Recognition: 1 theorem link
· Lean TheoremKV Cache Offloading for Context-Intensive Tasks
Pith reviewed 2026-05-13 07:32 UTC · model grok-4.3
The pith
KV cache offloading loses accuracy on context-intensive tasks because of low-rank key projections and unreliable landmarks, but a simpler strategy restores performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
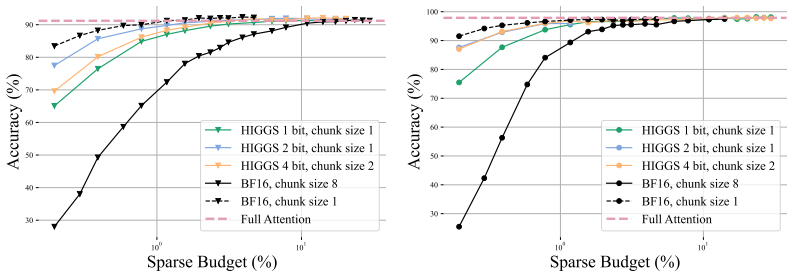
Standard KV-cache offloading techniques produce substantial accuracy losses on context-intensive tasks because they use low-rank projections of keys and unreliable landmarks. Replacing these elements with a simpler alternative strategy yields significantly higher accuracy on the new Text2JSON benchmark and other context-intensive tasks across Llama 3, Qwen 3, and additional LLM families.
What carries the argument
The central mechanism is the replacement of low-rank key projections and unreliable landmarks in KV offloading with a simpler alternative strategy that preserves accuracy during memory offloading for long contexts.
If this is right
- KV offloading becomes usable for tasks requiring dense information lookup once low-rank projections are removed.
- The accuracy gains from the alternative strategy hold across multiple LLM families and several context-intensive benchmarks.
- Text2JSON provides a repeatable test for measuring how well compression methods handle structured extraction.
- Evaluations of long-context techniques must include information-heavy tasks to expose their true limits.
Where Pith is reading between the lines
- Offloading designs may require changes to selection and projection steps to support real applications that involve heavy context lookup.
- Applying the strategy at higher compression ratios or longer sequence lengths would test whether the gains remain stable.
- Landmark reliability should be treated as a first-order requirement in future offloading work instead of a secondary concern.
Load-bearing premise
Performance degradation on context-intensive tasks is caused primarily by low-rank key projections and unreliable landmarks rather than other factors in the offloading implementation.
What would settle it
Applying the simpler alternative strategy to Text2JSON and measuring no meaningful accuracy gain over the original offloading methods would falsify the central claim.
Figures






read the original abstract
With the growing demand for long-context LLMs across a wide range of applications, the key-value (KV) cache has become a critical bottleneck for both latency and memory usage. Recently, KV-cache offloading has emerged as a promising approach to reduce memory footprint and inference latency while preserving accuracy. Prior evaluations have largely focused on tasks that do not require extracting large amounts of information from the context. In this work, we study KV-cache offloading on context-intensive tasks: problems where the solution requires looking up a lot of information from the input prompt. We create and release the Text2JSON benchmark, a highly context-intensive task that requires extracting structured knowledge from raw text. We evaluate modern KV offloading on Text2JSON and other context-intensive tasks and find significant performance degradation on both Llama 3 and Qwen 3 models. Our analysis identifies two key reasons for poor accuracy: low-rank projection of keys and unreliable landmarks, and proposes a simpler alternative strategy that significantly improves accuracy across multiple LLM families and benchmarks. These findings highlight the need for a comprehensive and rigorous evaluation of long-context compression techniques.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Text2JSON benchmark for highly context-intensive tasks that require extracting structured information from long input text. It evaluates existing KV-cache offloading methods on Text2JSON and related tasks using Llama 3 and Qwen 3 models, reports substantial accuracy degradation relative to full-cache baselines, attributes the degradation primarily to low-rank key projections and unreliable landmarks, and proposes a simpler alternative offloading strategy that recovers accuracy across multiple LLM families and benchmarks.
