Recognition: 2 theorem links
· Lean TheoremVisually-grounded Humanoid Agents
Pith reviewed 2026-05-10 18:06 UTC · model grok-4.3
The pith
A two-layer system turns digital human avatars into autonomous agents that perceive, plan, and act in novel 3D scenes using only first-person visual input.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
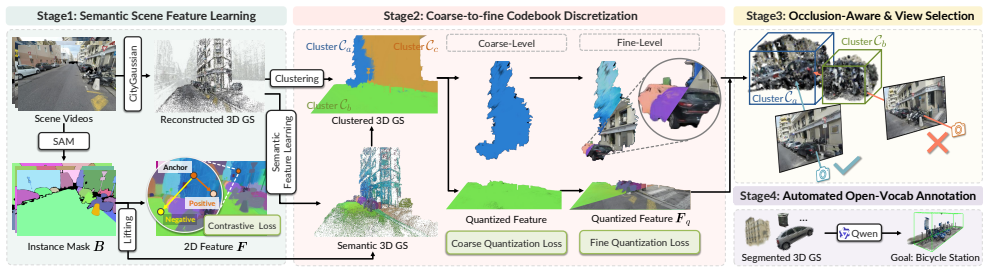
The authors introduce Visually-grounded Humanoid Agents as a coupled world-agent framework. The world layer reconstructs semantically rich 3D Gaussian scenes from real-world videos through an occlusion-aware pipeline and supports animatable Gaussian human avatars. The agent layer equips these avatars with first-person RGB-D perception, embodied planning that incorporates spatial awareness and iterative reasoning, and low-level execution of full-body actions. A new benchmark evaluates interaction in diverse reconstructed environments, and experiments report higher task success rates with fewer collisions than both internal ablations and existing planning methods.
What carries the argument
The coupled two-layer (world-agent) paradigm, where occlusion-aware 3D Gaussian scene reconstruction feeds into an agent equipped with first-person RGB-D perception and iterative embodied planning for full-body control.
If this is right
- Digital humans can exhibit goal-directed behavior in arbitrary reconstructed scenes without access to privileged state or scripted controls.
- Task success rates increase and collision counts decrease relative to current state-of-the-art planning baselines.
- Any 3D environment captured on video can be populated at scale with active, autonomous humanoid agents.
- A dedicated benchmark now exists for measuring humanoid-scene interaction across varied reconstructed settings.
Where Pith is reading between the lines
- The same reconstruction-plus-agent loop could generate large volumes of synthetic human motion data to train real robots that must interact with people.
- Extending the pipeline to handle moving objects or people within the scene would require adding temporal consistency to the Gaussian reconstruction step.
- Pairing the agents with a language interface could let goals be specified in ordinary sentences instead of explicit spatial targets.
Load-bearing premise
The occlusion-aware 3D Gaussian reconstruction must yield scenes that are spatially accurate and semantically detailed enough to support reliable first-person planning and collision-free action execution in environments the system has never encountered before.
What would settle it
Measure reconstruction accuracy independently on a held-out video sequence, then run the agents on the resulting model and check whether success rates fall below those achieved by planners given ground-truth 3D geometry.
Figures






read the original abstract
Digital human generation has been studied for decades and supports a wide range of real-world applications. However, most existing systems are passively animated, relying on privileged state or scripted control, which limits scalability to novel environments. We instead ask: how can digital humans actively behave using only visual observations and specified goals in novel scenes? Achieving this would enable populating any 3D environments with digital humans at scale that exhibit spontaneous, natural, goal-directed behaviors. To this end, we introduce Visually-grounded Humanoid Agents, a coupled two-layer (world-agent) paradigm that replicates humans at multiple levels: they look, perceive, reason, and behave like real people in real-world 3D scenes. The World Layer reconstructs semantically rich 3D Gaussian scenes from real-world videos via an occlusion-aware pipeline and accommodates animatable Gaussian-based human avatars. The Agent Layer transforms these avatars into autonomous humanoid agents, equipping them with first-person RGB-D perception and enabling them to perform accurate, embodied planning with spatial awareness and iterative reasoning, which is then executed at the low level as full-body actions to drive their behaviors in the scene. We further introduce a benchmark to evaluate humanoid-scene interaction in diverse reconstructed environments. Experiments show our agents achieve robust autonomous behavior, yielding higher task success rates and fewer collisions than ablations and state-of-the-art planning methods. This work enables active digital human population and advances human-centric embodied AI. Data, code, and models will be open-sourced.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Visually-grounded Humanoid Agents, a coupled two-layer (world-agent) paradigm for creating autonomous digital humans that exhibit goal-directed behaviors in novel 3D scenes using only visual observations. The World Layer reconstructs semantically rich 3D Gaussian scenes and animatable avatars from real-world videos via an occlusion-aware pipeline. The Agent Layer equips these avatars with first-person RGB-D perception, embodied planning with spatial awareness and iterative reasoning, and low-level full-body action execution. A benchmark for humanoid-scene interaction is introduced, with experiments claiming higher task success rates and fewer collisions than ablations and state-of-the-art planning methods.
