Recognition: unknown
RewardFlow: Generate Images by Optimizing What You Reward
Pith reviewed 2026-05-10 17:21 UTC · model grok-4.3
The pith
RewardFlow steers pretrained diffusion models at inference time by optimizing multiple differentiable rewards through Langevin dynamics guided by a prompt-aware adaptive policy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
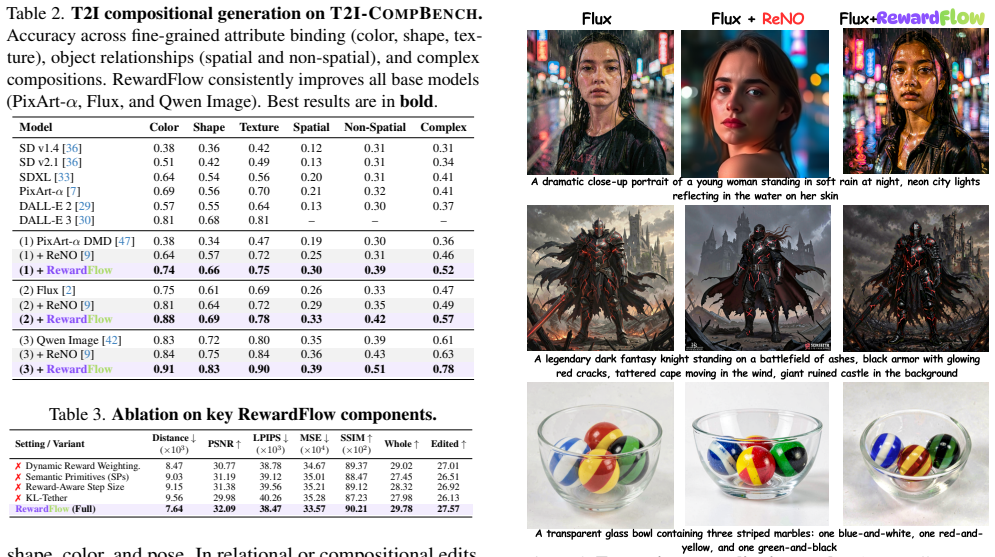
RewardFlow unifies complementary differentiable rewards for semantic alignment, perceptual fidelity, localized grounding, object consistency, and human preference, and further introduces a differentiable VQA-based reward that provides fine-grained semantic supervision through language-vision reasoning. To coordinate these heterogeneous objectives, it designs a prompt-aware adaptive policy that extracts semantic primitives from the instruction, infers edit intent, and dynamically modulates reward weights and step sizes throughout sampling. This is realized via multi-reward Langevin dynamics applied at inference time to steer pretrained diffusion and flow-matching models.
What carries the argument
Multi-reward Langevin dynamics coordinated by a prompt-aware adaptive policy that infers edit intent from the input prompt and dynamically modulates individual reward weights plus step sizes during sampling.
If this is right
- Delivers higher edit fidelity by jointly optimizing semantic, perceptual, and consistency objectives during sampling.
- Achieves stronger compositional alignment through the addition of fine-grained VQA-based supervision.
- Applies directly to existing pretrained models without requiring inversion or retraining.
- Enables automatic, prompt-dependent adjustment of reward influence instead of manual hyperparameter search.
Where Pith is reading between the lines
- The approach could be tested on video or 3D generation by defining analogous differentiable rewards for temporal consistency or depth.
- It opens a route for incorporating external reasoning models directly into the generative sampling loop rather than only at evaluation time.
- Users might define task-specific reward combinations at runtime to steer outputs toward particular stylistic or factual constraints.
- The framework suggests a path to reduce reliance on classifier-free guidance by letting explicit rewards take over more of the control burden.
Load-bearing premise
That the different rewards can be balanced by the adaptive policy without producing conflicts or instabilities in the sampling trajectory.
