Recognition: no theorem link
Quantifying Explanation Consistency: The C-Score Metric for CAM-Based Explainability in Medical Image Classification
Pith reviewed 2026-05-10 18:17 UTC · model grok-4.3
The pith
The C-Score quantifies whether medical image classifiers apply the same spatial reasoning to every patient with a given condition and flags instability before accuracy metrics fail.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
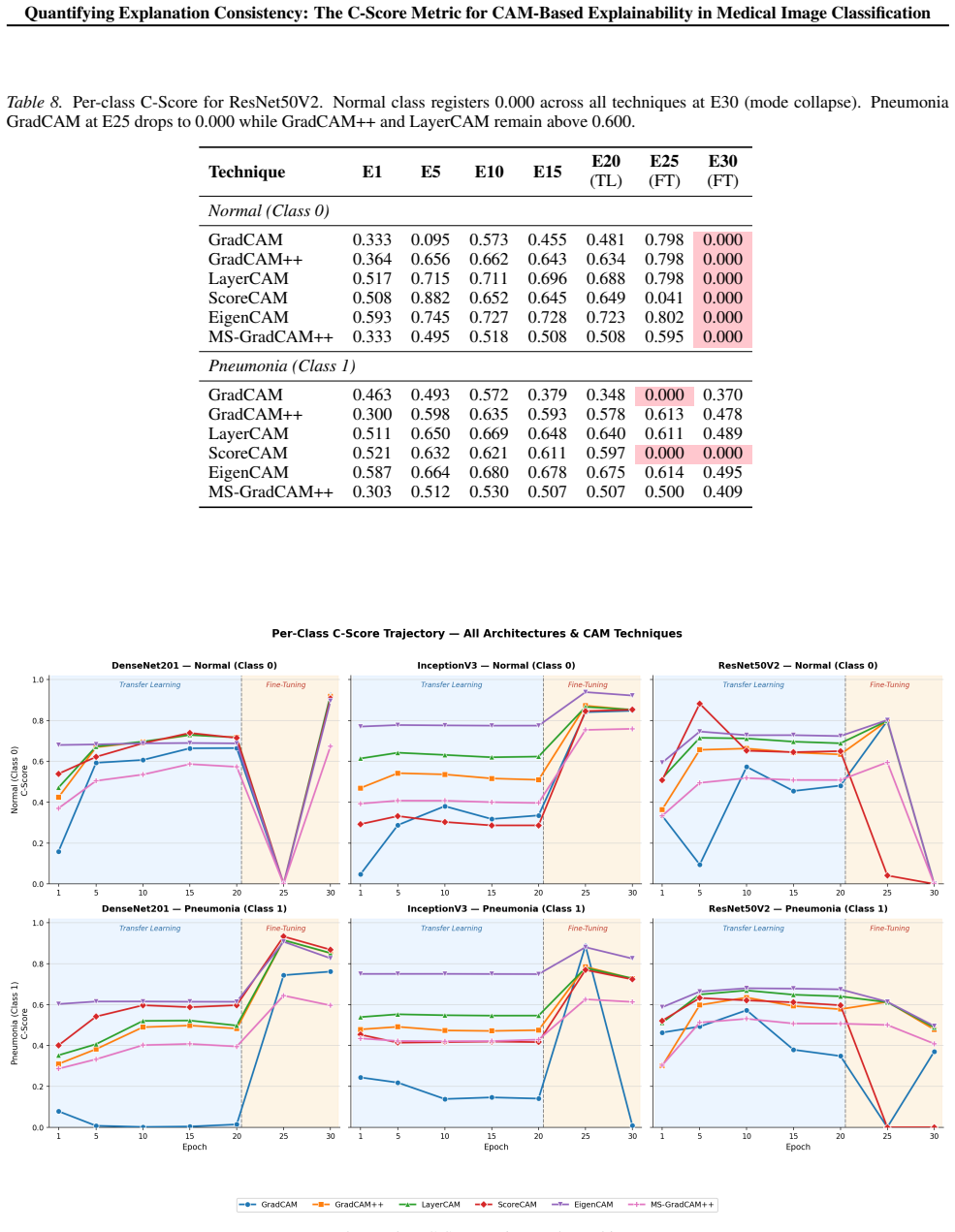
The C-Score is the average, confidence-weighted soft IoU computed on intensity-emphasised explanation maps produced by a CAM method for all correctly classified instances of a class. Evaluation on six CAM variants and three CNN architectures over thirty epochs of the Kermany chest X-ray dataset identifies three mechanisms by which AUC and explanation consistency can separate: threshold-mediated gold-list collapse, technique-specific attribution collapse at peak AUC, and class-level masking inside global averages. Because these separations are invisible to classification metrics, the C-Score supplies an annotation-free early signal of impending model instability, as illustrated by ScoreCAM on
What carries the argument
The C-Score itself, a confidence-weighted, annotation-free average of pairwise soft IoU on intensity-emphasised CAM maps restricted to correctly classified instances.