Significance. If the experimental claims hold, this work could have significant impact on human-centric embodied AI and digital human generation by enabling scalable, active population of arbitrary 3D environments with spontaneous, natural behaviors. The commitment to open-sourcing data, code, and models supports reproducibility and further research.
major comments (2)
- [§4 Experiments] §4 Experiments: the abstract and results assert higher task success rates and fewer collisions than ablations and SOTA planning methods, but the manuscript provides no quantitative values, baseline details, dataset descriptions, number of trials, or error analysis to support these claims.
- [§3.1 World Layer] §3.1 World Layer: the occlusion-aware 3D Gaussian reconstruction is asserted to produce semantically rich and spatially accurate scenes sufficient for reliable embodied planning, but no quantitative reconstruction metrics (e.g., PSNR, semantic segmentation accuracy, or novel-view error) are reported to validate this load-bearing assumption.
minor comments (2)
- [Abstract] Abstract: including at least one headline quantitative result (e.g., success rate delta) would strengthen the summary of the empirical contribution.
- [§2 Overview] The two-layer architecture description would benefit from an explicit diagram or pseudocode reference to clarify the interface between world reconstruction and agent planning.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important gaps in the quantitative support for our claims, and we address each point below. We agree that additional details are needed and will revise the manuscript to incorporate them.
read point-by-point responses
-
Referee: [§4 Experiments] §4 Experiments: the abstract and results assert higher task success rates and fewer collisions than ablations and SOTA planning methods, but the manuscript provides no quantitative values, baseline details, dataset descriptions, number of trials, or error analysis to support these claims.
Authors: We acknowledge that the current manuscript does not provide the specific quantitative values, baseline details, dataset descriptions, number of trials, or error analysis to fully substantiate the claims in the abstract and results section. This is a presentation gap that weakens the experimental section. In the revised version, we will expand Section 4 to include a detailed table reporting task success rates, collision counts, comparisons against ablations and state-of-the-art planning methods, along with descriptions of the benchmark environments, number of trials per task, and any relevant error analysis or variance statistics. revision: yes
-
Referee: [§3.1 World Layer] §3.1 World Layer: the occlusion-aware 3D Gaussian reconstruction is asserted to produce semantically rich and spatially accurate scenes sufficient for reliable embodied planning, but no quantitative reconstruction metrics (e.g., PSNR, semantic segmentation accuracy, or novel-view error) are reported to validate this load-bearing assumption.