What would settle it
A controlled experiment on a standard image-editing benchmark that replaces the prompt-aware adaptive policy with fixed equal weights and measures whether edit fidelity and compositional alignment fall below the levels reported for the full method.
Figures














read the original abstract
We introduce RewardFlow, an inversion-free framework that steers pretrained diffusion and flow-matching models at inference time through multi-reward Langevin dynamics. RewardFlow unifies complementary differentiable rewards for semantic alignment, perceptual fidelity, localized grounding, object consistency, and human preference, and further introduces a differentiable VQA-based reward that provides fine-grained semantic supervision through language-vision reasoning. To coordinate these heterogeneous objectives, we design a prompt-aware adaptive policy that extracts semantic primitives from the instruction, infers edit intent, and dynamically modulates reward weights and step sizes throughout sampling. Across several image editing and compositional generation benchmarks, RewardFlow delivers state-of-the-art edit fidelity and compositional alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RewardFlow, an inversion-free framework for steering pretrained diffusion and flow-matching models at inference time via multi-reward Langevin dynamics. It unifies differentiable rewards for semantic alignment, perceptual fidelity, localized grounding, object consistency, and human preference, while introducing a new differentiable VQA-based reward for fine-grained language-vision supervision. A prompt-aware adaptive policy is proposed to extract semantic primitives from instructions, infer edit intent, and dynamically modulate reward weights and step sizes. The central claim is state-of-the-art edit fidelity and compositional alignment across image editing and compositional generation benchmarks.
Significance. If the empirical claims hold with proper validation, the work could meaningfully advance inference-time control in generative models by enabling flexible, training-free coordination of heterogeneous objectives through Langevin dynamics. The introduction of a differentiable VQA reward and the adaptive policy represent potentially useful technical ideas for multi-objective optimization in diffusion-based generation.
major comments (2)
- [Method (prompt-aware adaptive policy)] The description of the prompt-aware adaptive policy (in the method section) asserts that it resolves objective conflicts and prevents sampling instabilities across heterogeneous rewards, but provides no quantitative analysis of reward trade-offs, trajectory variance, or failure modes on conflicting objectives; this mechanism is load-bearing for the SOTA claim on edit fidelity and compositional alignment.
- [Abstract and Experiments] The abstract and results overview assert SOTA performance on several benchmarks but supply no quantitative metrics, baselines, ablation studies, or error analysis to support the central claim; without these, the effectiveness of the unified rewards and adaptive coordination cannot be verified.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., a metric improvement) to substantiate the SOTA assertion.
- [Method] Notation for the Langevin dynamics update and reward weighting should be made fully explicit with equations to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We appreciate the emphasis on strengthening the empirical support for the prompt-aware adaptive policy and the SOTA claims. We address each major comment below and commit to revisions that provide the requested quantitative analysis and clearer experimental presentation.
read point-by-point responses
-
Referee: [Method (prompt-aware adaptive policy)] The description of the prompt-aware adaptive policy (in the method section) asserts that it resolves objective conflicts and prevents sampling instabilities across heterogeneous rewards, but provides no quantitative analysis of reward trade-offs, trajectory variance, or failure modes on conflicting objectives; this mechanism is load-bearing for the SOTA claim on edit fidelity and compositional alignment.
Authors: We agree that a dedicated quantitative analysis of the adaptive policy is necessary to substantiate its role in managing heterogeneous rewards. The current manuscript demonstrates the policy's benefits through end-to-end performance on benchmarks but does not isolate metrics such as reward trade-off curves, trajectory variance statistics, or explicit failure cases under conflicting objectives. In the revised version, we will add a new subsection with ablations that report these quantities (e.g., variance in reward gradients and sampling trajectories with/without adaptation, Pareto analysis on conflicting reward pairs, and qualitative/quantitative failure modes). This will directly bolster the SOTA claims on edit fidelity and compositional alignment. revision: yes
-
Referee: [Abstract and Experiments] The abstract and results overview assert SOTA performance on several benchmarks but supply no quantitative metrics, baselines, ablation studies, or error analysis to support the central claim; without these, the effectiveness of the unified rewards and adaptive coordination cannot be verified.
