Recognition: unknown
Toward Hardware-Agnostic Quadrupedal World Models via Morphology Conditioning
Pith reviewed 2026-05-10 16:50 UTC · model grok-4.3
The pith
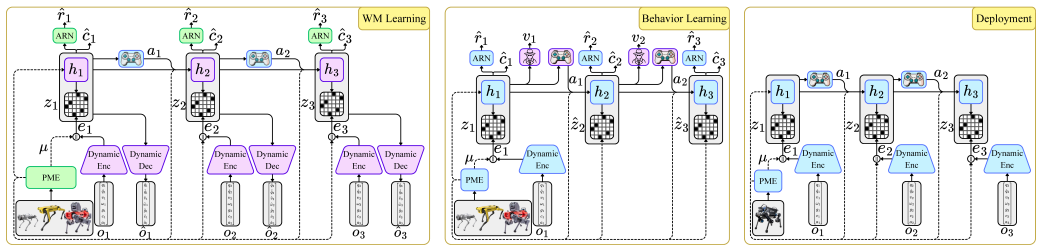
A quadrupedal world model generalizes zero-shot to new robot morphologies by conditioning on their engineering specifications.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By explicitly conditioning the generative dynamics on robot engineering specifications rather than treating physical properties as latent variables inferred from motion history, the Quadrupedal World Model disentangles environmental dynamics from morphology and functions as a neural simulator that supports zero-shot locomotion control across different quadrupedal embodiments within a bounded distribution.
What carries the argument
Morphology-conditioned generative dynamics that takes explicit engineering specifications as conditioning input to separate embodiment from environmental physics.
If this is right
- Zero-shot transfer of locomotion policies to new quadruped hardware without retraining or adaptation.
- Elimination of safety risks from adaptation lag that occurs when inferring morphology from motion history.
- One model serving as a shared simulator across multiple quadruped designs.
- Faster iteration on robot hardware because behaviors learned in the conditioned model transfer directly.
Where Pith is reading between the lines
- The same conditioning strategy could be tested on other legged platforms such as bipeds to check whether the disentanglement principle generalizes beyond quadrupeds.
- Combining the morphology encoder with limited real-world fine-tuning on a target robot might extend reliable operation beyond the current interpolation range.
- Designers could use the model to simulate candidate robot geometries before building them, treating morphology as a controllable input variable.
Load-bearing premise
Explicitly supplying engineering specifications is sufficient to disentangle morphology-specific effects from shared environmental dynamics without residual confusion.
What would settle it
Measure prediction error of the trained model on a quadruped whose limb lengths or masses lie well outside the training distribution, such as a much larger or smaller robot than those seen during training, and check whether error remains low without any online adaptation.
Figures









read the original abstract
World models promise a paradigm shift in robotics, where an agent learns the underlying physics of its environment once to enable efficient planning and behavior learning. However, current world models are often hardware-locked specialists: a model trained on a Boston Dynamics Spot robot fails catastrophically on a Unitree Go1 due to the mismatch in kinematic and dynamic properties, as the model overfits to specific embodiment constraints rather than capturing the universal locomotion dynamics. Consequently, a slight change in actuator dynamics or limb length necessitates training a new model from scratch. In this work, we take a step towards a framework for training a generalizable Quadrupedal World Model (QWM) that disentangles environmental dynamics from robot morphology. We address the limitations of implicit system identification, where treating static physical properties (like mass or limb length) as latent variables to be inferred from motion history creates an adaptation lag that can compromise zero-shot safety and efficiency. Instead, we explicitly condition the generative dynamics on the robot's engineering specifications. By integrating a physical morphology encoder and a reward normalizer, we enable the model to serve as a neural simulator capable of generalizing across morphologies. This capability unlocks zero-shot control across a range of embodiments. We introduce, for the first time, a world model that enables zero-shot generalization to new morphologies for locomotion. While we carefully study the limitations of our method, QWM operates as a distribution-bounded interpolator within the quadrupedal morphology family rather than a universal physics engine, this work represents a significant step toward morphology-conditioned world models for legged locomotion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Quadrupedal World Model (QWM) that explicitly conditions generative dynamics on robot engineering specifications (via a physical morphology encoder and reward normalizer) to disentangle environmental dynamics from morphology. This is intended to overcome hardware-specific overfitting in existing world models and enable zero-shot locomotion control on new quadrupedal embodiments, in contrast to implicit system identification approaches that incur adaptation lag.
