Recognition: unknown
Self-Improving 4D Perception via Self-Distillation
Pith reviewed 2026-05-10 17:28 UTC · model grok-4.3
The pith
A self-distillation scheme with spatiotemporal asymmetry lets 4D perception models improve themselves on unlabeled videos
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SelfEvo enables self-improvement of 4D perception by using a self-distillation scheme based on spatiotemporal context asymmetry to supply a stable supervisory signal from unlabeled videos, producing measurable gains in video depth estimation and camera pose estimation without any external 3D or 4D annotations.
What carries the argument
Spatiotemporal context asymmetry in self-distillation, which presents the model with differing temporal and spatial views of the same unlabeled video sequence to create a non-collapsing training target.
If this is right
- Video depth estimation improves by up to 36.5 percent relative to the starting model.
- Camera pose estimation improves by up to 20.1 percent relative to the starting model.
- Gains appear across eight diverse benchmarks and hold when the method is applied to different base models such as VGGT and π^{3}.
- The largest benefits occur on dynamic scenes where motion makes reconstruction harder.
Where Pith is reading between the lines
- Large unlabeled video datasets become more valuable for advancing 4D perception if the self-improvement loop holds.
- The same asymmetry principle could be tested on other perception tasks that currently require expensive 3D labels.
Load-bearing premise
The asymmetry in spatiotemporal context during self-distillation supplies a stable supervisory signal that drives genuine improvement on unlabeled dynamic videos instead of collapse or simple preservation of the original performance.
What would settle it
Applying the full SelfEvo training loop to a fresh collection of unlabeled dynamic videos and measuring no gain, or an actual drop, in video depth and camera estimation accuracy relative to the original pretrained model.
Figures






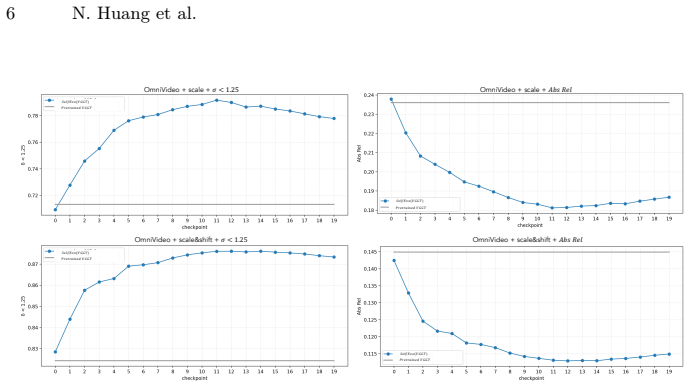
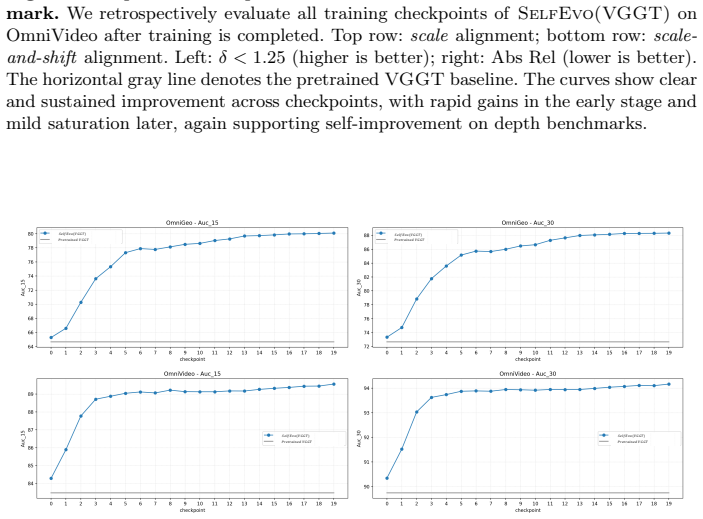

read the original abstract
Large-scale multi-view reconstruction models have made remarkable progress, but most existing approaches still rely on fully supervised training with ground-truth 3D/4D annotations. Such annotations are expensive and particularly scarce for dynamic scenes, limiting scalability. We propose SelfEvo, a self-improving framework that continually improves pretrained multi-view reconstruction models using unlabeled videos. SelfEvo introduces a self-distillation scheme using spatiotemporal context asymmetry, enabling self-improvement for learning-based 4D perception without external annotations. We systematically study design choices that make self-improvement effective, including loss signals, forms of asymmetry, and other training strategies. Across eight benchmarks spanning diverse datasets and domains, SelfEvo consistently improves pretrained baselines and generalizes across base models (e.g. VGGT and $\pi^3$), with significant gains on dynamic scenes. Overall, SelfEvo achieves up to 36.5% relative improvement in video depth estimation and 20.1% in camera estimation, without using any labeled data. Project Page: https://self-evo.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SelfEvo, a self-improving framework for pretrained multi-view 4D reconstruction models. It employs a self-distillation scheme based on spatiotemporal context asymmetry to enable continual improvement on unlabeled dynamic videos, without any external 3D/4D annotations. The authors systematically examine design choices (loss signals, asymmetry forms, training strategies) and report consistent gains across eight benchmarks on two base models (VGGT and π³), with relative improvements reaching 36.5% on video depth estimation and 20.1% on camera estimation, particularly on dynamic scenes.
