Recognition: 2 theorem links
· Lean TheoremRobust Reasoning Benchmark
Pith reviewed 2026-05-15 00:01 UTC · model grok-4.3
The pith
Open-weight reasoning models lose up to 55 percent accuracy when AIME problems receive 14 simple text perturbations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By applying 14 perturbations to AIME 2024 problems, the authors demonstrate that open weights reasoning models undergo catastrophic accuracy collapses of up to 55 percent on average and 100 percent in some cases, while frontier models remain resilient. When models are forced to solve multiple problems sequentially in a single context, accuracy decays on subsequent problems for open weight models from 7B to 120B parameters and for Claude Opus, indicating that intermediate reasoning steps permanently pollute standard dense attention mechanisms. The authors conclude that future reasoning architectures must incorporate explicit contextual resets within Chain-of-Thought to achieve reliability,
What carries the argument
A pipeline of 14 perturbation techniques applied to mathematical problems, combined with sequential multi-problem solving in a fixed context window to isolate attention pollution.
If this is right
- Open-weight models from 7B to 120B parameters exhibit progressive accuracy decay on later problems inside the same context window.
- Frontier models remain largely stable under the same perturbations that collapse open models.
- Intermediate reasoning steps produce lasting interference in standard dense attention.
- Future architectures will need explicit contextual resets inside the chain of thought.
- Questions about the optimal size of atomic reasoning steps become central to reliable performance.
Where Pith is reading between the lines
- The observed fragility may arise because training data rewards surface-form matching more than abstract mathematical structure.
- Architectures that separate working memory from attention, such as sparse or external-memory designs, could avoid the pollution effect.
- Extending the same perturbation and sequential tests to coding or formal logic tasks would show whether the fragility is specific to mathematics.
- If explicit resets prove effective, models could sustain accurate reasoning over much longer chains without retraining.
Load-bearing premise
The 14 perturbations preserve the underlying mathematical content and difficulty so that accuracy drops reflect reasoning or parsing failures rather than changes in problem solvability.
What would settle it
Measuring whether any open-weight model maintains its original accuracy on the perturbed problems while also showing no accuracy decay across a long sequence of unperturbed problems solved in one context.
Figures
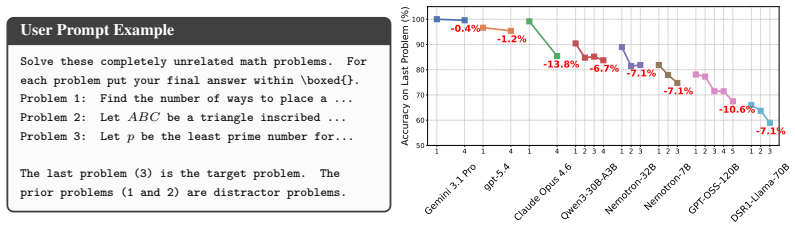






read the original abstract
While Large Language Models (LLMs) achieve high performance on standard mathematical benchmarks, their underlying reasoning processes remain highly overfit to standard textual formatting. We propose a perturbation pipeline consisting of 14 techniques to evaluate robustness of LLM reasoning. We apply this pipeline to AIME 2024 dataset and evalute 8 state-of-the-art models on the resulting benchmark. While frontier models exhibit resilience, open weights reasoning models suffer catastrophic collapses (up to 55% average accuracy drops across perturbations and up to 100% on some), exposing structural fragility. To further disentangle mechanical parsing failures from downstream reasoning failures, we strictly isolate the models' working memory capacity by forcing models to solve multiple unperturbed mathematical problems sequentially within a single context window. Our results indicate that open weight models ranging from 7B to 120B parameters and Claude Opus 4.6 exhibit accuracy decay on subsequent problems. This degradation demonstrates that intermediate reasoning steps permanently pollute standard dense attention mechanisms. We argue that to achieve reliable reasoning, future reasoning architectures must integrate explicit contextual resets within a model's own Chain-of-Thought, leading to fundamental open questions regarding the optimal granularity of atomic reasoning tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a perturbation pipeline of 14 techniques applied to the AIME 2024 dataset to create a robustness benchmark for LLM reasoning. Evaluation across 8 state-of-the-art models shows frontier models are resilient while open-weight reasoning models exhibit large accuracy collapses (up to 55% average drop, 100% on individual perturbations). Sequential solving of unperturbed problems within one context window reveals accuracy decay on later problems, which the authors attribute to permanent pollution of dense attention mechanisms by intermediate CoT steps. The paper concludes that reliable reasoning requires explicit contextual resets inside the model's own Chain-of-Thought.