Significance. If the central claims are supported by rigorous evaluation, the work would advance hardware-agnostic world models for legged robotics by providing a practical conditioning mechanism that avoids per-embodiment retraining. The explicit use of engineering specs rather than learned latents is a clear methodological choice with potential safety benefits. The paper appropriately qualifies its scope as distribution-bounded interpolation within the quadrupedal family rather than a universal engine, which keeps the contribution proportionate.
major comments (1)
- [Abstract] Abstract: The claim of introducing 'for the first time, a world model that enables zero-shot generalization to new morphologies for locomotion' is load-bearing for the paper's contribution. However, the same paragraph qualifies the model as 'a distribution-bounded interpolator within the quadrupedal morphology family'. The evaluation must demonstrate that held-out test morphologies have engineering parameters (limb lengths, masses, actuator dynamics) lying outside the convex hull of the training distribution; otherwise the results reduce to interpolation and do not substantiate the asserted disentanglement or zero-shot transfer.
minor comments (1)
- [Abstract] The final sentence of the abstract is a run-on that mixes a limitation statement with a significance claim; splitting it would improve readability.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. We address the single major comment below and commit to revisions that strengthen the alignment between claims and evaluation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of introducing 'for the first time, a world model that enables zero-shot generalization to new morphologies for locomotion' is load-bearing for the paper's contribution. However, the same paragraph qualifies the model as 'a distribution-bounded interpolator within the quadrupedal morphology family'. The evaluation must demonstrate that held-out test morphologies have engineering parameters (limb lengths, masses, actuator dynamics) lying outside the convex hull of the training distribution; otherwise the results reduce to interpolation and do not substantiate the asserted disentanglement or zero-shot transfer.
Authors: We agree that clarifying the scope of generalization is essential. In the manuscript, 'zero-shot' specifically denotes the absence of any online adaptation, fine-tuning, or latent inference from interaction history (in contrast to implicit system identification baselines). The test morphologies are held-out samples drawn from the same quadrupedal family but with parameter combinations not encountered during training. We acknowledge that this is interpolation within a bounded distribution rather than extrapolation to arbitrary embodiments. To directly address the convex-hull concern, we will add to the revised manuscript (1) a table in the experiments section listing the concrete engineering parameters (limb lengths, masses, actuator dynamics) for every training and test morphology, and (2) an explicit analysis of whether each test morphology lies inside or outside the convex hull of the training set. If any test points fall inside the hull, we will revise the abstract and introduction language to describe the results as 'strong interpolation within the quadrupedal family' while retaining the zero-shot (no-adaptation) distinction. These changes will make the evaluation fully rigorous and proportionate to the stated claims. revision: yes
Circularity Check
No circularity: method uses explicit conditioning on provided morphology parameters without self-referential definitions or fitted predictions.
full rationale
The paper's core approach—explicitly conditioning generative dynamics on engineering specifications via a morphology encoder and reward normalizer—is presented as a direct architectural choice to avoid implicit latent inference. No equations, derivations, or results in the abstract reduce a claimed prediction or generalization to a parameter fitted from the target outcome itself. The zero-shot claim is framed as an empirical outcome of training across a morphology family and evaluating held-out cases, with an explicit qualification that the model remains a bounded interpolator. This structure is self-contained and does not rely on self-citation chains, ansatzes smuggled via prior work, or renaming of known results as new derivations.
