Recognition: unknown
Revisiting Anisotropy in Language Transformers: The Geometry of Learning Dynamics
Pith reviewed 2026-05-10 17:02 UTC · model grok-4.3
The pith
Low-rank tangent proxies from activations capture most gradient anisotropy in language transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By fitting activation-derived low-rank tangent proxies during training rather than only after the fact, these directions capture both unusually large gradient energy and a substantially larger share of gradient anisotropy than matched-rank normal controls, providing strong empirical support for a tangent-aligned account of anisotropy across encoder-style and decoder-style language models.
What carries the argument
Activation-derived low-rank tangent proxies that approximate the tangent space of the representation manifold and are tested against true gradients.
If this is right
- Training dynamics preferentially amplify tangent directions, explaining why anisotropy grows during optimization.
- Frequency-biased sampling attenuates curvature visibility, making the manifold appear flatter than it is.
- The tangent-aligned mechanism operates similarly in both encoder-style and decoder-style language models.
- Low-rank proxies built from activations can serve as efficient diagnostics for gradient behavior without full backpropagation.
Where Pith is reading between the lines
- Regularizing curvature during training might reduce unwanted anisotropy while preserving task performance.
- The geometric account could be tested in non-transformer architectures to check if tangent amplification is general.
- If the proxies predict downstream behavior, they could guide early stopping or architecture adjustments.
Load-bearing premise
The low-rank proxies constructed from activations during training accurately approximate the true tangent space of the representation manifold and that this alignment is not an artifact of the specific concept-based interpretability method chosen.
What would settle it
Observing that activation-derived low-rank proxies capture no more gradient anisotropy than random vectors of equal rank in a held-out model, or that true gradients align equally with any low-rank subspace.
Figures




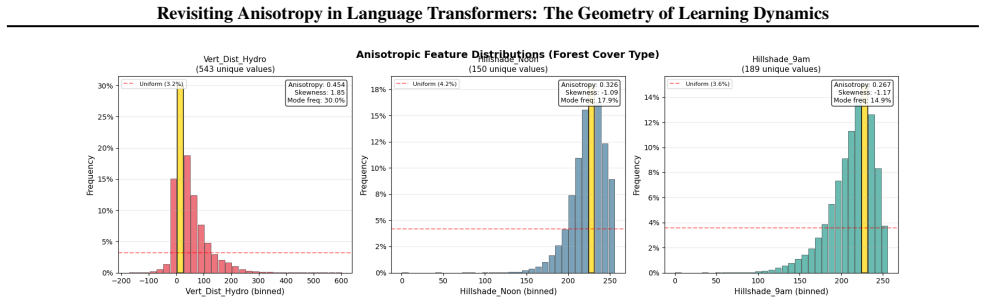


read the original abstract
Since their introduction, Transformer architectures have dominated Natural Language Processing (NLP). However, recent research has highlighted an inherent anisotropy phenomenon in these models, presenting a significant challenge to their geometric interpretation. Previous theoretical studies on this phenomenon are rarely grounded in the underlying representation geometry. In this paper, we extend them by deriving geometric arguments for how frequency-biased sampling attenuates curvature visibility and why training preferentially amplify tangent directions. Empirically, we then use concept-based mechanistic interpretability during training, rather than only post hoc, to fit activation-derived low-rank tangent proxies and test them against ordinary backpropagated true gradients. Across encoder-style and decoder-style language models, we find that these activation-derived directions capture both unusually large gradient energy and a substantially larger share of gradient anisotropy than matched-rank normal controls, providing strong empirical support for a tangent-aligned account of anisotropy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives geometric arguments showing that frequency-biased sampling in language data attenuates curvature visibility on the representation manifold and that gradient descent preferentially amplifies tangent directions. It then constructs activation-derived low-rank tangent proxies via concept-based mechanistic interpretability applied during training (rather than post hoc) and reports that these proxies capture substantially more gradient energy and a larger fraction of gradient anisotropy than matched-rank normal controls, across both encoder- and decoder-style models.
Significance. If the low-rank proxies are shown to faithfully span the tangent space, the combination of geometric derivation and controlled empirical comparison would provide a coherent, manifold-based account of anisotropy that moves beyond purely post-hoc geometric observations and could guide future work on representation geometry and training dynamics.
major comments (1)
- The central empirical claim (that the activation-derived proxies capture unusually large gradient energy and anisotropy share) is load-bearing on the assumption that these proxies accurately approximate the true tangent space. The manuscript does not appear to include independent verification of this (e.g., curvature estimates, orthogonality checks against estimated normal vectors, or ablation of the concept-fitting procedure), leaving open the possibility that the observed alignment is partly an artifact of the interpretability method's selection of high-variance or gradient-correlated directions.
minor comments (2)
- The description of the proxy-fitting procedure and the exact definition of 'matched-rank normal controls' would benefit from additional detail on hyperparameter choices and statistical controls to allow full reproducibility.
- Figure captions and axis labels should explicitly state whether error bars represent standard deviation across seeds, layers, or models.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting a key assumption in our empirical section. We respond to the major comment below and will incorporate additional verification steps in the revised manuscript.
read point-by-point responses
-
Referee: The central empirical claim (that the activation-derived proxies capture unusually large gradient energy and anisotropy share) is load-bearing on the assumption that these proxies accurately approximate the true tangent space. The manuscript does not appear to include independent verification of this (e.g., curvature estimates, orthogonality checks against estimated normal vectors, or ablation of the concept-fitting procedure), leaving open the possibility that the observed alignment is partly an artifact of the interpretability method's selection of high-variance or gradient-correlated directions.
