–14866, 2023. 7
2023
-
[22]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 3 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
The Kinetics Human Action Video Dataset
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. The kinetics hu- man action video dataset.arXiv preprint arXiv:1705.06950,
work page internal anchor Pith review arXiv
-
[24]
Visual genome: Connecting language and vision using crowdsourced dense image annotations.International journal of computer vision, 123:32–73, 2017
Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalan- tidis, Li-Jia Li, David A Shamma, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations.International journal of computer vision, 123:32–73, 2017. 2, 6
2017
-
[25]
Revealing single frame bias for video-and-language learning
Jie Lei, Tamara Berg, and Mohit Bansal. Revealing single frame bias for video-and-language learning. InProceedings of the 61st Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers), pages 487–507,
-
[26]
Align and prompt: Video-and- language pre-training with entity prompts
Dongxu Li, Junnan Li, Hongdong Li, Juan Carlos Niebles, and Steven CH Hoi. Align and prompt: Video-and- language pre-training with entity prompts. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4953–4963, 2022. 7
2022
-
[27]
Prototype-based aleatoric uncertainty quantifica- tion for cross-modal retrieval.Advances in Neural Informa- tion Processing Systems, 36:24564–24585, 2023
Hao Li, Jingkuan Song, Lianli Gao, Xiaosu Zhu, and Heng- tao Shen. Prototype-based aleatoric uncertainty quantifica- tion for cross-modal retrieval.Advances in Neural Informa- tion Processing Systems, 36:24564–24585, 2023. 2
2023
-
[28]
Fine-grained semantically aligned vision-language pre-training.Advances in neural information processing sys- tems, 35:7290–7303, 2022
Juncheng Li, Xin He, Longhui Wei, Long Qian, Linchao Zhu, Lingxi Xie, Yueting Zhuang, Qi Tian, and Siliang Tang. Fine-grained semantically aligned vision-language pre-training.Advances in neural information processing sys- tems, 35:7290–7303, 2022. 3
2022
-
[29]
Unmasked teacher: Towards training-efficient video foundation models
Kunchang Li, Yali Wang, Yizhuo Li, Yi Wang, Yinan He, Limin Wang, and Yu Qiao. Unmasked teacher: Towards training-efficient video foundation models. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 19948–19960, 2023. 3, 4, 6, 7, 8
2023
-
[30]
Grounded language-image pre-training
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jian- wei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al. Grounded language-image pre-training. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10965–10975, 2022. 3
2022
-
[31]
Oscar: Object-semantics aligned pre-training for vision-language tasks
Xiujun Li, Xi Yin, Chunyuan Li, Pengchuan Zhang, Xiaowei Hu, Lei Zhang, Lijuan Wang, Houdong Hu, Li Dong, Furu Wei, et al. Oscar: Object-semantics aligned pre-training for vision-language tasks. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXX 16, pages 121–137. Springer,
2020
-
[32]
Openvision: A fully-open, cost-effective family of advanced vision encoders for multimodal learning
Xianhang Li, Yanqing Liu, Haoqin Tu, and Cihang Xie. Openvision: A fully-open, cost-effective family of advanced vision encoders for multimodal learning. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3977–3987, 2025. 6
2025
-
[33]
Token activation map to visually explain mul- timodal llms
Yi Li, Hualiang Wang, Xinpeng Ding, Haonan Wang, and Xiaomeng Li. Token activation map to visually explain mul- timodal llms. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 48–58, 2025. 8
2025
-
[34]
Egocentric video-language pretraining.Advances in Neural Information Processing Sys- tems, 35:7575–7586, 2022
Kevin Qinghong Lin, Jinpeng Wang, Mattia Soldan, Michael Wray, Rui Yan, Eric Z Xu, Difei Gao, Rong-Cheng Tu, Wen- zhe Zhao, Weijie Kong, et al. Egocentric video-language pretraining.Advances in Neural Information Processing Sys- tems, 35:7575–7586, 2022. 2
2022
-
[35]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In Computer vision–ECCV 2014: 13th European conference, zurich, Switzerland, September 6-12, 2014, proceedings, part v 13, pages 740–755. Springer, 2014. 6
2014
-
[36]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuro- pean conference on computer vision, pages 38–55. Springer,
-
[37]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning.Neu- rocomputing, 508:293–304, 2022
Huaishao Luo, Lei Ji, Ming Zhong, Yang Chen, Wen Lei, Nan Duan, and Tianrui Li. Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning.Neu- rocomputing, 508:293–304, 2022. 7
2022
-
[39]
Ea-vtr: Event-aware video-text retrieval
Zongyang Ma, Ziqi Zhang, Yuxin Chen, Zhongang Qi, Chunfeng Yuan, Bing Li, Yingmin Luo, Xu Li, Xiaojuan Qi, Ying Shan, et al. Ea-vtr: Event-aware video-text retrieval. InEuropean Conference on Computer Vision, pages 76–94. Springer, 2024. 7