Significance. If the perturbations are rigorously shown to preserve mathematical content and difficulty, the results would provide concrete evidence of structural limitations in current dense-attention reasoning models and motivate architectures with built-in context management. The empirical scale (AIME 2024 + 14 perturbations + 8 models) and the sequential-decay experiment are potentially useful benchmarks, but the significance is currently limited by the absence of verification that accuracy drops isolate reasoning failures rather than altered problem solvability.
major comments (2)
- [Methods (perturbation pipeline description)] The central claim that accuracy collapses (55% avg, up to 100%) demonstrate 'structural fragility' and 'attention pollution' is load-bearing on the assumption that all 14 perturbations preserve the original mathematical content, unique solution, and difficulty exactly. No verification procedure (human equivalence ratings, automated solution checks, or difficulty metrics) is described for the perturbation pipeline, leaving open the possibility that drops reflect changes in solvability rather than reasoning mechanism failure.
- [Results (sequential unperturbed problems)] The attribution of accuracy decay in the sequential unperturbed-problem experiment to 'permanent pollution' of attention by CoT steps requires controls for prompt-length effects and generic context saturation. Without such controls or ablation (e.g., non-CoT filler text of matched length), the decay cannot be isolated to reasoning-step pollution as claimed.
minor comments (2)
- [Abstract] Typo in abstract: 'evalute' should be 'evaluate'.
- [Abstract] Clarify the exact model referred to as 'Claude Opus 4.6'; standard naming is Claude 3 Opus.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of our methodology and experimental design. We address each major comment below and will incorporate revisions to strengthen the manuscript's claims regarding perturbation validity and the isolation of attention pollution effects.
read point-by-point responses
-
Referee: [Methods (perturbation pipeline description)] The central claim that accuracy collapses (55% avg, up to 100%) demonstrate 'structural fragility' and 'attention pollution' is load-bearing on the assumption that all 14 perturbations preserve the original mathematical content, unique solution, and difficulty exactly. No verification procedure (human equivalence ratings, automated solution checks, or difficulty metrics) is described for the perturbation pipeline, leaving open the possibility that drops reflect changes in solvability rather than reasoning mechanism failure.
Authors: We agree that the absence of an explicit verification procedure in the original manuscript leaves the interpretation of accuracy drops open to the alternative explanation of altered solvability. In the revised version, we will expand the Methods section to describe a verification protocol: (1) human equivalence ratings on a stratified sample of 100 perturbed problems by three independent raters assessing preservation of mathematical content, unique solution, and perceived difficulty on a 1-5 scale; (2) automated checks confirming that the ground-truth answer remains unchanged; and (3) comparison of average solution lengths and lexical complexity metrics between original and perturbed versions. These additions will directly support that the observed collapses reflect reasoning fragility. revision: yes
-
Referee: [Results (sequential unperturbed problems)] The attribution of accuracy decay in the sequential unperturbed-problem experiment to 'permanent pollution' of attention by CoT steps requires controls for prompt-length effects and generic context saturation. Without such controls or ablation (e.g., non-CoT filler text of matched length), the decay cannot be isolated to reasoning-step pollution as claimed.
