Recognition: 2 theorem links
· Lean TheoremVerify Before You Commit: Towards Faithful Reasoning in LLM Agents via Self-Auditing
Pith reviewed 2026-05-10 17:44 UTC · model grok-4.3
The pith
LLM agents can audit their own reasoning steps before acting to stop unfaithful beliefs from spreading.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SAVeR generates persona-based diverse candidate beliefs for selection under a faithfulness-relevant structure space, then applies adversarial auditing to localize violations and repair them through constraint-guided minimal interventions that meet verifiable acceptance criteria, thereby enforcing faithful reasoning before action commitment.
What carries the argument
SAVeR framework that uses persona-based candidate generation followed by adversarial auditing to localize and minimally repair violations before commitment.
If this is right
- Reasoning trajectories become more faithful across six standard agent benchmarks.
- Unsupported beliefs are less likely to be stored in memory and propagated to future steps.
- End-task performance stays competitive with unaudited agents.
- Systematic behavioral drift is reduced in long-horizon decision sequences.
- Verification occurs over internal belief states rather than final outputs alone.
Where Pith is reading between the lines
- The same candidate-generation-plus-audit loop could be layered on top of existing agent frameworks without retraining the underlying model.
- If acceptance criteria are made domain-specific, the method might transfer to safety-critical settings where logical violations carry high stakes.
- Scaling the number of personas or audit rounds could trade compute for further faithfulness gains, which remains untested here.
- Repeated auditing across many steps might expose whether the repair process itself accumulates subtle biases over time.
Load-bearing premise
Persona-based candidate generation plus adversarial auditing can reliably detect and repair logical or evidential violations without introducing new inconsistencies or excessive cost.
What would settle it
A controlled run on any of the six benchmarks where SAVeR either lowers faithfulness scores or increases the rate of unsupported beliefs compared with a plain chain-of-thought baseline.
Figures



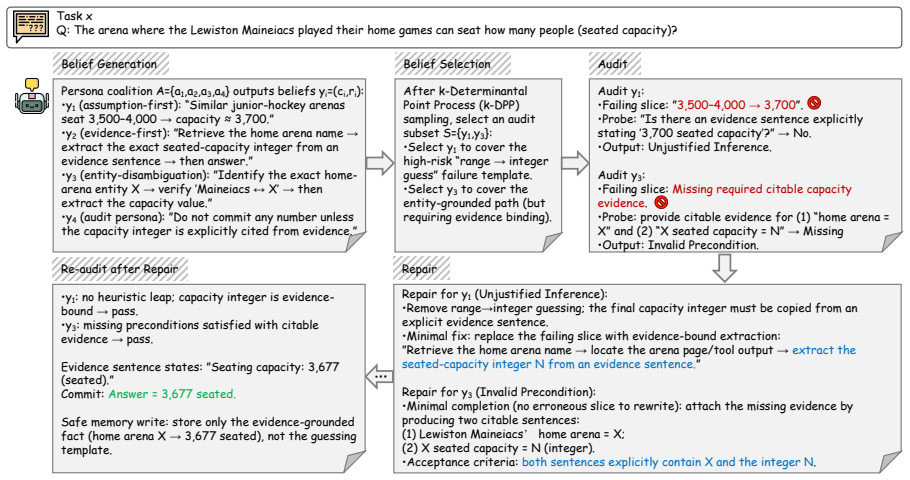
read the original abstract
In large language model (LLM) agents, reasoning trajectories are treated as reliable internal beliefs for guiding actions and updating memory. However, coherent reasoning can still violate logical or evidential constraints, allowing unsupported beliefs repeatedly stored and propagated across decision steps, leading to systematic behavioral drift in long-horizon agentic systems. Most existing strategies rely on the consensus mechanism, conflating agreement with faithfulness. In this paper, inspired by the vulnerability of unfaithful intermediate reasoning trajectories, we propose \textbf{S}elf-\textbf{A}udited \textbf{Ve}rified \textbf{R}easoning (\textsc{SAVeR}), a novel framework that enforces verification over internal belief states within the agent before action commitment, achieving faithful reasoning. Concretely, we structurally generate persona-based diverse candidate beliefs for selection under a faithfulness-relevant structure space. To achieve reasoning faithfulness, we perform adversarial auditing to localize violations and repair through constraint-guided minimal interventions under verifiable acceptance criteria. Extensive experiments on six benchmark datasets demonstrate that our approach consistently improves reasoning faithfulness while preserving competitive end-task performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SAVeR (Self-Audited Verified Reasoning), a framework for LLM agents that generates persona-based diverse candidate beliefs, applies adversarial auditing to localize logical or evidential violations, and performs constraint-guided minimal repairs under verifiable acceptance criteria before committing to actions. This aims to prevent unsupported beliefs from propagating and causing behavioral drift in long-horizon systems. The central empirical claim is that the approach yields consistent gains in reasoning faithfulness across six benchmark datasets while preserving competitive end-task performance.