Authors: We agree that quantitative metrics for the occlusion-aware 3D Gaussian reconstruction are not reported in Section 3.1, even though the pipeline is presented as producing scenes suitable for embodied planning. To validate this assumption, the revised manuscript will add quantitative evaluations, including PSNR and SSIM for novel-view synthesis, semantic segmentation accuracy on reconstructed scenes, and novel-view reconstruction error. These will be presented in a new table or subsection within the World Layer description. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents a constructive two-layer system (world layer for occlusion-aware 3D Gaussian scene reconstruction from videos plus animatable avatars; agent layer for first-person RGB-D perception, spatial planning, and low-level action execution) whose headline performance claims (higher task success, fewer collisions) are supported by empirical benchmark comparisons to ablations and prior planning methods. No equations, fitted parameters, or derivations are described that reduce by construction to self-definitions, renamed inputs, or load-bearing self-citations. The architecture integrates established components (Gaussian splatting, embodied planning) without circular reduction, rendering the derivation chain self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
occlusion-aware semantic scene reconstruction pipeline... 3D Gaussian Splatting... VLM... iterative reasoning... diffusion-based motion generation
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
8-tick period... three spatial dimensions... c, ℏ, G
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Video based reconstruction of 3d people models
Thiemo Alldieck, Marcus Magnor, Weipeng Xu, Christian Theobalt, and Gerard Pons-Moll. Video based reconstruction of 3d people models. InProceedings of Conference on Computer Vision and Pattern Recognition (CVPR), pages 8387–8397, 2018. 2, 7
2018
-
[3]
On Evaluation of Embodied Navigation Agents
Peter Anderson, Angel Chang, Devendra Singh Chaplot, Alexey Dosovitskiy, Saurabh Gupta, Vladlen Koltun, Jana Kosecka, Jitendra Malik, Roozbeh Mottaghi, Manolis Savva, et al. On evaluation of embodied navigation agents.arXiv preprint arXiv:1807.06757, 2018. 2, 7
work page internal anchor Pith review arXiv 2018
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 4, 5, 17, 18, 24, 25
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Mip-nerf: A multiscale representation for anti-aliasing neu- ral radiance fields
Jonathan T Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P Srinivasan. Mip-nerf: A multiscale representation for anti-aliasing neu- ral radiance fields. InProceedings of International Confer- ence on Computer Vision (ICCV), pages 5855–5864, 2021. 6, 20
2021
-
[6]
Dhruv Batra, Aaron Gokaslan, Aniruddha Kembhavi, Olek- sandr Maksymets, Roozbeh Mottaghi, Manolis Savva, Alexander Toshev, and Erik Wijmans. Objectnav revisited: On evaluation of embodied agents navigating to objects. arXiv preprint arXiv:2006.13171, 2020. 7
-
[7]
Multidimensional binary search trees used for associative searching.Communications of the ACM, 18(9):509–517, 1975
Jon Louis Bentley. Multidimensional binary search trees used for associative searching.Communications of the ACM, 18(9):509–517, 1975. 19
1975
-
[8]
The University of Utah, 1974
Edwin Earl Catmull.A subdivision algorithm for computer display of curved surfaces. The University of Utah, 1974. 19
1974
-
[9]
Executing your commands via motion diffusion in latent space
Xin Chen, Biao Jiang, Wen Liu, Zilong Huang, Bin Fu, Tao Chen, and Gang Yu. Executing your commands via motion diffusion in latent space. InProceedings of Conference on Computer Vision and Pattern Recognition (CVPR), pages 18000–18010, 2023. 3
2023
-
[10]
Omnire: Omni urban scene reconstruction.arXiv preprint arXiv:2408.16760, 2024
Ziyu Chen, Jiawei Yang, Jiahui Huang, Riccardo de Lu- tio, Janick Martinez Esturo, Boris Ivanovic, Or Litany, Zan Gojcic, Sanja Fidler, Marco Pavone, et al. Omnire: Omni ur- ban scene reconstruction.arXiv preprint arXiv:2408.16760,