If this is right
- High AUC can coexist with low explanation consistency, creating deployment risks invisible to standard performance monitoring.
- ScoreCAM on ResNet50V2 exhibits detectable consistency deterioration one full checkpoint before catastrophic AUC collapse.
- Architecture-specific deployment choices can be informed by explanation quality rather than predictive ranking alone.
- Consistency can be monitored continuously without requiring fresh radiologist annotations for every new case.
Where Pith is reading between the lines
- During model selection, C-Score could be used alongside accuracy to prefer architectures whose explanations remain stable across patients.
- The same consistency-tracking approach might apply to other explainability families or to imaging tasks outside chest X-rays.
- Models that maintain high C-Score throughout training may prove more robust when inputs shift slightly from the training distribution.
Load-bearing premise
That pairwise soft IoU on intensity-emphasised explanation maps across correctly classified instances actually captures whether the model applies the same spatial reasoning strategy.
What would settle it
Repeated training runs on the same architectures and dataset in which C-Score deterioration for ScoreCAM on ResNet50V2 fails to precede AUC collapse, or in which high C-Score models still produce visibly inconsistent maps on held-out cases.
Figures



read the original abstract
Class Activation Mapping (CAM) methods are widely used to generate visual explanations for deep learning classifiers in medical imaging. However, existing evaluation frameworks assess whether explanations are correct, measured by localisation fidelity against radiologist annotations, rather than whether they are consistent: whether the model applies the same spatial reasoning strategy across different patients with the same pathology. We propose the C-Score (Consistency Score), a confidence-weighted, annotation-free metric that quantifies intra-class explanation reproducibility via intensity-emphasised pairwise soft IoU across correctly classified instances. We evaluate six CAM techniques: GradCAM, GradCAM++, LayerCAM, EigenCAM, ScoreCAM, and MS GradCAM++ across three CNN architectures (DenseNet201, InceptionV3, ResNet50V2) over thirty training epochs on the Kermany chest X-ray dataset, covering transfer learning and fine-tuning phases. We identify three distinct mechanisms of AUC-consistency dissociation, invisible to standard classification metrics: threshold-mediated gold list collapse, technique-specific attribution collapse at peak AUC, and class-level consistency masking in global aggregation. C-Score provides an early warning signal of impending model instability. ScoreCAM deterioration on ResNet50V2 is detectable one full checkpoint before catastrophic AUC collapse and yields architecture-specific clinical deployment recommendations grounded in explanation quality rather than predictive ranking alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the C-Score, a confidence-weighted annotation-free metric that quantifies intra-class explanation consistency for CAM methods via intensity-emphasised pairwise soft IoU computed only on correctly classified instances. It evaluates six CAM techniques (GradCAM, GradCAM++, LayerCAM, EigenCAM, ScoreCAM, MS GradCAM++) across DenseNet201, InceptionV3 and ResNet50V2 on the Kermany chest X-ray dataset over 30 training epochs, identifies three mechanisms of AUC-consistency dissociation, and claims that C-Score deterioration on ResNet50V2 with ScoreCAM provides an early warning of impending AUC collapse one checkpoint prior.