Authors: We concur that the current sequential experiment lacks controls to rule out generic prompt-length or context-saturation effects. In the revision, we will add an ablation study in which non-CoT filler text (neutral descriptive paragraphs matched for token length and position) is inserted between problems instead of Chain-of-Thought steps. We will report accuracy trajectories under this control condition alongside the original CoT condition, allowing us to quantify the specific contribution of reasoning-step pollution versus general context accumulation. These results will be presented in an updated Results section with corresponding statistical comparisons. revision: yes
Circularity Check
No circularity: purely empirical benchmark with no derivations
full rationale
The paper introduces a perturbation pipeline of 14 techniques and applies it to the AIME 2024 dataset to measure accuracy drops in LLMs. All claims rest on direct experimental measurements of model performance under these perturbations and sequential problem solving, without any equations, fitted parameters, predictions derived from inputs, or self-citation chains that reduce the central results to their own definitions. No load-bearing step equates an output to an input by construction; the evaluation is self-contained against external benchmarks and falsifiable via replication on the same dataset.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Perturbations preserve the mathematical content and correct solution of each AIME problem
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
open weight models ... exhibit accuracy decay on subsequent problems. This degradation demonstrates that intermediate reasoning steps permanently pollute standard dense attention mechanisms
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
14 deterministic structural perturbations ... Information-Theoretic Invariance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
More agents helps but adversarial robustness gap persists, 2025
Khashayar Alavi, Zhastay Yeltay, Lucie Flek, and Akbar Karimi. More agents helps but adversarial robustness gap persists, 2025. URLhttps://arxiv.org/abs/2511.07112
-
[2]
Cutting through the noise: Boosting llm performance on math word problems,
Ujjwala Anantheswaran, Himanshu Gupta, Kevin Scaria, Shreyas Verma, Chitta Baral, and Swaroop Mishra. Cutting through the noise: Boosting llm performance on math word problems,
- [3]
-
[4]
Anthropic. The claude 4.6 model family. Technical report, Anthropic, 2026. URL https: //www.anthropic.com/news/claude-opus-4-6
work page 2026
-
[5]
Google Gemini API. Prompt caching, 2026. URL https://ai.google.dev/gemini-api/ docs/caching
work page 2026
-
[6]
Fragile thoughts: How large language models handle chain-of-thought perturbations, 2026
Ashwath Vaithinathan Aravindan and Mayank Kejriwal. Fragile thoughts: How large language models handle chain-of-thought perturbations, 2026. URL https://arxiv.org/abs/2603. 03332
work page 2026
-
[7]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021. URL https://arxiv.org/ abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Deepseek-r1-distill-llama-70b, January 2025
DeepSeek-AI. Deepseek-r1-distill-llama-70b, January 2025. URL https://huggingface. co/deepseek-ai/DeepSeek-R1-Distill-Llama-70B
work page 2025
-
[9]
Claude API Docs. Prompt caching, 2026. URL https://platform.claude.com/docs/en/ build-with-claude/prompt-caching
work page 2026
-
[10]
Hugging Face. Math verify, 2026. URLhttps://pypi.org/project/math-verify/
work page 2026
-
[11]
Google. Google antigravity, 2026. URLhttps://antigravity.google/
work page 2026
-
[12]
Gemini 3.1: Advancing the state of the art in multimodal reason- ing
Google DeepMind. Gemini 3.1: Advancing the state of the art in multimodal reason- ing. Technical report, Google, 2026. URL https://blog.google/innovation-and-ai/ models-and-research/gemini-models/gemini-3-1-pro/
work page 2026
-
[13]
Yuren Hao, Xiang Wan, and ChengXiang Zhai. An investigation of robustness of llms in mathematical reasoning: Benchmarking with mathematically-equivalent transformation of advanced mathematical problems, 2025. URLhttps://arxiv.org/abs/2508.08833
-
[14]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks,
-
[15]
URLhttps://arxiv.org/abs/2103.03874
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Evaluating LLMs’ mathematical and coding competency through ontology- guided interventions
Pengfei Hong, Navonil Majumder, Deepanway Ghosal, Somak Aditya, Rada Mihalcea, and Soujanya Poria. Evaluating LLMs’ mathematical and coding competency through ontology- guided interventions. InFindings of the Association for Computational Linguistics: ACL 2025, pages 22811–22849, Vienna, Austria, jul 2025. Association for Computational Linguis- tics. doi:...