-
[11]
Navila: Legged robot vision- language-action model for navigation,
An-Chieh Cheng, Yandong Ji, Zhaojing Yang, Zaitian Gongye, Xueyan Zou, Jan Kautz, Erdem Bıyık, Hongxu Yin, Sifei Liu, and Xiaolong Wang. Navila: Legged robot vision-language-action model for navigation.arXiv preprint arXiv:2412.04453, 2024. 2, 7, 20, 25, 26
-
[12]
Occam’s lgs: An efficient approach for language gaussian splatting,
Jiahuan Cheng, Jan-Nico Zaech, Luc Van Gool, and Danda Pani Paudel. Occam’s lgs: A simple approach for lan- guage gaussian splatting.arXiv preprint arXiv:2412.01807, 3(4), 2024. 3
-
[13]
Dna-rendering: A diverse neural actor repository for high-fidelity human-centric rendering
Wei Cheng, Ruixiang Chen, Siming Fan, Wanqi Yin, Keyu Chen, Zhongang Cai, Jingbo Wang, Yang Gao, Zhengming Yu, Zhengyu Lin, et al. Dna-rendering: A diverse neural actor repository for high-fidelity human-centric rendering. InProceedings of International Conference on Computer Vision (ICCV), 2023. 2
2023
-
[14]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 24, 25
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Peishan Cong, Ziyi Wang, Zhiyang Dou, Yiming Ren, Wei Yin, Kai Cheng, Yujing Sun, Xiaoxiao Long, Xinge Zhu, and Yuexin Ma. Laserhuman: language-guided scene-aware hu- man motion generation in free environment.arXiv preprint arXiv:2403.13307, 2024. 3
-
[16]
Dy- namic 3d gaussian fields for urban areas.arXiv preprint arXiv:2406.03175, 2024
Tobias Fischer, Jonas Kulhanek, Samuel Rota Bulo, Lorenzo Porzi, Marc Pollefeys, and Peter Kontschieder. Dy- namic 3d gaussian fields for urban areas.arXiv preprint arXiv:2406.03175, 2024. 3
-
[17]
Multi-level neural scene graphs for dynamic urban environments
Tobias Fischer, Lorenzo Porzi, Samuel Rota Bulo, Marc Pollefeys, and Peter Kontschieder. Multi-level neural scene graphs for dynamic urban environments. InProceedings of Conference on Computer Vision and Pattern Recognition (CVPR), pages 21125–21135, 2024. 3
2024
-
[18]
Kaolin: A pytorch library for accelerating 3d deep learning research
Clement Fuji Tsang, Maria Shugrina, Jean Francois Lafleche, Or Perel, Charles Loop, Towaki Takikawa, Vis- may Modi, Alexander Zook, Jiehan Wang, Wenzheng Chen, Tianchang Shen, Jun Gao, Krishna Murthy Jatavallabhula, Edward Smith, Artem Rozantsev, Sanja Fidler, Gavriel State, Jason Gorski, Tommy Xiang, Jianing Li, Michael Li, and Rev Lebaredian. Kaolin: A ...
-
[19]
Dylan Goetting, Himanshu Gaurav Singh, and Antonio Lo- quercio. End-to-end navigation with vision language mod- els: Transforming spatial reasoning into question-answering. arXiv preprint arXiv:2411.05755, 2024. 3
-
[20]
Conceptgraphs: Open-vocabulary 3d scene graphs for per- ception and planning
Qiao Gu, Ali Kuwajerwala, Sacha Morin, Krishna Murthy Jatavallabhula, Bipasha Sen, Aditya Agarwal, Corban Rivera, William Paul, Kirsty Ellis, Rama Chellappa, et al. Conceptgraphs: Open-vocabulary 3d scene graphs for per- ception and planning. InInternational Conference on Robotics and Automation (ICRA), pages 5021–5028. IEEE,
-
[21]
Generating diverse and natural 3d human motions from text
Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. Generating diverse and natural 3d human motions from text. InProceedings of Conference on Computer Vision and Pattern Recognition (CVPR), pages 5152–5161, 2022. 18
2022
-
[22]
Stochastic 10 scene-aware motion prediction
Mohamed Hassan, Duygu Ceylan, Ruben Villegas, Jun Saito, Jimei Yang, Yi Zhou, and Michael J Black. Stochastic 10 scene-aware motion prediction. InProceedings of Inter- national Conference on Computer Vision (ICCV), pages 11374–11384, 2021. 3
2021
-
[23]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. 18
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Gaussianavatar: Towards realistic human avatar modeling from a single video via animatable 3d gaussians
