Recognition: 1 theorem link
· Lean TheoremScaffolding Human-AI Collaboration: A Field Experiment on Behavioral Protocols and Cognitive Reframing
Pith reviewed 2026-05-10 16:52 UTC · model grok-4.3
The pith
A cognitive reframing that treats AI as a thought partner was associated with higher document quality at the top of the distribution in a field experiment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
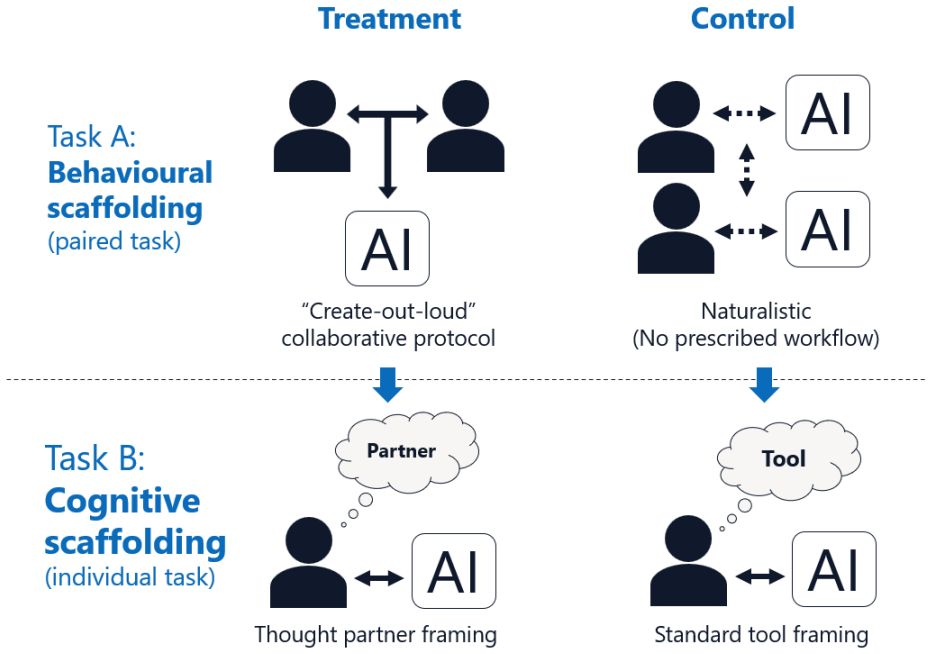
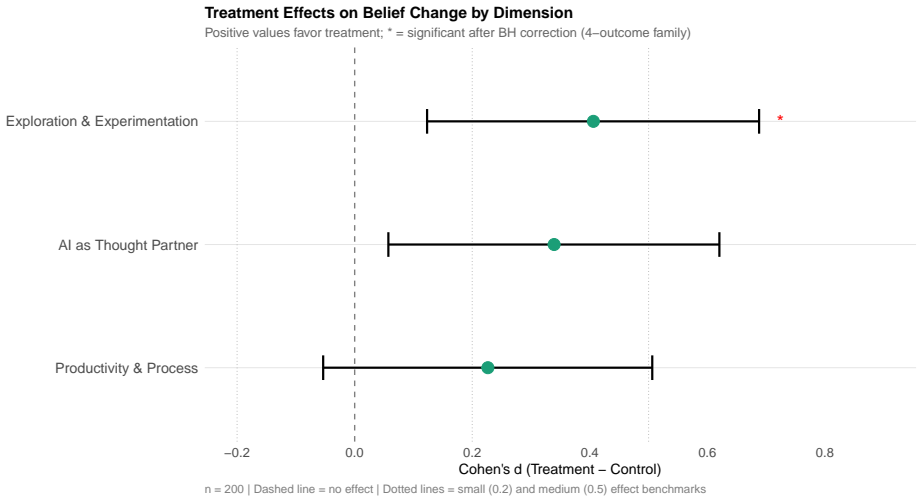
In the experiment with 388 employees, the cognitive scaffolding intervention—partnership training that reframed AI as a thought partner—was associated with higher individual document quality at the top of the distribution compared with unstructured use, while the behavioral scaffolding intervention—a structured protocol requiring joint AI use within pairs—was associated with lower document quality and substantially lower document production. Participants in the treatment arms also showed greater positive belief change, though this appears attributable to recovery from carry-over effects rather than the training itself.