Significance. If the empirical results hold under rigorous verification, the work has clear significance for scalable 4D perception: it directly tackles the annotation bottleneck for dynamic scenes by turning abundant unlabeled video into a self-improvement signal. The reported generalization across base models and the explicit design study that avoids collapse are strengths that could influence future self-supervised 4D pipelines.
major comments (2)
- [Experiments] Experiments section: the central claim of consistent, non-trivial self-improvement rests on the quantitative gains (36.5 % depth, 20.1 % camera). However, the reported numbers lack accompanying error bars, statistical significance tests, and per-scene breakdowns that would confirm the gains are robust rather than driven by a few easy sequences or post-hoc metric selection.
- [§3] §3 (Method), spatiotemporal asymmetry definition: the claim that the asymmetry supplies a strictly more informative signal than the model's own predictions on dynamic regions is load-bearing. The paper should explicitly demonstrate (via an additional controlled ablation) that removing the asymmetry collapses performance to the pretrained baseline or worse, rather than merely preserving it.
minor comments (3)
- [Abstract / §1] The abstract and introduction repeatedly cite “up to 36.5 %” and “20.1 %” relative improvement; these should be accompanied by the absolute metric values and the exact baseline numbers in the main text for immediate interpretability.
- [Figure 2] Figure 2 (framework diagram) would benefit from explicit arrows or labels indicating which frames are used as context versus target in the asymmetry construction.
- [§2] Related-work section should add a short paragraph contrasting SelfEvo with recent self-distillation methods in monocular depth and video reconstruction to clarify the novelty of the spatiotemporal asymmetry.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation, the recommendation of minor revision, and the constructive comments on empirical robustness and methodological validation. We address each major comment point by point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim of consistent, non-trivial self-improvement rests on the quantitative gains (36.5 % depth, 20.1 % camera). However, the reported numbers lack accompanying error bars, statistical significance tests, and per-scene breakdowns that would confirm the gains are robust rather than driven by a few easy sequences or post-hoc metric selection.
Authors: We agree that error bars, significance testing, and per-scene analysis would strengthen the presentation of robustness. In the revised version we will report standard deviations computed over multiple independent runs with different random seeds, include statistical significance tests (e.g., paired t-tests) against the pretrained baselines, and add per-scene breakdowns for the primary benchmarks in the supplementary material. These additions will demonstrate that the reported relative gains are consistent rather than driven by outlier sequences. revision: yes
-
Referee: [§3] §3 (Method), spatiotemporal asymmetry definition: the claim that the asymmetry supplies a strictly more informative signal than the model's own predictions on dynamic regions is load-bearing. The paper should explicitly demonstrate (via an additional controlled ablation) that removing the asymmetry collapses performance to the pretrained baseline or worse, rather than merely preserving it.