Liangxiao Hu, Hongwen Zhang, Yuxiang Zhang, Boyao Zhou, Boning Liu, Shengping Zhang, and Liqiang Nie. Gaussianavatar: Towards realistic human avatar modeling from a single video via animatable 3d gaussians. InPro- ceedings of Conference on Computer Vision and Pattern Recognition (CVPR), pages 634–644, 2024. 3, 5, 7, 18, 26
2024
-
[25]
2d gaussian splatting for geometrically ac- curate radiance fields
Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, and Shenghua Gao. 2d gaussian splatting for geometrically ac- curate radiance fields. InACM SIGGRAPH 2024 conference papers, pages 1–11, 2024. 4, 16
2024
-
[26]
Horizon- gs: Unified 3d gaussian splatting for large-scale aerial-to- ground scenes
Lihan Jiang, Kerui Ren, Mulin Yu, Linning Xu, Junting Dong, Tao Lu, Feng Zhao, Dahua Lin, and Bo Dai. Horizon- gs: Unified 3d gaussian splatting for large-scale aerial-to- ground scenes. InProceedings of Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 26789– 26799, 2025. 3, 4, 6
2025
-
[27]
Scaling up dynamic human-scene interaction model- ing
Nan Jiang, Zhiyuan Zhang, Hongjie Li, Xiaoxuan Ma, Zan Wang, Yixin Chen, Tengyu Liu, Yixin Zhu, and Siyuan Huang. Scaling up dynamic human-scene interaction model- ing. InProceedings of Conference on Computer Vision and Pattern Recognition (CVPR), pages 1737–1747, 2024. 3
2024
-
[28]
In- stantavatar: Learning avatars from monocular video in 60 seconds
Tianjian Jiang, Xu Chen, Jie Song, and Otmar Hilliges. In- stantavatar: Learning avatars from monocular video in 60 seconds. InProceedings of Conference on Computer Vision and Pattern Recognition (CVPR), pages 16922–16932, 2023. 3
2023
-
[29]
Neuman: Neural human radiance field from a single video
Wei Jiang, Kwang Moo Yi, Golnoosh Samei, Oncel Tuzel, and Anurag Ranjan. Neuman: Neural human radiance field from a single video. InProceedings of European Conference on Computer Vision (ECCV), pages 402–418. Springer, 2022. 7
2022
-
[30]
Gradient-weighted feature back-projection: A fast alterna- tive to feature distillation in 3d gaussian splatting
Joji Joseph, Bharadwaj Amrutur, and Shalabh Bhatnagar. Gradient-weighted feature back-projection: A fast alterna- tive to feature distillation in 3d gaussian splatting. InPro- ceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–12, 2025. 3, 7, 9
2025
-
[31]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[32]
Op- timizing diffusion noise can serve as universal motion priors
Korrawe Karunratanakul, Konpat Preechakul, Emre Aksan, Thabo Beeler, Supasorn Suwajanakorn, and Siyu Tang. Op- timizing diffusion noise can serve as universal motion priors. InProceedings of Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 1334–1345, 2024. 6
2024
-
[33]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics (TOG), 42(4):139–1, 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics (TOG), 42(4):139–1, 2023. 2, 3, 26
2023
-
[34]
A hierarchical 3d gaussian representation for real-time ren- dering of very large datasets.ACM Transactions on Graphics (TOG), 43(4):1–15, 2024
Bernhard Kerbl, Andreas Meuleman, Georgios Kopanas, Michael Wimmer, Alexandre Lanvin, and George Drettakis. A hierarchical 3d gaussian representation for real-time ren- dering of very large datasets.ACM Transactions on Graphics (TOG), 43(4):1–15, 2024. 3, 4, 6, 9, 16, 17, 19, 21
2024
-
[35]
Lerf: Language embedded radiance fields
Justin Kerr, Chung Min Kim, Ken Goldberg, Angjoo Kanazawa, and Matthew Tancik. Lerf: Language embedded radiance fields. InProceedings of International Conference on Computer Vision (ICCV), pages 19729–19739, 2023. 3, 17
2023
-
[36]
Segment any- thing
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of International Conference on Com- puter Vision (ICCV), pages 4015–4026, 2023. 4, 6, 17, 23
2023
-
[37]
Project starline: A high-fidelity telepresence system
Jason Lawrence, Ryan Overbeck, Todd Prives, Tommy Fortes, Nikki Roth, and Brett Newman. Project starline: A high-fidelity telepresence system. InACM SIGGRAPH 2024 emerging technologies, pages 1–2. 2024. 2
2024
-
[38]
Gart: Gaussian articulated template models
