Recognition: no theorem link
Novel View Synthesis as Video Completion
Pith reviewed 2026-05-10 18:21 UTC · model grok-4.3
The pith
Video diffusion models can be adapted for sparse novel view synthesis by reformulating it as low frame-rate video completion and removing temporal order cues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Sparse novel view synthesis reduces to low frame-rate video completion once video diffusion models are modified to become invariant to input ordering; the modifications consist of per-frame latent encodings plus removal of temporal positional embeddings, after which the models can be fine-tuned with minimal supervision to produce competitive results on standard sparse-view benchmarks.
What carries the argument
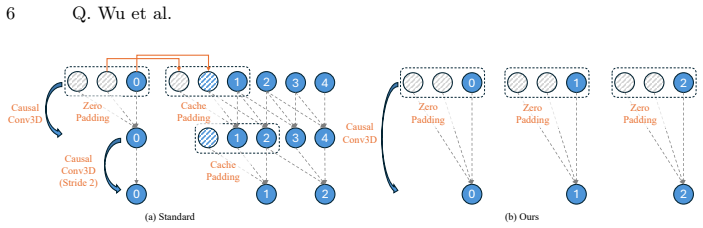
FrameCrafter, the adapted video diffusion architecture that uses per-frame latent encodings and drops temporal positional embeddings to enforce permutation invariance on unordered input sets.
If this is right
- Video models contain implicit multi-view geometric knowledge that survives the removal of temporal positional embeddings.
- Only minimal supervision is needed to train such models to ignore frame ordering while still producing coherent novel views.
- Sparse-view NVS performance becomes competitive with methods that rely on single-image generative priors.
- The same adaptation pattern may allow other video-trained models to handle unordered multi-view tasks without explicit 3D supervision.
Where Pith is reading between the lines
- The same removal of temporal embeddings could be tested on other tasks that require set-like rather than sequential inputs, such as unordered image sets for 3D reconstruction.
- If the approach scales, it suggests that future multi-view generators might be derived from video pre-training rather than image pre-training, changing data collection priorities.
- One could measure how much geometric consistency is retained purely by the diffusion prior versus how much is added during the light fine-tuning stage.
Load-bearing premise
Video diffusion models already encode usable multi-view geometric knowledge from their original training that survives the removal of temporal cues and can be activated by light fine-tuning on sparse inputs.
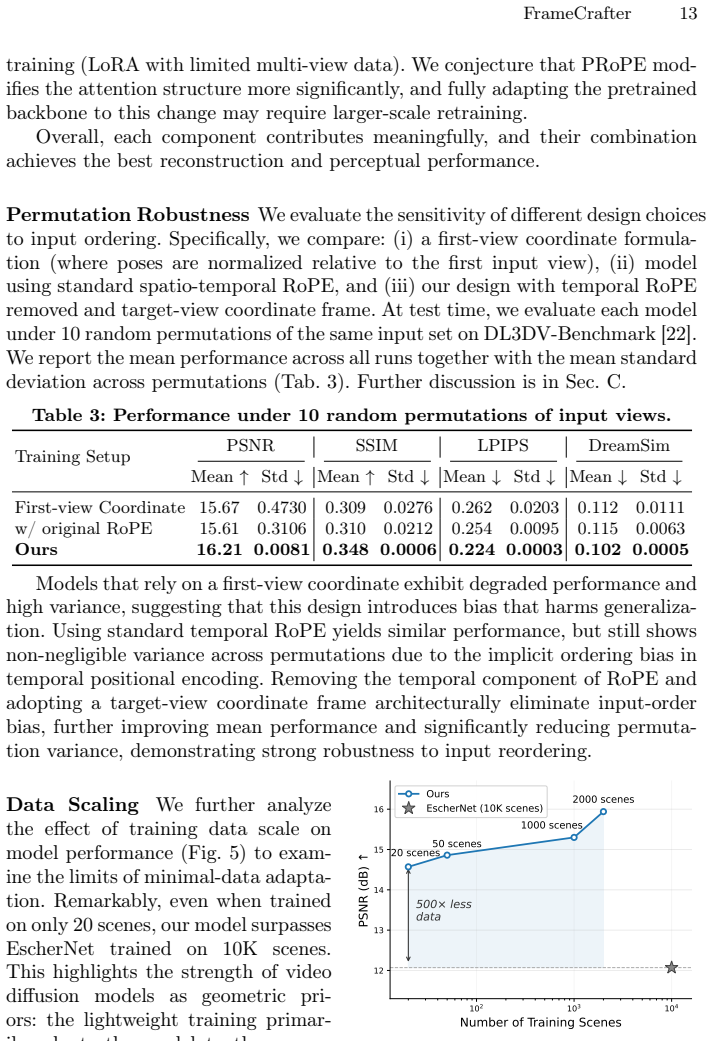
What would settle it
Train a video diffusion model on the described modifications and fine-tuning regime, then check whether the generated target views remain geometrically consistent with the provided camera poses when the input images are presented in random order; failure of consistency across random permutations would falsify the claim.
