Recognition: 2 theorem links
· Lean TheoremSilhouette Loss: Differentiable Global Structure Learning for Deep Representations
Pith reviewed 2026-05-14 23:45 UTC · model grok-4.3
The pith
Soft Silhouette Loss adds a batch-level global structure term that raises average top-1 accuracy from 36.71 percent to 39.08 percent when combined with cross-entropy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors demonstrate that a softened per-sample silhouette score, computed by comparing average distance to the own class against distances to all other classes in the batch, supplies an effective global structure signal that improves representation quality and classification accuracy when added to standard objectives.
What carries the argument
Soft Silhouette Loss: a per-sample term that contrasts the distance to the own class against distances to competing classes across the full batch and is made differentiable through a soft approximation of the max operation.
If this is right
- Augmenting cross-entropy with the silhouette term consistently outperforms both plain cross-entropy and existing metric-learning baselines on the tested datasets.
- The hybrid objective that joins silhouette loss, cross-entropy, and supervised contrastive learning reaches the highest reported top-1 accuracy of 39.08 percent.
- The added term incurs substantially lower computational overhead than full pairwise contrastive formulations while still capturing global separation.
Where Pith is reading between the lines
- Classical clustering metrics can be turned into lightweight, batch-global regularizers that complement pairwise contrastive objectives without requiring large batch sizes.
- The same silhouette formulation could be adapted to unsupervised or semi-supervised regimes by replacing ground-truth class labels with pseudo-labels or nearest-neighbor assignments.
- Because the loss operates at the batch level rather than on explicit pairs, it may scale more gracefully to very high-dimensional embeddings where pairwise methods become costly.
Load-bearing premise
A soft differentiable approximation of the silhouette coefficient stays stable and useful without requiring special batch sizes or introducing training instability.
What would settle it
A controlled training run on the same datasets in which adding the silhouette term produces no accuracy improvement or triggers divergence relative to the cross-entropy baseline.
Figures






read the original abstract
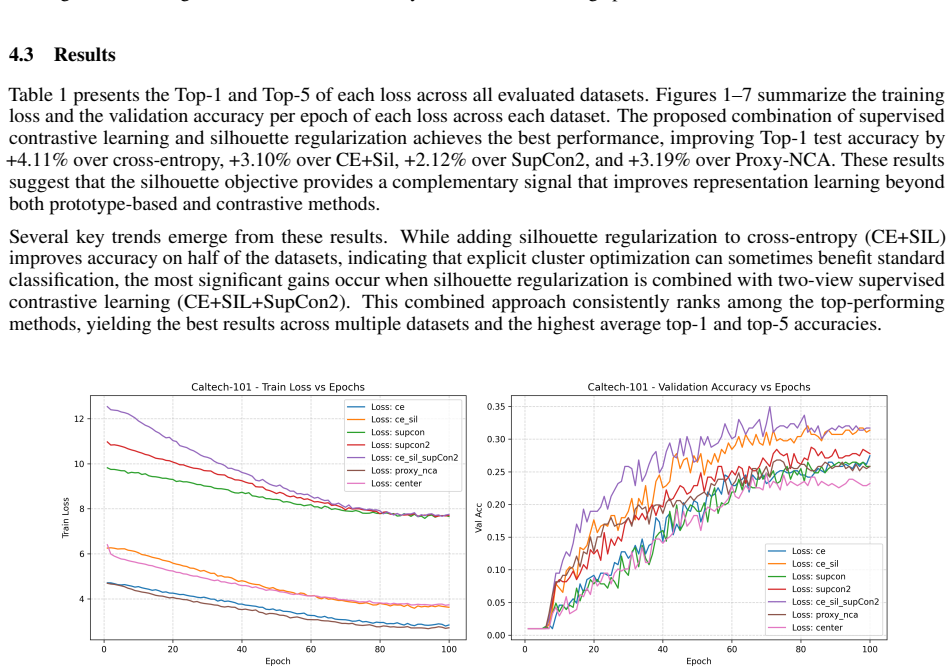
Learning discriminative representations is a central goal of supervised deep learning. While cross-entropy (CE) remains the dominant objective for classification, it does not explicitly enforce desirable geometric properties in the embedding space, such as intra-class compactness and inter-class separation. Existing metric learning approaches, including supervised contrastive learning (SupCon) and proxy-based methods, address this limitation by operating on pairwise or proxy-based relationships, but often increase computational cost and complexity. In this work, we introduce Soft Silhouette Loss, a novel differentiable objective inspired by the classical silhouette coefficient from clustering analysis. Unlike pairwise objectives, our formulation evaluates each sample against all classes in the batch, providing a batch-level notion of global structure. The proposed loss directly encourages samples to be closer to their own class than to competing classes, while remaining lightweight. Soft Silhouette Loss can be seamlessly combined with cross-entropy, and is also complementary to supervised contrastive learning. We propose a hybrid objective that integrates them, jointly optimizing local pairwise consistency and global cluster structure. Extensive experiments on seven diverse datasets demonstrate that: (i) augmenting CE with Soft Silhouette Loss consistently improves over CE and other metric learning baselines; (ii) the hybrid formulation outperforms SupCon alone; and (iii) the combined method achieves the best performance, improving average top-1 accuracy from 36.71% (CE) and 37.85% (SupCon2) to 39.08%, while incurring substantially lower computational overhead. These results suggest that classical clustering principles can be reinterpreted as differentiable objectives for deep learning, enabling efficient optimization of both local and global structure in representation spaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Soft Silhouette Loss, a differentiable objective derived from the classical silhouette coefficient, to explicitly enforce intra-class compactness and inter-class separation at the batch level in deep embedding spaces. Unlike pairwise metric losses, it evaluates each sample against all classes present in the batch. The loss is designed to be combined with cross-entropy (CE) and is shown to be complementary to supervised contrastive learning (SupCon). Experiments across seven datasets report consistent accuracy gains, with the hybrid CE + Soft Silhouette + SupCon objective improving average top-1 accuracy from 36.71% (CE) and 37.85% (SupCon2) to 39.08% while incurring lower computational overhead than SupCon alone.