Jiahui Lei, Yufu Wang, Georgios Pavlakos, Lingjie Liu, and Kostas Daniilidis. Gart: Gaussian articulated template models. InProceedings of Conference on Computer Vision and Pattern Recognition (CVPR), pages 19876–19887, 2024. 3, 26
2024
-
[39]
Matrixcity: A large-scale city dataset for city-scale neural rendering and beyond
Yixuan Li, Lihan Jiang, Linning Xu, Yuanbo Xiangli, Zhen- zhi Wang, Dahua Lin, and Bo Dai. Matrixcity: A large-scale city dataset for city-scale neural rendering and beyond. In Proceedings of International Conference on Computer Vi- sion (ICCV), pages 3205–3215, 2023. 4, 6
2023
-
[40]
Scenesplat: Gaussian splatting-based scene understanding with vision-language pretraining
Yue Li, Qi Ma, Runyi Yang, Huapeng Li, Mengjiao Ma, Bin Ren, Nikola Popovic, Nicu Sebe, Ender Konukoglu, Theo Gevers, et al. Scenesplat: Gaussian splatting-based scene understanding with vision-language pretraining. InPro- ceedings of International Conference on Computer Vision (ICCV), pages 4961–4972, 2025. 3
2025
-
[41]
Ani- matable gaussians: Learning pose-dependent gaussian maps for high-fidelity human avatar modeling
Zhe Li, Zerong Zheng, Lizhen Wang, and Yebin Liu. Ani- matable gaussians: Learning pose-dependent gaussian maps for high-fidelity human avatar modeling. InProceedings of Conference on Computer Vision and Pattern Recognition (CVPR), pages 19711–19722, 2024. 3
2024
-
[42]
Vastgaussian: Vast 3d gaussians for large scene reconstruction
Jiaqi Lin, Zhihao Li, Xiao Tang, Jianzhuang Liu, Shiyong Liu, Jiayue Liu, Yangdi Lu, Xiaofei Wu, Songcen Xu, You- liang Yan, et al. Vastgaussian: Vast 3d gaussians for large scene reconstruction. InProceedings of Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 5166– 5175, 2024. 3
2024
-
[43]
Learning implicit templates for point-based clothed human modeling
Siyou Lin, Hongwen Zhang, Zerong Zheng, Ruizhi Shao, and Yebin Liu. Learning implicit templates for point-based clothed human modeling. InProceedings of European Conference on Computer Vision (ECCV), pages 210–228. Springer, 2022. 3
2022
-
[44]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InProceedings of Conference on Computer Vision and Pattern Recognition (CVPR), pages 22160–22169, 2024. 6, 20
2024
-
[45]
Programmable motion generation for open- set motion control tasks
Hanchao Liu, Xiaohang Zhan, Shaoli Huang, Tai-Jiang Mu, and Ying Shan. Programmable motion generation for open- set motion control tasks. InProceedings of Conference on 11 Computer Vision and Pattern Recognition (CVPR), pages 1399–1408, 2024. 6
2024
-
[46]
Xinhao Liu, Jintong Li, Yicheng Jiang, Niranjan Sujay, Zhicheng Yang, Juexiao Zhang, John Abanes, Jing Zhang, and Chen Feng. Citywalker: Learning embodied ur- ban navigation from web-scale videos.arXiv preprint arXiv:2411.17820, 2024. 3
-
[47]
Citygaussian: Real-time high-quality large-scale scene rendering with gaussians
Yang Liu, Chuanchen Luo, Lue Fan, Naiyan Wang, Jun- ran Peng, and Zhaoxiang Zhang. Citygaussian: Real-time high-quality large-scale scene rendering with gaussians. In Proceedings of European Conference on Computer Vision (ECCV), pages 265–282. Springer, 2024. 3, 4, 16
2024
-
[48]
Citygaussianv2: Efficient and geometri- cally accurate reconstruction for large-scale scenes
Yang Liu, Chuanchen Luo, Zhongkai Mao, Junran Peng, and Zhaoxiang Zhang. Citygaussianv2: Efficient and geometri- cally accurate reconstruction for large-scale scenes.arXiv preprint arXiv:2411.00771, 2024. 3, 4, 16
-
[49]
Learn- ing to generate diverse pedestrian movements from web videos with noisy labels
Zhizheng Liu, Joe Lin, Wayne Wu, and Bolei Zhou. Learn- ing to generate diverse pedestrian movements from web videos with noisy labels. InProceedings of International Conference on Learning Representations (ICLR), 2024. 3
2024
-
[50]
Smpl: A skinned multi- person linear model
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi- person linear model. InSeminal Graphics Papers: Pushing the Boundaries, Volume 2, pages 851–866. 2023. 18, 26
2023
-
[51]
arXiv preprint arXiv:2412.09043 (2024)
