Recognition: unknown
SUPERNOVA: Eliciting General Reasoning in LLMs with Reinforcement Learning on Natural Instructions
Pith reviewed 2026-05-10 17:12 UTC · model grok-4.3
The pith
Curating expert-annotated instruction data for verifiable rewards extends reinforcement learning to general reasoning tasks in language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SUPERNOVA shows that instruction-tuning datasets containing expert-annotated ground-truth encode reasoning patterns that can be adapted into high-quality verifiable rewards for RLVR. Source task selection proves non-trivial and matters more when done per target task than by overall average performance. Task mixing strategies and synthetic interventions for data quality also affect outcomes. Models trained on the resulting data surpass baselines including Qwen3.5 on challenging general reasoning benchmarks, achieving up to 52.8 percent relative improvement on BBEH.
What carries the argument
SUPERNOVA, a data curation framework that examines source task selection, task mixing strategies, and synthetic interventions to convert natural instructions into RLVR training data.
If this is right
- Source task selection tailored to individual target tasks yields better downstream results than selection based on average performance across tasks.
- Synthetic interventions improve the quality of adapted data for use in verifiable-reward training.
- Principled curation of human-annotated resources enables RLVR to address general reasoning skills beyond formal domains.
- Models trained under this approach deliver measurable gains on benchmarks requiring causal inference and temporal understanding.
- The 100-plus controlled experiments isolate the impact of data design choices from other training variables.
Where Pith is reading between the lines
- Similar curation principles could be tested on other human-annotated resources to extend RLVR into domains with sparse verifiable signals.
- The findings suggest that data design choices may interact with model scale in ways that warrant separate scaling experiments.
- Automated versions of the per-target task selection process could reduce the manual effort needed to apply the framework.
- The work implies that future RLVR pipelines might benefit from hybrid human-synthetic data pipelines rather than purely synthetic generation.
- Extensions might explore whether the same curation logic applies when the base model has already undergone extensive instruction tuning.
Load-bearing premise
That expert-annotated instruction datasets contain reasoning patterns that can be reliably converted into verifiable reward signals without losing their effectiveness for general tasks.
What would settle it
Training models on SUPERNOVA-curated data and measuring no outperformance or even underperformance relative to baselines on BBEH, Zebralogic, and MMLU-Pro would falsify the central effectiveness claim.
Figures







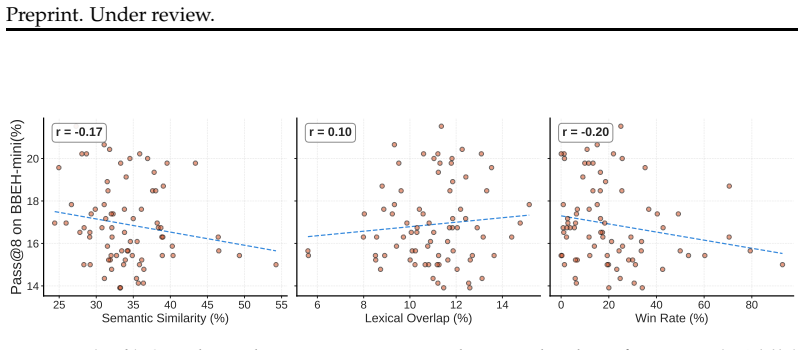
read the original abstract
Reinforcement Learning with Verifiable Rewards (RLVR) has significantly improved large language model (LLM) reasoning in formal domains such as mathematics and code. Despite these advancements, LLMs still struggle with general reasoning tasks requiring capabilities such as causal inference and temporal understanding. Extending RLVR to general reasoning is fundamentally constrained by the lack of high-quality, verifiable training data that spans diverse reasoning skills. To address this challenge, we propose SUPERNOVA, a data curation framework for RLVR aimed at enhancing general reasoning. Our key insight is that instruction-tuning datasets containing expert-annotated ground-truth encode rich reasoning patterns that can be systematically adapted for RLVR. To study this, we conduct 100+ controlled RL experiments to analyze how data design choices impact downstream reasoning performance. In particular, we investigate three key factors: (i) source task selection, (ii) task mixing strategies, and (iii) synthetic interventions for improving data quality. Our analysis reveals that source task selection is non-trivial and has a significant impact on downstream reasoning performance. Moreover, selecting tasks based on their performance for individual target tasks outperforms strategies based on overall average performance. Finally, models trained on SUPERNOVA outperform strong baselines (e.g., Qwen3.5) on challenging reasoning benchmarks including BBEH, Zebralogic, and MMLU-Pro. In particular, training on SUPERNOVA yields relative improvements of up to 52.8\% on BBEH across model sizes, demonstrating the effectiveness of principled data curation for RLVR. Our findings provide practical insights for curating human-annotated resources to extend RLVR to general reasoning. The code and data is available at https://github.com/asuvarna31/supernova.