Significance. If the temporal precedence holds after controlling for shifts in the correctly-classified instance pool, C-Score would supply a practical, annotation-free monitor of explanation stability that complements standard classification metrics and could inform architecture-specific deployment decisions in medical imaging. The multi-epoch, multi-architecture evaluation and explicit identification of dissociation mechanisms are strengths that go beyond single-snapshot localisation fidelity studies.
major comments (1)
- [Results (ResNet50V2/ScoreCAM)] Results section (ResNet50V2/ScoreCAM early-warning experiment): the claim that C-Score drop precedes catastrophic AUC collapse rests on pairwise soft IoU computed over the changing set of correctly classified instances at each checkpoint. No ablation is described that holds the instance set fixed across epochs or matches class-balance and difficulty statistics to earlier checkpoints; without this control the observed IoU deterioration could arise from a shift toward easier cases rather than loss of consistent spatial reasoning, undermining the early-warning interpretation.
minor comments (2)
- [Methods] The exact mathematical definition of the confidence-weighted soft IoU (including the intensity-emphasis transformation and the aggregation over pairs) should be stated explicitly with equation numbers in the Methods section so that the metric can be reproduced without ambiguity.
- [Figures] All C-Score and AUC plots over epochs should include per-checkpoint standard deviations or bootstrap confidence intervals and the number of correctly classified instances used at each point.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review of our manuscript. The concern regarding potential confounding from the evolving set of correctly classified instances in the ResNet50V2/ScoreCAM early-warning analysis is well-taken, and we address it directly below with a commitment to strengthen the supporting evidence.
read point-by-point responses
-
Referee: Results section (ResNet50V2/ScoreCAM early-warning experiment): the claim that C-Score drop precedes catastrophic AUC collapse rests on pairwise soft IoU computed over the changing set of correctly classified instances at each checkpoint. No ablation is described that holds the instance set fixed across epochs or matches class-balance and difficulty statistics to earlier checkpoints; without this control the observed IoU deterioration could arise from a shift toward easier cases rather than loss of consistent spatial reasoning, undermining the early-warning interpretation.
Authors: We agree that the dynamic nature of the correctly-classified instance pool introduces a potential confound that must be explicitly controlled before the temporal precedence claim can be considered robust. In the revised manuscript we will add a controlled ablation that recomputes C-Score trajectories on a fixed reference set: specifically, the subset of test instances that remain correctly classified from the epoch of peak AUC through the checkpoint immediately preceding the observed collapse. We will additionally report a matched-difficulty variant that subsamples instances at each epoch to preserve the same distribution of prediction confidences as the reference set. These analyses will be presented alongside the original curves so readers can directly assess whether the C-Score decline persists when the evaluated population is held constant. We believe this addition will eliminate the alternative explanation of instance-pool shift while preserving the annotation-free character of the metric. revision: yes
Circularity Check
No significant circularity detected in metric definition or empirical claims
full rationale
The C-Score is introduced as a direct definition: a confidence-weighted, annotation-free metric computed from intensity-emphasised pairwise soft IoU on CAM explanation maps restricted to correctly classified instances. This construction uses standard similarity measures on model outputs without any fitted parameters, self-referential loops, or reduction of the metric itself to its claimed downstream uses. The reported dissociation mechanisms and early-warning observation on ResNet50V2/ScoreCAM are presented as empirical findings from the thirty-epoch evaluation on the Kermany dataset across six CAM methods and three architectures; they do not rely on self-citations for justification of the metric or invoke uniqueness theorems. No step in the provided abstract or summary equates a prediction or result to its own inputs by construction, and the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Soft IoU on intensity-weighted CAM maps is a valid proxy for whether the model applies the same spatial reasoning across instances of the same class.