2024
-
[40]
Im2text: Describing images using 1 million captioned pho- tographs.Advances in neural information processing sys- tems, 24, 2011
Vicente Ordonez, Girish Kulkarni, and Tamara Berg. Im2text: Describing images using 1 million captioned pho- tographs.Advances in neural information processing sys- tems, 24, 2011. 6
2011
-
[41]
Flickr30k entities: Collecting region-to-phrase corre- spondences for richer image-to-sentence models
Bryan A Plummer, Liwei Wang, Chris M Cervantes, Juan C Caicedo, Julia Hockenmaier, and Svetlana Lazeb- nik. Flickr30k entities: Collecting region-to-phrase corre- spondences for richer image-to-sentence models. InPro- ceedings of the IEEE international conference on computer vision, pages 2641–2649, 2015. 2
2015
-
[42]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 1, 2, 6
2021
-
[43]
Sam 2: Segment anything in images and videos,
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junt- ing Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao- Yuan Wu, Ross Girshick, Piotr Doll´ar, and Christoph Feicht- enhofer. Sam 2: Segment anything in images and videos,
-
[44]
Movie description.International Journal of Computer Vision, 123(1):94–120, 2017
Anna Rohrbach, Atousa Torabi, Marcus Rohrbach, Niket Tandon, Christopher Pal, Hugo Larochelle, Aaron Courville, and Bernt Schiele. Movie description.International Journal of Computer Vision, 123(1):94–120, 2017. 6
2017
-
[45]
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo 10 Coombes, Jenia Jitsev, and Aran Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. arXiv preprint arXiv:2111.02114, 2021. 3
work page internal anchor Pith review arXiv 2021
-
[46]
Annotating objects and relations in user- generated videos
Xindi Shang, Donglin Di, Junbin Xiao, Yu Cao, Xun Yang, and Tat-Seng Chua. Annotating objects and relations in user- generated videos. InProceedings of the 2019 on Interna- tional Conference on Multimedia Retrieval, pages 279–287,
2019
-
[47]
Conceptual captions: A cleaned, hypernymed, im- age alt-text dataset for automatic image captioning
Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, im- age alt-text dataset for automatic image captioning. InPro- ceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2556–2565, 2018. 6
2018
-
[48]
Fangxun Shu, Biaolong Chen, Yue Liao, Shuwen Xiao, Wenyu Sun, Xiaobo Li, Yousong Zhu, Jinqiao Wang, and Si Liu. Masked contrastive pre-training for efficient video-text retrieval.arXiv preprint arXiv:2212.00986, 2022. 4
-
[49]
Long-form video-language pre- training with multimodal temporal contrastive learning.Ad- vances in neural information processing systems, 35:38032– 38045, 2022
Yuchong Sun, Hongwei Xue, Ruihua Song, Bei Liu, Huan Yang, and Jianlong Fu. Long-form video-language pre- training with multimodal temporal contrastive learning.Ad- vances in neural information processing systems, 35:38032– 38045, 2022. 2
2022
-
[50]
Holistic features are almost sufficient for text-to- video retrieval
Kaibin Tian, Ruixiang Zhao, Zijie Xin, Bangxiang Lan, and Xirong Li. Holistic features are almost sufficient for text-to- video retrieval. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17138– 17147, 2024. 2
2024
-
[51]
Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training.Advances in neural information processing systems, 35:10078–10093, 2022
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training.Advances in neural information processing systems, 35:10078–10093, 2022. 3, 4
2022
-
[52]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muham- mad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language en- coders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Object- aware video-language pre-training for retrieval
Jinpeng Wang, Yixiao Ge, Guanyu Cai, Rui Yan, Xudong Lin, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. Object- aware video-language pre-training for retrieval. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3313–3322, 2022. 7
2022
-
[54]
InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, et al. Internvid: A large-scale video-text dataset for multimodal understanding and generation.arXiv preprint arXiv:2307.06942, 2023. 7
work page internal anchor Pith review arXiv 2023
-
[55]
InternVideo2.5: Empowering video MLLMs with long and rich context modeling.arXiv:2501.12386, 2025
Yi Wang, Xinhao Li, Ziang Yan, Yinan He, Jiashuo Yu, Xi- angyu Zeng, Chenting Wang, Changlian Ma, Haian Huang, Jianfei Gao, et al. Internvideo2. 5: Empowering video mllms with long and rich context modeling.arXiv preprint arXiv:2501.12386, 2025. 2, 3
-
[56]
Xing Wu, Chaochen Gao, Zijia Lin, Zhongyuan Wang, Jizhong Han, and Songlin Hu. Rap: redundancy-aware video-language pre-training for text-video retrieval.arXiv preprint arXiv:2210.06881, 2022. 7
-
[57]
Videoclip: Contrastive pre-training for zero-shot video-text understanding