Hao Lu, Tianshuo Xu, Wenzhao Zheng, Yunpeng Zhang, Wei Zhan, Dalong Du, Masayoshi Tomizuka, Kurt Keutzer, and Yingcong Chen. Drivingrecon: Large 4d gaussian re- construction model for autonomous driving.arXiv preprint arXiv:2412.09043, 2024. 3
-
[52]
Scaffold-gs: Structured 3d gaussians for view-adaptive rendering
Tao Lu, Mulin Yu, Linning Xu, Yuanbo Xiangli, Limin Wang, Dahua Lin, and Bo Dai. Scaffold-gs: Structured 3d gaussians for view-adaptive rendering. InProceedings of Conference on Computer Vision and Pattern Recognition (CVPR), pages 20654–20664, 2024. 3
2024
-
[53]
Mengjiao Ma, Qi Ma, Yue Li, Jiahuan Cheng, Runyi Yang, Bin Ren, Nikola Popovic, Mingqiang Wei, Nicu Sebe, Luc Van Gool, et al. Scenesplat++: A large dataset and compre- hensive benchmark for language gaussian splatting.arXiv preprint arXiv:2506.08710, 2025. 3
-
[54]
The power of points for modeling humans in clothing
Qianli Ma, Jinlong Yang, Siyu Tang, and Michael J Black. The power of points for modeling humans in clothing. In Proceedings of International Conference on Computer Vi- sion (ICCV), pages 10974–10984, 2021. 3
2021
-
[55]
Ludvig: Learning-free uplifting of 2d visual features to gaussian splatting scenes
Juliette Marrie, Romain M´en´egaux, Michael Arbel, Diane Larlus, and Julien Mairal. Ludvig: Learning-free uplifting of 2d visual features to gaussian splatting scenes. InPro- ceedings of International Conference on Computer Vision (ICCV), pages 7440–7450, 2025. 3
2025
-
[56]
Towards physically executable 3d gaussian for embodied navigation,
Bingchen Miao, Rong Wei, Zhiqi Ge, Shiqi Gao, Jingzhe Zhu, Renhan Wang, Siliang Tang, Jun Xiao, Rui Tang, Juncheng Li, et al. Towards physically executable 3d gaussian for embodied navigation.arXiv preprint arXiv:2510.21307, 2025. 4, 6, 7, 17, 20, 22
-
[57]
Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021. 3
2021
-
[58]
Generating continual human motion in diverse 3d scenes
Aymen Mir, Xavier Puig, Angjoo Kanazawa, and Gerard Pons-Moll. Generating continual human motion in diverse 3d scenes. InInternational Conference on 3D Vision (3DV), pages 903–913. IEEE, 2024. 3
2024
-
[59]
Aymen Mir, Jian Wang, Riza Alp Guler, Chuan Guo, Gerard Pons-Moll, and Bing Zhou. Aha! animating human avatars in diverse scenes with gaussian splatting.arXiv preprint arXiv:2511.09827, 2025. 3
-
[60]
Expressive whole-body 3d gaussian avatar
Gyeongsik Moon, Takaaki Shiratori, and Shunsuke Saito. Expressive whole-body 3d gaussian avatar. InProceedings of European Conference on Computer Vision (ECCV), pages 19–35. Springer, 2024. 3, 5
2024
-
[61]
Pivot: Iterative visual prompting elicits actionable knowledge for vlms
Soroush Nasiriany, Fei Xia, Wenhao Yu, Ted Xiao, Jacky Liang, Ishita Dasgupta, Annie Xie, Danny Driess, Ayzaan Wahid, Zhuo Xu, et al. Pivot: Iterative visual prompt- ing elicits actionable knowledge for vlms.arXiv preprint arXiv:2402.07872, 2024. 6
-
[62]
Disco4d: Disentangled 4d human generation and animation from a single image
Hui En Pang, Shuai Liu, Zhongang Cai, Lei Yang, Tianwei Zhang, and Ziwei Liu. Disco4d: Disentangled 4d human generation and animation from a single image. InProceed- ings of Conference on Computer Vision and Pattern Recog- nition (CVPR), pages 26331–26344, 2025. 3
2025
-
[63]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Mered- ith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023. 2, 3, 27
2023
-
[64]
Expressive body capture: 3d hands, face, and body from a single image
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed AA Osman, Dimitrios Tzionas, and Michael J Black. Expressive body capture: 3d hands, face, and body from a single image. InProceedings of Conference on Computer Vision and Pattern Recognition (CVPR), pages 10975–10985, 2019. 18, 26
2019
-
[65]
Multi-track timeline control for text-driven 3d human motion generation
Mathis Petrovich, Or Litany, Umar Iqbal, Michael J Black, Gul Varol, Xue Bin Peng, and Davis Rempe. Multi-track timeline control for text-driven 3d human motion generation. InProceedings of Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 1911–1921, 2024. 6, 18, 20