Authors: We appreciate this request for a more direct demonstration. Our existing ablations already compare the full SelfEvo pipeline against a symmetric (no-asymmetry) variant and show that the latter yields no improvement. To address the referee's point explicitly, we will add a controlled ablation in the revised §3 and supplementary material that isolates the removal of spatiotemporal asymmetry while keeping all other components fixed; the results will show that performance reverts to (or falls below) the pretrained baseline, confirming that the asymmetry is necessary to generate the self-improvement signal on dynamic regions. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical self-distillation framework for improving pretrained 4D perception models on unlabeled videos, with gains measured on external benchmarks. No equations, derivations, or first-principles predictions are presented that reduce by construction to the method's own inputs or fitted parameters. The self-distillation signal is defined operationally via spatiotemporal asymmetry and evaluated through ablation studies and cross-model generalization, remaining independent of the reported performance metrics. No self-citation chains or uniqueness theorems are invoked as load-bearing justifications for the core claims.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Communications of the ACM54(10), 105–112 (2011) 3
Agarwal, S., Furukawa, Y., Snavely, N., Simon, I., Curless, B., Seitz, S.M., Szeliski, R.: Building rome in a day. Communications of the ACM54(10), 105–112 (2011) 3
2011
-
[2]
AI, B.: Egocentric-10k (2025),https://huggingface.co/datasets/builddotai/ Egocentric-10K1, 7
2025
-
[3]
In: Euro- pean conference on computer vision
Bay, H., Tuytelaars, T., Van Gool, L.: Surf: Speeded up robust features. In: Euro- pean conference on computer vision. pp. 404–417. Springer (2006) 3
2006
-
[4]
Advances in neural information processing systems32(2019) 3
Bian, J., Li, Z., Wang, N., Zhan, H., Shen, C., Cheng, M.M., Reid, I.: Unsupervised scale-consistent depth and ego-motion learning from monocular video. Advances in neural information processing systems32(2019) 3
2019
-
[5]
Bozic, A., Palafox, P., Thies, J., Dai, A., Niessner, M.: Transformerfusion: Monoc- ular rgb scene reconstruction using transformers. Proc. Neural Information Pro- cessing Systems (NeurIPS) (2021) 7, 8
2021
-
[6]
In: Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining
Buciluˇ a, C., Caruana, R., Niculescu-Mizil, A.: Model compression. In: Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining. pp. 535–541 (2006) 4 SelfEvo: Self-Improving 4D Perception via Self-Distillation 15
2006
-
[7]
In: Proceedings of the IEEE/CVF international conference on computer vision
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9650–9660 (2021) 4
2021
-
[8]
In: arXiv (2020) 3
Chan, E., Monteiro, M., Kellnhofer, P., Wu, J., Wetzstein, G.: pi-gan: Periodic implicit generative adversarial networks for 3d-aware image synthesis. In: arXiv (2020) 3
2020
-
[9]
Self-supervised flow matching for scalable multi-modal synthesis, 2026
Chefer, H., Esser, P., Lorenz, D., Podell, D., Raja, V., Tong, V., Torralba, A., Rombach, R.: Self-supervised flow matching for scalable multi-modal synthesis. arXiv preprint arXiv:2603.06507 (2026) 4
-
[10]
Advances in neural information pro- cessing systems33, 22243–22255 (2020) 4
Chen, T., Kornblith, S., Swersky, K., Norouzi, M., Hinton, G.E.: Big self-supervised models are strong semi-supervised learners. Advances in neural information pro- cessing systems33, 22243–22255 (2020) 4
2020
-
[11]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Chen, Z., Qin, M., Yuan, T., Liu, Z., Zhao, H.: Long3r: Long sequence streaming 3d reconstruction. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 5273–5284 (2025) 3
2025
-
[12]
In: Proc
Dai,A.,Chang,A.X.,Savva,M.,Halber,M.,Funkhouser,T.,Nießner,M.:Scannet: Richly-annotated 3d reconstructions of indoor scenes. In: Proc. Computer Vision and Pattern Recognition (CVPR), IEEE (2017) 1
2017
-
[13]
arXiv preprint arXiv:2512.08930 (2025) 4