Figures




read the original abstract
We tackle the problem of sparse novel view synthesis (NVS) using video diffusion models; given $K$ ($\approx 5$) multi-view images of a scene and their camera poses, we predict the view from a target camera pose. Many prior approaches leverage generative image priors encoded via diffusion models. However, models trained on single images lack multi-view knowledge. We instead argue that video models already contain implicit multi-view knowledge and so should be easier to adapt for NVS. Our key insight is to formulate sparse NVS as a low frame-rate video completion task. However, one challenge is that sparse NVS is defined over an unordered set of inputs, often too sparse to admit a meaningful order, so the models should be $\textit{invariant}$ to permutations of that input set. To this end, we present FrameCrafter, which adapts video models (naturally trained with coherent frame orderings) to permutation-invariant NVS through several architectural modifications, including per-frame latent encodings and removal of temporal positional embeddings. Our results suggest that video models can be easily trained to "forget" about time with minimal supervision, producing competitive performance on sparse-view NVS benchmarks. Project page: https://frame-crafter.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FrameCrafter, an adaptation of video diffusion models for sparse novel view synthesis (NVS). It reformulates the task as low frame-rate video completion given K≈5 unordered input views and their camera poses, with the goal of predicting a target view. Architectural changes include per-frame latent encodings and removal of temporal positional embeddings to achieve permutation invariance, allowing the model to 'forget' about time. The central claim is that video models already encode implicit multi-view knowledge and can be adapted with minimal supervision to achieve competitive results on sparse-view NVS benchmarks.
Significance. If the empirical claims hold, the work is significant because it offers a new perspective on leveraging video generative priors for multi-view geometry tasks rather than relying solely on single-image diffusion models. The reformulation as video completion and the focus on minimal supervision are strengths. Credit is due for the explicit handling of unordered inputs via the described modifications, which could influence future work on adapting temporal models to set-based tasks in computer vision.
major comments (2)
- [Method (description of per-frame encodings and temporal embedding removal)] The central claim of permutation invariance (and thus successful 'forgetting' of time) rests on the modifications in the FrameCrafter architecture. However, video diffusion backbones typically retain 3D convolutions, temporal attention layers, or frame-wise processing that can retain residual order dependence even after temporal positional embeddings are removed. No experiment is reported that feeds the same K views in different orders and verifies identical outputs. This directly affects whether the competitive benchmark performance can be attributed to implicit multi-view knowledge rather than order artifacts.
- [Abstract and Experiments section] The abstract asserts 'competitive performance on sparse-view NVS benchmarks' but the provided text contains no quantitative numbers, specific baselines, ablation tables, or error metrics. Without these details (presumably in §4), the strength of the empirical support for the central claim cannot be assessed. Please add explicit comparisons to prior NVS methods and ablations on the invariance modifications.
minor comments (2)
- [Method] Clarify how the target camera pose is encoded and injected into the model, as this is central to the NVS formulation but not detailed in the abstract.
