Recognition: no theorem link
Can We Still Hear the Accent? Investigating the Resilience of Native Language Signals in the LLM Era
Pith reviewed 2026-05-15 08:55 UTC · model grok-4.3
The pith
Native language signals in ACL research papers have declined steadily since neural networks and LLMs arrived.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
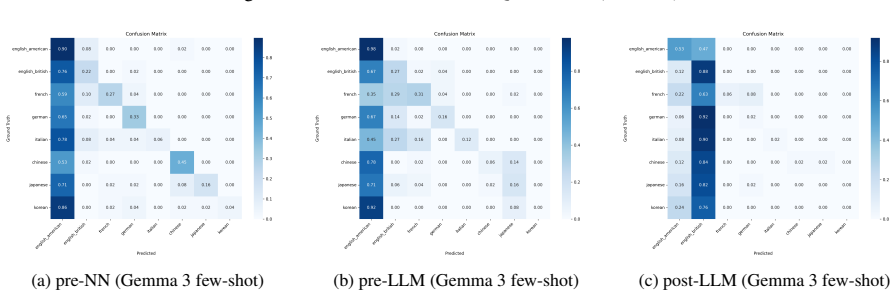
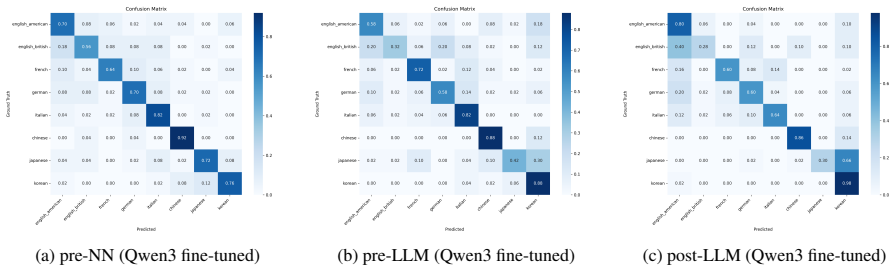
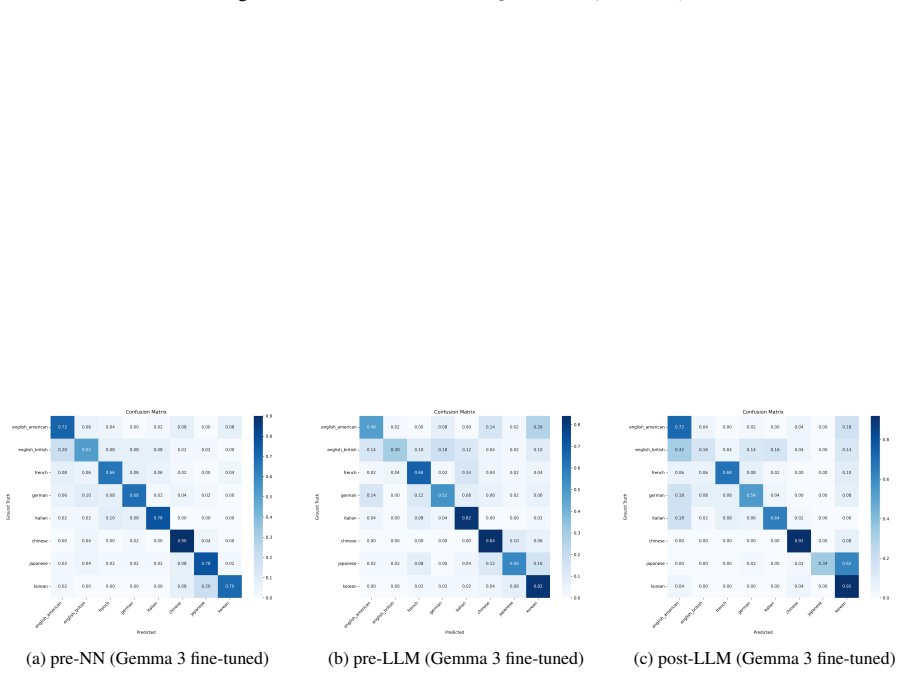
The central claim is that native language identification accuracy on ACL Anthology papers falls consistently from the pre-neural-network era through the post-LLM era, which the authors interpret as evidence that native-language fingerprints are becoming weaker in research writing. In the most recent period the pattern is not uniform: Chinese and French exhibit greater resistance or different trajectories, whereas Japanese and Korean show steeper declines than the overall trend.