invented entities (1)
-
C-Score
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Varun Gulshan, Lily Peng, Marc Coram, Martin C Stumpe, Derek Wu, Arunachalam Narayanaswamy, Subhashini Venugopalan, Kasumi Widner, Tom Madams, Jorge Cuadros, et al. Development and validation of a deep learning algorithm for detec- tion of diabetic retinopathy in retinal fundus pho- tographs.JAMA, 316(22):2402–2410, 2016. doi: 10.1001/jama.2016.17216
-
[2]
Dermatologist-level classification of skin can- cer with deep neural networks.Nature, 542:115–118,
Andre Esteva, Brett Kuprel, Roberto A Novoa, Justin Ko, Susan M Swetter, Helen M Blau, and Sebastian Thrun. Dermatologist-level classification of skin can- cer with deep neural networks.Nature, 542:115–118,
-
[3]
doi: 10.1038/nature21056
-
[4]
Daniel S Kermany, Michael Goldbaum, Wenjia Cai, Carolina C S Valentim, Huiying Liang, Sally L Bax- ter, Alex McKeown, Ge Yang, Xiaokang Wu, Fang- bing Yan, et al. Identifying medical diagnoses and treatable diseases by image-based deep learning.Cell, 172(5):1122–1131, 2018. doi: 10.1016/j.cell.2018. 02.010
-
[5]
Pranav Rajpurkar, Jeremy Irvin, Robyn L Ball, Kaylie Zhu, Brandon Yang, Hershel Mehta, Tony Duan, Daisy Ding, Aarti Bagul, Curtis P Langlotz, et al. CheXNet: Radiologist-level pneumonia detection on chest x-rays with deep learning.arXiv preprint arXiv:1711.05225, 2017. doi: 10.48550/arXiv.1711. 05225
-
[6]
Alex J DeGrave, Joseph D Janizek, and Su-In Lee. AI for radiographic COVID-19 detection selects short- cuts over signal.Nature Machine Intelligence, 3:610– 619, 2021. doi: 10.1038/s42256-021-00338-7
-
[7]
John R Zech, Marcus A Badgeley, Manway Liu, An- thony B Costa, Joseph J Titano, and Eric Karl Oer- mann. Variable generalization performance of a deep learning model to detect pneumonia in chest radio- graphs: A cross-sectional study.PLOS Medicine, 15(11):e1002683, 2018. doi: 10.1371/journal.pmed. 1002683
-
[8]
Luke Oakden-Rayner, Jared Dunnmon, Gustavo Carneiro, and Christopher Ré. Hidden stratifica- tion causes clinically meaningful failures in machine learning for medical imaging. InProceedings of the ACM Conference on Health, Inference, and Learn- ing (CHIL), pages 151–159, 2020. doi: 10.1145/ 3368555.3384468
-
[9]
Julia K Winkler, Christine Fink, Ferdinand Toberer, Alexander Enk, Teresa Deinlein, Rainer Hofmann- Wellenhof, Luc Thomas, Aimilios Lallas, Andreas Blum, Wilhelm Stolz, et al. Association between surgical skin markings in dermoscopic images and diagnostic performance of a deep learning convo- lutional neural network for melanoma recognition. JAMA Dermatol...
-
[10]
Michael Roberts, Derek Driggs, Matthew Thorpe, Julian Gilbey, Michael Yeung, Stephan Ursprung, Angelica I Aviles-Rivero, Christian Etmann, Cathal McCague, Lucian Beer, et al. Common pit- falls and recommendations for using machine learn- ing to detect and prognosticate for COVID-19 us- ing chest radiographs and ct scans.Nature Ma- chine Intelligence, 3:19...