-
[17]
Automatic robustness stress testing of llms as mathematical problem solvers,
Yutao Hou, Zeguan Xiao, Fei Yu, Yihan Jiang, Xuetao Wei, Hailiang Huang, Yun Chen, and Guanhua Chen. Automatic robustness stress testing of llms as mathematical problem solvers,
-
[18]
URLhttps://arxiv.org/abs/2506.05038. 10
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Math-perturb: Benchmarking llms’ math reasoning abilities against hard perturbations
Kaixuan Huang, Jiacheng Guo, Zihao Li, Xiang Ji, Jiawei Ge, Wenzhe Li, Yingqing Guo, Tianle Cai, Hui Yuan, Runzhe Wang, Yue Wu, Ming Yin, Shange Tang, Yangsibo Huang, Chi Jin, Xinyun Chen, Chiyuan Zhang, and Mengdi Wang. Math-perturb: Benchmarking llms’ math reasoning abilities against hard perturbations. InForty-second International Conference on Machine...
-
[20]
Quantifying artificial intelligence through algorithmic generalization
Takuya Ito, Murray Campbell, Lior Horesh, Tim Klinger, and Parikshit Ram. Quantifying artificial intelligence through algorithmic generalization. InNature Machine Intelligence, 2025. URLhttps://arxiv.org/abs/2411.05943
-
[21]
Su, Camillo Jose Taylor, and Dan Roth
Bowen Jiang, Yangxinyu Xie, Zhuoqun Hao, Xiaomeng Wang, Tanwi Mallick, Weijie J. Su, Camillo Jose Taylor, and Dan Roth. A peek into token bias: Large language models are not yet genuine reasoners. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4722–4756, Miami, Florida, USA, nov 2024. Association fo...
-
[22]
Ming Jiang, Tingting Huang, Biao Guo, Yao Lu, and Feng Zhang. Enhancing robustness in large language models: Prompting for mitigating the impact of irrelevant information, 2025. URLhttps://arxiv.org/abs/2408.10615
-
[23]
Farrar, Straus and Giroux, New York, 2011
Daniel Kahneman.Thinking, fast and slow. Farrar, Straus and Giroux, New York, 2011. ISBN 9780374275631 0374275637. URL https://mlsu.ac.in/econtents/2950_Daniel% 20Kahneman%20-%20Thinking,%20Fast%20and%20Slow%20(2013).pdf
work page 2011
-
[24]
Lost in Cultural Translation: Do LLMs Struggle with Math Across Cultural Contexts?
Aabid Karim, Abdul Karim, Bhoomika Lohana, Matt Keon, Jaswinder Singh, and Abdul Sattar. Lost in cultural translation: Do llms struggle with math across cultural contexts?, 2025. URL https://arxiv.org/abs/2503.18018
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Neeraja Kirtane, Yuvraj Khanna, and Peter Relan. Mathrobust-lv: Evaluation of large language models’ robustness to linguistic variations in mathematical reasoning, 2025. URL https: //arxiv.org/abs/2510.06430
-
[26]
Qintong Li, Leyang Cui, Xueliang Zhao, Lingpeng Kong, and Wei Bi. GSM-plus: A comprehensive benchmark for evaluating the robustness of LLMs as mathematical prob- lem solvers. InProceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers), pages 2961–2984, Bangkok, Thailand, aug
-
[27]
doi: 10.18653/v1/2024.acl-long.163
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.163. URL https://aclanthology.org/2024.acl-long.163
-
[28]
Ride: Difficulty evolving perturbation with item response theory for mathematical reasoning,
Xinyuan Li, Murong Xu, Wenbiao Tao, Hanlun Zhu, Yike Zhao, Jipeng Zhang, and Yunshi Lan. Ride: Difficulty evolving perturbation with item response theory for mathematical reasoning,
- [29]
-
[30]
Mathematical Association of America. Aime 2024 dataset, 2024. URL https:// huggingface.co/datasets/HuggingFaceH4/aime_2024
work page 2024
-
[31]
Thomas McCoy, Shunyu Yao, Dan Friedman, Matthew Hardy, and Thomas L
R. Thomas McCoy, Shunyu Yao, Dan Friedman, Matthew Hardy, and Thomas L. Griffiths. Embers of autoregression: Understanding large language models through the problem they are trained to solve. InProceedings of the National Academy of Sciences (PNAS), 2023. doi: 10. 1073/pnas.2322420121. URLhttps://www.pnas.org/doi/10.1073/pnas.2322420121