Hu Xu, Gargi Ghosh, Po-Yao Huang, Dmytro Okhonko, Armen Aghajanyan, Florian Metze, Luke Zettlemoyer, and Christoph Feichtenhofer. Videoclip: Contrastive pre-training for zero-shot video-text understanding.arXiv preprint arXiv:2109.14084, 2021. 2, 3
-
[58]
Msr-vtt: A large video description dataset for bridging video and language
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. Msr-vtt: A large video description dataset for bridging video and language. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5288–5296, 2016. 6
2016
-
[59]
Ad- vancing high-resolution video-language representation with large-scale video transcriptions
Hongwei Xue, Tiankai Hang, Yanhong Zeng, Yuchong Sun, Bei Liu, Huan Yang, Jianlong Fu, and Baining Guo. Ad- vancing high-resolution video-language representation with large-scale video transcriptions. InInternational Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 3
2022
-
[60]
Clip-vip: Adapting pre- trained image-text model to video-language alignment
Hongwei Xue, Yuchong Sun, Bei Liu, Jianlong Fu, Ruihua Song, Houqiang Li, and Jiebo Luo. Clip-vip: Adapting pre- trained image-text model to video-language alignment. In The Eleventh International Conference on Learning Repre- sentations, 2023. 7
2023
-
[61]
Multiview transformers for video recognition
Shen Yan, Xuehan Xiong, Anurag Arnab, Zhichao Lu, Mi Zhang, Chen Sun, and Cordelia Schmid. Multiview transformers for video recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3333–3343, 2022. 3
2022
-
[62]
Learning trajectory-word alignments for video-language tasks
Xu Yang, Zhangzikang Li, Haiyang Xu, Hanwang Zhang, Qinghao Ye, Chenliang Li, Ming Yan, Yu Zhang, Fei Huang, and Songfang Huang. Learning trajectory-word alignments for video-language tasks. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2504– 2514, 2023. 7
2023
-
[63]
Dgl: Dynamic global-local prompt tuning for text-video re- trieval
Xiangpeng Yang, Linchao Zhu, Xiaohan Wang, and Yi Yang. Dgl: Dynamic global-local prompt tuning for text-video re- trieval. InProceedings of the AAAI Conference on Artificial Intelligence, pages 6540–6548, 2024. 2
2024
-
[64]
CoCa: Contrastive Captioners are Image-Text Foundation Models
Jiahui Yu, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mo- jtaba Seyedhosseini, and Yonghui Wu. Coca: Contrastive captioners are image-text foundation models.arXiv preprint arXiv:2205.01917, 2022. 7
work page internal anchor Pith review arXiv 2022
-
[65]
Osprey: Pixel un- derstanding with visual instruction tuning
Yuqian Yuan, Wentong Li, Jian Liu, Dongqi Tang, Xinjie Luo, Chi Qin, Lei Zhang, and Jianke Zhu. Osprey: Pixel un- derstanding with visual instruction tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 28202–28211, 2024. 2, 3
2024
-
[66]
Mer- lot: Multimodal neural script knowledge models.Advances in neural information processing systems, 34:23634–23651,
Rowan Zellers, Ximing Lu, Jack Hessel, Youngjae Yu, Jae Sung Park, Jize Cao, Ali Farhadi, and Yejin Choi. Mer- lot: Multimodal neural script knowledge models.Advances in neural information processing systems, 34:23634–23651,
-
[67]
Yan Zeng, Xinsong Zhang, and Hang Li. Multi-grained vi- sion language pre-training: Aligning texts with visual con- cepts.arXiv preprint arXiv:2111.08276, 2021. 3
-
[68]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023. 2, 7 11
2023
-
[69]
Vinvl: Revisiting visual representations in vision-language models
Pengchuan Zhang, Xiujun Li, Xiaowei Hu, Jianwei Yang, Lei Zhang, Lijuan Wang, Yejin Choi, and Jianfeng Gao. Vinvl: Revisiting visual representations in vision-language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5579–5588,
-
[70]
Long Zhao, Nitesh B Gundavarapu, Liangzhe Yuan, Hao Zhou, Shen Yan, Jennifer J Sun, Luke Friedman, Rui Qian, Tobias Weyand, Yue Zhao, et al. Videoprism: A founda- tional visual encoder for video understanding.arXiv preprint arXiv:2402.13217, 2024. 3, 7
-
[71]
Regionclip: Region- based language-image pretraining
Yiwu Zhong, Jianwei Yang, Pengchuan Zhang, Chun- yuan Li, Noel Codella, Liunian Harold Li, Luowei Zhou, Xiyang Dai, Lu Yuan, Yin Li, et al. Regionclip: Region- based language-image pretraining. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16793–16803, 2022. 3
2022
-
[72]
Grounded video description
Luowei Zhou, Yannis Kalantidis, Xinlei Chen, Jason J Corso, and Marcus Rohrbach. Grounded video description. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 6578–6587, 2019. 2
2019
-
[73]
Au- toshot: A short video dataset and state-of-the-art shot bound- ary detection
Wentao Zhu, Yufang Huang, Xiufeng Xie, Wenxian Liu, Jin- can Deng, Debing Zhang, Zhangyang Wang, and Ji Liu. Au- toshot: A short video dataset and state-of-the-art shot bound- ary detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2238– 2247, 2023. 3 12
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.