Recognition: 2 theorem links
· Lean TheoremWhat Drives Representation Steering? A Mechanistic Case Study on Steering Refusal
Pith reviewed 2026-05-10 17:43 UTC · model grok-4.3
The pith
Steering vectors for refusal in LLMs mainly modify the output-value attention circuit and largely bypass query-key scoring.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
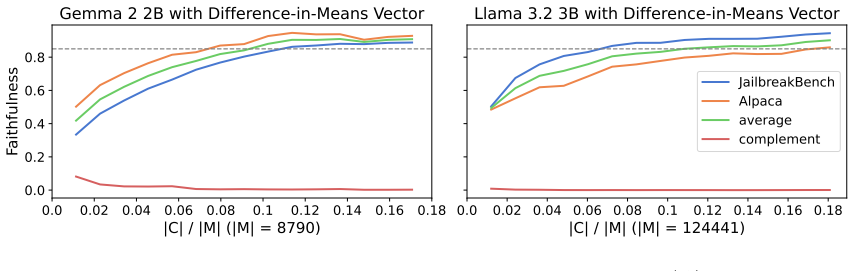
Different steering methods applied at the same layer recruit functionally interchangeable circuits that operate primarily through the OV component of attention. Freezing the attention scores (QK circuit) during steering reduces refusal performance by only 8.75 percent across two model families. A mathematical decomposition of the steered OV circuit isolates semantically meaningful concepts even when the original steering vector lacks clear interpretability. The patching results further allow sparsification of steering vectors by 90-99 percent while preserving most of their effect, and different methods converge on a shared subset of critical dimensions.
What carries the argument
Multi-token activation patching framework that isolates the causal contribution of the OV versus QK circuits inside attention layers during steering.
If this is right
- Steering vectors can be reduced to 1-10 percent of their original dimensions while retaining most refusal control.
- Different steering techniques converge on the same small set of important dimensions at a given layer.
- The OV circuit after steering contains readable semantic directions that can be read out directly.
- Steering applied at the same layer produces equivalent functional effects regardless of the exact vector construction method.
Where Pith is reading between the lines
- The OV dominance may extend to steering other behaviors beyond refusal, allowing targeted circuit edits rather than full retraining.
- Directly modifying the OV weights in attention layers could provide a cheaper alternative to generating and applying steering vectors.
- The same patching approach could be used to compare steering with other alignment methods such as preference tuning.
- If the pattern holds across more tasks, it would imply that many high-level behaviors are routed through a narrow set of attention output pathways.
Load-bearing premise
The patching procedure cleanly separates causal mechanisms without creating artifacts from the patching operation itself or from the specific refusal dataset and models chosen.
What would settle it
An experiment in which freezing attention scores during steering causes refusal performance to drop by more than 50 percent on the same models and tasks would falsify the claim that the OV circuit carries most of the effect.
Figures


















read the original abstract
Applying steering vectors to large language models (LLMs) is an efficient and effective model alignment technique, but we lack an interpretable explanation for how it works-- specifically, what internal mechanisms steering vectors affect and how this results in different model outputs. To investigate the causal mechanisms underlying the effectiveness of steering vectors, we conduct a comprehensive case study on refusal. We propose a multi-token activation patching framework and discover that different steering methodologies leverage functionally interchangeable circuits when applied at the same layer. These circuits reveal that steering vectors primarily interact with the attention mechanism through the OV circuit while largely ignoring the QK circuit-- freezing all attention scores during steering drops performance by only 8.75% across two model families. A mathematical decomposition of the steered OV circuit further reveals semantically interpretable concepts, even in cases where the steering vector itself does not. Leveraging the activation patching results, we show that steering vectors can be sparsified by up to 90-99% while retaining most performance, and that different steering methodologies agree on a subset of important dimensions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a mechanistic case study on how representation steering vectors affect refusal behavior in LLMs. Using a proposed multi-token activation patching framework, it claims that steering vectors primarily interact with the attention mechanism through the OV circuit while largely ignoring the QK circuit, as evidenced by freezing all attention scores during steering causing only an 8.75% performance drop across two model families. It further shows that different steering methods leverage interchangeable circuits at the same layer, that steering vectors can be sparsified by 90-99% while retaining most performance, and that they agree on a subset of important dimensions, with a mathematical decomposition revealing interpretable concepts in the steered OV circuit.