2021
-
[11]
Dissecting racial bias in an algorithm used to manage the health of populations
Ziad Obermeyer, Brian Powers, Christine V ogeli, and Sendhil Mullainathan. Dissecting racial bias in an algorithm used to manage the health of populations. Science, 366(6464):447–453, 2019. doi: 10.1126/ science.aax2342
2019
-
[12]
Graham A McLeod, Emma A M Stanley, Tom Rose- nal, and Nils D Forkert. Distinct visual biases affect humans and artificial intelligence in medical imaging 7 Quantifying Explanation Consistency: The C-Score Metric for CAM-Based Explainability in Medical Image Classification diagnoses.npj Digital Medicine, 9(62), 2026. doi: 10.1038/s41746-025-02226-5
-
[13]
Selvaraju, Michael Cogswell, Ab- hishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra
Ramprasaath R Selvaraju, Michael Cogswell, Ab- hishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-CAM: Visual explanations from deep networks via gradient-based localization. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 618–626, 2017. doi: 10.1109/ICCV .2017.74
-
[14]
Sanity checks for saliency maps
Julius Adebayo, Justin Gilmer, Michael Muelly, Ian Goodfellow, Moritz Hardt, and Been Kim. Sanity checks for saliency maps. InAdvances in Neural In- formation Processing Systems (NeurIPS), volume 31, pages 9525–9536, 2018
2018
-
[15]
The (un)reliability of saliency methods
Pieter-Jan Kindermans, Sara Hooker, Julius Adebayo, Maximilian Alber, Kristof T Schütt, Sven Dähne, Dumitru Erhan, and Been Kim. The (un)reliability of saliency methods. InExplainable AI: Inter- preting, Explaining and Visualizing Deep Learning, pages 267–280. Springer, 2019. doi: 10.1007/ 978-3-030-28954-6_14
2019
-
[16]
Interpretation of neural networks is fragile
Amirata Ghorbani, Abubakar Abid, and James Zou. Interpretation of neural networks is fragile. InPro- ceedings of the AAAI Conference on Artificial Intel- ligence, volume 33, pages 3681–3688, 2019. doi: 10.1609/aaai.v33i01.33013681
-
[17]
Use hirescam instead of grad-cam for faithful explanations of convolutional neural networks,
Rachel Lea Draelos and Lawrence Carin. Use HiResCAM instead of Grad-CAM for faithful ex- planations of convolutional neural networks.arXiv preprint arXiv:2011.08891, 2020
-
[18]
Wojciech Samek, Alexander Binder, Grégoire Mon- tavon, Sebastian Lapuschkin, and Klaus-Robert Müller. Evaluating the visualization of what a deep neural network has learned.IEEE Transac- tions on Neural Networks and Learning Systems, 28 (11):2660–2673, 2017. doi: 10.1109/TNNLS.2016. 2599820
-
[19]
Sanity checks for saliency metrics
Richard Tomsett, Dan Harborne, Supriyo Chakraborty, Prudhvi Gurram, and Alun Preece. Sanity checks for saliency metrics. InProceedings of the AAAI Conference on Artificial Intelligence, pages 6021–6029, 2020. doi: 10.1609/aaai.v34i04.6064
-
[20]
The disagreement problem in explainable machine learning: A practi- tioner’s perspective,
Satyapriya Krishna, Tessa Han, Alex Gu, Javin Pom- bra, Shahin Jabbari, Steven Wu, and Himabindu Lakkaraju. The disagreement problem in explain- able machine learning: A practitioner’s perspective. Transactions on Machine Learning Research, 2024. doi: 10.48550/arXiv.2202.01602. arXiv:2202.01602 (2022); TMLR publication (2024)
-
[21]
The disagreement problem in faith- fulness metrics.arXiv preprint arXiv:2311.07763,
Ethan Barr et al. The disagreement problem in faith- fulness metrics.arXiv preprint arXiv:2311.07763,
-
[22]
doi: 10.48550/arXiv.2311.07763
-
[23]
Localized gaussian splatting editing with contextual awareness
Aditya Chattopadhay, Anirban Sarkar, Prantik Howlader, and Vineeth N Balasubramanian. Grad- CAM++: Generalized gradient-based visual expla- nations for deep convolutional networks. In2018 IEEE Winter Conference on Applications of Com- puter Vision (WACV), pages 839–847. IEEE, 2018. doi: 10.1109/W ACV .2018.00097
work page doi:10.1109/w 2018
-
[24]
Layercam: Exploring hierarchical class activation maps for localization
Peng-Tao Jiang, Chang-Bin Zhang, Qibin Hou, Ming- Ming Cheng, and Yunchao Wei. LayerCAM: Explor- ing hierarchical class activation maps for localization. IEEE Transactions on Image Processing, 30:5875– 5888, 2021. doi: 10.1109/TIP.2021.3089943