Significance. If the empirical findings hold, the work is significant because it demonstrates that standard KV offloading techniques, which have been validated mainly on retrieval-light tasks, fail on information-extraction workloads and supplies both a new benchmark and a practical mitigation. The release of Text2JSON and the cross-model evaluation constitute reusable contributions for the long-context community.
major comments (2)
- [§4] §4 (Analysis of degradation causes): The attribution of accuracy loss to low-rank key projections and unreliable landmarks is not supported by isolating ablations. The reported comparisons are observational (different offloading pipelines versus full cache); no controlled experiments hold attention recomputation, eviction policy, quantization, and data movement fixed while varying only projection rank or landmark selection. Without such interventions it remains possible that the proposed simpler strategy improves results for unrelated reasons.
- [§5] §5 (Proposed alternative strategy): The claim that the simpler strategy 'significantly improves accuracy' is load-bearing for the central contribution, yet the manuscript provides no quantitative tables showing per-task deltas, error bars, or direct comparison against an ablated version that retains the original projection/landmark components. This prevents readers from verifying that the improvement specifically remedies the two identified factors.
minor comments (2)
- [Abstract] The abstract states clear findings but omits any numerical accuracy deltas or baseline names; adding one-sentence quantitative highlights would improve readability.
- [Tables] Table captions should explicitly state the number of runs and random seeds used for the reported accuracy figures.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our analysis and results presentation. We address the major comments below and have updated the manuscript with additional experiments and quantitative details to strengthen the claims.
read point-by-point responses
-
Referee: [§4] §4 (Analysis of degradation causes): The attribution of accuracy loss to low-rank key projections and unreliable landmarks is not supported by isolating ablations. The reported comparisons are observational (different offloading pipelines versus full cache); no controlled experiments hold attention recomputation, eviction policy, quantization, and data movement fixed while varying only projection rank or landmark selection. Without such interventions it remains possible that the proposed simpler strategy improves results for unrelated reasons.
Authors: We agree that the original §4 analysis relied on observational comparisons across full pipelines rather than fully isolated controls. In the revised manuscript we have added controlled ablation experiments that hold attention recomputation, eviction policy, quantization, and data movement fixed while varying only key projection rank and landmark selection. These new results, reported in an expanded §4, confirm that low-rank projections and unreliable landmarks are the dominant sources of degradation. The text has been updated to describe the experimental controls explicitly. revision: yes
-
Referee: [§5] §5 (Proposed alternative strategy): The claim that the simpler strategy 'significantly improves accuracy' is load-bearing for the central contribution, yet the manuscript provides no quantitative tables showing per-task deltas, error bars, or direct comparison against an ablated version that retains the original projection/landmark components. This prevents readers from verifying that the improvement specifically remedies the two identified factors.
Authors: We accept that the original presentation lacked the requested quantitative detail. The revised §5 now includes a table reporting per-task accuracy deltas with standard errors computed over multiple runs. We also added an ablation that applies the simpler strategy while retaining the original low-rank projections and landmark mechanisms; the gains are substantially smaller in this ablated setting, indicating that the improvements specifically address the two identified factors. These results are presented with direct comparisons to the full-cache baseline. revision: yes
Circularity Check
Empirical evaluation with no circular derivations or self-referential fits
full rationale
The paper is an empirical study that introduces the Text2JSON benchmark, evaluates KV offloading methods on context-intensive tasks, observes accuracy degradation on Llama 3 and Qwen 3, attributes it to low-rank key projections and unreliable landmarks via analysis, and proposes a simpler strategy with measured improvements. No equations, derivations, or parameter fits are described that reduce any result to a quantity defined inside the paper itself. The central claims rest on benchmark measurements and observational comparisons rather than self-definitional loops, fitted-input predictions, or load-bearing self-citation chains. This is a standard non-circular empirical evaluation.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
When Does Value-Aware KV Eviction Help? A Fixed-Contract Diagnostic for Non-Monotone Cache Compression
A fixed-contract probe shows value-aware KV eviction recovers needed evidence in 72.6% of accuracy-improving cases on LongBench but only 32.4% otherwise, suggesting an order of recover evidence, rank value, then prese...