Authors: We acknowledge that the abstract and high-level results overview currently state SOTA outcomes without accompanying numbers or error analysis, which limits immediate verifiability. The detailed experimental section does contain quantitative comparisons, baselines, and ablations, but these are not sufficiently highlighted in the overview. In the revision, we will (1) update the abstract to include key quantitative highlights (e.g., specific metric improvements over baselines), (2) expand the results overview with a concise table of main metrics, baseline comparisons, and error bars, and (3) add explicit error analysis and additional ablations on reward unification and adaptive coordination. These changes will make the central claims directly verifiable from the overview. revision: yes
Circularity Check
No circularity: RewardFlow derivation is self-contained using external pretrained models and rewards
full rationale
The paper presents RewardFlow as an inference-time framework that applies multi-reward Langevin dynamics to steer existing pretrained diffusion and flow-matching models. It unifies complementary differentiable rewards drawn from prior literature (semantic, perceptual, grounding, consistency, preference, and a new VQA-based reward) and introduces a prompt-aware adaptive policy to modulate them. No equations or method steps reduce by construction to self-defined quantities, fitted inputs renamed as predictions, or load-bearing self-citations whose validity depends on the current work. The central claims of SOTA performance are evaluated on external benchmarks rather than being forced by internal definitions or prior author results invoked as uniqueness theorems. The coordination mechanism, while an assumption, is not circular; it is an empirical claim tested via benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Edicho: Consistent image editing in the wild
Qingyan Bai, Hao Ouyang, Yinghao Xu, Qiuyu Wang, Ceyuan Yang, Ka Leong Cheng, Yujun Shen, and Qifeng Chen. Edicho: Consistent image editing in the wild. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025. 2
2025
-
[2]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Black Forest Labs. FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space. arXiv preprint arXiv:2506.15742, 2025. 1, 5, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[4]
Ledits++: Limitless image editing us- ing text-to-image models
Manuel Brack, Felix Friedrich, Katharia Kornmeier, Linoy Tsaban, Patrick Schramowski, Kristian Kersting, and Apolinário Passos. Ledits++: Limitless image editing us- ing text-to-image models. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 2
2024
-
[5]
In- structpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. In- structpix2pix: Learning to follow image editing instructions. InIEEE Conference on Computer Vision and Pattern Recog- nition (CVPR), 2023. 2
2023
-
[6]
Training-Free Reward-Guided Image Editing via Trajectory Optimal Control
Jinho Chang, Jaemin Kim, and Jong Chul Ye. Training-free reward-guided image editing via trajectory optimal control. arXiv preprint arXiv:2509.25845, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Pixart- α: Fast training of diffusion transformer for photorealistic text-to-image synthesis
Junsong Chen, YU Jincheng, GE Chongjian, Lewei Yao, Enze Xie, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart- α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. InIn- ternational Conference on Learning Representations (ICLR),
-
[8]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim En- tezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InInternational Conference on Machine Learning (ICML), 2024. 1
2024
-
[9]
Reno: Enhancing one-step text-to-image models through reward-based noise optimiza- tion.Advances in Neural Information Processing Systems (NeurIPS), 2024
Luca Eyring, Shyamgopal Karthik, Karsten Roth, Alexey Dosovitskiy, and Zeynep Akata. Reno: Enhancing one-step text-to-image models through reward-based noise optimiza- tion.Advances in Neural Information Processing Systems (NeurIPS), 2024. 2, 7