Significance. If the self-auditing and repair pipeline proves reliable, the work could meaningfully advance faithful reasoning in agentic LLMs by shifting from consensus-based checks to explicit verification of internal belief states. The persona-based candidate generation and constraint-guided intervention are conceptually clean contributions. However, the significance is limited by the absence of external oracles and the reliance on the same LLM instance for both generation and auditing, which directly tests the weakest assumption identified in the stress-test note.
major comments (2)
- [§3] §3 (Method, adversarial auditing paragraph): The auditor is instantiated from the same underlying LLM as the reasoner. This is load-bearing for the faithfulness claim because any undetected inconsistencies in the candidate trajectories will propagate through the repair step; the manuscript provides no independent verification mechanism or quantitative audit-success rates to demonstrate that the auditor reliably flags violations the reasoner itself missed.
- [§4] §4 (Experiments): The abstract asserts 'consistent improvements' and 'competitive end-task performance' on six datasets, yet the reported results lack explicit metrics, baseline comparisons, statistical tests, or ablation studies on the auditing component. Without these, it is impossible to evaluate whether the gains are attributable to the SAVeR pipeline or to post-hoc choices, directly undermining the central empirical claim.
minor comments (2)
- [Abstract] The expansion of the SAVeR acronym appears after its first use in the abstract; define it on first mention for clarity.
- [§3] Notation for 'verifiable acceptance criteria' is introduced without a formal definition or pseudocode; a short algorithmic box would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment below and describe the revisions we will undertake to strengthen the paper.
read point-by-point responses
-
Referee: [§3] §3 (Method, adversarial auditing paragraph): The auditor is instantiated from the same underlying LLM as the reasoner. This is load-bearing for the faithfulness claim because any undetected inconsistencies in the candidate trajectories will propagate through the repair step; the manuscript provides no independent verification mechanism or quantitative audit-success rates to demonstrate that the auditor reliably flags violations the reasoner itself missed.
Authors: We agree that instantiating the auditor from the same LLM is a central design decision whose reliability must be demonstrated. The framework uses persona-based candidate generation to produce diverse belief trajectories, followed by adversarial auditing that cross-checks these trajectories against logical and evidential constraints; this structure is intended to surface violations that a single forward pass might overlook. Nevertheless, the current manuscript does not report quantitative audit-success rates or an independent verification mechanism. In the revised version we will add a dedicated evaluation subsection that injects controlled violations into reasoning traces and measures the auditor’s detection precision and recall under the verifiable acceptance criteria. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract asserts 'consistent improvements' and 'competitive end-task performance' on six datasets, yet the reported results lack explicit metrics, baseline comparisons, statistical tests, or ablation studies on the auditing component. Without these, it is impossible to evaluate whether the gains are attributable to the SAVeR pipeline or to post-hoc choices, directly undermining the central empirical claim.