-
[25]
Trevor Hastie, Andrea Montanari, Saharon Rosset, and Ryan J
Haofan Wang, Zifan Wang, Mengnan Du, Fan Yang, Zijian Zhang, Sirui Ding, Piotr Mardziel, and Xia Hu. Score-CAM: Score-weighted visual explanations for convolutional neural networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition Workshops, pages 111–119, 2020. doi: 10.1109/CVPRW50498.2020.00020
-
[26]
Eigen-CAM: Class activation map using principal components
Mohammed Bany Muhammad and Mohammed Yeasin. Eigen-CAM: Class activation map using principal components. In2020 International Joint Conference on Neural Networks (IJCNN), pages 1–
-
[27]
O’Connor, and Kevin McGuinness
IEEE, 2020. doi: 10.1109/IJCNN48605.2020. 9206626
-
[28]
A survey on explainable artificial intelligence (XAI) techniques for visualizing deep learning models in medical imaging.Journal of Imaging, 10(10):239, 2024
Siddharth Bhati, Fnu Neha, and Md Amiruzzaman. A survey on explainable artificial intelligence (XAI) techniques for visualizing deep learning models in medical imaging.Journal of Imaging, 10(10):239, 2024
2024
-
[29]
Reviewing CAM- based deep explainable methods in healthcare.Ap- plied Sciences, 14(10):4124, 2024
Deyang Tang, Jie Chen, Liyuan Ren, Xiuqin Wang, Dan Li, and Haibing Zhang. Reviewing CAM- based deep explainable methods in healthcare.Ap- plied Sciences, 14(10):4124, 2024. doi: 10.3390/ app14104124
2024
-
[30]
Bas H M van der Velden, Hugo J Kuijf, Kenneth G A Gilhuijs, and Max A Viergever. Explainable artifi- cial intelligence (XAI) in deep learning-based med- ical image analysis.Medical Image Analysis, 79: 102470, 2022. doi: 10.1016/j.media.2022.102470
-
[31]
Is grad-CAM explainable in med- ical images?arXiv preprint arXiv:2307.10506, 2023
Suman Suara et al. Is grad-CAM explainable in med- ical images?arXiv preprint arXiv:2307.10506, 2023. doi: 10.48550/arXiv.2307.10506
-
[32]
Learning deep features for discriminative localization
Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. Learning deep features 8 Quantifying Explanation Consistency: The C-Score Metric for CAM-Based Explainability in Medical Image Classification for discriminative localization. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2921–2929,...
-
[33]
Junhee Lee, Hyeonseong Cho, Yun Jang Pyun, Suk- Ju Kang, and Hyoungsik Nam. Heatmap assisted ac- curacy score evaluation method for machine-centric explainable deep neural networks.IEEE Access, 10: 64832–64849, 2022. doi: 10.1109/ACCESS.2022. 3184453
-
[34]
A benchmark for interpretability methods in deep neural networks
Sara Hooker, Dumitru Erhan, Pieter-Jan Kindermans, and Been Kim. A benchmark for interpretability methods in deep neural networks. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[35]
doi: 10.48550/arXiv.1806.10758
-
[36]
Quantus: An explainable AI toolkit for responsible evaluation of neural network expla- nations and beyond.Journal of Machine Learning Research, 24(34):1–11, 2023
Anna Hedström, Leander Weber, Daniel Krakowczyk, Dilyara Bareeva, Franz Motzkus, Wojciech Samek, Sebastian Lapuschkin, and Marina M-C Müller. Quantus: An explainable AI toolkit for responsible evaluation of neural network expla- nations and beyond.Journal of Machine Learning Research, 24(34):1–11, 2023
2023
-
[37]
The meta-evaluation problem in explainable AI: Identifying reliable estimators with MetaQuantus.Transactions on Machine Learning Re- search, 2023
Anna Hedström, Philine Bommer, Kristoffer K Wick- ström, Wojciech Samek, Sebastian Lapuschkin, and Marina M-C Müller. The meta-evaluation problem in explainable AI: Identifying reliable estimators with MetaQuantus.Transactions on Machine Learning Re- search, 2023. Featured Certification
2023
-
[38]
Cemre Ozer et al. Consistent explainable image quality assessment for medical imaging.Health In- formation Science and Systems, 14:31, 2025. doi: 10.1007/s13755-025-00411-0
-
[39]
Lago, Ghada Zamzmi, Brandon Eich, and Jana G
Miguel A. Lago, Ghada Zamzmi, Brandon Eich, and Jana G. Delfino. Evaluating explainability: A framework for systematic assessment and reporting of explainable ai features, 2025. URLhttps:// arxiv.org/abs/2506.13917