Reference graph
Works this paper leans on
-
[1]
R. Y . Aminabadi, S. Rajbhandari, M. Zhang, A. A. Awan, C. Li, D. Li, E. Zheng, J. Rasley, S. Smith, O. Ruwase, and Y . He. Deepspeed inference: Enabling efficient inference of trans- former models at unprecedented scale. InSC22: International Conference for High Performance Computing, Networking, Storage and Analysis, 2022
work page 2022
-
[2]
S. Ananthanarayanan and A. Sengupta. Understanding the physics of key-value cache compres- sion for LLMs through attention dynamics.arXiv preprint arXiv:2603.01426, 2026
-
[3]
S. Ananthanarayanan, A. Sengupta, and T. Chakraborty. Understanding the physics of key-value cache compression for llms through attention dynamics, 2026
work page 2026
-
[4]
S. Ashkboos, A. Mohtashami, M. L. Croci, B. Li, P. Cameron, M. Jaggi, D. Alistarh, T. Hoefler, and J. Hensman. Quarot: Outlier-free 4-bit inference in rotated llms.Advances in Neural Information Processing Systems, 37:100213–100240, 2024
work page 2024
-
[5]
Y . Bai, X. Lv, J. Zhang, H. Lyu, J. Tang, Z. Huang, Z. Du, X. Liu, A. Zeng, L. Hou, Y . Dong, J. Tang, and J. Li. Longbench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024
work page 2024
-
[6]
O. Bianchi, M. J. Koretsky, M. Willey, C. X. Alvarado, T. Nayak, A. Asija, N. Kuznetsov, M. A. Nalls, F. Faghri, and D. Khashabi. Lost in the haystack: Smaller needles are more difficult for llms to find.arXiv preprint arXiv:2505.18148, abs/2505.18148, 2025
- [7]
-
[8]
A. Chen, R. Geh, A. Grover, G. V . den Broeck, and D. Israel. The pitfalls of kv cache compression, 2025
work page 2025
-
[9]
R. Chen, Z. Wang, B. Cao, T. Wu, S. Zheng, X. Li, X. Wei, S. Yan, M. Li, and Y . Liang. Arkvale: Efficient generative llm inference with recallable key-value eviction. InAdvances in Neural Information Processing Systems 37, 2024
work page 2024
-
[10]
Z. Chen, W. Chen, C. Smiley, S. Shah, I. Borova, D. Langdon, R. Moussa, M. Beane, T.-H. Huang, B. Routledge, and W. Y . Wang. Finqa: A dataset of numerical reasoning over financial data.Proceedings of EMNLP 2021, 2021
work page 2021
-
[11]
J. Dagdelen, A. Dunn, S. Lee, N. Walker, A. S. Rosen, G. Ceder, K. A. Persson, and A. Jain. Structured information extraction from scientific text with large language models.Nature Communications, 15(1):1418, 2024
work page 2024
-
[12]
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
V . Egiazarian, R. L. Castro, D. Kuznedelev, A. Panferov, E. Kurtic, S. Pandit, A. Marques, M. Kurtz, S. Ashkboos, T. Hoefler, and D. Alistarh. Bridging the gap between promise and performance for microscaling fp4 quantization, 2026
work page 2026
-
[14]
T. GLM, :, A. Zeng, B. Xu, B. Wang, C. Zhang, D. Yin, D. Zhang, D. Rojas, G. Feng, H. Zhao, H. Lai, H. Yu, H. Wang, J. Sun, J. Zhang, J. Cheng, J. Gui, J. Tang, J. Zhang, J. Sun, J. Li, L. Zhao, L. Wu, L. Zhong, M. Liu, M. Huang, P. Zhang, Q. Zheng, R. Lu, S. Duan, S. Zhang, S. Cao, S. Yang, W. L. Tam, W. Zhao, X. Liu, X. Xia, X. Zhang, X. Gu, X. Lv, X. L...