Authors: We acknowledge that the experimental presentation in the submitted manuscript does not make the supporting metrics and controls sufficiently explicit. The full paper already contains comparisons against standard baselines (chain-of-thought, self-consistency, and reflection-based agents) across the six benchmarks, but we will expand §4 to include (i) complete numerical tables for both faithfulness and end-task metrics, (ii) statistical significance tests (paired t-tests and Wilcoxon signed-rank tests with p-values), and (iii) ablation studies that isolate the adversarial-auditing and constraint-guided repair stages. These additions will allow readers to attribute observed gains directly to the SAVeR components. revision: yes
Circularity Check
No circularity in SAVeR framework; method is independent procedural proposal
full rationale
The paper introduces SAVeR as a novel procedural framework consisting of persona-based candidate generation, adversarial auditing for violation localization, and constraint-guided repairs under verifiable criteria. The provided text contains no equations, fitted parameters, or load-bearing self-citations that reduce any claimed result to its own inputs by construction. The derivation chain is a sequence of described steps rather than a mathematical reduction, and the experimental results on six benchmarks are presented as separate empirical validation without renaming known patterns or smuggling ansatzes via prior self-work. This qualifies as a self-contained methodological contribution with no detectable circularity under the specified patterns.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/LogicAsFunctionalEquation.leanSatisfiesLawsOfLogic unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we structurally generate persona-based diverse candidate beliefs... perform adversarial auditing to localize violations and repair through constraint-guided minimal interventions under verifiable acceptance criteria
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
trajectory-level unfaithfulness rate U(τ) = 1/L Σ I[Γ(sl | x, Hl, El) < ϵ]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Kaikai An, Fangkai Yang, Liqun Li, Junting Lu, Sitao Cheng, Shuzheng Si, Lu Wang, Pu Zhao, Lele Cao, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang, and Baobao Chang. 2025. https://aclanthology.org/2025.emnlp-main.923 Thread: A logic-based data organization paradigm for how-to question answering with retrieval augmented generation . In Proceedings of the 20...
2025
-
[4]
Aseem Arora, Shabbirhussain Bhaisaheb, Harshit Nigam, Manasi Patwardhan, Lovekesh Vig, and Gautam Shroff. 2023. https://aclanthology.org/2023.genbench-1.3 Adapt and decompose: Efficient generalization of text-to-sql via domain adapted least-to-most prompting . In Proceedings of the 1st GenBench Workshop on (Benchmarking) Generalisation in NLP, pages 25--4...
2023
-
[5]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, and 8 others. 2025. https://arxiv.org/abs/2502.13923 Qwen2.5-vl technical report . Preprint, arXiv:2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Fazl Barez, Tung-Yu Wu, Iv \'a n Arcuschin, Michael Lan, Vincent Wang, Noah Siegel, Nicolas Collignon, Clement Neo, Isabelle Lee, Alasdair Paren, and 1 others. 2025. https://fbarez.github.io/assets/pdf/Cot_Is_Not_Explainability.pdf Chain-of-thought is not explainability . Preprint, alphaXiv, page v1
2025
-
[7]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, and 12 others. 2020. https://proceedings.neurips.cc/paper_fil...
2020
-
[8]
Neeloy Chakraborty, Melkior Ornik, and Katherine Driggs-Campbell. 2025. https://doi.org/10.1145/3716846 Hallucination detection in foundation models for decision-making: A flexible definition and review of the state of the art . ACM Computing Surveys, 57(7):1--35
-
[9]
Ching Chang, Yidan Shi, Defu Cao, Wei Yang, Jeehyun Hwang, Haixin Wang, Jiacheng Pang, Wei Wang, Yan Liu, Wen-Chih Peng, and Tien-Fu Chen. 2025. https://arxiv.org/abs/2509.11575 A survey of reasoning and agentic systems in time series with large language models . arXiv preprint arXiv:2509.11575
-
[10]
Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W Cohen. 2023. https://openreview.net/forum?id=YfZ4ZPt8zd Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks . Transactions on Machine Learning Research
2023
-
[11]
Zhaoling Chen, Robert Tang, Gangda Deng, Fang Wu, Jialong Wu, Zhiwei Jiang, Viktor Prasanna, Arman Cohan, and Xingyao Wang. 2025. https://aclanthology.org/2025.acl-long.426 Locagent: Graph-guided llm agents for code localization . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8697...