What carries the argument
The cognitive scaffolding intervention, defined as partnership training that reframes the AI as a thought partner rather than a subordinate tool.
If this is right
- Structured behavioral protocols for joint AI use can reduce both quality and output volume relative to independent use.
- Reframing the AI relationship through brief training can lift performance for top individual contributors without changing the underlying tool.
- Belief shifts toward viewing AI as a partner may occur quickly but can be confounded by prior exposure or fatigue in short sessions.
- Effects on quality appear concentrated at the high end of the performance distribution rather than shifting the average uniformly.
Where Pith is reading between the lines
- Future workplace AI rollouts could prioritize short cognitive orientation sessions over enforced pairing rules to avoid productivity drops.
- The concentration of gains at the top suggests the intervention may interact with existing skill levels, which could be tested by stratifying participants by baseline performance.
- Design fixes such as within-day randomization would strengthen causal claims about scaffolding type.
- This setup connects to questions of how brief mindset interventions scale when AI tools update frequently.
Load-bearing premise
That the AM/PM session timing difference and uneven dropout rates across arms did not create systematic biases in the measured document quality or belief changes.
What would settle it
Replicating the study with randomized session times, full retention of participants, and length-insensitive quality scoring that shows no quality advantage for the cognitive training arm at the upper tail would falsify the central association.
Figures



read the original abstract
Organizations have widely deployed generative AI tools, yet productivity gains remain uneven, suggesting that how people use AI matters as much as whether they have access. We conducted a field experiment with 388 employees at a Fortune 500 retailer to test two scaffolding interventions for human-AI collaboration. All participants had access to the same AI tool; we varied only the structure surrounding its use. A behavioral scaffolding intervention (a structured protocol requiring joint AI use within pairs) was associated with lower document quality relative to unstructured use and substantially lower document production. A cognitive scaffolding intervention (partnership training that reframed AI as a thought partner) was associated with higher individual document quality at the top of the distribution. Treatment participants also showed greater positive belief change across the session, though sensitivity analyses suggest this likely reflects recovery from carry-over effects rather than genuine training-induced shifts. Both findings are subject to design limitations including an AM/PM session confound, differential attrition, and LLM grading sensitivity to document length.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports results from a field experiment with 388 employees at a Fortune 500 retailer testing two scaffolding interventions for generative AI use. All participants had access to the same AI tool; a behavioral scaffolding arm (structured joint-use protocol in pairs) was associated with lower document quality and substantially lower production, while a cognitive scaffolding arm (partnership training reframing AI as a thought partner) was associated with higher individual document quality at the top of the distribution and greater positive belief change. The abstract explicitly flags design limitations including an AM/PM session timing confound, differential attrition, and LLM grading sensitivity to document length.
Significance. If the top-tail quality association holds after addressing the design threats, the results would provide field evidence that cognitive reframing can improve uneven productivity gains from AI tools in real organizational settings. The large employee sample and within-firm randomization offer external validity advantages over lab experiments on human-AI collaboration.
major comments (4)
- [Abstract] Abstract: the claim of higher document quality at the upper tail for the cognitive scaffolding arm is not identified because the AM/PM session timing confound (which can affect cognitive performance) is noted but not isolated via robustness checks, bounds, or session-fixed effects in the reported comparisons.
- [Abstract] Abstract: differential attrition is flagged as a limitation but without reported selection corrections, inverse-probability weighting, or attrition bounds, it is unclear whether the quantile-specific quality and belief-change associations are biased by selection on unobservables correlated with performance.
- [Abstract] Abstract: LLM grading sensitivity to document length threatens the quality measure, especially at the top tail where length may correlate with scores; no length controls, alternative grading, or sensitivity analyses isolating this from the treatment effect are described.