Axiom & Free-Parameter Ledger
free parameters (2)
- morphology encoder network weights
- reward normalizer parameters
axioms (1)
- domain assumption Explicit conditioning on static physical properties disentangles embodiment from environmental dynamics without requiring motion history inference.
Reference graph
Works this paper leans on
-
[1]
Fay, Henrik I Christensen, Jan Peters, and Hao Su
Bo Ai, Liu Dai, Nico Bohlinger, Dichen Li, Tongzhou Mu, Zhanxin Wu, K. Fay, Henrik I Christensen, Jan Peters, and Hao Su. Towards embodiment scaling laws in robot locomotion. In Joseph Lim, Shuran Song, and Hae- Won Park, editors,Proceedings of The 9th Conference on Robot Learning, volume 305 ofProceedings of Machine Learning Research, pages 3483–3515. PM...
2025
-
[2]
Diffusion for world modeling: Visual details matter in atari.Advances in Neural Information Pro- cessing Systems, 37:58757–58791, 2024
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kan- ervisto, Amos J Storkey, Tim Pearce, and Franc ¸ois Fleuret. Diffusion for world modeling: Visual details matter in atari.Advances in Neural Information Pro- cessing Systems, 37:58757–58791, 2024
2024
-
[3]
Genesis: A generative and universal physics engine for robotics and beyond, December 2024
Genesis Authors. Genesis: A generative and universal physics engine for robotics and beyond, December 2024. URL https://github.com/Genesis-Embodied-AI/Genesis
2024
-
[4]
Sample-efficient learning to solve a real-world labyrinth game using data-augmented model-based reinforcement learning
Thomas Bi and Raffaello D’Andrea. Sample-efficient learning to solve a real-world labyrinth game using data-augmented model-based reinforcement learning. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 7455–7460. IEEE, 2024
2024
-
[5]
One policy to run them all: an end- to-end learning approach to multi-embodiment locomo- tion
Nico Bohlinger, Grzegorz Czechmanowski, Maciej Piotr Krupka, Piotr Kicki, Krzysztof Walas, Jan Peters, and Davide Tateo. One policy to run them all: an end- to-end learning approach to multi-embodiment locomo- tion. In Pulkit Agrawal, Oliver Kroemer, and Wolfram Burgard, editors,Proceedings of The 8th Conference on Robot Learning, volume 270 ofProceedings...
2025
-
[6]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott G...
1901
-
[7]
Chan, Nicolas Heess, Lucy Gonzalez, Simon Osindero, Sherjil Ozair, Scott Reed, Jingwei Zhang, Konrad Zolna, Jeff Clune, Nando de Freitas, Satinder Singh, and Tim Rockt ¨aschel
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, Yusuf Aytar, Sarah Maria Elisabeth Bechtle, Feryal Behbahani, Stephanie C.Y . Chan, Nicolas Heess, Lucy Gonzalez, Simon Osindero, Sherjil Ozair, Scott Reed, Jingwei Zhang, Konrad Zolna, Jeff Clune, Nando...