2024
-
[10]
An image is worth one word: Personalizing text-to-image generation using textual inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit Haim Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image generation using textual inversion. InInternational Confer- ence on Learning Representations (ICLR), 2022. 2
2022
-
[11]
Controllable first-frame-guided video editing via mask-aware lora fine-tuning
Chenjian Gao, Lihe Ding, Xin Cai, Zhanpeng Huang, Zibin Wang, and Tianfan Xue. Controllable first-frame-guided video editing via mask-aware lora fine-tuning. InInterna- tional Conference on Learning Representations (ICLR), 2025. 2
2025
-
[12]
Instantedit: Text-guided few-step image editing with piecewise rectified flow
Yiming Gong, Zhen Zhu, and Minjia Zhang. Instantedit: Text-guided few-step image editing with piecewise rectified flow. InInternational Conference on Computer Vision (ICCV),
-
[13]
Generative adversarial networks.Communi- cations of the ACM, 2020
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks.Communi- cations of the ACM, 2020. 2
2020
-
[14]
Proxedit: Improving tuning-free real image editing with proximal guidance
Ligong Han, Song Wen, Qi Chen, Zhixing Zhang, Kunpeng Song, Mengwei Ren, Ruijiang Gao, Anastasis Stathopou- los, Xiaoxiao He, Yuxiao Chen, et al. Proxedit: Improving tuning-free real image editing with proximal guidance. In IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2024. 5
2024
-
[15]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-Prompt Image Editing with Cross Attention Control. InACM SIGGRAPH Asia, 2022. 2, 5
2022
-
[16]
Denoising diffu- sion probabilistic models.Advances in Neural Information Processing Systems (NeurIPS), 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models.Advances in Neural Information Processing Systems (NeurIPS), 2020. 1
2020
-
[17]
T2i-compbench: A comprehensive benchmark for open- world compositional text-to-image generation.Advances in Neural Information Processing Systems (NeurIPS), 2023
Kaiyi Huang, Kaiyue Sun, Enze Xie, Zhenguo Li, and Xihui Liu. T2i-compbench: A comprehensive benchmark for open- world compositional text-to-image generation.Advances in Neural Information Processing Systems (NeurIPS), 2023. 5
2023
-
[18]
An edit friendly ddpm noise space: Inversion and manipulations
Inbar Huberman-Spiegelglas, Vladimir Kulikov, and Tomer Michaeli. An edit friendly ddpm noise space: Inversion and manipulations. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 5
2024
-
[19]
arXiv preprint arXiv:2310.01506 (2023)
Xuan Ju, Ailing Zeng, Yuxuan Bian, Shaoteng Liu, and Qiang Xu. Direct Inversion: Boosting Diffusion-Based Editing with 3 Lines of Code.arXiv preprint arXiv:2310.01506, 2023. 2, 5
-
[20]
Pnp inversion: Boosting diffusion-based editing with 3 lines of code
Xuan Ju, Ailing Zeng, Yuxuan Bian, Shaoteng Liu, and Qiang Xu. Pnp inversion: Boosting diffusion-based editing with 3 lines of code. InInternational Conference on Learning Representations (ICLR), 2024. 5
2024
-
[21]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2019. 2
2019
-
[22]
Imagic: Text-based real image editing with diffusion models
Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang, Tali Dekel, Inbar Mosseri, and Michal Irani. Imagic: Text-based real image editing with diffusion models. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 2
2023
-
[23]
FlowEdit: Inversion-Free 9 Text-Based Editing Using Pre-Trained Flow Models
Vladimir Kulikov, Matan Kleiner, Inbar Huberman- Spiegelglas, and Tomer Michaeli. FlowEdit: Inversion-Free 9 Text-Based Editing Using Pre-Trained Flow Models. InIn- ternational Conference on Computer Vision (ICCV), 2025. 2, 5
2025
-
[24]
Flow matching for generative mod- eling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative mod- eling. InThe Eleventh International Conference on Learning Representations, 2022. 1
2022
-
[25]
Regiondrag: Fast region- based image editing with diffusion models