work page 2024
-
[15]
A. Hengle, P. Bajpai, S. Dan, and T. Chakraborty. Multilingual needle in a haystack: Investigat- ing long-context behavior of multilingual large language models. In L. Chiruzzo, A. Ritter, and L. Wang, editors,Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technolo...
work page 2025
- [16]
- [17]
- [18]
- [19]
-
[20]
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th Symposium on Operating Systems Principles, pages 611–626, 2023
work page 2023
-
[21]
W. Lee, J. Lee, J. Seo, and J. Sim. Infinigen: Efficient generative inference of large language models with dynamic kv cache management. InProceedings of the 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), 2024
work page 2024
-
[22]
D. Li, R. Shao, A. Xie, Y . Sheng, L. Zheng, J. Gonzalez, I. Stoica, X. Ma, and H. Zhang. How long can context length of open-source LLMs truly promise? InNeurIPS 2023 Workshop on Instruction Tuning and Instruction Following, 2023
work page 2023
-
[23]
J. Li, N. Farahini, E. Iuliugin, M. Vesterlund, C. Häggström, G. Wang, S. Upasani, A. Sachdeva, R. Li, F. Fu, C. Wu, A. Siddiqua, J. Long, T. Zhao, M. Musaddiq, H. Zeffer, Y . Du, M. Wang, Q. Li, B. Li, U. Thakker, and R. Prabhakar. Snapstream: Efficient long sequence decoding on dataflow accelerators, 2025
work page 2025
-
[24]
J. Li, M. Wang, Z. Zheng, and M. Zhang. Loogle: Can long-context language models understand long contexts?, 2024
work page 2024
-
[25]
J. Li, Z. Wang, Y . Zhang, S. Liu, M. Liu, X. Li, J. Chen, Y . Shen, Z. Zhang, Y . Guo, X. Chen, M. Zhao, T. Chen, I. Stoica, H. Chen, L. Chen, et al. SnapStream: Efficient long sequence decoding on dataflow accelerators.arXiv preprint arXiv:2511.03092, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
M. Li, S. Zhang, T. Zhang, H. Duan, Y . Liu, and K. Chen. Needlebench: Evaluating LLM retrieval and reasoning across varying information densities.Transactions on Machine Learning Research, 2025
work page 2025
-
[27]
Y . Li, Y . Huang, B. Yang, B. Venkitesh, A. Locatelli, H. Ye, T. Cai, P. Lewis, and D. Chen. Snapkv: Llm knows what you are looking for before generation. InAdvances in Neural Information Processing Systems 37, 2024
work page 2024
-
[28]
C. Lin, J. Tang, S. Yang, H. Wang, T. Tang, B. Tian, I. Stoica, S. Han, and M. Gao. Twilight: Adaptive attention sparsity with hierarchical top-ppruning, 2025
work page 2025
-
[29]
H. Lin, ZhiqiBai, X. Zhang, S. Yang, J. Wang, Y . Xu, J. Liu, Y . Zhao, X. Li, Y . Xu, W. Su, and B. Zheng. Reconstructing KV caches with cross-layer fusion for enhanced transformers. InThe Fourteenth International Conference on Learning Representations, 2026. 7
work page 2026
- [30]
- [31]
- [32]
-
[33]
Z. Liu, J. Yuan, H. Jin, S. Zhong, Z. Xu, V . Braverman, B. Chen, and X. Hu. Kivi: A tuning-free asymmetric 2bit quantization for kv cache. InProceedings of the 41st International Conference on Machine Learning, 2024
work page 2024
-
[34]
Q. Luo, Y . Ye, S. Liang, Z. Zhang, Y . Qin, Y . Lu, Y . Wu, X. Cong, Y . Lin, Y . Zhang, et al. Repoagent: An llm-powered open-source framework for repository-level code documentation generation. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 436–464, 2024
work page 2024
-
[35]