-
[32]
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar. Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models. InThe Thirteenth International Conference on Learning Representations (ICLR), 2025. URLhttps://arxiv.org/abs/2410.05229
work page Pith review arXiv 2025
-
[33]
Allen Newell and Herbert A. Simon. Computer science as empirical inquiry: symbols and search.Commun. ACM, 19(3), March 1976. ISSN 0001-0782. doi: 10.1145/360018.360022. URLhttps://doi.org/10.1145/360018.360022
-
[34]
Marianna Nezhurina, Lucia Cipolina-Kun, Mehdi Cherti, and Jenia Jitsev. Alice in wonderland: Simple tasks showing complete reasoning breakdown in state-of-the-art large language models,
- [35]
-
[36]
Openreasoning-nemotron-32b, 2025
NVIDIA. Openreasoning-nemotron-32b, 2025. URL https://huggingface.co/nvidia/ OpenReasoning-Nemotron-32B
work page 2025
-
[37]
Openreasoning-nemotron-7b, 2025
NVIDIA. Openreasoning-nemotron-7b, 2025. URL https://huggingface.co/nvidia/ OpenReasoning-Nemotron-7B
work page 2025
-
[38]
OpenAI. gpt-oss-120b, 2025. URLhttps://huggingface.co/openai/gpt-oss-120b
work page 2025
-
[39]
OpenAI. Gpt-5.4 technical report. Technical report, OpenAI, 2026. URL https://openai. com/index/introducing-gpt-5-4/
work page 2026
-
[40]
OpenAI. Prompt caching, 2026. URL https://openai.com/index/ api-prompt-caching/
work page 2026
-
[41]
VarBench: Robust language model benchmarking through dynamic variable perturbation
Kun Qian, Shunji Wan, Claudia Tang, Youzhi Wang, Xuanming Zhang, Maximillian Chen, and Zhou Yu. VarBench: Robust language model benchmarking through dynamic variable perturbation. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 16131–16161, Miami, Florida, USA, nov 2024. Association for Computational Linguis- tics. doi: 10.1...
-
[42]
Qwen3: The next generation of qwen large language models, 2026
Qwen Team. Qwen3: The next generation of qwen large language models, 2026. URL https://huggingface.co/Qwen/Qwen3-30B-A3B-Thinking-2507
work page 2026
-
[43]
Lost in the middle: An emergent property from information retrieval demands in llms, 2025
Nikolaus Salvatore, Hao Wang, and Qiong Zhang. Lost in the middle: An emergent property from information retrieval demands in llms, 2025. URL https://arxiv.org/abs/2510. 10276
work page 2025
-
[44]
Asymob: Algebraic symbolic mathematical operations benchmark, 2025
Michael Shalyt, Rotem Elimelech, and Ido Kaminer. Asymob: Algebraic symbolic mathematical operations benchmark, 2025. URLhttps://arxiv.org/abs/2505.23851
-
[45]
Chi, Nathanael Schärli, and Denny Zhou
Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H. Chi, Nathanael Schärli, and Denny Zhou. Large language models can be easily distracted by irrelevant context. InProceedings of the 40th International Conference on Machine Learning (ICML), pages 31210–31227, 2023. URLhttps://proceedings.mlr.press/v202/shi23a.html
work page 2023
-
[46]
Parshin Shojaee, Iman Mirzadeh, Keivan Alizadeh, Maxwell Horton, Samy Bengio, and Mehrdad Farajtabar. The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity, 2025. URL https://arxiv.org/abs/ 2506.06941
-
[47]
Functional benchmarks for robust evaluation of reasoning performance, and the reasoning gap
Saurabh Srivastava, Annarose M B, Anto P V , Shashank Menon, Ajay Sukumar, Adwaith Samod T, Alan Philipose, Stevin Prince, and Sooraj Thomas. Functional benchmarks for robust evaluation of reasoning performance, and the reasoning gap, 2024. URL https://arxiv. org/abs/2402.19450
-
[48]
Zhishen Sun, Guang Dai, Ivor Tsang, and Haishan Ye. Numerical sensitivity and robustness: Exploring the flaws of mathematical reasoning in large language models, 2025. URL https: //arxiv.org/abs/2511.08022