- [Experiments] Ensure all figures showing qualitative results include the input views, target pose, and ground truth for direct comparison.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments. We address each major comment point by point below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method (description of per-frame encodings and temporal embedding removal)] The central claim of permutation invariance (and thus successful 'forgetting' of time) rests on the modifications in the FrameCrafter architecture. However, video diffusion backbones typically retain 3D convolutions, temporal attention layers, or frame-wise processing that can retain residual order dependence even after temporal positional embeddings are removed. No experiment is reported that feeds the same K views in different orders and verifies identical outputs. This directly affects whether the competitive benchmark performance can be attributed to implicit multi-view knowledge rather than order artifacts.
Authors: We agree that an explicit empirical verification of permutation invariance is valuable and would strengthen the central claim. While the per-frame latent encodings and removal of temporal positional embeddings are specifically designed to eliminate order cues (allowing the model to process inputs as an unordered set), we acknowledge that residual dependencies could potentially remain in other backbone components such as 3D convolutions or attention layers. In the revised manuscript, we will add a dedicated experiment that feeds identical sets of K input views in multiple random permutations and quantifies output consistency (e.g., via PSNR, SSIM, and LPIPS between the resulting target views). This will provide direct evidence that performance arises from implicit multi-view knowledge rather than order artifacts. revision: yes
-
Referee: [Abstract and Experiments section] The abstract asserts 'competitive performance on sparse-view NVS benchmarks' but the provided text contains no quantitative numbers, specific baselines, ablation tables, or error metrics. Without these details (presumably in §4), the strength of the empirical support for the central claim cannot be assessed. Please add explicit comparisons to prior NVS methods and ablations on the invariance modifications.
Authors: The full manuscript contains quantitative results and comparisons in Section 4, including evaluations on standard sparse-view NVS benchmarks (DTU and RealEstate10K), direct comparisons against prior methods (e.g., single-image diffusion baselines and dedicated NVS approaches), ablation studies isolating the effects of the per-frame encoding and temporal embedding removal, and standard error metrics (PSNR, SSIM, LPIPS). The abstract summarizes these findings at a high level without numbers, which is conventional for brevity. To make the empirical support more immediately accessible, we will revise the abstract to include a brief mention of key quantitative highlights and ensure the experiments section features clearly labeled tables for all baselines and ablations. revision: yes
Circularity Check
Empirical adaptation of video models for NVS is self-contained with no circular derivation
full rationale
The paper proposes treating sparse NVS as low frame-rate video completion and adapts video diffusion models via per-frame latent encodings plus removal of temporal positional embeddings to enforce permutation invariance. Effectiveness is measured by performance on external benchmarks rather than by any internal loss or fitted quantity. No equations, predictions, or uniqueness claims reduce to the method's own inputs by construction. The approach is presented as a practical architectural modification whose validity is established empirically, not definitionally or via self-citation chains.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Video diffusion models trained on coherent frame sequences already encode implicit multi-view geometric knowledge.