2024
-
[8]
Learning transformer-based world models with contrastive predic- tive coding
Maxime Burchi and Radu Timofte. Learning transformer-based world models with contrastive predic- tive coding. InThe Thirteenth International Confer- ence on Learning Representations, 2025. URL https: //openreview.net/forum?id=YK9G4Htdew
2025
-
[9]
Mi-hgnn: Morphology-informed heterogeneous graph neural network for legged robot contact perception
Daniel Butterfield, Sandilya Sai Garimella, Nai-Jen Cheng, and Lu Gan. Mi-hgnn: Morphology-informed heterogeneous graph neural network for legged robot contact perception. In2025 IEEE International Confer- ence on Robotics and Automation (ICRA), pages 10110– 10116. IEEE, 2025
2025
-
[10]
Diwa: Diffusion policy adaptation with world models.Conference on Robot Learning (CoRL), 2025
Akshay L Chandra, Iman Nematollahi, Chenguang Huang, Tim Welschehold, Wolfram Burgard, and Ab- hinav Valada. Diwa: Diffusion policy adaptation with world models.Conference on Robot Learning (CoRL), 2025
2025
-
[11]
Chang Chen, Yi-Fu Wu, Jaesik Yoon, and Sungjin Ahn. Transdreamer: Reinforcement learning with transformer world models.arXiv preprint arXiv:2202.09481, 2022
-
[12]
Hardware conditioned policies for multi-robot transfer learning.Advances in Neural Information Processing Systems, 31, 2018
Tao Chen, Adithyavairavan Murali, and Abhinav Gupta. Hardware conditioned policies for multi-robot transfer learning.Advances in Neural Information Processing Systems, 31, 2018
2018
-
[13]
Mohamad H. Danesh. Heterogeneous environments in isaac lab. Technical Blog Post, 2026. URL https: //modanesh.github.io/blog/hetero-isaaclab
2026
-
[14]
Mohamad H. Danesh. Hetero-isaac: Heterogeneous quadrupedal simulation built atop isaac lab, 2026. URL https://github.com/modanesh/Hetero-IsaacLab
2026
-
[15]
Mohamad H Danesh, Maxime Wabartha, Stanley Wu, Joelle Pineau, and Hsiu-Chin Lin. Safe domain randomization via uncertainty-aware out-of-distribution detection and policy adaptation.arXiv preprint arXiv:2507.06111, 2025
-
[16]
Im- proving transformer world models for data-efficient RL
Antoine Dedieu, Joseph Ortiz, Xinghua Lou, Carter Wendelken, J Swaroop Guntupalli, Wolfgang Lehrach, Miguel Lazaro-Gredilla, and Kevin Patrick Murphy. Im- proving transformer world models for data-efficient RL. InForty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id= IajCvMJw41
2025
-
[17]
Pilco: a model-based and data-efficient approach to pol- icy search
Marc Peter Deisenroth and Carl Edward Rasmussen. Pilco: a model-based and data-efficient approach to pol- icy search. InProceedings of the 28th International Conference on International Conference on Machine Learning, ICML’11, page 465–472, Madison, WI, USA,
-
[18]
ISBN 9781450306195
Omnipress. ISBN 9781450306195
-
[19]
Bert: Pre-training of deep bidirec- tional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirec- tional transformers for language understanding. InPro- ceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
2019
-
[20]
Visual foresight: Model-based deep reinforcement learning for vision-based robotic control,
Frederik Ebert, Chelsea Finn, Sudeep Dasari, Annie Xie, Alex Lee, and Sergey Levine. Visual foresight: Model-based deep reinforcement learning for vision- based robotic control.arXiv preprint arXiv:1812.00568, 2018
-
[21]
Genloco: Gen- eralized locomotion controllers for quadrupedal robots
Gilbert Feng, Hongbo Zhang, Zhongyu Li, Xue Bin Peng, Bhuvan Basireddy, Linzhu Yue, Zhitao Song, Lizhi Yang, Yunhui Liu, Koushil Sreenath, et al. Genloco: Gen- eralized locomotion controllers for quadrupedal robots. InConference on Robot Learning, pages 1893–1903. PMLR, 2023
1903
-
[22]
Finetuning offline world models in the real world
Yunhai Feng, Nicklas Hansen, Ziyan Xiong, Chan- dramouli Rajagopalan, and Xiaolong Wang. Finetuning offline world models in the real world. InProceedings of the 7th Conference on Robot Learning (CoRL), 2023