V . Malinovskii, A. Panferov, I. Ilin, H. Guo, P. Richtárik, and D. Alistarh. Pushing the limits of large language model quantization via the linearity theorem.arXiv preprint arXiv:2411.17525, 2024
-
[36]
P. Micikevicius, D. Stosic, N. Burgess, M. Cornea, P. Dubey, R. Grisenthwaite, S. Ha, A. Hei- necke, P. Judd, J. Kamalu, N. Mellempudi, S. Oberman, M. Shoeybi, M. Siu, and H. Wu. Fp8 formats for deep learning, 2022
work page 2022
-
[37]
NVIDIA. Nvidia, arm, and intel publish fp8 specification for standardiza- tion as an interchange format for ai. https://developer.nvidia.com/blog/ nvidia-arm-and-intel-publish-fp8-specification-for-standardization-as-an-interchange-format-for-ai/ , 2022
work page 2022
-
[38]
Optimizing inference for long context and large batch sizes with nvfp4 kv cache
NVIDIA. Optimizing inference for long context and large batch sizes with nvfp4 kv cache. https://developer.nvidia.com/blog/ optimizing-inference-for-long-context-and-large-batch-sizes-with-nvfp4-kv-cache/ , 2025
work page 2025
-
[39]
NVIDIA. Quantization. https://nvidia.github.io/TensorRT-LLM/features/ quantization.html, 2026. Accessed: 2026-04-08
work page 2026
-
[40]
Speed up inference with sota quantization techniques in tensorrt- llm
NVIDIA Corporation. Speed up inference with sota quantization techniques in tensorrt- llm. https://nvidia.github.io/TensorRT-LLM/blogs/quantization-in-TRT-LLM. html, 2026. Describes post-training quantization (FP8, INT8, INT4), performance/accuracy trade-offs, and KV-cache quantization in TensorRT-LLM. Accessed: 2026-04-08
work page 2026
-
[41]
L. Pekelis, M. Feil, F. Moret, M. Huang, and T. Peng. Llama 3 gra- dient: A series of long context models. https://gradient.ai/blog/ scaling-rotational-embeddings-for-long-context-language-models , 2024. Gradient AI blog post
work page 2024
- [42]
-
[43]
B. Peng, J. Quesnelle, H. Fan, and E. Shippole. YaRN: Efficient context window extension of large language models. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[44]
A. Qiao, Z. Yao, S. Rajbhandari, and Y . He. SwiftKV: Fast prefill-optimized inference with knowledge-preserving model transformation. In C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25734–25753, Suzhou, China, Nov. 2025. Association for ...
work page 2025
-
[45]
Y . Sheng, L. Zheng, B. Yuan, Z. Li, M. Ryabinin, D. Y . Fu, Z. Xie, B. Chen, C. Barrett, J. E. Gonzalez, P. Liang, C. Re, I. Stoica, and C. Zhang. Flexgen: High-throughput generative inference of large language models with a single gpu. InProceedings of the 40th International Conference on Machine Learning, 2023
work page 2023
-
[46]
M. Shi, T. Furon, and H. Jégou. A group testing framework for similarity search in high- dimensional spaces. InProceedings of the 22nd ACM International Conference on Multimedia, MM ’14, page 407–416, New York, NY , USA, 2014. Association for Computing Machinery
work page 2014
-
[47]
A. Shutova, V . Malinovskii, V . Egiazarian, D. Kuznedelev, D. Mazur, S. Nikita, I. Ermakov, and D. Alistarh. Cache me if you must: Adaptive key-value quantization for large language models. In A. Singh, M. Fazel, D. Hsu, S. Lacoste-Julien, F. Berkenkamp, T. Maharaj, K. Wagstaff, and J. Zhu, editors,Proceedings of the 42nd International Conference on Mach...