Jingyi Lu, Xinghui Li, and Kai Han. Regiondrag: Fast region- based image editing with diffusion models. InEuropean Conference on Computer Vision (ECCV), 2024. 2
2024
-
[26]
Sdedit: Guided image synthesis and editing with stochastic differential equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations. InInternational Conference on Learning Representations (ICLR), 2021. 2
2021
-
[27]
Yunhong Min, Daehyeon Choi, Kyeongmin Yeo, Jihyun Lee, and Minhyuk Sung. Origen: Zero-shot 3d orienta- tion grounding in text-to-image generation.arXiv preprint arXiv:2503.22194, 2025. 2, 3
-
[28]
Null-text inversion for editing real im- ages using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real im- ages using guided diffusion models. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 2
2023
-
[29]
Introducing dall-e 2
OpenAI. Introducing dall-e 2. OpenAI Blog (2022). https: //openai.com/index/dall-e-2/, 2022. 7
2022
-
[30]
Introducing dall-e 3
OpenAI. Introducing dall-e 3. OpenAI Blog (2023). https: //openai.com/dall-e-3, 2023. 7
2023
-
[31]
Styleclip: Text-driven manipulation of stylegan imagery
Or Patashnik, Zongze Wu, Eli Shechtman, Daniel Cohen-Or, and Dani Lischinski. Styleclip: Text-driven manipulation of stylegan imagery. InInternational Conference on Computer Vision (ICCV), 2021. 2
2021
-
[32]
Metaxas, and Yezhou Yang
Maitreya Patel, Song Wen, Dimitris N. Metaxas, and Yezhou Yang. FlowChef: Steering of Rectified Flow Models for Con- trolled Generations. InInternational Conference on Computer Vision (ICCV), 2025. 5
2025
-
[33]
Sdxl: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. InInternational Conference on Learning Representations (ICLR), 2023. 7
2023
-
[34]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning (ICML),
-
[35]
Sam 2: Segment any- thing in images and videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment any- thing in images and videos. InThe Thirteenth International Conference on Learning Representations, 2024. 2, 4
2024
-
[36]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 7
2022
-
[37]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven gen- eration
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven gen- eration. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 2
2023
-
[38]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations,
-
[39]
Postedit: Posterior sampling for effi- cient zero-shot image editing
Feng Tian, Yixuan Li, Yichao Yan, Shanyan Guan, Yanhao Ge, and Xiaokang Yang. Postedit: Posterior sampling for effi- cient zero-shot image editing. InThe Thirteenth International Conference on Learning Representations, 2024. 2
2024
-
[40]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muham- mad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language en- coders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025. 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Training-free text-guided image editing with visual autoregressive model
Yufei Wang, Lanqing Guo, Zhihao Li, Jiaxing Huang, Pichao Wang, Bihan Wen, and Jian Wang. Training-free text-guided image editing with visual autoregressive model. InInterna- tional Conference on Computer Vision (ICCV), 2025. 5
2025
-
[42]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025. 5, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis.arXiv preprint arXiv:2306.09341,
work page internal anchor Pith review arXiv
-
[44]
TurboEdit: Instant Text-Based Im- age Editing Using Few-Step Diffusion Models
Zongze Wu, Nicholas Kolkin, Jonathan Brandt, Richard Zhang, and Eli Shechtman. TurboEdit: Instant Text-Based Im- age Editing Using Few-Step Diffusion Models. InEuropean Conference on Computer Vision (ECCV), 2024. 5
2024
-
[45]
Dymo: Training-free diffusion model alignment with dynamic multi-objective scheduling
Xin Xie and Dong Gong. Dymo: Training-free diffusion model alignment with dynamic multi-objective scheduling. InIEEE Conference on Computer Vision and Pattern Recog- nition (CVPR), 2025. 2
2025
-
[46]
arXiv preprint arXiv:2312.04965 (2023) 18 R.Morita et al
Sihan Xu, Yidong Huang, Jiayi Pan, Ziqiao Ma, and Joyce Chai. Inversion-Free Image Editing with Natural Language. arXiv preprint arXiv:2312.04965, 2023. 5