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Bai,J., Xia, M., Fu, X.,Wang, X.,Mu, L., Cao, J.,Liu, Z., Hu, H., Bai, X., Wan, P., et al.: Recammaster: Camera-controlled generative rendering from a single video. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 14834–14844 (2025)
2025
-
[2]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Barron, J.T., Mildenhall, B., Verbin, D., Srinivasan, P.P., Hedman, P.: Mip- nerf 360: Unbounded anti-aliased neural radiance fields. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5470–5479 (2022)
2022
-
[3]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023)
work page internal anchor Pith review arXiv 2023
-
[4]
Brooks, T., Peebles, B., Holmes, C., DePue, W., Guo, Y., Jing, L., Schnurr, D., Taylor, J., Luhman, T., Luhman, E., et al.: Video generation models as world simulators. 2024. URL https://openai. com/research/video-generation-models-as- world-simulators3(1), 3 (2024)
2024
-
[5]
In: Proceedings of the IEEE/CVF international conference on computer vision
Chen, A., Xu, Z., Zhao, F., Zhang, X., Xiang, F., Yu, J., Su, H.: Mvsnerf: Fast generalizable radiance field reconstruction from multi-view stereo. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 14124–14133 (2021)
2021
-
[6]
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
Chen, H., Xia, M., He, Y., Zhang, Y., Cun, X., Yang, S., Xing, J., Liu, Y., Chen, Q., Wang, X., et al.: Videocrafter1: Open diffusion models for high-quality video generation. arXiv preprint arXiv:2310.19512 (2023)
work page internal anchor Pith review arXiv 2023
-
[7]
arXiv preprint arXiv:2507.12646 (2025)
Chen, K., Khurana, T., Ramanan, D.: Reconstruct, inpaint, test-time fine- tune: Dynamic novel-view synthesis from monocular videos. arXiv preprint arXiv:2507.12646 (2025)
-
[8]
Advances in Neural Information Processing Systems36, 35799–35813 (2023)
Deitke, M., Liu, R., Wallingford, M., Ngo, H., Michel, O., Kusupati, A., Fan, A., Laforte, C., Voleti, V., Gadre, S.Y., et al.: Objaverse-xl: A universe of 10m+ 3d objects. Advances in Neural Information Processing Systems36, 35799–35813 (2023)
2023
-
[9]
Fu,S.,Tamir,N.,Sundaram,S.,Chai,L.,Zhang,R.,Dekel,T.,Isola,P.:Dreamsim: Learning new dimensions of human visual similarity using synthetic data. arXiv preprint arXiv:2306.09344 (2023) 16 Q. Wu et al
-
[10]
Cat3d: Create any- thing in 3d with multi-view diffusion models,
Gao, R., Holynski, A., Henzler, P., Brussee, A., Martin-Brualla, R., Srinivasan, P., Barron, J.T., Poole, B.: Cat3d: Create anything in 3d with multi-view diffusion models. arXiv preprint arXiv:2405.10314 (2024)
-
[11]
He, H., Xu, Y., Guo, Y., Wetzstein, G., Dai, B., Li, H., Yang, C.: Cameractrl: En- ablingcameracontrolfortext-to-videogeneration.arXivpreprintarXiv:2404.02101 (2024)
work page internal anchor Pith review arXiv 2024
-
[12]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[13]
Iclr1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. Iclr1(2), 3 (2022)
2022
- [14]
-
[15]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Jiang, H., Tan, H., Wang, P., Jin, H., Zhao, Y., Bi, S., Zhang, K., Luan, F., Sunkavalli, K., Huang, Q., et al.: Rayzer: A self-supervised large view synthesis model. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4918–4929 (2025)
2025
-
[16]
Jiang, Z., Zheng, C., Laina, I., Larlus, D., Vedaldi, A.: Geo4d: Leveraging video generatorsforgeometric4dscenereconstruction.In:ProceedingsoftheIEEE/CVF International Conference on Computer Vision. pp. 20658–20671 (2025)
2025
-
[17]
Jin, H., Jiang, H., Tan, H., Zhang, K., Bi, S., Zhang, T., Luan, F., Snavely, N., Xu, Z.: Lvsm: A large view synthesis model with minimal 3d inductive bias. arXiv preprint arXiv:2410.17242 (2024)
-
[18]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G., et al.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023)
2023
-
[19]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al.: Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Kong,X.,Liu,S.,Lyu,X.,Taher,M.,Qi,X.,Davison,A.J.:Eschernet:Agenerative model for scalable view synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9503–9513 (2024)
2024
-
[21]
Cameras as relative positional encoding, 2025