- [Abstract] Abstract: the positive belief-change result is qualified by sensitivity analyses indicating it likely reflects recovery from carry-over effects rather than genuine training-induced shifts, which directly undermines the interpretation of the cognitive intervention's impact on beliefs.
minor comments (2)
- The manuscript would benefit from explicit reporting of per-arm sample sizes, attrition rates, and the precise statistical methods (including any quantile regression specifications) used for the top-tail claims.
- Clarify whether the analysis plan was pre-registered and include any additional robustness tables addressing the length and timing issues.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our field experiment manuscript. We agree that additional robustness analyses and qualifications are needed to strengthen identification claims and will revise the abstract and main text accordingly while preserving transparency about the inherent field-design constraints.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of higher document quality at the upper tail for the cognitive scaffolding arm is not identified because the AM/PM session timing confound (which can affect cognitive performance) is noted but not isolated via robustness checks, bounds, or session-fixed effects in the reported comparisons.
Authors: We acknowledge that the AM/PM timing represents a plausible confound for cognitive performance. Although flagged in the abstract, we did not report session-fixed effects or bounds in the primary results. In revision we will add session-fixed effects and sensitivity bounds using available session data. Full isolation is limited by the field setting where session assignment could not be independently randomized, but these checks will clarify the robustness of the top-tail quality association. revision: yes
-
Referee: [Abstract] Abstract: differential attrition is flagged as a limitation but without reported selection corrections, inverse-probability weighting, or attrition bounds, it is unclear whether the quantile-specific quality and belief-change associations are biased by selection on unobservables correlated with performance.
Authors: We agree that differential attrition could bias the quantile and belief-change estimates. The current version notes the limitation but omits corrections. We will implement inverse-probability weighting on observables and report attrition bounds (e.g., Lee bounds) in the revised analyses to assess sensitivity of the reported associations. revision: yes
-
Referee: [Abstract] Abstract: LLM grading sensitivity to document length threatens the quality measure, especially at the top tail where length may correlate with scores; no length controls, alternative grading, or sensitivity analyses isolating this from the treatment effect are described.
Authors: We concur that LLM scores may be length-sensitive, particularly at the upper tail. We will add document-length controls, length-normalized grading variants, and sensitivity checks that isolate treatment effects from length. Where feasible we will also report results from a human-coded subsample to validate the LLM measure. revision: yes
-
Referee: [Abstract] Abstract: the positive belief-change result is qualified by sensitivity analyses indicating it likely reflects recovery from carry-over effects rather than genuine training-induced shifts, which directly undermines the interpretation of the cognitive intervention's impact on beliefs.
Authors: The abstract already qualifies the belief-change result by referencing the sensitivity analyses on carry-over effects. We will expand the main-text discussion to more explicitly link these analyses to the limited causal interpretation of the cognitive intervention on beliefs, ensuring readers understand the qualified nature of this secondary finding. revision: partial
- We cannot re-randomize session timing or eliminate the AM/PM confound through new experimental data collection, as the field experiment has concluded.
Circularity Check
No circularity: empirical field experiment without derivation or self-referential fitting
full rationale
This is a randomized field experiment reporting associations between two scaffolding interventions and outcomes (document quality, belief change) in a sample of 388 employees. The central claims rest on direct statistical comparisons of treatment arms to control, with explicit acknowledgment of design limitations (AM/PM timing, differential attrition, LLM length sensitivity). No equations, parameters fitted to subsets then relabeled as predictions, self-definitional constructs, or load-bearing self-citations appear in the reported chain; the results are identified (or not) by the data collection and analysis rather than reducing to prior inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Participants were randomly assigned to treatment conditions with no systematic baseline differences beyond the reported AM/PM timing.