-
[49]
Zhishen Sun, Guang Dai, and Haishan Ye. Mscr: Exploring the vulnerability of llms’ mathematical reasoning abilities using multi-source candidate replacement, 2025. URL https://arxiv.org/abs/2511.08055
-
[50]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, S. H. Cai, Yuan Cao, Y . Charles, H. S. Che, Cheng Chen, Guanduo Chen, Huarong Chen, Jia Chen, Jiahao Chen, Jianlong Chen, Jun Chen, Kefan Chen, Liang Chen, Ruijue Chen, Xinhao Chen, Yanru Chen, Yanxu Chen, Yicun Chen, Yimin Chen, Yingjiang Chen, Yuankun Chen, Yujie Chen, Yutian Chen, Zhirong Chen, Ziwei Che...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Technology Innovation Institute. Falcon-h1r: Pushing the reasoning frontiers with a hy- brid model for efficient test-time scaling, January 2026. URL https://huggingface.co/ tiiuae/Falcon-H1R-7B
work page 2026
-
[52]
Leaked: I caught google antigravity’s hidden inner prompt, 2026
Reddit User. Leaked: I caught google antigravity’s hidden inner prompt, 2026. URL https://www.reddit.com/r/google_antigravity/comments/1rl1vjx/leaked_i_ caught_google_antigravitys_hidden_inner/
work page 2026
-
[53]
Alexander von Recum, Leander Girrbach, and Zeynep Akata. Are reasoning llms robust to interventions on their chain-of-thought? InThe Fourteenth International Conference on Learning Representations (ICLR), 2026. URLhttps://arxiv.org/abs/2602.07470
-
[54]
Yuqing Wang and Yun Zhao. Rupbench: Benchmarking reasoning under perturbations for robustness evaluation in large language models, 2024. URL https://arxiv.org/abs/2406. 11020
work page 2024
-
[55]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InProceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, Red Hook, NY , USA, 2022. Curran Associates Inc. ISBN 9781713871088. 13
work page 2022
-
[56]
Wikipedia. Rail fence cipher, 2026. URLhttps://en.wikipedia.org/wiki/Rail_fence_ cipher
work page 2026
-
[57]
On memorization of large language models in logical reasoning
Chulin Xie, Yangsibo Huang, Chiyuan Zhang, Da Yu, Xinyun Chen, Bill Yuchen Lin, Bo Li, Badih Ghazi, and Ravi Kumar. On memorization of large language models in logical reasoning. InProceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Li...
work page 2025
-
[58]
Adversarial math word prob- lem generation
Roy Xie, Chengxuan Huang, Junlin Wang, and Bhuwan Dhingra. Adversarial math word prob- lem generation. pages 5075–5093, Miami, Florida, USA, 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-emnlp.292. URL https://aclanthology.org/ 2024.findings-emnlp.292
-
[59]
Evaluating robustness of LLMs to numerical variations in mathematical reasoning
Yuli Yang, Hiroaki Yamada, and Takenobu Tokunaga. Evaluating robustness of LLMs to numerical variations in mathematical reasoning. InThe Sixth Workshop on Insights from Negative Results in NLP, pages 171–180, Albuquerque, New Mexico, May 2025. Association for Computational Linguistics. doi: 10.18653/v1/2025.insights-1.16. URL https://aclanthology.org/2025...
-
[60]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. InProceedings of the Neural Information Processing Systems, volume 36, 2023. URL https://arxiv.org/abs/2305.10601
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[61]
Alex L. Zhang, Tim Kraska, and Omar Khattab. Recursive language models, 2026. URL https://arxiv.org/abs/2512.24601
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[62]
Yilun Zhao, Guo Gan, Chengye Wang, Chen Zhao, and Arman Cohan. Are multimodal LLMs robust against adversarial perturbations? RoMMath: A systematic evaluation on multimodal math reasoning. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Lingui...