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SUPERNOVA, a data curation framework that adapts expert-annotated instruction-tuning datasets into verifiable rewards for RLVR to elicit general reasoning capabilities (causal inference, temporal understanding) in LLMs. It reports results from over 100 controlled RL experiments examining source task selection, task mixing strategies, and synthetic interventions, concluding that per-target performance-based task selection outperforms average-performance selection and that SUPERNOVA-trained models achieve relative gains of up to 52.8% on BBEH (plus improvements on Zebralogic and MMLU-Pro) over strong baselines such as Qwen3.5.
Significance. If the reported gains prove robust under full experimental controls, the work would offer concrete, actionable guidance for extending RLVR from formal domains to general reasoning by leveraging existing human-annotated resources, with the open-sourced code and data providing a useful starting point for the community.
major comments (3)
- [Experimental section] Experimental section (description of the 100+ RL runs): the manuscript states that experiments are 'controlled' and isolate the effects of source task selection, mixing, and synthetic interventions, yet supplies no complete hyperparameter table, multi-seed variance statistics, or explicit verification that reward functions (exact match vs. LLM judge) and other non-data variables remained identical across all compared configurations. Without these, performance deltas cannot be confidently attributed to the three studied factors.
- [Results on BBEH] Results on BBEH (and related benchmark tables): the headline relative improvement of up to 52.8% is presented without accompanying statistical significance tests, standard-error bars, or precise baseline implementation details (e.g., whether Qwen3.5 was instruction-tuned with the same RLVR setup or merely prompted). This leaves open the possibility that gains arise from unaccounted confounds rather than the proposed data-curation principles.
- [Task-selection ablation] Task-selection ablation: the claim that 'selecting tasks based on their performance for individual target tasks outperforms strategies based on overall average performance' requires clarification on how per-target performance was measured (on which split, with which metric) and whether selection was performed on held-out data to prevent leakage into the final evaluation.
minor comments (2)
- [Abstract] Abstract: the acronym RLVR is used before its expansion ('Reinforcement Learning with Verifiable Rewards') is given; a parenthetical expansion on first use would improve readability.
- [Data-curation description] Data-curation description: the precise mapping from expert-annotated ground-truth answers to automatic verifiable reward functions is described at a high level; a short pseudocode or explicit example for one task type would clarify how 'rich reasoning patterns' are preserved versus introducing shortcuts.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments highlight important aspects of experimental rigor and clarity that we will address in the revision. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Experimental section] Experimental section (description of the 100+ RL runs): the manuscript states that experiments are 'controlled' and isolate the effects of source task selection, mixing, and synthetic interventions, yet supplies no complete hyperparameter table, multi-seed variance statistics, or explicit verification that reward functions (exact match vs. LLM judge) and other non-data variables remained identical across all compared configurations. Without these, performance deltas cannot be confidently attributed to the three studied factors.