What carries the argument
A classifier fine-tuned on a semi-automatically labeled dataset of ACL papers to detect native-language linguistic fingerprints.
If this is right
- Academic writing is becoming more standardized across author backgrounds.
- LLMs appear to help non-native writers produce text closer to native English norms.
- Some languages retain more distinctive signals than others even after LLM adoption.
- Continued homogenization could reduce visible linguistic diversity in the scientific record.
Where Pith is reading between the lines
- Similar signal loss may appear in conference proceedings outside computational linguistics.
- The trend could make it harder to study author demographics or geographic bias using text alone.
- Language-specific exceptions might reflect differences in LLM adoption rates or training data quality across regions.
Load-bearing premise
The semi-automated labels and resulting classifier are isolating genuine native-language signals rather than topic, editing style, or other correlated factors.
What would settle it
Re-label a fresh sample of ACL papers using direct author self-reports of native language and re-train the classifier; if the performance decline disappears, the original trend is likely an artifact of the labeling method.
Figures

read the original abstract
The evolution of writing assistance tools from machine translation to large language models (LLMs) has changed how researchers write. This study investigates whether this shift is homogenizing research papers by analyzing native language identification (NLI) trends in ACL Anthology papers across three eras: pre-neural network (NN), pre-LLM, and post-LLM. We construct a labeled dataset using a semi-automated framework and fine-tune a classifier to detect linguistic fingerprints of author backgrounds. Our analysis shows a consistent decline in NLI performance over time. Interestingly, the post-LLM era reveals anomalies: while Chinese and French show unexpected resistance or divergent trends, Japanese and Korean exhibit sharper-than-expected declines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines whether LLMs are eroding native-language fingerprints in academic writing by measuring native language identification (NLI) accuracy on ACL Anthology papers across pre-neural, pre-LLM, and post-LLM eras. Using a semi-automated labeling procedure to build a dataset and a fine-tuned classifier, it reports a consistent decline in NLI performance over time, with post-LLM anomalies including greater resistance for Chinese and French authors and sharper drops for Japanese and Korean.
Significance. If the reported decline proves robust after controlling for topical and stylistic confounders, the result would provide concrete evidence that LLM-assisted writing is reducing detectable native-language signals in published research, with direct implications for authorship attribution, forensic linguistics, and studies of linguistic homogenization in science.
major comments (3)
- [Methods] The semi-automated labeling procedure (Methods section) does not describe explicit balancing or regression controls for topic distribution, venue, or editing-style covariates across eras; without these, the observed NLI decline could track shifts in ACL Anthology content rather than loss of native-language features.
- [Results] No dataset sizes, classifier architecture details, or statistical tests (e.g., significance of accuracy drops or confidence intervals) are provided to support the claim of a 'consistent decline' or the language-specific anomalies; this prevents assessment of whether the trends are reliable or driven by small samples or post-hoc observations.
- [Experimental Setup] The fine-tuned classifier's ability to isolate native-language signals versus topic or LLM-polishing artifacts is not validated with ablation studies or human evaluation; this is load-bearing for the central claim that performance drops reflect homogenization rather than confounding factors.
minor comments (2)
- [Abstract] The abstract and results would benefit from explicit numerical values for NLI accuracies per era and per language to allow readers to gauge effect sizes.
- [Dataset Construction] Clarify the exact time boundaries used for the three eras (pre-NN, pre-LLM, post-LLM) and how papers were assigned to avoid boundary effects.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods] The semi-automated labeling procedure (Methods section) does not describe explicit balancing or regression controls for topic distribution, venue, or editing-style covariates across eras; without these, the observed NLI decline could track shifts in ACL Anthology content rather than loss of native-language features.