-
[63]
Dynamic evaluation of large language models by meta probing agents
Kaijie Zhu, Jindong Wang, Qinlin Zhao, Ruochen Xu, and Xing Xie. Dynamic evaluation of large language models by meta probing agents. InForty-first International Conference on Machine Learning (ICML), 2024. URLhttps://arxiv.org/abs/2402.14865. A Appendix A.1 A - Methodology Details When the model is given a transformed user query, it is given instructions ...
-
[64]
Word Reversal: The order of words (words are defined as sequences of symbols separated by spaces) in the user query has been reversed
-
[65]
Sentences are defined as sequences of symbols separated by periods
Sentence Reversal: The order of sentences in the user query has been reversed. Sentences are defined as sequences of symbols separated by periods
-
[66]
Interleaved Context Word: User query will consist of two problems - A and B, whose statements are interleaved word by word. First word belongs to problem A, second word belongs to problem B, third word belongs to problem A, and so on. You need to solve only problem A. Words are defined as sequences of symbols separated by spaces. If one problem statement ...
-
[67]
Each segment is followed by a space and a problem tag (e.g
Interleaved Context Line: User query will consist of two problems - A and B, whose statements are split into line segments at most 60 symbols long. Each segment is followed by a space and a problem tag (e.g. problem A or B). The segments are interleaved. You need to solve only problem A. If one problem statement is shorter than the other, the empty lines ...
-
[68]
If the word has odd number of symbols, the first part has one symbol less than the second part
Word Split Swap: Every word (words are defined as sequences of symbols separated by spaces) in user query is split into 2 parts down the middle. If the word has odd number of symbols, the first part has one symbol less than the second part. After splitting, the 2 parts are swapped
-
[69]
Split Reversal: Every word (words are defined as sequences of symbols separated by spaces) in user query has its symbols in reverse order
-
[70]
The remappings are defined inside ’defyn’ block in the middle of user query
Opposites: There will be terms remapped in the user query. The remappings are defined inside ’defyn’ block in the middle of user query
-
[71]
The remappings are defined inside ’defyn’ block in the middle of user query
Wrappers: There will be terms remapped in the user query. The remappings are defined inside ’defyn’ block in the middle of user query
-
[72]
Rail Fence: The user query is encoded using the Rail Fence Cipher. The input is provided as a visual grid where the symbols (including spaces) of the encoded message string (message string does NOT contain any newline characters) are placed in a zigzag pattern across multiple rails (rows), and empty spaces are filled with dots (.). To decode, read the cha...
-
[73]
Rectangle Perimeter: "The user query is mapped onto the perimeter of a rectangle. The message is written as a single continuous string following the edges of the shape in a clockwise manner, beginning at the top-left. The TRANSFORMED INPUT is provided as a visual text block representing this rectangle with GRID START and GRID END markers. The center of th...
-
[74]
Snake Vertical: The user query is written into a grid using a vertical ’snake’ (zigzag) pattern. Starting from the top-left, the text is written down the first column, then up the second column, then down the third, and so on. The TRANSFORMED INPUT is provided as a visual grid with GRID START and GRID END markers
-
[75]
Snake Horizontal: The user query is written into a grid using a horizontal ’snake’ (zigzag) pattern. Starting from the top-left, the text is written across the first row, then left across the second row, then right across the third, and so on. The TRANSFORMED INPUT is provided as a visual grid with GRID START and GRID END markers. Disclosure:This research...
-
[76]
Read the "TRANSFORMATION RULE" provided by the user and reverse the transformation on the "TRANSFORMED INPUT" to obtain the original problem statement
-
[77]
Once you have the original problem statement, proceed to solve the math problem
-
[78]
Put your final answer within\\boxed{}. A.3 Cognitive Thrashing Figure 7 shows the average output token length for each transformation. The number in the center of each bar is the accuracy of the model on that transformation. Analysis of the figure reveals a 15 BaselineNot-Not OppositesWrappers Interleave-LInterleave-WInterleave-S Context Sentence-Rev Word...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.