Authors: We agree that additional documentation will strengthen the experimental section. In the revised manuscript we will add a complete hyperparameter table in the appendix covering all RL runs. All original experiments used a fixed random seed for reproducibility; we will also report variance statistics from a subset of multi-seed replications (three seeds) for the key configurations. We will insert explicit statements confirming that reward functions (exact match versus LLM judge) and all non-data variables were held identical across compared runs, consistent with the controlled design described in the paper. These additions will make the attribution of performance differences to the studied factors fully transparent. revision: partial
-
Referee: [Results on BBEH] Results on BBEH (and related benchmark tables): the headline relative improvement of up to 52.8% is presented without accompanying statistical significance tests, standard-error bars, or precise baseline implementation details (e.g., whether Qwen3.5 was instruction-tuned with the same RLVR setup or merely prompted). This leaves open the possibility that gains arise from unaccounted confounds rather than the proposed data-curation principles.
Authors: We will strengthen the results presentation by adding standard-error bars and statistical significance tests (paired t-tests across seeds) to the BBEH and related benchmark tables. For the baseline, Qwen3.5 was trained with the identical RLVR procedure and hyperparameters as the SUPERNOVA models (not merely prompted); we will clarify this explicitly in the text and provide the corresponding implementation details. These revisions will reduce the possibility of unaccounted confounds and allow readers to assess the robustness of the reported relative gains. revision: yes
-
Referee: [Task-selection ablation] Task-selection ablation: the claim that 'selecting tasks based on their performance for individual target tasks outperforms strategies based on overall average performance' requires clarification on how per-target performance was measured (on which split, with which metric) and whether selection was performed on held-out data to prevent leakage into the final evaluation.
Authors: We will expand the task-selection ablation section to provide the requested details. Per-target performance was measured on a held-out validation split (separate from all test benchmarks) using exact-match accuracy as the metric. Task selection was performed exclusively on this validation split before any final evaluation, thereby preventing leakage. The revised text will include the exact split sizes, the validation metric, and the full selection procedure to make the ablation fully reproducible and free of data leakage concerns. revision: yes
Circularity Check
No circularity: purely empirical results from controlled experiments
full rationale
The paper reports outcomes from 100+ RL training runs on curated instruction data, with performance measured on external benchmarks (BBEH, Zebralogic, MMLU-Pro). No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided text. Claims rest on direct experimental deltas rather than any derivation that reduces to its own inputs by construction. This is self-contained empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Instruction-tuning datasets containing expert-annotated ground-truth encode rich reasoning patterns that can be systematically adapted for RLVR
Reference graph
Works this paper leans on
-
[2]
URLhttps://arxiv.org/abs/2504.01943. Syeda Nahida Akter, Shrimai Prabhumoye, Matvei Novikov, Seungju Han, Ying Lin, Evelina Bakhturina, Eric Nyberg, Yejin Choi, Mostofa Patwary, Mohammad Shoeybi, et al. Nemotron-crossthink: Scaling self-learning beyond math reasoning. InProceedings of the 19th Conference of the European Chapter of the Association for Comp...