2025
-
[12]
Haoang Chi, He Li, Wenjing Yang, Feng Liu, Long Lan, Xiaoguang Ren, Tongliang Liu, and Bo Han. 2024. https://proceedings.neurips.cc/paper_files/paper/2024/file/af2bb2b2280d36f8842e440b4e275152-Paper-Conference.pdf Unveiling causal reasoning in large language models: Reality or mirage? In Advances in Neural Information Processing Systems, volume 37, pages ...
2024
-
[13]
Pradeep Dasigi, Nelson F Liu, Ana Marasovi \'c , Noah A Smith, and Matt Gardner. 2019. https://doi.org/10.18653/v1/D19-1606 Quoref: A reading comprehension dataset with questions requiring coreferential reasoning . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natura...
-
[14]
Bowen Ding, Qingkai Min, Shengkun Ma, Yingjie Li, Linyi Yang, and Yue Zhang. 2024. https://aclanthology.org/2024.naacl-long.63 A rationale-centric counterfactual data augmentation method for cross-document event coreference resolution . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Hu...
2024
-
[15]
John Dougrez-Lewis, Mahmud Elahi Akhter, Federico Ruggeri, Sebastian L \"o bbers, Yulan He, and Maria Liakata. 2025. https://aclanthology.org/2025.findings-acl.1059 Assessing the reasoning capabilities of llms in the context of evidence-based claim verification . In Findings of the Association for Computational Linguistics: ACL 2025, pages 20604--20628. A...
2025
-
[16]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, A. Schelten, Amy Yang, Angela Fan, Anirudh Goyal, Anthony S. Hartshorn, Aobo Yang, Archi Mitra, A. Sravankumar, A. Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, and 510 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3 herd of models
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Dayuan Fu, Keqing He, Yejie Wang, Wentao Hong, Zhuoma Gongque, Weihao Zeng, Wei Wang, Jingang Wang, Xunliang Cai, and Weiran Xu. 2025. https://openreview.net/forum?id=FDimWzmcWn Agentrefine: Enhancing agent generalization through refinement tuning . In The Thirteenth International Conference on Learning Representations
2025
-
[18]
Florian Gr \"o tschla, Luis M \"u ller, Jan T \"o nshoff, Mikhail Galkin, and Bryan Perozzi. 2025. https://arxiv.org/abs/2507.08616 Agentsnet: Coordination and collaborative reasoning in multi-agent llms . arXiv preprint arXiv:2507.08616
-
[19]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. https://doi.org/10.18653/v1/2020.coling-main.580 Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps . In Proceedings of the 28th International Conference on Computational Linguistics, pages 6609--6625, Barcelona, Spain (Online). International Committee ...
-
[20]
Sirui Hong, Yizhang Lin, Bang Liu, Bangbang Liu, Binhao Wu, Ceyao Zhang, Danyang Li, Jiaqi Chen, Jiayi Zhang, Jinlin Wang, Li Zhang, Lingyao Zhang, Min Yang, Mingchen Zhuge, Taicheng Guo, Tuo Zhou, Wei Tao, Robert Tang, Xiangtao Lu, and 9 others. 2025. https://aclanthology.org/2025.findings-acl.1016 Data interpreter: An LLM agent for data science . In Fin...