Significance. If the central results hold under rigorous controls, the work offers a causal, mechanistic explanation for steering effectiveness that could guide more precise and efficient alignment interventions. The activation-patching approach provides a concrete way to isolate circuit contributions, and the sparsification finding has immediate practical value for deployment. The decomposition into interpretable concepts strengthens the link between steering vectors and model internals.
major comments (2)
- [Results (OV/QK analysis)] Results section on OV/QK circuits: the central claim that steering vectors largely ignore the QK circuit rests on the reported 8.75% performance drop when freezing attention scores. This requires explicit reporting of per-prompt variance, statistical significance tests, and ablations on the freezing implementation (global vs. per-head, original vs. mean scores) to rule out that the small drop reflects dataset robustness rather than true QK irrelevance.
- [Methods (multi-token activation patching)] Methods section describing the multi-token activation patching framework: the isolation of OV vs. QK contributions assumes the patching operation cleanly disables QK-mediated updates without side-effects on value propagation, residual-stream steering, or later layers. Additional controls are needed to address potential artifacts from global freezing in multi-token refusal settings, such as position-specific dynamics or indirect effects on query/key projections.
minor comments (2)
- [Abstract] The abstract summarizes empirical findings but omits key details on the specific models, refusal datasets, and statistical controls used, which are necessary for evaluating the claims.
- [Decomposition analysis] Notation for the mathematical decomposition of the steered OV circuit should be clarified with explicit equations showing how semantic concepts are extracted.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights opportunities to strengthen the rigor of our OV/QK analysis and multi-token patching framework. We address each major comment below and will incorporate the requested analyses and controls in the revised manuscript.
read point-by-point responses
-
Referee: [Results (OV/QK analysis)] Results section on OV/QK circuits: the central claim that steering vectors largely ignore the QK circuit rests on the reported 8.75% performance drop when freezing attention scores. This requires explicit reporting of per-prompt variance, statistical significance tests, and ablations on the freezing implementation (global vs. per-head, original vs. mean scores) to rule out that the small drop reflects dataset robustness rather than true QK irrelevance.
Authors: We agree that additional statistical detail will better substantiate the claim. In the revision we will report per-prompt standard deviation for the 8.75% drop, include paired statistical significance tests across prompts, and add ablations comparing global vs. per-head freezing as well as original vs. mean attention scores. These controls confirm the drop remains small and consistent across variants, indicating the result is not an artifact of dataset robustness but reflects genuine QK bypass by the steering vector. revision: yes
-
Referee: [Methods (multi-token activation patching)] Methods section describing the multi-token activation patching framework: the isolation of OV vs. QK contributions assumes the patching operation cleanly disables QK-mediated updates without side-effects on value propagation, residual-stream steering, or later layers. Additional controls are needed to address potential artifacts from global freezing in multi-token refusal settings, such as position-specific dynamics or indirect effects on query/key projections.
Authors: We acknowledge that global freezing in multi-token settings could introduce artifacts. We will expand the Methods and Results sections with targeted controls: position-specific attention-score analysis during refusal generation, separate ablations that freeze only query or key projections, and direct comparisons verifying that value propagation and residual-stream steering remain unaffected. These additions will demonstrate that the observed OV dominance is not an artifact of the patching procedure. revision: yes
Circularity Check
No circularity: empirical activation-patching results are independent of inputs
full rationale
The paper's claims rest on direct experimental interventions (multi-token activation patching and attention-score freezing) whose outcomes are measured against observed model behavior on refusal tasks. These measurements do not reduce by construction to fitted parameters, self-definitions, or prior self-citations; the 8.75% drop figure is an observed quantity, not a renamed input. No mathematical derivations are presented that equate to their own premises, and the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
freezing all attention scores during steering drops performance by only 8.75% across two model families
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
steering value vector decomposition... svvh(s) = (s ⊙ γ) W_h^OV
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Prompt-Activation Duality: Improving Activation Steering via Attention-Level Interventions
GCAD reduces coherence drift from -18.6 to -1.9 and raises turn-10 trait expression from 78.0 to 93.1 in persona-steering tasks by using gated attention-delta interventions from system prompts.
-
Prompt-Activation Duality: Improving Activation Steering via Attention-Level Interventions
GCAD steering extracts prompt-based attention deltas and gates them at token level, cutting coherence drift from -18.6 to -1.9 while raising trait expression at turn 10 from 78 to 93 on multi-turn persona benchmarks.