Deng, Y., Peng, S., Zhang, J., Heal, K., Sun, T., Flynn, J., Marschner, S., Chai, L.: Selfi: Self improving reconstruction engine via 3d geometric feature alignment. arXiv preprint arXiv:2512.08930 (2025) 4
-
[14]
In: Proceedings of the IEEE conference on com- puter vision and pattern recognition workshops
DeTone, D., Malisiewicz, T., Rabinovich, A.: Superpoint: Self-supervised interest point detection and description. In: Proceedings of the IEEE conference on com- puter vision and pattern recognition workshops. pp. 224–236 (2018) 3
2018
-
[15]
In: Proceedings of the Asian Conference on Computer Vision
Doersch, C., Luc, P., Yang, Y., Gokay, D., Koppula, S., Gupta, A., Heyward, J., Rocco, I., Goroshin, R., Carreira, J., et al.: Bootstap: Bootstrapped training for tracking-any-point. In: Proceedings of the Asian Conference on Computer Vision. pp. 3257–3274 (2024) 4
2024
-
[16]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A.: An image is worth 16x16 words: Transformers for image recogni- tion at scale. arXiv preprint arXiv:2010.11929 (2020) 3
work page internal anchor Pith review Pith/arXiv arXiv 2010
- [17]
-
[18]
In: Proceedings of the ieee/cvf conference on computer vision and pattern recognition
Dusmanu, M., Rocco, I., Pajdla, T., Pollefeys, M., Sivic, J., Torii, A., Sattler, T.: D2-net: A trainable cnn for joint description and detection of local features. In: Proceedings of the ieee/cvf conference on computer vision and pattern recognition. pp. 8092–8101 (2019) 3
2019
-
[19]
arXiv preprint arXiv:2210.07181 (2022) 3
Fu, Y., Misra, I., Wang, X.: Mononerf: Learning generalizable nerfs from monocular videos without camera poses. arXiv preprint arXiv:2210.07181 (2022) 3
-
[20]
Foundations and trends®in Computer Graphics and Vision9(1-2), 1–148 (2015) 3
Furukawa, Y., Hernández, C., et al.: Multi-view stereo: A tutorial. Foundations and trends®in Computer Graphics and Vision9(1-2), 1–148 (2015) 3
2015
-
[21]
The International Journal of Robotics Research32(11), 1231–1237 (2013) 7, 8
Geiger, A., Lenz, P., Stiller, C., Urtasun, R.: Vision meets robotics: The kitti dataset. The International Journal of Robotics Research32(11), 1231–1237 (2013) 7, 8
2013
-
[22]
In: Proceedings of the IEEE/CVF in- ternational conference on computer vision
Godard, C., Mac Aodha, O., Firman, M., Brostow, G.J.: Digging into self- supervised monocular depth estimation. In: Proceedings of the IEEE/CVF in- ternational conference on computer vision. pp. 3828–3838 (2019) 3
2019
-
[23]
arXiv preprint arXiv:2512.04012 (2025) 3
Han, J., Hong, S., Jung, J., Jang, W., An, H., Wang, Q., Kim, S., Feng, C.: Emergent outlier view rejection in visual geometry grounded transformers. arXiv preprint arXiv:2512.04012 (2025) 11 16 N. Huang et al
-
[24]
Hartley, R.: Multiple view geometry in computer vision, vol. 665. Cambridge uni- versity press (2003) 3
2003
-
[25]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 (2015) 4
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[26]
Rayzer: A Self- supervised Large View Synthesis Model.arXiv preprint arXiv:2505.00702, 2025
Jiang, H., Tan, H., Wang, P., Jin, H., Zhao, Y., Bi, S., Zhang, K., Luan, F., Sunkavalli, K., Huang, Q., et al.: Rayzer: A self-supervised large view synthesis model. arXiv preprint arXiv:2505.00702 (2025) 3
-
[27]
In: ECCV (2018) 3
Kanazawa, A., Tulsiani, S., Efros, A.A., Malik, J.: Learning category-specific mesh reconstruction from image collections. In: ECCV (2018) 3
2018
-
[28]
Keetha, N., Müller, N., Schönberger, J., Porzi, L., Zhang, Y., Fischer, T., Knapitsch, A., Zauss, D., Weber, E., Antunes, N., Luiten, J., Lopez-Antequera, M., Bulò, S.R., Richardt, C., Ramanan, D., Scherer, S., Kontschieder, P.: MapA- nything: Universal feed-forward metric 3D reconstruction (2025), arXiv preprint arXiv:2509.13414 1
work page internal anchor Pith review arXiv 2025
-
[29]
Khazatsky, A., Pertsch, K., Nair, S., Balakrishna, A., Dasari, S., Karamcheti, S., Nasiriany, S., Srirama, M.K., Chen, L.Y., Ellis, K., Fagan, P.D., Hejna, J., Itkina, M., Lepert, M., Ma, Y.J., Miller, P.T., Wu, J., Belkhale, S., Dass, S., Ha, H., Jain, A., Lee, A., Lee, Y., Memmel, M., Park, S., Radosavovic, I., Wang, K., Zhan, A., Black, K., Chi, C., Ha...