2025
-
[21]
Yue Jiang, Qin Chao, Yile Chen, Xiucheng Li, Shuai Liu, and Gao Cong. 2024. https://aclanthology.org/2024.findings-emnlp.98 U rban LLM : Autonomous urban activity planning and management with large language models . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 1810--1825. Association for Computational Linguistics
2024
- [22]
-
[23]
Abhinav Joshi, Areeb Ahmad, and Ashutosh Modi. 2024. https://proceedings.neurips.cc/paper_files/paper/2024/file/09265e2568cf7a6ff47b506acbc2c6eb-Paper-Conference.pdf Cold: Causal reasoning in closed daily activities . In Advances in Neural Information Processing Systems, volume 37, pages 5145--5187. Curran Associates, Inc
2024
-
[24]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick SH Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.550 Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769--6781. Associati...
-
[25]
Zixuan Ke, Fangkai Jiao, Yifei Ming, Xuan-Phi Nguyen, Austin Xu, Do Xuan Long, Minzhi Li, Chengwei Qin, PeiFeng Wang, silvio savarese, Caiming Xiong, and Shafiq Joty. 2025. https://openreview.net/forum?id=SlsZZ25InC A survey of frontiers in LLM reasoning: Inference scaling, learning to reason, and agentic systems . Transactions on Machine Learning Researc...
2025
-
[26]
Minsoo Kim, Jongyoon Kim, Jihyuk Kim, and Seung-won Hwang. 2024. https://aclanthology.org/2024.emnlp-main.1193 Q u BE : Question-based belief enhancement for agentic LLM reasoning . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 21403--21423. Association for Computational Linguistics
2024
-
[27]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. https://proceedings.neurips.cc/paper_files/paper/2022/file/8bb0d291acd4acf06ef112099c16f326-Paper-Conference.pdf Large language models are zero-shot reasoners . In Advances in Neural Information Processing Systems, volume 35, pages 22199--22213. Curran Associates, Inc
2022
-
[28]
Adam Kostka and Jaros \'L Chudziak. 2025. https://escholarship.org/uc/item/20j8628c Towards cognitive synergy in llm-based multi-agent systems: integrating theory of mind and critical evaluation . In Proceedings of the Annual Meeting of the Cognitive Science Society, volume 47
2025
-
[29]
Man Ho Lam, Chaozheng Wang, Jen-tse Huang, and Michael Lyu. 2025. https://openreview.net/forum?id=CAB0EjD9EK Codecrash: Exposing llm fragility to misleading natural language in code reasoning . In The Thirty-ninth Annual Conference on Neural Information Processing Systems, volume 38
2025
-
[30]
Jiachun Li, Pengfei Cao, Yubo Chen, Jiexin Xu, Huaijun Li, Xiaojian Jiang, Kang Liu, and Jun Zhao. 2025. https://aclanthology.org/2025.findings-acl.560 Towards better chain-of-thought: A reflection on effectiveness and faithfulness . In Findings of the Association for Computational Linguistics: ACL 2025, pages 10747--10765. Association for Computational L...
2025
- [31]
-
[32]
Sirui Liang, Baoli Zhang, Jun Zhao, and Kang Liu. 2024 a . https://aclanthology.org/2024.emnlp-main.691 ABSE val: An agent-based framework for script evaluation . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 12418--12434. Association for Computational Linguistics
2024
-
[33]
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. 2024 b . https://doi.org/10.18653/v1/2024.emnlp-main.992 Encouraging divergent thinking in large language models through multi-agent debate . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17889--...
-
[34]
Linhao Luo, Yuan-Fang Li, Gholamreza Haffari, and Shirui Pan. 2024. https://openreview.net/forum?id=ZGNWW7xZ6Q Reasoning on graphs: Faithful and interpretable large language model reasoning . In The Twelfth International Conference on Learning Representations
2024
-
[35]
Linhao Luo, Zicheng Zhao, Gholamreza Haffari, Yuan-Fang Li, Chen Gong, and Shirui Pan. 2025. https://proceedings.mlr.press/v267/luo25t.html Graph-constrained reasoning: Faithful reasoning on knowledge graphs with large language models . In Proceedings of the 42nd International Conference on Machine Learning, volume 267 of Proceedings of Machine Learning R...