Reference graph
Works this paper leans on
-
[1]
Marco Ancona, Enea Ceolini, Cengiz Öztireli, and Markus Gross. 2018. https://openreview.net/forum?id=Sy21R9JAW Towards better understanding of gradient-based attribution methods for deep neural networks . In International Conference on Learning Representations
2018
-
[2]
Edelman, Zhaowei Zhang, Mario G \"u nther, Anton Korinek, Jose Hernandez-Orallo, Lewis Hammond, Eric J Bigelow, Alexander Pan, Lauro Langosco, and 23 others
Usman Anwar, Abulhair Saparov, Javier Rando, Daniel Paleka, Miles Turpin, Peter Hase, Ekdeep Singh Lubana, Erik Jenner, Stephen Casper, Oliver Sourbut, Benjamin L. Edelman, Zhaowei Zhang, Mario G \"u nther, Anton Korinek, Jose Hernandez-Orallo, Lewis Hammond, Eric J Bigelow, Alexander Pan, Lauro Langosco, and 23 others. 2024. https://openreview.net/forum?...
2024
-
[3]
Andy Arditi, Oscar Balcells Obeso, Aaquib Syed, Daniel Paleka, Nina Rimsky, Wes Gurnee, and Neel Nanda. 2024. https://openreview.net/forum?id=pH3XAQME6c Refusal in language models is mediated by a single direction . In The Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[4]
Nora Belrose. 2023. https://blog.eleuther.ai/diff-in-means/ Diff-in-means concept editing is worst-case optimal: Explaining a result by sam marks and max tegmark
2023
-
[5]
Joschka Braun, Carsten Eickhoff, David Krueger, Seyed Ali Bahrainian, and Dmitrii Krasheninnikov. 2025. https://openreview.net/forum?id=JZiKuvIK1t Understanding (un)reliability of steering vectors in language models . In ICLR 2025 Workshop on Building Trust in Language Models and Applications
2025
-
[6]
Yuanpu Cao, Tianrong Zhang, Bochuan Cao, Ziyi Yin, Lu Lin, Fenglong Ma, and Jinghui Chen. 2024. https://doi.org/10.52202/079017-1567 Personalized steering of large language models: Versatile steering vectors through bi-directional preference optimization . In Advances in Neural Information Processing Systems, volume 37, pages 49519--49551. Curran Associates, Inc
-
[7]
Pappas, Florian Tram \`e r, Hamed Hassani, and Eric Wong
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tram \`e r, Hamed Hassani, and Eric Wong. 2024. https://openreview.net/forum?id=urjPCYZt0I Jailbreakbench: An open robustness benchmark for jailbreaking large language models . In The Thir...
2024
-
[8]
Runjin Chen, Andy Arditi, Henry Sleight, Owain Evans, and Jack Lindsey. 2025. https://arxiv.org/abs/2507.21509 Persona vectors: Monitoring and controlling character traits in language models . Preprint, arXiv:2507.21509
work page internal anchor Pith review arXiv 2025
-
[9]
Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adri \`a Garriga-Alonso
Arthur Conmy, Augustine N. Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adri \`a Garriga-Alonso. 2023. https://openreview.net/forum?id=89ia77nZ8u Towards automated circuit discovery for mechanistic interpretability . In Thirty-seventh Conference on Neural Information Processing Systems
2023
-
[10]
Patrick Queiroz Da Silva, Hari Sethuraman, Dheeraj Rajagopal, Hannaneh Hajishirzi, and Sachin Kumar. 2025. https://doi.org/10.18653/v1/2025.acl-long.974 Steering off course: Reliability challenges in steering language models . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 19856--1...
-
[11]
Tobin Driscoll and Richard Braun. 2017. Fundamentals of Numerical Computation. Society for Industrial and Applied Mathematics
2017
-
[12]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. 2022. https://transformer-circuits.pub/2022/toy_model/index.html Toy models of superposition
2022
-
[13]
Zijian Feng, Tianjiao Li, Zixiao Zhu, Hanzhang Zhou, Junlang Qian, Li Zhang, Chua Jia Jim Deryl, Mak Lee Onn, Gee Wah Ng, and Kezhi Mao. 2026. https://openreview.net/forum?id=guSVafqhrB Fine-grained activation steering: Steering less, achieving more . In The Fourteenth International Conference on Learning Representations
2026
-
[14]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, and 1 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3 herd of models . Preprint, arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Michael Hanna, Sandro Pezzelle, and Yonatan Belinkov. 2024. https://openreview.net/forum?id=TZ0CCGDcuT Have faith in faithfulness: Going beyond circuit overlap when finding model mechanisms . In First Conference on Language Modeling
2024
- [16]
-
[17]
Lee, Inkit Padhi, Karthikeyan Natesan Ramamurthy, Erik Miehling, Pierre Dognin, Manish Nagireddy, and Amit Dhurandhar
Bruce W. Lee, Inkit Padhi, Karthikeyan Natesan Ramamurthy, Erik Miehling, Pierre Dognin, Manish Nagireddy, and Amit Dhurandhar. 2025. https://openreview.net/forum?id=Oi47wc10sm Programming refusal with conditional activation steering . In The Thirteenth International Conference on Learning Representations
2025
-
[18]
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Samuel Marks, Can Rager, Eric J. Michaud, Yonatan Belinkov, David Bau, and Aaron Mueller. 2025. https://arxiv.org/abs/2403.19647 Sparse feature circuits: Discovering and editing interpretable causal graphs in language models . Preprint, arXiv:2403.19647
work page internal anchor Pith review arXiv 2025
-
[19]
Mantas Mazeika, Dan Hendrycks, Huichen Li, Xiaojun Xu, Sidney Hough, Andy Zou, Arezoo Rajabi, Qi Yao, Zihao Wang, Jian Tian, Yao Tang, Di Tang, Roman Smirnov, Pavel Pleskov, Nikita Benkovich, Dawn Song, Radha Poovendran, Bo Li, and David. Forsyth. 2022. https://proceedings.mlr.press/v220/mazeika23a.html The trojan detection challenge . In Proceedings of t...