2024
-
[30]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Lai, Z., Liu, S., Efros, A.A., Wang, X.: Video autoencoder: self-supervised disen- tanglement of static 3d structure and motion. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9730–9740 (2021) 3
2021
-
[31]
In: European Conference on Computer Vision
Leroy, V., Cabon, Y., Revaud, J.: Grounding image matching in 3d with mast3r. In: European Conference on Computer Vision. pp. 71–91. Springer (2024) 3
2024
-
[32]
In: Advances in Neural Information Processing Systems (NeurIPS) (2020) 3
Lin, C.H., Wang, C., Lucey, S.: Sdf-srn: Learning signed distance 3d object re- construction from static images. In: Advances in Neural Information Processing Systems (NeurIPS) (2020) 3
2020
-
[33]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J.H., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647 (2025) 2, 3
work page internal anchor Pith review arXiv 2025
-
[34]
In: Proceedings of the IEEE/CVF international conference on com- puter vision
Lindenberger, P., Sarlin, P.E., Pollefeys, M.: Lightglue: Local feature matching at light speed. In: Proceedings of the IEEE/CVF international conference on com- puter vision. pp. 17627–17638 (2023) 3
2023
-
[35]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Liu, Y., Liu, Y., Jiang, C., Lyu, K., Wan, W., Shen, H., Liang, B., Fu, Z., Wang, H., Yi, L.: Hoi4d: A 4d egocentric dataset for category-level human-object interaction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 21013–21022 (June 2022) 3, 9, 10
2022
-
[36]
In: Proceedings of the seventh IEEE international conference on computer vision
Lowe, D.G.: Object recognition from local scale-invariant features. In: Proceedings of the seventh IEEE international conference on computer vision. vol. 2, pp. 1150–
-
[37]
Ieee (1999) 3 SelfEvo: Self-Improving 4D Perception via Self-Distillation 17
1999
-
[38]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Lu, J., Huang, T., Li, P., Dou, Z., Lin, C., Cui, Z., Dong, Z., Yeung, S.K., Wang, W., Liu, Y.: Align3r: Aligned monocular depth estimation for dynamic videos. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 22820–22830 (2025) 3
2025
-
[39]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Mahjourian, R., Wicke, M., Angelova, A.: Unsupervised learning of depth and ego- motion from monocular video using 3d geometric constraints. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 5667–5675 (2018) 3
2018
-
[40]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Murai, R., Dexheimer, E., Davison, A.J.: Mast3r-slam: Real-time dense slam with 3d reconstruction priors. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 16695–16705 (2025) 3
2025
-
[41]
In: IEEE Conf
Mustikovela, S.K., Jampani, V., De Mello, S., Liu, S., Iqbal, U., Rother, C., Kautz, J.: Self-supervised viewpoint learning from image collections. In: IEEE Conf. on Computer Vision and Pattern Recognition (CVPR) (June 2020) 3
2020
-
[42]
In: The IEEE Interna- tional Conference on Computer Vision (ICCV) (Nov 2019) 3
Nguyen-Phuoc, T., Li, C., Theis, L., Richardt, C., Yang, Y.L.: Hologan: Unsuper- vised learning of 3d representations from natural images. In: The IEEE Interna- tional Conference on Computer Vision (ICCV) (Nov 2019) 3
2019
-
[43]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023) 4, 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
In: 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Palazzolo, E., Behley, J., Lottes, P., Giguere, P., Stachniss, C.: Refusion: 3d recon- struction in dynamic environments for rgb-d cameras exploiting residuals. In: 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 7855–7862. IEEE (2019) 7, 8, 12
2019
-
[45]
In: CVPR (2025) 1, 7, 8
Rockwell, C., Tung, J., Lin, T.Y., Liu, M.Y., Fouhey, D.F., Lin, C.H.: Dynamic camera poses and where to find them. In: CVPR (2025) 1, 7, 8
2025
-
[46]
CVPR (2023) 3
Sajjadi,M.S.M.,Mahendran,A.,Kipf,T.,Pot,E.,Duckworth,D.,Lučić,M.,Greff, K.: RUST: Latent Neural Scene Representations from Unposed Imagery. CVPR (2023) 3
2023
-