Li, R., Yi, B., Liu, J., Gao, H., Ma, Y., Kanazawa, A.: Cameras as relative posi- tional encoding. arXiv preprint arXiv:2507.10496 (2025)
-
[22]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ling, L., Sheng, Y., Tu, Z., Zhao, W., Xin, C., Wan, K., Yu, L., Guo, Q., Yu, Z., Lu, Y., et al.: Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22160–22169 (2024)
2024
-
[23]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
In: Proceedings of the IEEE/CVF inter- national conference on computer vision
Liu, R., Wu, R., Van Hoorick, B., Tokmakov, P., Zakharov, S., Vondrick, C.: Zero- 1-to-3: Zero-shot one image to 3d object. In: Proceedings of the IEEE/CVF inter- national conference on computer vision. pp. 9298–9309 (2023)
2023
-
[25]
arXiv preprint arXiv:2309.03453 , year=
Liu, Y., Lin, C., Zeng, Z., Long, X., Liu, L., Komura, T., Wang, W.: Syncdreamer: Generating multiview-consistent images from a single-view image. arXiv preprint arXiv:2309.03453 (2023)
-
[26]
Commu- nications of the ACM65(1), 99–106 (2021)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Commu- nications of the ACM65(1), 99–106 (2021)
2021
-
[27]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Niemeyer, M., Barron, J.T., Mildenhall, B., Sajjadi, M.S., Geiger, A., Radwan, N.: Regnerf: Regularizing neural radiance fields for view synthesis from sparse in- puts. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5480–5490 (2022) FrameCrafter 17
2022
-
[28]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[29]
on a new geometry of space
Plucker, J.: Xvii. on a new geometry of space. Philosophical Transactions of the Royal Society of London (155), 725–791 (1865)
-
[30]
In: Proceedings of the IEEE/CVF international conference on computer vision
Reizenstein, J., Shapovalov, R., Henzler, P., Sbordone, L., Labatut, P., Novotny, D.: Common objects in 3d: Large-scale learning and evaluation of real-life 3d cat- egory reconstruction. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 10901–10911 (2021)
2021
-
[31]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ren,X.,Shen,T.,Huang,J.,Ling,H.,Lu,Y.,Nimier-David,M.,Müller,T.,Keller, A., Fidler, S., Gao, J.: Gen3c: 3d-informed world-consistent video generation with precise camera control. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6121–6132 (2025)
2025
-
[32]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Sargent, K., Li, Z., Shah, T., Herrmann, C., Yu, H.X., Zhang, Y., Chan, E.R., Lagun, D., Fei-Fei, L., Sun, D., et al.: Zeronvs: Zero-shot 360-degree view synthesis from a single image. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9420–9429 (2024)
2024
-
[34]
arXiv preprint arXiv:2310.15110 , year=
Shi, R., Chen, H., Zhang, Z., Liu, M., Xu, C., Wei, X., Chen, L., Zeng, C., Su, H.: Zero123++: a single image to consistent multi-view diffusion base model. arXiv preprint arXiv:2310.15110 (2023)
-
[35]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Shi, W., Caballero, J., Huszár, F., Totz, J., Aitken, A.P., Bishop, R., Rueckert, D., Wang, Z.: Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1874–1883 (2016)
2016
-
[36]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[37]
Neurocomputing568, 127063 (2024)
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., Liu, Y.: Roformer: Enhanced trans- former with rotary position embedding. Neurocomputing568, 127063 (2024)
2024
-
[38]
arXiv preprint arXiv:2601.16982 (2026)
Van Hoorick, B., Chen, D., Iwase, S., Tokmakov, P., Irshad, M.Z., Vasiljevic, I., Gupta, S., Cheng, F., Zakharov, S., Guizilini, V.C.: Anyview: Synthesizing any novel view in dynamic scenes. arXiv preprint arXiv:2601.16982 (2026)
-
[39]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., Wang, J., Zhang, J., Zhou, J., Wang, J., Chen, J., Zhu, K., Zhao, K., Yan, K., Huang, L., Feng, M., Zhang, N., Li, P., Wu, P., Chu, R., Feng, R., Zhang, S., Sun, S., Fang, T., Wang, T., Gui, T., Weng, T., Shen, T., Lin, W., Wang, W., Wang, W., Zhou, W.,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5294–5306 (2025)
2025
-