-
[47]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shecht- man, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2024. 7
2024
-
[48]
RegionCLIP: Region- Based Language-Image Pretraining
Yiwu Zhong, Jianwei Yang, Pengchuan Zhang, Chunyuan Li, Noel Codella, Liunian Harold Li, Luowei Zhou, Xiyang Dai, Lu Yuan, Yin Li, and Jianfeng Gao. RegionCLIP: Region- Based Language-Image Pretraining. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 4
2022
-
[49]
Training-free geometric image editing on diffusion models
Hanshen Zhu, Zhen Zhu, Kaile Zhang, Yiming Gong, Yu- liang Liu, and Xiang Bai. Training-free geometric image editing on diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025. 2 10
2025
-
[50]
KV-Edit: Training-Free Image Editing for Precise Back- ground Preservation
Tianrui Zhu, Shiyi Zhang, Jiawei Shao, and Yansong Tang. KV-Edit: Training-Free Image Editing for Precise Back- ground Preservation. InInternational Conference on Com- puter Vision (ICCV), 2025. 5 11 : Generate Images by Optimizing What You Reward Supplementary Material Figure 8.High-resolution images generated by RewardFlow. 1
2025
-
[51]
(2), specify the diffusion-strength schedule γk, and provide a derivation showing how Eq
SDE Formulation In this section, we detail the stochastic differential equa- tion (SDE) that grounds the Langevin-style reverse update in Eq. (2), specify the diffusion-strength schedule γk, and provide a derivation showing how Eq. (2) emerges from sampling a prompt-tilted latent density. Prompt-tilted target density.Let qt(z|p) denote the un- conditional...
-
[52]
What color is the bench?
Datasets and Evaluation To ensure a fair comparison, we adopt the same evaluation protocols and metrics as defined in the original papers of each respective dataset. T2I-COMPBENCH.T2I-COMPBENCHis a large-scale benchmark designed to evaluate compositional text-to-image generation in open-world settings, and consists of approxi- mately 6,000 prompts categor...
-
[53]
remove cap
Implementation Details In this section, we provide additional implementation details for RewardFlow. An overview of the method is illustrated in Figure 9. Unless otherwise stated, we use the same hy- perparameters across all backbones, datasets, and tasks. All experiments are run on a single node with2× NVIDIA A100 GPUs (80 GB each). We implement RewardFl...
-
[54]
Include: • Visible subject descriptors (pose, angle, clothing items) actually present
Extract short edit prompts:output a compact list of 5–12 atomic, actionable tags/phrases that guide the image edit. Include: • Visible subject descriptors (pose, angle, clothing items) actually present. • The edit action(s) and key visual attributes (style, color, size, placement). • Constraints to preserve identity, lighting, composition, realism, and co...
-
[55]
Unspecified from image
Create exactly one Q&A pair focused on the final edited image’s appearance. • Ask **one** question that would most affect the final look (e.g., style, colorway, size/scale, placement, material/finish, mood/lighting continuity). • Give **one** concise answer based on the image/instruction; if not determinable, answer "Unspecified from image." ## Rules - **...
-
[56]
Additional Results Text-to-Image Generation.We perform additional text-to-image generation evaluation on GENEVAL. As shown in Table 5, RewardFlow consistently improves compositional faithfulness over both backbone models and Table 5.T2I generation on GENEVAL. Model Overall↑Single↑Two↑Counting↑Colors↑Position↑Color Attribution↑ SD v2.1 0.50 0.98 0.51 0.44 ...
-
[57]
as if on psychedelics,
Additional Qualitative Results Image Editing Qualitative Results.Using Flux as the base model, as shown in Figure 12, RewardFlow follows a wide variety of fine-grained instructions while preserving background layout and image identity. RewardFlow can perform strong stylistic changes, such as recoloring the carved wooden ornament “as if on psychedelics,” t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.