-
[3]
Honeybee: Data recipes for vision-language reasoners.arXiv preprint arXiv:2510.12225,
Hritik Bansal, Devandra Singh Sachan, Kai-Wei Chang, Aditya Grover, Gargi Ghosh, Wen- tau Yih, and Ramakanth Pasunuru. Honeybee: Data recipes for vision-language reasoners. arXiv preprint arXiv:2510.12225,
-
[4]
URLhttps://arxiv.org/abs/2509.20357. Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evalu- ating large language models trained on code.arXiv preprint arXiv:2107.03374,
-
[5]
Yang Chen, Zhuolin Yang, Zihan Liu, Chankyu Lee, Peng Xu, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. Acereason-nemotron: Advancing math and code reasoning through reinforcement learning.arXiv preprint arXiv:2505.16400,
-
[6]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
OpenThoughts: Data Recipes for Reasoning Models
Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, et al. Openthoughts: Data recipes for reasoning models.arXiv preprint arXiv:2506.04178,
work page internal anchor Pith review arXiv
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Measuring Mathematical Problem Solving With the MATH Dataset
URLhttps://arxiv.org/abs/2103.03874. Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xiangyu Zhang, and Heung-Yeung Shum. Open-reasoner-zero: An open source approach to scaling up reinforcement learn- ing on the base model.arXiv preprint arXiv:2503.24290,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
URL https://arxiv. org/abs/2507.00432. 10 Preprint. Under review. Hugging Face. Open r1: A fully open reproduction of deepseek-r1, January
-
[11]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, et al. Tulu 3: Pushing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124,
work page internal anchor Pith review arXiv
-
[12]
Zebralogic: On the scaling limits of llms for logical reasoning
Bill Yuchen Lin, Ronan Le Bras, Kyle Richardson, Ashish Sabharwal, Radha Poovendran, Peter Clark, and Yejin Choi. Zebralogic: On the scaling limits of llms for logical reasoning. arXiv preprint arXiv:2502.01100,
-
[13]
Synlogic: Synthesizing verifiable reasoning data at scale for learning logical reasoning and beyond
URLhttps://arxiv.org/abs/2505.19641. Yang Liu, Jiaqi Li, and Zilong Zheng. Rulereasoner: Reinforced rule-based reasoning via domain-aware dynamic sampling,
-
[14]
URLhttps://arxiv.org/abs/2506.08672. Ximing Lu, David Acuna, Jaehun Jung, Jian Hu, Di Zhang, Shizhe Diao, Yunheng Zou, Shaokun Zhang, Brandon Cui, Mingjie Liu, Hyunwoo Kim, Prithviraj Ammanabrolu, Jan Kautz, Yi Dong, and Yejin Choi. Golden goose: A simple trick to synthesize unlimited rlvr tasks from unverifiable internet text,
-
[15]
Xueguang Ma, Qian Liu, Dongfu Jiang, Ge Zhang, Zejun Ma, and Wenhu Chen
URLhttps://arxiv.org/abs/2601.22975. Xueguang Ma, Qian Liu, Dongfu Jiang, Ge Zhang, Zejun Ma, and Wenhu Chen. General- reasoner: Advancing llm reasoning across all domains.arXiv preprint arXiv:2505.14652,
-
[16]
s1: Simple test-time scaling
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori B Hashimoto. s1: Simple test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 20286–20332,
2025
-
[17]
arXiv preprint arXiv:2512.13961,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Challenging big- bench tasks and whether chain-of-thought can solve them
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc Le, Ed Chi, Denny Zhou, et al. Challenging big- bench tasks and whether chain-of-thought can solve them. InFindings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051,
2023
-
[20]
Under review
11 Preprint. Under review. Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Atharva Naik, Arjun Ashok, Arut Selvan Dhanasekaran, Anjana Arunkumar, David Stap, et al. Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks. InProceedings of the 2022 conference on empirical methods in n...
2022
-
[21]
Finetuned Language Models Are Zero-Shot Learners
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652,
work page internal anchor Pith review arXiv
-
[22]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
arXiv preprint arXiv:2502.03387 , year=
Yixin Ye, Zhen Huang, Yang Xiao, Ethan Chern, Shijie Xia, and Pengfei Liu. Limo: Less is more for reasoning.arXiv preprint arXiv:2502.03387,
-
[24]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?arXiv preprint arXiv:2504.13837,
work page internal anchor Pith review arXiv
-
[26]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild.arXiv preprint arXiv:2503.18892,
work page internal anchor Pith review arXiv
-
[27]
Instruction tuning for large language models: A survey
URLhttps://arxiv.org/abs/2308.10792. Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2024.https://huggingface.co/datasets/math-ai/aime24,
-
[28]
arXiv preprint arXiv:2503.19633 , year=
Han Zhao, Haotian Wang, Yiping Peng, Sitong Zhao, Xiaoyu Tian, Shuaiting Chen, Yunjie Ji, and Xiangang Li. 1.4 million open-source distilled reasoning dataset to empower large language model training.arXiv preprint arXiv:2503.19633,
-
[29]
URLhttps://arxiv.org/abs/2507.04391. 12 Preprint. Under review. A Related Work A.1 General-Purpose Reasoning in LLMs Several works have explored expanding the general reasoning capabilities of LLMs. Ma et al. (2025) constructs a large-scale dataset spanning multiple domains such as history, finance, and physics from web-scraped sources. Akter et al. (2026...