[47]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Sarlin, P.E., DeTone, D., Malisiewicz, T., Rabinovich, A.: Superglue: Learning feature matching with graph neural networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4938–4947 (2020) 3
2020
-
[48]
In: European conference on computer vision
Schönberger, J.L., Zheng, E., Frahm, J.M., Pollefeys, M.: Pixelwise view selection for unstructured multi-view stereo. In: European conference on computer vision. pp. 501–518. Springer (2016) 3
2016
-
[49]
In: Conference on Computer Vision and Pattern Recognition (CVPR) (2016) 3
Schönberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: Conference on Computer Vision and Pattern Recognition (CVPR) (2016) 3
2016
-
[50]
In: European Conference on Computer Vision (ECCV) (2016) 3
Schönberger, J.L., Zheng, E., Pollefeys, M., Frahm, J.M.: Pixelwise view selection for unstructured multi-view stereo. In: European Conference on Computer Vision (ECCV) (2016) 3
2016
-
[51]
Advances in neural information processing systems 33, 20154–20166 (2020) 3
Schwarz, K., Liao, Y., Niemeyer, M., Geiger, A.: Graf: Generative radiance fields for 3d-aware image synthesis. Advances in neural information processing systems 33, 20154–20166 (2020) 3
2020
-
[52]
Self-Distillation Enables Continual Learning
Shenfeld, I., Damani, M., Hübotter, J., Agrawal, P.: Self-distillation enables con- tinual learning. arXiv preprint arXiv:2601.19897 (2026) 4
work page internal anchor Pith review arXiv 2026
-
[53]
In: ACM siggraph 2006 papers, pp
Snavely, N., Seitz, S.M., Szeliski, R.: Photo tourism: exploring photo collections in 3d. In: ACM siggraph 2006 papers, pp. 835–846 (2006) 3
2006
-
[54]
Song, Y., Chen, L., Tajwar, F., Munos, R., Pathak, D., Bagnell, J.A., Singh, A., Zanette, A.: Expanding the capabilities of reinforcement learning via text feedback. arXiv preprint arXiv:2602.02482 (2026) 4 18 N. Huang et al
-
[55]
Mv-dust3r+: Single-stage scene reconstruction from sparse views in 2 seconds
Tang,Z.,Fan,Y.,Wang,D.,Xu,H.,Ranjan,R.,Schwing,A.,Yan,Z.:Mv-dust3r+: Single-stage scene reconstruction from sparse views in 2 seconds. arXiv preprint arXiv:2412.06974 (2024) 3
-
[56]
Advances in neural information processing systems30(2017) 4
Tarvainen, A., Valpola, H.: Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Advances in neural information processing systems30(2017) 4
2017
-
[57]
In: The Thirty- ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2025) 2, 6
Tesch, J., Becherini, G., Achar, P., Yiannakidis, A., Kocabas, M., Patel, P., Black, M.J.: BEDLAM2.0: Synthetic humans and cameras in motion. In: The Thirty- ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2025) 2, 6
2025
-
[58]
In: International conference on machine learning
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., Jégou, H.: Training data-efficient image transformers & distillation through attention. In: International conference on machine learning. pp. 10347–10357. PMLR (2021) 4
2021
-
[59]
Advances in neural information pro- cessing systems30(2017) 3
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017) 3
2017
-
[60]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5294–5306 (2025) 2, 3, 4, 6, 7, 8, 10
2025
-
[61]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, Q., Zhang, Y., Holynski, A., Efros, A.A., Kanazawa, A.: Continuous 3d perception model with persistent state. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 10510–10522 (2025) 3, 7
2025
-
[62]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: Dust3r: Geometric 3d vision made easy. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20697–20709 (2024) 2, 3, 7
2024
-
[63]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Wang, Y., Zhou, J., Zhu, H., Chang, W., Zhou, Y., Li, Z., Chen, J., Pang, J., Shen, C., He, T.: pi-3: Permutation-equivariant visual geometry learning. arXiv preprint arXiv:2507.13347 (2025) 2, 3, 4, 6, 7, 8
work page internal anchor Pith review arXiv 2025
-
[64]
In: ICCV (2023) 3
Weinzaepfel, P., Lucas, T., Leroy, V., Cabon, Y., Arora, V., Brégier, R., Csurka, G., Antsfeld, L., Chidlovskii, B., Revaud, J.: CroCo v2: Improved Cross-view Com- pletion Pre-training for Stereo Matching and Optical Flow. In: ICCV (2023) 3
2023
-
[65]
In: NeurIPS (2022) 3