Significance. If the central claims hold, the work provides a lightweight, batch-global alternative to existing metric-learning objectives that can be hybridized without substantial extra cost. The reinterpretation of a classical clustering metric as a differentiable loss is a constructive contribution that could generalize to other non-ML metrics. The reported complementarity to both CE and SupCon, together with the efficiency advantage, would be of practical interest for representation learning pipelines.
major comments (2)
- [§3] §3 (Method), Soft Silhouette Loss definition: the differentiable relaxation of the silhouette coefficient (via temperature-scaled soft min/max or log-sum-exp) implicitly assumes that gradients continue to enforce strict global separation even when batches contain few or uneven representatives per class. Under realistic long-tailed or large-vocabulary regimes this approximation risks collapsing to a local pairwise term, undermining the claimed batch-level global structure and the hybrid objective's complementarity to SupCon.
- [§4] §4 (Experiments): the accuracy improvements (e.g., 36.71% → 39.08%) are presented without reported standard deviations across random seeds, statistical significance tests, or ablation on the temperature/scaling hyper-parameter of the soft operations. This omission makes it impossible to judge whether the gains are robust or sensitive to the exact softening schedule.
minor comments (2)
- [Abstract] The abstract states results on 'seven diverse datasets' but does not name them; the experimental section should list the datasets explicitly in the first paragraph for immediate clarity.
- [§3] Notation for the temperature or scaling parameter used in the soft min/max should be introduced once in §3 and used consistently thereafter; current description leaves the exact functional form of the softening ambiguous.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important aspects of the Soft Silhouette Loss formulation and experimental validation. We address each major comment below and indicate the revisions we will incorporate in the updated manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method), Soft Silhouette Loss definition: the differentiable relaxation of the silhouette coefficient (via temperature-scaled soft min/max or log-sum-exp) implicitly assumes that gradients continue to enforce strict global separation even when batches contain few or uneven representatives per class. Under realistic long-tailed or large-vocabulary regimes this approximation risks collapsing to a local pairwise term, undermining the claimed batch-level global structure and the hybrid objective's complementarity to SupCon.
Authors: We appreciate this observation on the behavior of the soft relaxation. The formulation evaluates each sample against the mean distance to all other classes present in the batch (via the soft min/max), which preserves a batch-global comparison even when class counts are uneven; the temperature controls the degree of softening but does not reduce the loss to a purely pairwise term. Our experiments on seven datasets that include natural class imbalances show consistent gains when combined with CE and SupCon, supporting the claimed complementarity. Nevertheless, we agree that extreme long-tailed or large-vocabulary settings warrant further discussion. In the revision we will add a paragraph in §3 clarifying the assumptions of the relaxation and noting its potential limitations under severe imbalance, together with a brief analysis of batch composition effects. revision: partial
-
Referee: [§4] §4 (Experiments): the accuracy improvements (e.g., 36.71% → 39.08%) are presented without reported standard deviations across random seeds, statistical significance tests, or ablation on the temperature/scaling hyper-parameter of the soft operations. This omission makes it impossible to judge whether the gains are robust or sensitive to the exact softening schedule.
Authors: We agree that the experimental section would be strengthened by these additions. In the revised manuscript we will report standard deviations over at least five random seeds for all accuracy figures, include paired t-tests or Wilcoxon tests to assess statistical significance of the observed improvements, and add an ablation study on the temperature parameter of the soft min/max operations across the main datasets, showing its effect on final performance. revision: yes
Circularity Check
No circularity: Soft Silhouette Loss is a novel differentiable reformulation of the classical silhouette coefficient with independent derivation
full rationale
The paper introduces Soft Silhouette Loss by directly adapting the silhouette coefficient's intra-class vs. inter-class distance comparison into a batch-level differentiable objective. No step reduces to a fitted parameter renamed as prediction, no self-citation chain justifies the core formulation, and the hybrid objective with CE/SupCon adds the new term rather than deriving it from prior results. The derivation chain remains self-contained against the external clustering metric; softening via log-sum-exp or similar is an explicit design choice, not a hidden equivalence to inputs. This is the common honest case of a new loss function with no load-bearing circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- scaling or temperature parameter for soft min/max
axioms (1)
- domain assumption The batch contains multiple samples from each class for meaningful class averages
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
b(i) = −τ_s log ∑_{c≠y_i} exp(−d_{i,c}/τ_s); ˜m(a,b)=τ_m log(exp(a/τ_m)+exp(b/τ_m)); L_sil = −1/|B| ∑ ˜s(i)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hybrid L = L_sup + λ_sil L_sil; batch-level global cluster quality
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Training Convolutional Networks with Noisy Labels
Sainbayar Sukhbaatar, Joan Bruna, Manohar Paluri, Lubomir Bourdev, and Rob Fergus. Training convolutional networks with noisy labels.arXiv preprint arXiv:1406.2080,
work page internal anchor Pith review Pith/arXiv arXiv 2080
-
[2]
Large-Margin Softmax Loss for Convolutional Neural Networks
Weiyang Liu, Yandong Wen, Zhiding Yu, and Meng Yang. Large-margin softmax loss for convolutional neural networks. arXiv preprint arXiv:1612.02295,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, and Neil Houlsby. Large scale learning of general visual representations for transfer.arXiv preprint arXiv:1912.11370, 2(8):2019–4,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.