-
[30]
and logic puzzles (Liu et al., 2025). While effective for specialized reasoning, these approaches rely on highly curated logic and rule-based datasets that are challenging to scale and cover a limited range of reasoning types. In contrast, SUPERNOVAleverages instruction-tuning datasets, which are human-annotated and generally of higher quality than raw in...
2025
-
[31]
On the other hand, (Muennighoff et al., 2025; Ye et al.,
and RLVR (Chen et al., 2025; Hu et al., 2025), typically by scraping competition websites or distilling knowledge from larger models. On the other hand, (Muennighoff et al., 2025; Ye et al.,
2025
-
[32]
The answer i s
demonstrate that carefully curated, high-quality reasoning datasets can yield strong gains even with relatively small datasets. Guha et al. (2025) systemat- ically studies data design principles for SFT reasoning data at scale through controlled experiments, in a manner similar to SUPERNOVA. However, these efforts primarily focus on reasoning in formal do...
2025
-
[33]
We run our training for 250 steps (1 epoch). For our large scale experiments, we run 5000 steps (1 epoch) across 10,000 prompts and use a learning rate of 1e-6 for 0.6B models and 4e-6 for 1.7B and 4B models. B.3 Evaluation For our evaluations, we use the following prompt across all benchmarks Think step by step, and when you are ready to provide the fina...
-
[34]
We observe that SUPERNOVAis able to improve on tasks like Hyperbaton, Multi-step Arithmetic and Shuffling Objects where the base model has near zero performance
We observe negligible gains on 7 out of the 23 sub-tasks. We observe that SUPERNOVAis able to improve on tasks like Hyperbaton, Multi-step Arithmetic and Shuffling Objects where the base model has near zero performance. E Pass@k Analysis Following Chen et al. (2021) and Yue et al. (2025), we analyze the pass@k curves of our task- specific models. Across 8...
2021
-
[35]
F Task Analysis We prompt an LLM (Claude-Opus-4.6) with the task descriptions from each task and gener- ate coarse category labels. We find that Multi-hop Reasoning and Coreference resolution emerge as the strongest categories, while narrative and surface-formatting tasks (e.g., Story Coherence, Date/Temporal format) consistently underperform (Figure 7). ...
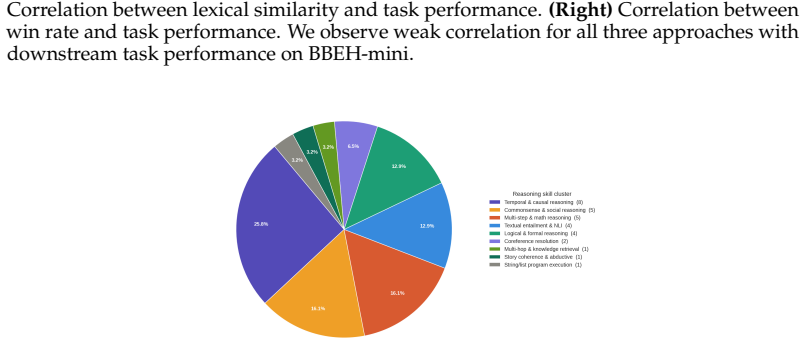
2025
-
[36]
original_problem
and prompt GPT-5-mini with G. Since, we want to preserve the ground-truth answer, we apply these interventions only to the problem statement. Finally, to ensure the that the final answer is preserved, filter the augmented data with based on win-rate computed again with the augmented problem statements. In our experiments, we combine the original data and ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.