- domain assumption LLM-based document grading provides a valid proxy for human-assessed quality independent of text length.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe conducted a field experiment with 388 employees... A behavioral scaffolding intervention... A cognitive scaffolding intervention... OLS with HC2 robust standard errors... Lee (2009) trimming bounds
Reference graph
Works this paper leans on
-
[1]
Agrawal, A., Gans, J., and Goldfarb, A. (2024). Artificial intelligence adoption and system-wide change. Journal of Economics & Management Strategy , 33(2):327--337
2024
-
[2]
Angrist, J. D. and Pischke, J.-S. (2009). Mostly Harmless Econometrics: An Empiricist's Companion . Princeton University Press
2009
-
[3]
and Cajochen, C
Blatter, K. and Cajochen, C. (2007). Circadian rhythms in cognitive performance: Methodological constraints, protocols, theoretical underpinnings. Physiology & Behavior , 90(2--3):196--208
2007
-
[4]
D., Ford, J
Blume, B. D., Ford, J. K., Baldwin, T. T., and Huang, J. L. (2010). Transfer of training: A meta-analytic review. Journal of Management , 36(4):1065--1105
2010
-
[5]
Brynjolfsson, E., Li, D., and Raymond, L. R. (2025). Generative AI at work. The Quarterly Journal of Economics , 140(2):889--942
2025
-
[6]
Cadario, R., Longoni, C., and Morewedge, C. K. (2021). Understanding, explaining, and utilizing medical artificial intelligence. Nature Human Behaviour , 5(12):1636--1642
2021
-
[7]
R., Mollick, L., Han, Y., Goldman, J., Nair, H., Taub, S., and Lakhani, K
Dell'Acqua, F., Ayoubi, C., Lifshitz-Assaf, H., Sadun, R., Mollick, E. R., Mollick, L., Han, Y., Goldman, J., Nair, H., Taub, S., and Lakhani, K. R. (2025). The cybernetic teammate: A field experiment on generative AI reshaping teamwork and expertise. Harvard Business School Working Paper No. 25-043
2025
-
[8]
R., Lifshitz-Assaf, H., Kellogg, K., Rajendran, S., Krayer, L., Candelon, F., and Lakhani, K
Dell'Acqua, F., McFowland, E., Mollick, E. R., Lifshitz-Assaf, H., Kellogg, K., Rajendran, S., Krayer, L., Candelon, F., and Lakhani, K. R. (2026). Navigating the jagged technological frontier: Field experimental evidence of the effects of artificial intelligence on knowledge worker productivity and quality. Organization Science
2026
-
[9]
and Poole, M
DeSanctis, G. and Poole, M. S. (1994). Capturing the complexity in advanced technology use: Adaptive structuration theory. Organization Science , 5(2):121--147
1994
-
[10]
J., Simmons, J
Dietvorst, B. J., Simmons, J. P., and Massey, C. (2015). Algorithm aversion: People erroneously avoid algorithms after seeing them err. Journal of Experimental Psychology: General , 144(1):114--126
2015
-
[11]
Doshi, A. R. and Hauser, O. P. (2024). Generative AI enhances individual creativity but reduces the collective diversity of novel content. Science Advances , 10(28):eadn5290
2024
-
[12]
C., Bohmer, R
Edmondson, A. C., Bohmer, R. M., and Pisano, G. P. (2001). Disrupted routines: Team learning and new technology implementation in hospitals. Administrative Science Quarterly , 46(4):685--716
2001
-
[13]
Faraj, S., Pachidi, S., and Sayegh, K. (2018). Working and organizing in the age of the learning algorithm. Information and Organization , 28(1):62--70
2018
-
[14]
Grennan, C. (2023). AI mindset training curriculum
2023
-
[15]
Imai, K., Keele, L., and Tingley, D. (2010). A general approach to causal mediation analysis. Psychological Methods , 15(4):309--334
2010
-
[16]
E., and Zmud, R
Jasperson, J., Carter, P. E., and Zmud, R. W. (2005). A comprehensive conceptualization of post-adoptive behaviors associated with information technology enabled work systems. MIS Quarterly , 29(3):525--557
2005
-
[17]
C., Valentine, M
Kellogg, K. C., Valentine, M. A., and Christin, A. (2020). Algorithms at work: The new contested terrain of control. Academy of Management Annals , 14(1):366--410
2020
-
[18]