2022
-
[20]
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. 2024. https://openreview.net/forum?id=f3TUipYU3U Harmbench: A standardized evaluation framework for automated red teaming and robust refusal . In Forty-first International Conference on Machine Learning
2024
-
[21]
Kevin Meng, David Bau, Alex J Andonian, and Yonatan Belinkov. 2022. https://openreview.net/forum?id=-h6WAS6eE4 Locating and editing factual associations in GPT . In Advances in Neural Information Processing Systems
2022
-
[22]
Aaron Mueller, Atticus Geiger, Sarah Wiegreffe, Dana Arad, Iv \'a n Arcuschin, Adam Belfki, Yik Siu Chan, Jaden Fried Fiotto-Kaufman, Tal Haklay, Michael Hanna, Jing Huang, Rohan Gupta, Yaniv Nikankin, Hadas Orgad, Nikhil Prakash, Anja Reusch, Aruna Sankaranarayanan, Shun Shao, Alessandro Stolfo, and 4 others. 2025. https://openreview.net/forum?id=sSrOwve...
2025
-
[23]
Neel Nanda. 2023. https://www.lesswrong.com/posts/gtLLBhzQTG6nKTeCZ/attribution-patching-activation-patching-at-industrial-scale Attribution patching: Activation patching at industrial scale
2023
-
[24]
nostalgebraist. 2020. https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens interpreting gpt: the logit lens
2020
- [25]
-
[26]
Daniele Potert \`i , Andrea Seveso, and Fabio Mercorio. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.963 Can role vectors affect LLM behaviour? In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 17735--17747, Suzhou, China. Association for Computational Linguistics
-
[27]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728--53741
2023
-
[28]
Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Turner. 2024. https://doi.org/10.18653/v1/2024.acl-long.828 Steering llama 2 via contrastive activation addition . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15504--15522, Bangkok, Thailand. Assoc...
-
[29]
Viacheslav Sinii, Nikita Balagansky, Yaroslav Aksenov, Vadim Kurochkin, Daniil Laptev, Alexey Gorbatovski, Boris Shaposhnikov, and Daniil Gavrilov. 2025. https://openreview.net/forum?id=M8WDG1TfBb Small vectors, big effects: A mechanistic study of RL -induced reasoning via steering vectors . In Mechanistic Interpretability Workshop at NeurIPS 2025
2025
- [30]
-
[31]
Alessandro Stolfo, Yonatan Belinkov, and Mrinmaya Sachan. 2023. A mechanistic interpretation of arithmetic reasoning in language models using causal mediation analysis. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7035--7052
2023
-
[32]
Nishant Subramani, Nivedita Suresh, and Matthew Peters. 2022. https://doi.org/10.18653/v1/2022.findings-acl.48 Extracting latent steering vectors from pretrained language models . In Findings of the Association for Computational Linguistics: ACL 2022, pages 566--581, Dublin, Ireland. Association for Computational Linguistics
- [33]
-
[34]
Aaquib Syed, Can Rager, and Arthur Conmy. 2024. https://doi.org/10.18653/v1/2024.blackboxnlp-1.25 Attribution patching outperforms automated circuit discovery . In Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pages 407--416, Miami, Florida, US. Association for Computational Linguistics
-
[35]
Hashimoto
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. https://github.com/tatsu-lab/stanford_alpaca Stanford alpaca: An instruction-following llama model
2023
-
[36]
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, Johan Ferret, Peter Liu, Pouya Tafti, Abe Friesen, Michelle Casbon, Sabela Ramos, Ravin Kumar, Charline Le Lan, Sammy Jerome, and 179 others. 2024. https://arxiv.org/abs/2408.00118 Gemma 2: ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. 2023. Steering language models with activation engineering. arXiv preprint arXiv:2308.10248
work page internal anchor Pith review arXiv 2023
-
[38]
TurnTrout, Monte M, David Udell, lisathiergart, and Ulisse Mini. 2023. https://www.lesswrong.com/posts/5spBue2z2tw4JuDCx/steering-gpt-2-xl-by-adding-an-activation-vector Steering gpt-2-xl by adding an activation vector
2023
- [39]
-
[40]
Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, and Stuart Shieber. 2020. https://proceedings.neurips.cc/paper_files/paper/2020/file/92650b2e92217715fe312e6fa7b90d82-Paper.pdf Investigating gender bias in language models using causal mediation analysis . In Advances in Neural Information Processing Systems, volume ...