Authors: We appreciate the referee identifying this assumption. The proxies are obtained via concept-based mechanistic interpretability applied during training, which extracts low-rank directions of activation variation that the geometric analysis in Section 3 predicts should align with the tangent space (because frequency-biased sampling reduces observable curvature). The primary evidence we report is their superior capture of gradient energy and anisotropy share relative to matched-rank controls. We acknowledge, however, that this comparison alone does not fully rule out selection artifacts. In the revision we will add (i) an ablation replacing the concept-fitting step with random and top-variance directions of the same rank, (ii) orthogonality checks of the proxies against estimated normal directions on a subset of layers, and (iii) curvature estimates along the proxy directions for the smaller models. These additions will directly test whether the observed alignment exceeds what would be expected from high-variance or gradient-correlated directions alone. revision: yes
Circularity Check
No significant circularity; derivation self-contained via independent geometric arguments and controlled empirical tests
full rationale
The paper derives geometric arguments from manifold properties regarding frequency-biased sampling and tangent amplification during training, then conducts empirical validation by fitting low-rank proxies from activations via concept-based interpretability and comparing them to backpropagated gradients against matched-rank controls. No quoted steps reduce by construction to fitted inputs, self-definitions, or load-bearing self-citations; the central claim rests on comparative statistics that are not tautological with the proxy construction. The analysis is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
free parameters (1)
- rank of tangent proxies
axioms (1)
- domain assumption The representation manifold has a tangent space that can be approximated from activations
Reference graph
Works this paper leans on
-
[1]
URL https://aclanthology.org/2021. naacl-main.403/. Boizard, N., Gisserot-Boukhlef, H., Alves, D. M., Martins, A., Hammal, A., Corro, C., Hudelot, C., Malherbe, E., Malaboeuf, E., Jourdan, F., Hautreux, G., Alves, J., El- Haddad, K., Faysse, M., Peyrard, M., Guerreiro, N. M., Fernandes, P., Rei, R., and Colombo, P. Eurobert: Scaling multilingual encoders ...
-
[2]
URL https://aclanthology.org/2024. emnlp-main.344/. 10 Revisiting Anisotropy in Language Transformers: The Geometry of Learning Dynamics Diehl Martinez, R., Lesci, P., and Buttery, P. Tending towards stability: Convergence challenges in small language models. In Al-Onaizan, Y ., Bansal, M., and Chen, Y .-N. (eds.),Findings of the Associa- tion for Computa...
-
[3]
doi: 10.1109/TPAMI.2008.277. Ethayarajh, K. How contextual are contextualized word representations? comparing the geometry of bert, elmo, and gpt-2 embeddings, 2019. URL https://arxiv. org/abs/1909.00512. Facco, E., d’Errico, M., Rodriguez, A., and Laio, A. Es- timating the intrinsic dimension of datasets by a min- imal neighborhood information.Scientific...
-
[4]
URL https://aclanthology.org/2022. findings-emnlp.314/. Gao, J., He, D., Tan, X., Qin, T., Wang, L., and Liu, T.-Y . Representation degeneration problem in training natural language generation models, 2019. URL https:// arxiv.org/abs/1907.12009. Gao, T. The diffusion geometry of fibre bundles: Horizontal diffusion maps, 2019. URL https://arxiv.org/ abs/16...
-
[5]
PMLR. URL https://proceedings.mlr. press/v9/glorot10a.html. Godey, N., Clergerie, ´E., and Sagot, B. Anisotropy is in- herent to self-attention in transformers. In Graham, Y . and Purver, M. (eds.),Proceedings of the 18th Confer- ence of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 35–48, St. Julian’s,...
-
[6]
URL https://www.science.org/doi/ abs/10.1126/science.290.5500.2323. Roy, O. and Vetterli, M. The effective rank: A measure of effective dimensionality. In2007 15th European Signal Processing Conference, pp. 606–610, 2007. Rudman, W. and Eickhoff, C. Stable anisotropic regulariza- tion, 2024. URL https://arxiv.org/abs/2305. 19358. Rudman, W., Gillman, N., ...
-
[7]
URL https://aclanthology.org/2022. findings-acl.262/. Sadrtdinov, I., Klimov, I., Lobacheva, E., and Vetrov, D. Sgd as free energy minimization: A thermodynamic view on neural network training, 2025. URL https://arxiv. org/abs/2505.23489. Singh, A. K., Moskovitz, T., Hill, F., Chan, S. C. Y ., and Saxe, A. M. What needs to go right for an induction head? ...
-
[8]
URL https://aclanthology.org/2020. findings-emnlp.46/. Zhou, K., Ethayarajh, K., and Jurafsky, D. Frequency-based distortions in contextualized word embeddings, 2021. URLhttps://arxiv.org/abs/2104.08465. 13 Revisiting Anisotropy in Language Transformers: The Geometry of Learning Dynamics A. Proof of Proposition 2.1 We invert (1) to expressr 2 as a functio...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.