2025
-
[36]
Qing Lyu, Shreya Havaldar, Adam Stein, Li Zhang, Delip Rao, Eric Wong, Marianna Apidianaki, and Chris Callison-Burch. 2023. https://par.nsf.gov/biblio/10463284 Faithful chain-of-thought reasoning . In The 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computation...
-
[37]
Qianou Ma, Weirui Peng, Chenyang Yang, Hua Shen, Kenneth Koedinger, and Tongshuang Wu. 2025. https://doi.org/10.1145/3731756 What should we engineer in prompts? training humans in requirement-driven llm use . ACM Transactions on Computer-Human Interaction, 32(4)
-
[38]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/file/91edff07232fb1b55a505a9e9f6c0ff3-Pap...
2023
-
[39]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. https://doi.org/10.3115/1073083.1073135 Bleu: a method for automatic evaluation of machine translation . In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311--318, USA. Association for Computational Linguistics
-
[40]
Debjit Paul, Robert West, Antoine Bosselut, and Boi Faltings. 2024. https://aclanthology.org/2024.findings-emnlp.882 Making reasoning matter: Measuring and improving faithfulness of chain-of-thought reasoning . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 15012--15032. Association for Computational Linguistics
2024
-
[41]
Amartya Roy, N Devharish, Shreya Ganguly, and Kripabandhu Ghosh. 2025. https://aclanthology.org/2025.findings-emnlp.439 Causal- LLM : A unified one-shot framework for prompt- and data-driven causal graph discovery . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 8259--8279. Association for Computational Linguistics
2025
-
[42]
Lei Shu, Liangchen Luo, Jayakumar Hoskere, Yun Zhu, Yinxiao Liu, Simon Tong, Jindong Chen, and Lei Meng. 2024. https://ojs.aaai.org/index.php/AAAI/article/view/29863 Rewritelm: An instruction-tuned large language model for text rewriting . In Proceedings of the AAAI Conference on Artificial Intelligence, pages 18970--18980
2024
-
[43]
Xiangru Tang, Tianyu Hu, Muyang Ye, Yanjun Shao, Xunjian Yin, Siru Ouyang, Wangchunshu Zhou, Pan Lu, Zhuosheng Zhang, Yilun Zhao, Arman Cohan, and Mark Gerstein. 2025. https://openreview.net/forum?id=kuhIqeVg0e Chemagent: Self-updating memories in large language models improves chemical reasoning . In The Thirteenth International Conference on Learning Re...
2025
-
[44]
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. 2018. https://doi.org/10.18653/v1/N18-1074 Fever: a large-scale dataset for fact extraction and verification . Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) ...
work page internal anchor Pith review doi:10.18653/v1/n18-1074 2018
-
[45]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth \'e e Lacroix, Baptiste Rozi \`e re, Naman Goyal, Eric Hambro, Faisal Azhar, Rodriguez Aurelien, Joulin Armand, Grave Edouard, and Lample Guillaume. 2023. https://formacion.actuarios.org/wp-content/uploads/2024/05/2302.13971-LLama-Open-and-Efficient-Foundation-Langu...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2022. https://doi.org/10.1162/tacl_a_00475 Musique: Multihop questions via single-hop question composition . Transactions of the Association for Computational Linguistics, 10:539--554
-
[47]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel Bowman. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/file/ed3fea9033a80fea1376299fa7863f4a-Paper-Conference.pdf Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting . In Advances in Neural Information Processing Systems, volume 36, pages...
2023
-
[48]
Guangya Wan, Yuqi Wu, Jie Chen, and Sheng Li. 2025. https://aclanthology.org/2025.naacl-long.184 Reasoning aware self-consistency: Leveraging reasoning paths for efficient llm sampling . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long...