1911
-
[66]
SuperSplat
PlayCanvas. SuperSplat. https://superspl.at/ . Accessed: 2025-11-05. 6, 20
2025
-
[67]
Virtualhome: Simulating household activities via programs
Xavier Puig, Kevin Ra, Marko Boben, Jiaman Li, Tingwu Wang, Sanja Fidler, and Antonio Torralba. Virtualhome: Simulating household activities via programs. InProceed- ings of Conference on Computer Vision and Pattern Recog- nition (CVPR), pages 8494–8502, 2018. 2
2018
-
[68]
Tenenbaum, Sanja Fidler, and Antonio Torralba
Xavier Puig, Tianmin Shu, Shuang Li, Zilin Wang, Yuan- Hong Liao, Joshua B. Tenenbaum, Sanja Fidler, and Antonio Torralba. Watch-and-help: A challenge for social perception and human- {ai} collaboration. InProceedings of Inter- national Conference on Learning Representations (ICLR),
-
[69]
Xavier Puig, Tianmin Shu, Joshua B Tenenbaum, and An- tonio Torralba. Nopa: Neurally-guided online probabilistic assistance for building socially intelligent home assistants. arXiv preprint arXiv:2301.05223, 2023. 3 12
-
[70]
3dgs-avatar: Animatable avatars via deformable 3d gaussian splatting
Zhiyin Qian, Shaofei Wang, Marko Mihajlovic, Andreas Geiger, and Siyu Tang. 3dgs-avatar: Animatable avatars via deformable 3d gaussian splatting. InProceedings of Conference on Computer Vision and Pattern Recognition (CVPR), pages 5020–5030, 2024. 3
2024
-
[71]
Langsplat: 3d language gaussian splatting
Minghan Qin, Wanhua Li, Jiawei Zhou, Haoqian Wang, and Hanspeter Pfister. Langsplat: 3d language gaussian splatting. InProceedings of Conference on Computer Vision and Pattern Recognition (CVPR), pages 20051–20060, 2024. 2, 3, 17, 20
2024
-
[72]
LHM: large animatable human reconstruction model from a single image in seconds
Lingteng Qiu, Xiaodong Gu, Peihao Li, Qi Zuo, Weichao Shen, Junfei Zhang, Kejie Qiu, Weihao Yuan, Guanying Chen, Zilong Dong, et al. Lhm: Large animatable human reconstruction model from a single image in seconds.arXiv preprint arXiv:2503.10625, 2025. 3
-
[73]
Anigs: Animatable gaussian avatar from a single image with inconsistent gaussian reconstruction
Lingteng Qiu, Shenhao Zhu, Qi Zuo, Xiaodong Gu, Yuan Dong, Junfei Zhang, Chao Xu, Zhe Li, Weihao Yuan, Liefeng Bo, et al. Anigs: Animatable gaussian avatar from a single image with inconsistent gaussian reconstruction. In Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), pages 21148–21158, 2025. 3
2025
-
[74]
Learn- ing transferable visual models from natural language su- pervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language su- pervision. InProceedings of International Conference on Machine Learning (ICML), pages 8748–8763. PmLR, 2021. 3
2021
-
[75]
Learn- ing transferable visual models from natural language su- pervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language su- pervision. InProceedings of International Conference on Machine Learning (ICML), 2021. 2
2021
-
[76]
Vision language models are blind
Pooyan Rahmanzadehgervi, Logan Bolton, Moham- mad Reza Taesiri, and Anh Totti Nguyen. Vision language models are blind. InAsian Conference on Computer Vision (ACCV), pages 18–34, 2024. 6
2024
-
[77]
Accelerating 3D Deep Learning with PyTorch3D
Nikhila Ravi, Jeremy Reizenstein, David Novotny, Tay- lor Gordon, Wan-Yen Lo, Justin Johnson, and Georgia Gkioxari. Accelerating 3d deep learning with pytorch3d. arXiv:2007.08501, 2020. 19
work page internal anchor Pith review arXiv 2007
-
[78]
Kerui Ren, Lihan Jiang, Tao Lu, Mulin Yu, Linning Xu, Zhangkai Ni, and Bo Dai. Octree-gs: Towards consistent real-time rendering with lod-structured 3d gaussians.arXiv preprint arXiv:2403.17898, 2024. 3
-
[79]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159,
-
[80]
Viplanner: Visual semantic imperative learn- ing for local navigation
Pascal Roth, Julian Nubert, Fan Yang, Mayank Mittal, and Marco Hutter. Viplanner: Visual semantic imperative learn- ing for local navigation. InInternational Conference on Robotics and Automation (ICRA), pages 5243–5249. IEEE,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.