Weinzaepfel, Philippe and Leroy, Vincent and Lucas, Thomas and Brégier, Romain and Cabon, Yohann and Arora, Vaibhav and Antsfeld, Leonid and Chidlovskii, Boris and Csurka, Gabriela and Revaud Jérôme: CroCo: Self-Supervised Pre- training for 3D Vision Tasks by Cross-View Completion. In: NeurIPS (2022) 3
2022
-
[66]
In: 2013 Interna- tional Conference on 3D Vision-3DV 2013
Wu, C.: Towards linear-time incremental structure from motion. In: 2013 Interna- tional Conference on 3D Vision-3DV 2013. pp. 127–134. IEEE (2013) 3
2013
-
[67]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xie, Q., Luong, M.T., Hovy, E., Le, Q.V.: Self-training with noisy student improves imagenet classification. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10687–10698 (2020) 4
2020
-
[68]
Advances in neural information processing systems29(2016) 3
Yan, X., Yang, J., Yumer, E., Guo, Y., Lee, H.: Perspective transformer nets: Learning single-view 3d object reconstruction without 3d supervision. Advances in neural information processing systems29(2016) 3
2016
-
[69]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Yang, J., Sax, A., Liang, K.J., Henaff, M., Tang, H., Cao, A., Chai, J., Meier, F., Feiszli, M.: Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21924–21935 (2025) 3
2025
-
[70]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang, L., Kang, B., Huang, Z., Xu, X., Feng, J., Zhao, H.: Depth anything: Un- leashing the power of large-scale unlabeled data. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10371–10381 (2024) 4 SelfEvo: Self-Improving 4D Perception via Self-Distillation 19
2024
-
[71]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang,N.,Stumberg,L.v.,Wang,R.,Cremers,D.:D3vo:Deepdepth,deepposeand deep uncertainty for monocular visual odometry. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1281–1292 (2020) 3
2020
-
[72]
In: Proceedings of the European conference on computer vision (ECCV)
Yao, Y., Luo, Z., Li, S., Fang, T., Quan, L.: Mvsnet: Depth inference for unstruc- tured multi-view stereo. In: Proceedings of the European conference on computer vision (ECCV). pp. 767–783 (2018) 3
2018
-
[73]
In: European conference on computer vision
Yi, K.M., Trulls, E., Lepetit, V., Fua, P.: Lift: Learned invariant feature transform. In: European conference on computer vision. pp. 467–483. Springer (2016) 3
2016
-
[74]
In: Proceedings of the IEEE/CVF international conference on computer vision
Yun, S., Han, D., Oh, S.J., Chun, S., Choe, J., Yoo, Y.: Cutmix: Regularization strategy to train strong classifiers with localizable features. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 6023–6032 (2019) 4
2019
-
[75]
arXiv preprint arXiv:2410.03825 (2024)
Zhang, J., Herrmann, C., Hur, J., Jampani, V., Darrell, T., Cole, F., Sun, D., Yang, M.H.: Monst3r: A simple approach for estimating geometry in the presence of motion. arXiv preprint arXiv:2410.03825 (2024) 3, 7
-
[76]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhang, L., Song, J., Gao, A., Chen, J., Bao, C., Ma, K.: Be your own teacher: Improve the performance of convolutional neural networks via self distillation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3713–3722 (2019) 4
2019
-
[77]
Zhang, R., Bai, R.H., Zheng, H., Jaitly, N., Collobert, R., Zhang, Y.: Em- barrassingly simple self-distillation improves code generation. arXiv preprint arXiv:2604.01193 (2026) 4
-
[78]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhang, S., Wang, J., Xu, Y., Xue, N., Rupprecht, C., Zhou, X., Shen, Y., Wet- zstein, G.: Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21936–21947 (2025) 3
2025
-
[79]
arXiv preprint arXiv:2512.10950 (2025) 3
Zhao, Q., Tan, H., Wang, Q., Bi, S., Zhang, K., Sunkavalli, K., Tulsiani, S., Jiang, H.: E-rayzer: Self-supervised 3d reconstruction as spatial visual pre-training. arXiv preprint arXiv:2512.10950 (2025) 3
-
[80]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhou, T., Brown, M., Snavely, N., Lowe, D.G.: Unsupervised learning of depth and ego-motion from video. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1851–1858 (2017) 3
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.