Lebovitz, S., Lifshitz-Assaf, H., and Levina, N. (2022). To engage or not to engage with AI for critical judgments: How professionals deal with opacity when using AI for medical diagnosis. Organization Science , 33(1):126--148
2022
-
[19]
Lee, D. S. (2009). Training, wages, and sample selection: Estimating sharp bounds on treatment effects. Review of Economic Studies , 76(3):1071--1102
2009
-
[20]
Leonardi, P. M. (2011). When flexible routines meet flexible technologies: Affordance, constraint, and the imbrication of human and material agencies. MIS Quarterly , 35(1):147--167
2011
-
[21]
Lin, W. (2013). Agnostic notes on regression adjustments to experimental data: Reexamining Freedman 's critique. Annals of Applied Statistics , 7(1):295--318
2013
-
[22]
M., Minson, J
Logg, J. M., Minson, J. A., and Moore, D. A. (2019). Algorithm appreciation: People prefer algorithmic to human judgment. Organizational Behavior and Human Decision Processes , 151:90--103
2019
-
[23]
Work trend index annual report
Microsoft (2024). Work trend index annual report. Technical report, Microsoft Corporation
2024
-
[24]
Monk, T. H. (2005). The post-lunch dip in performance. Clinics in Sports Medicine , 24(2):e15--e23
2005
-
[25]
and Zhang, W
Noy, S. and Zhang, W. (2023). Experimental evidence on the productivity effects of generative artificial intelligence. Science , 381(6654):187--192
2023
-
[26]
Orlikowski, W. J. (1992). The duality of technology: Rethinking the concept of technology in organizations. Organization Science , 3(3):398--427
1992
-
[27]
Orlikowski, W. J. and Gash, D. C. (1994). Technological frames: Making sense of information technology in organizations. ACM Transactions on Information Systems , 12(2):174--207
1994
-
[28]
Oster, E. (2019). Unobservable selection and coefficient stability: Theory and evidence. Journal of Business & Economic Statistics , 37(2):187--204
2019
-
[29]
Pustejovsky, J. E. and Tipton, E. (2018). Small-sample methods for cluster-robust variance estimation and hypothesis testing in fixed effects models. Journal of Business & Economic Statistics , 36(4):672--683
2018
-
[30]
B., Outland, N., Kerstan, S., Georganta, E., and Ulfert, A.-S
Schmutz, J. B., Outland, N., Kerstan, S., Georganta, E., and Ulfert, A.-S. (2024). AI-Teaming : Redefining collaboration in the digital era. Current Opinion in Psychology , 58:101837
2024
-
[31]
Trist, E. L. and Bamforth, K. W. (1951). Some social and psychological consequences of the longwall method of coal-getting. Human Relations , 4(1):3--38
1951
-
[32]
Vaccaro, M., Almaatouq, A., and Malone, T. W. (2024). When combinations of humans and AI are useful: A systematic review and meta-analysis. Nature Human Behaviour , 8(12):2293--2303
2024
-
[33]
Valdez, P., Ram \'i rez, C., and Garc \'i a, A. (2014). Circadian rhythms in cognitive processes: Implications for school learning. Mind, Brain, and Education , 8(4):161--168
2014
-
[34]
Vygotsky, L. S. (1978). Mind in Society: The Development of Higher Psychological Processes . Harvard University Press
1978
-
[35]
Weick, K. E. (1990). Technology as equivoque: Sensemaking in new technologies. In Goodman, P. S. and Sproull, L. S., editors, Technology and Organizations , pages 1--44. Jossey-Bass
1990
-
[36]
S., and Ross, G
Wood, D., Bruner, J. S., and Ross, G. (1976). The role of tutoring in problem solving. Journal of Child Psychology and Psychiatry , 17(2):89--100
1976
-
[37]
Woolley, A. W. (2025). Generative AI and collaboration: Opportunities for cultivating collective intelligence. Journal of Organization Design
2025
-
[38]
P., Zhang, H., Gonzalez, J
Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E. P., Zhang, H., Gonzalez, J. E., and Stoica, I. (2023). Judging LLM -as-a-judge with MT-Bench and Chatbot Arena . Advances in Neural Information Processing Systems , 36
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.