-
[40]
Densely connected convo- lutional networks
Gao Huang, Zhuang Liu, Laurens van der Maaten, and Kilian Q Weinberger. Densely connected convo- lutional networks. InProceedings of the IEEE Con- ference on Computer Vision and Pattern Recognition (CVPR), pages 2261–2269, 2017
2017
-
[41]
Rethinking the inception architecture for computer vision
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. InPro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2818–2826,
-
[42]
doi: 10.1109/CVPR.2016.308
-
[43]
Identity mappings in deep residual net- works
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual net- works. InEuropean Conference on Computer Vi- sion (ECCV), volume 9908 ofLecture Notes in Com- puter Science, pages 630–645. Springer, 2016. doi: 10.1007/978-3-319-46493-0_38
-
[44]
ImageNet: A large-scale hierar- chical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Fei-Fei Li. ImageNet: A large-scale hierar- chical image database. InProceedings of the IEEE Conference on Computer Vision and Pattern Recog- nition (CVPR), pages 248–255, 2009. doi: 10.1109/ CVPR.2009.5206848
-
[45]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInternational Confer- ence on Learning Representations (ICLR), 2015. doi: 10.48550/arXiv.1412.6980
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1412.6980 2015
-
[46]
Regulation on artificial intelligence (AI Act)
European Parliament and Council of the European Union. Regulation on artificial intelligence (AI Act). Technical Report EU 2024/1689, Official Journal of the European Union, 2024
2024
-
[47]
Food and Drug Administration
U.S. Food and Drug Administration. AI/ML-based software as a medical device (SaMD) action plan. Technical report, U.S. Food and Drug Administration, 2021
2021
-
[48]
J Richard Landis and Gary G Koch. The measurement of observer agreement for categorical data.Biomet- rics, 33(1):159–174, 1977. doi: 10.2307/2529310
-
[49]
SmoothGrad: Removing noise by adding noise.arXiv preprint arXiv:1706.03825, 2017
Daniel Smilkov, Nikhil Thorat, Been Kim, Fer- nanda Viégas, and Martin Wattenberg. SmoothGrad: Removing noise by adding noise.arXiv preprint arXiv:1706.03825, 2017. doi: 10.48550/arXiv.1706. 03825
-
[50]
Axiomatic Attribution for Deep Networks, June 2017
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. InPro- ceedings of the 34th International Conference on Ma- chine Learning (ICML), pages 3319–3328, 2017. doi: 10.48550/arXiv.1703.01365
-
[51]
A unified ap- proach to interpreting model predictions
Scott M Lundberg and Su-In Lee. A unified ap- proach to interpreting model predictions. InAdvances in Neural Information Processing Systems (NeurIPS), pages 4765–4774, 2017. doi: 10.48550/arXiv.1705. 07874
-
[52]
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. “Why Should I Trust You?”: Explaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 1135– 1144, 2016. doi: 10.1145/2939672.2939778. 9 Quantifying Explanation Consistency: The C-Score Metric for CAM-Based ...
-
[53]
Efficientnet: Rethinking model scaling for convolutional neural networks,
Mingxing Tan and Quoc Le. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning (ICML), pages 6105–6114, 2019. doi: 10.48550/arXiv.1905.11946
-
[54]
A ConvNet for the 2020s
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A ConvNet for the 2020s. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 11976–11986, 2022
2022
-
[55]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16×16 words: Transformers for im- age recognition at scale. InInternational Conference on Learning Representations (ICLR), 2021. doi: 10.48550/arXiv.2010.11929
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2010.11929 2021
-
[56]
Larrazabal, Nicolás Nieto, Victoria Peterson, Diego H
Agustina J Larrazabal, Nicolás Nieto, Victoria Peter- son, Diego H Milone, and Enzo Ferrante. Gender im- balance in medical imaging datasets produces biased classifiers for computer-aided diagnosis.Proceedings of the National Academy of Sciences, 117(23):12592– 12594, 2020. doi: 10.1073/pnas.1919012117. 10 Quantifying Explanation Consistency: The C-Score ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.