[41]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, Q., Wang, Z., Genova, K., Srinivasan, P.P., Zhou, H., Barron, J.T., Martin- Brualla, R., Snavely, N., Funkhouser, T.: Ibrnet: Learning multi-view image-based rendering. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4690–4699 (2021) 18 Q. Wu et al
2021
-
[42]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: Dust3r: Geometric 3d vision made easy. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 20697–20709 (2024)
2024
-
[43]
In: ACM SIGGRAPH 2024 Conference Papers
Wang, Z., Yuan, Z., Wang, X., Li, Y., Chen, T., Xia, M., Luo, P., Shan, Y.: Mo- tionctrl: A unified and flexible motion controller for video generation. In: ACM SIGGRAPH 2024 Conference Papers. pp. 1–11 (2024)
2024
-
[44]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wu, R., Mildenhall, B., Henzler, P., Park, K., Gao, R., Watson, D., Srinivasan, P.P., Verbin, D., Barron, J.T., Poole, B., et al.: Reconfusion: 3d reconstruction with diffusion priors. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 21551–21561 (2024)
2024
-
[45]
arXiv preprint arXiv:2512.03040 (2025)
Xiao, Z., Zhao, Y., Li, L., Lan, Y., Yu, N., Garg, R., Cooper, R., Taghavi, M.H., Pan,X.:Video4spatial:Towardsvisuospatialintelligencewithcontext-guidedvideo generation. arXiv preprint arXiv:2512.03040 (2025)
-
[46]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yu,A.,Ye,V.,Tancik,M.,Kanazawa, A.:pixelnerf:Neuralradiancefieldsfromone or few images. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4578–4587 (2021)
2021
-
[48]
ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis
Yu, W., Xing, J., Yuan, L., Hu, W., Li, X., Huang, Z., Gao, X., Wong, T.T., Shan, Y., Tian, Y.: Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis. arXiv preprint arXiv:2409.02048 (2024)
work page internal anchor Pith review arXiv 2024
-
[49]
Zhang, Amy Lin, Moneish Kumar, Tzu-Hsuan Yang, Deva Ramanan, and Shubham Tulsiani
Zhang, J.Y., Lin, A., Kumar, M., Yang, T.H., Ramanan, D., Tulsiani, S.: Cameras as rays: Pose estimation via ray diffusion. arXiv preprint arXiv:2402.14817 (2024)
-
[50]
In: European Conference on Computer Vision
Zhang, K., Bi, S., Tan, H., Xiangli, Y., Zhao, N., Sunkavalli, K., Xu, Z.: Gs-lrm: Large reconstruction model for 3d gaussian splatting. In: European Conference on Computer Vision. pp. 1–19. Springer (2024)
2024
-
[51]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018)
2018
-
[52]
arXiv preprint arXiv:2512.10950 (2025) 3
Zhao, Q., Tan, H., Wang, Q., Bi, S., Zhang, K., Sunkavalli, K., Tulsiani, S., Jiang, H.: E-rayzer: Self-supervised 3d reconstruction as spatial visual pre-training. arXiv preprint arXiv:2512.10950 (2025)
-
[53]
arXiv preprint arXiv:2410.15957 , year=
Zheng, G., Li, T., Jiang, R., Lu, Y., Wu, T., Li, X.: Cami2v: Camera-controlled image-to-video diffusion model. arXiv preprint arXiv:2410.15957 (2024)
-
[54]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers
Zhi, Y., Li, C., Liao, H., Yang, X., Sun, Z., Chang, J., Cun, X., Feng, W., Han, X.: Mv-performer: Taming video diffusion model for faithful and synchronized multi- view performer synthesis. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers. pp. 1–14 (2025)
2025
-
[55]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhou,J.,Gao,H.,Voleti,V.,Vasishta,A.,Yao,C.H.,Boss,M.,Torr,P.,Rupprecht, C., Jampani, V.: Stable virtual camera: Generative view synthesis with diffusion models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 12405–12414 (2025)
2025
-
[56]
Zhou, T., Tucker, R., Flynn, J., Fyffe, G., Snavely, N.: Stereo magnification: Learn- ingviewsynthesisusingmultiplaneimages.arXivpreprintarXiv:1805.09817(2018)
work page internal anchor Pith review arXiv 2018
-
[57]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhu, H., Wang, Y., Zhou, J., Chang, W., Zhou, Y., Li, Z., Chen, J., Shen, C., Pang, J., He, T.: Aether: Geometric-aware unified world modeling. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8535–8546 (2025) FrameCrafter 19 Appendix Overview.In the appendix, we provide additional quantitative/qualitative results, ablation...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.