2020
-
[41]
Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. 2023. https://openreview.net/forum?id=NpsVSN6o4ul Interpretability in the wild: a circuit for indirect object identification in GPT -2 small . In The Eleventh International Conference on Learning Representations
2023
-
[42]
Xinpeng Wang, Chengzhi Hu, Paul R \"o ttger, and Barbara Plank. 2025. https://openreview.net/forum?id=SCBn8MCLwc Surgical, cheap, and flexible: Mitigating false refusal in language models via single vector ablation . In The Thirteenth International Conference on Learning Representations
2025
-
[43]
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/file/fd6613131889a4b656206c50a8bd7790-Paper-Conference.pdf Jailbroken: How does llm safety training fail? In Advances in Neural Information Processing Systems, volume 36, pages 80079--80110. Curran Associates, Inc
2023
-
[44]
Sarah Wiegreffe, Oyvind Tafjord, Yonatan Belinkov, Hannaneh Hajishirzi, and Ashish Sabharwal. 2025. https://openreview.net/forum?id=6NNA0MxhCH Answer, assemble, ace: Understanding how LM s answer multiple choice questions . In The Thirteenth International Conference on Learning Representations
2025
-
[45]
a ger, Jannes Elstner, Simon Geisler, Vincent Cohen-Addad, Stephan G \
Tom Wollschl \"a ger, Jannes Elstner, Simon Geisler, Vincent Cohen-Addad, Stephan G \"u nnemann, and Johannes Gasteiger. 2025. https://openreview.net/forum?id=80IwJqlXs8 The geometry of refusal in large language models: Concept cones and representational independence . In Forty-second International Conference on Machine Learning
2025
-
[46]
Zhengxuan Wu, Aryaman Arora, Atticus Geiger, Zheng Wang, Jing Huang, Dan Jurafsky, Christopher D Manning, and Christopher Potts. 2025 a . https://openreview.net/forum?id=K2CckZjNy0 Axbench: Steering LLM s? even simple baselines outperform sparse autoencoders . In Forty-second International Conference on Machine Learning
2025
-
[47]
Zhengxuan Wu, Qinan Yu, Aryaman Arora, Christopher D Manning, and Christopher Potts. 2025 b . https://openreview.net/forum?id=VHb883Gs1u Improved representation steering for language models . In The Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[48]
Zihao Xu, Yi Liu, Gelei Deng, Yuekang Li, and Stjepan Picek. 2024. https://doi.org/10.18653/v1/2024.findings-acl.443 A comprehensive study of jailbreak attack versus defense for large language models . In Findings of the Association for Computational Linguistics: ACL 2024, pages 7432--7449, Bangkok, Thailand. Association for Computational Linguistics
-
[49]
Lei Yu, Virginie Do, Karen Hambardzumyan, and Nicola Cancedda. 2025. https://openreview.net/forum?id=s5orchdb33 Robust LLM safeguarding via refusal feature adversarial training . In The Thirteenth International Conference on Learning Representations
2025
-
[50]
Fred Zhang and Neel Nanda. 2024. https://openreview.net/forum?id=Hf17y6u9BC Towards best practices of activation patching in language models: Metrics and methods . In The Twelfth International Conference on Learning Representations
2024
-
[51]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, and 2 others. 2025. https://arxiv.org/abs/2310.01405 Representation engineering: A top-...
work page internal anchor Pith review arXiv 2025
-
[52]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. 2023. https://arxiv.org/abs/2307.15043 Universal and transferable adversarial attacks on aligned language models . Preprint, arXiv:2307.15043
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[53]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[54]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.