work page 2025
-
[48]
A. Shutova, V . Malinovskii, V . Egiazarian, D. Kuznedelev, D. Mazur, N. Surkov, I. Ermakov, and D. Alistarh. Cache me if you must: Adaptive key-value quantization for large language models.arXiv preprint arXiv:2501.19392, 2025
- [49]
-
[50]
J. Tang, Y . Zhao, K. Zhu, G. Xiao, B. Kasikci, and S. Han. Quest: Query-aware sparsity for efficient long-context llm inference. InProceedings of the 41st International Conference on Machine Learning, 2024
work page 2024
-
[51]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, and I. Polosukhin. Attention is all you need. In I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017
work page 2017
-
[52]
vLLM Project. Quantized KV cache. https://docs.vllm.ai/en/latest/features/ quantization/quantized_kvcache/, 2026. Accessed: 2026-04-08
work page 2026
-
[53]
vLLM Team. Quantized kv cache. https://docs.vllm.ai/en/latest/features/ quantization/quantized_kvcache/, 2026. Accessed: 2026-04-08
work page 2026
-
[54]
M. Wang, L. Chen, F. Cheng, S. Liao, X. Zhang, B. Wu, H. Yu, N. Xu, L. Zhang, R. Luo, et al. Leave no document behind: Benchmarking long-context llms with extended multi-doc qa. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 5627–5646, 2024
work page 2024
-
[55]
J. Wei, Z. Sun, S. Papay, S. McKinney, J. Han, I. Fulford, H. W. Chung, A. T. Passos, W. Fedus, and A. Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents, 2025
work page 2025
-
[56]
D. Wu, H. Wang, W. Yu, Y . Zhang, K.-W. Chang, and D. Yu. Longmemeval: Benchmarking chat assistants on long-term interactive memory.CoRR, 2024
work page 2024
-
[57]
Y . Wu, H. Wu, and K. Tu. A systematic study of cross-layer kv sharing for efficient llm inference, 2025
work page 2025
-
[58]
G. Xiao, Y . Tian, B. Chen, S. Han, and M. Lewis. Efficient streaming language models with attention sinks. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[59]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, M. Li, P. Zhang, P. Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T. ...
work page 2025
-
[60]
A. Yang, B. Yu, C. Li, D. Liu, F. Huang, H. Huang, J. Jiang, J. Tu, J. Zhang, J. Zhou, J. Lin, K. Dang, K. Yang, L. Yu, M. Li, M. Sun, Q. Zhu, R. Men, T. He, W. Xu, W. Yin, W. Yu, X. Qiu, X. Ren, X. Yang, Y . Li, Z. Xu, and Z. Zhang. Qwen2.5-1m technical report, 2025
work page 2025
- [61]
-
[62]
J. Yuan, H. Gao, D. Dai, J. Luo, L. Zhao, Z. Zhang, Z. Xie, Y . Wei, L. Wang, Z. Xiao, Y . Wang, C. Ruan, M. Zhang, W. Liang, and W. Zeng. Native sparse attention: Hardware-aligned and natively trainable sparse attention. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 23078–23097. A...
work page 2025
-
[63]
T. Yuan, X. Ning, D. Zhou, Z. Yang, S. Li, M. Zhuang, Z. Tan, Z. Yao, D. Lin, B. Li, G. Dai, S. Yan, and Y . Wang. LV-eval: A balanced long-context benchmark with 5 length levels up to 256k. InSecond Conference on Language Modeling, 2025
work page 2025
- [64]
-
[65]
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in Neural Information Processing Systems, 36:46595–46623, 2023
work page 2023
-
[66]
L. Zheng, L. Yin, Z. Xie, C. L. Sun, J. Huang, C. H. Yu, S. Cao, C. Kozyrakis, I. Stoica, J. E. Gonzalez, C. Barrett, and Y . Sheng. Sglang: Efficient execution of structured language model programs. InConference on Neural Information Processing Systems (NeurIPS), 2024. 10 A Preliminary Benchmark Exploration & Configurations Before our primary investigati...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.