2025
-
[49]
Zilong Wang, Hao Zhang, Chun-Liang Li, Julian Martin Eisenschlos, Vincent Perot, Zifeng Wang, Lesly Miculicich, Yasuhisa Fujii, Jingbo Shang, Chen-Yu Lee, and Tomas Pfister. 2024. https://openreview.net/forum?id=4L0xnS4GQM Chain-of-table: Evolving tables in the reasoning chain for table understanding . In The Twelfth International Conference on Learning R...
2024
-
[50]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. 2022. https://proceedings.neurips.cc/paper_files/paper/2022/file/9d5609613524ecf4f15af0f7b31abca4-Paper-Conference.pdf Chain-of-thought prompting elicits reasoning in large language models . In Advances in Neural Information Processing Systems...
2022
-
[51]
Zhihui Xie, Jizhou Guo, Tong Yu, and Shuai Li. 2024. https://proceedings.neurips.cc/paper_files/paper/2024/file/d037fd021c9aace128b8ce25001cdb6c-Paper-Conference.pdf Calibrating reasoning in language models with internal consistency . In Advances in Neural Information Processing Systems, volume 37, pages 114872--114901. Curran Associates, Inc
2024
-
[52]
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. 2025 a . https://neurips.cc/virtual/2025/loc/san-diego/poster/119020 A-mem: Agentic memory for LLM agents . In The Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[53]
Yige Xu, Xu Guo, Zhiwei Zeng, and Chunyan Miao. 2025 b . https://aclanthology.org/2025.acl-long.1137 S oft C o T : Soft chain-of-thought for efficient reasoning with LLM s . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 23336--23351. Association for Computational Linguistics
2025
-
[54]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. https://proceedings.neurips.cc/paper_files/paper/2024/file/5a7c947568c1b1328ccc5230172e1e7c-Paper-Conference.pdf Swe-agent: Agent-computer interfaces enable automated software engineering . In Advances in Neural Information Processing System...
2024
-
[55]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. 2018. https://aclanthology.org/D18-1259 Hotpotqa: A dataset for diverse, explainable multi-hop question answering . In Proceedings of the 2018 conference on empirical methods in natural language processing, pages 2369--2380
2018
-
[56]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2023. https://openreview.net/forum?id=WE_vluYUL-X React: Synergizing reasoning and acting in language models . In The Eleventh International Conference on Learning Representations
2023
-
[57]
Shaowei Zhang and Deyi Xiong. 2025. https://aclanthology.org/2025.findings-acl.862 D ebate4 MATH : Multi-agent debate for fine-grained reasoning in math . In Findings of the Association for Computational Linguistics: ACL 2025, pages 16810--16824. Association for Computational Linguistics
2025
-
[58]
Tianhua Zhang, Jiaxin Ge, Hongyin Luo, Yung-Sung Chuang, Mingye Gao, Yuan Gong, Yoon Kim, Xixin Wu, Helen Meng, and James Glass. 2024. https://aclanthology.org/2024.findings-naacl.259 Natural language embedded programs for hybrid language symbolic reasoning . In Findings of the Association for Computational Linguistics: NAACL 2024, pages 4131--4155. Assoc...
2024
-
[59]
Chengshuai Zhao, Zhen Tan, Pingchuan Ma, Dawei Li, Bohan Jiang, Yancheng Wang, Yingzhen Yang, and Huan Liu. 2025. https://arxiv.org/abs/2508.01191 Is chain-of-thought reasoning of llms a mirage? a data distribution lens . arXiv preprint arXiv:2508.01191
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Denny Zhou, Nathanael Sch \"a rli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, and Ed H. Chi. 2023. https://openreview.net/forum?id=WZH7099tgfM Least-to-most prompting enables complex reasoning in large language models . In The Eleventh International Conference on Learning Representations
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.