Authors: We agree that explicit controls are necessary to rule out content shifts as a confounder. In the revised manuscript, we will expand the Methods section to describe the topic and venue distributions across the three eras, include explicit balancing steps where feasible, and add regression analyses controlling for topic, venue, and editing-style proxies to demonstrate that the NLI decline persists after these adjustments. revision: yes
-
Referee: [Results] No dataset sizes, classifier architecture details, or statistical tests (e.g., significance of accuracy drops or confidence intervals) are provided to support the claim of a 'consistent decline' or the language-specific anomalies; this prevents assessment of whether the trends are reliable or driven by small samples or post-hoc observations.
Authors: We accept this criticism. The revised version will report exact dataset sizes broken down by era and language, provide complete classifier architecture details (model, hyperparameters, training procedure), and include statistical tests such as bootstrap confidence intervals and significance tests for the accuracy drops and language-specific patterns to allow proper evaluation of reliability. revision: yes
-
Referee: [Experimental Setup] The fine-tuned classifier's ability to isolate native-language signals versus topic or LLM-polishing artifacts is not validated with ablation studies or human evaluation; this is load-bearing for the central claim that performance drops reflect homogenization rather than confounding factors.
Authors: This is a substantive concern. We will add ablation experiments that isolate native-language features by removing topic-related signals (via topic modeling or feature ablation) and will include a human evaluation on a stratified sample of papers to verify that the classifier detects native-language fingerprints rather than topical or polishing artifacts. These results will be reported in the revised manuscript. revision: yes
Circularity Check
No circularity: purely empirical trend measurement
full rationale
The paper reports an empirical analysis of NLI classifier performance on ACL Anthology papers across pre-NN, pre-LLM, and post-LLM eras. It constructs a semi-automated labeled dataset and fine-tunes a classifier to track accuracy trends, with no equations, derivations, fitted parameters renamed as predictions, or self-referential definitions. The central claims rest on observed performance declines and language-specific anomalies, which are directly measurable against the external corpus rather than forced by any internal construction or self-citation chain. No load-bearing steps reduce to the inputs by definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On the Use of ArXiv as a Dataset
On the use of ArXiv as a dataset.Preprint, arXiv:1905.00075. Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[2]
Gemma 3 Technical Report.Preprint, arXiv:2503.19786. Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Authority and invisibility: Authorial identity in academic writing.Journal of Pragmatics, 34(8):1091–1112. Scott Jarvis and Scott. A Crossley. 2012.Approach- ing Language Transfer through Text Classification: Explorations in the Detection-based Approach. Mul- tilingual Matters & Channel View Publications. Tom S Juzek and Zina B. Ward
work page 2012
-
[4]
Jason Priem, Heather Piwowar, and Richard Orr
Mapping the Increasing Use of LLMs in Scientific Papers.Preprint, arXiv:2404.01268. Jason Priem, Heather Piwowar, and Richard Orr
-
[5]
OpenAlex: A fully-open index of scholarly works, authors, venues, institutions, and concepts.Preprint, arXiv:2205.01833. Shaurya Rohatgi
-
[6]
Qwen3 Technical Report.Preprint, arXiv:2505.09388. Aohan Zeng, Xiao Liu, Zhengxiao Du, Zihan Wang, Hanyu Lai, Ming Ding, Zhuoyi Yang, Yifan Xu, Wendi Zheng, Xiao Xia, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Independent Distributions on a Multi-Branching AND-OR Tree of Height 2
GLM- 130B: An open bilingual pre-trained model. InThe Eleventh International Conference on Learning Rep- resentations. A Name Origin Prediction Prompt To generate the candidate countries for our dataset (Section 2.1), we used Qwen3-8B with the follow- ing strict JSON-output prompt. The model was instructed to output the ISO 3166-1 alpha-2 codes for the to...
work page 1983
-
[8]
Tables 7 and 8 summarize the results for the few-shot and fine-tuned settings re- spectively
The significance level was set to α= 0.05 . Tables 7 and 8 summarize the results for the few-shot and fine-tuned settings re- spectively. Language Precision Recall F1-score pre-NN pre-LLM post-LLM pre-NN pre-LLM post-LLM pre-NN pre-LLM post-LLM English (US) 0.603 0.569 0.471 0.700 0.500 0.800 0.6480.574 0.593 English (UK) 0.651 0.696 0.737 0.560 0.320 0.2...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.