2023
-
[23]
Focus: object-centric world models for robotic manipulation.Frontiers in Neurorobotics, 19: 1585386, 2025
Stefano Ferraro, Pietro Mazzaglia, Tim Verbelen, and Bart Dhoedt. Focus: object-centric world models for robotic manipulation.Frontiers in Neurorobotics, 19: 1585386, 2025
2025
-
[24]
arXiv preprint arXiv:2506.22355 (2025) 5
Pascale Fung, Yoram Bachrach, Asli Celikyilmaz, Ka- malika Chaudhuri, Delong Chen, Willy Chung, Em- manuel Dupoux, Hongyu Gong, Herv´e J´egou, Alessandro Lazaric, et al. Embodied ai agents: Modeling the world. arXiv preprint arXiv:2506.22355, 2025
-
[25]
PWM: Policy learning with multi- task world models
Ignat Georgiev, Varun Giridhar, Nicklas Hansen, and Animesh Garg. PWM: Policy learning with multi- task world models. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=hOELrZfg0J
2025
-
[26]
Metamorph: Learning universal controllers with transformers
Agrim Gupta, Linxi Fan, Surya Ganguli, and Li Fei- Fei. Metamorph: Learning universal controllers with transformers. InInternational Conference on Learn- ing Representations, 2022. URL https://openreview.net/ forum?id=Opmqtk GvYL
2022
-
[27]
Recurrent world models facilitate policy evolution
David Ha and J ¨urgen Schmidhuber. Recurrent world models facilitate policy evolution. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018. URL https://proceedings.neurips.cc/paper files/paper/2018/ file/2de5d16682c3c35007e...
2018
-
[28]
Learning latent dynamics for planning from pixels
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels. In International conference on machine learning, pages 2555–2565. PMLR, 2019
2019
-
[29]
Mastering atari with discrete world models
Danijar Hafner, Timothy P Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with discrete world models. InInternational Conference on Learn- ing Representations, 2021. URL https://openreview.net/ forum?id=0oabwyZbOu
2021
-
[30]
Mastering diverse control tasks through world models.Nature, pages 1–7, 2025
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Tim- othy Lillicrap. Mastering diverse control tasks through world models.Nature, pages 1–7, 2025
2025
-
[31]
Td-mpc2: Scalable, robust world models for continuous control
Nicklas Hansen, Hao Su, and Xiaolong Wang. Td-mpc2: Scalable, robust world models for continuous control. In International Conference on Learning Representations, 2024
2024
-
[32]
Safedreamer: Safe reinforcement learning with world models
Weidong Huang, Jiaming Ji, Borong Zhang, Chunhe Xia, and Yaodong Yang. Safedreamer: Safe reinforcement learning with world models. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=tsE5HLYtYg
2024
-
[33]
One policy to control them all: Shared modular policies for agent-agnostic control
Wenlong Huang, Igor Mordatch, and Deepak Pathak. One policy to control them all: Shared modular policies for agent-agnostic control. InInternational Conference on Machine Learning, pages 4455–4464. PMLR, 2020
2020
-
[34]
Learning agile and dynamic motor skills for legged robots.Science Robotics, 4(26):eaau5872, 2019
Jemin Hwangbo, Joonho Lee, Alexey Dosovitskiy, Dario Bellicoso, Vassilios Tsounis, Vladlen Koltun, and Marco Hutter. Learning agile and dynamic motor skills for legged robots.Science Robotics, 4(26):eaau5872, 2019
2019
-
[35]
Dreamgen: Un- locking generalization in robot learning through neural trajectories.arXiv e-prints, pages arXiv–2505, 2025
Joel Jang, Seonghyeon Ye, Zongyu Lin, Jiannan Xiang, Johan Bjorck, Yu Fang, Fengyuan Hu, Spencer Huang, Kaushil Kundalia, Yen-Chen Lin, et al. Dreamgen: Un- locking generalization in robot learning through neural trajectories.arXiv e-prints, pages arXiv–2505, 2025
2025
-
[36]
Reinforce- ment learning in robotics: A survey.The International Journal of Robotics Research, 32(11):1238–1274, 2013
Jens Kober, J Andrew Bagnell, and Jan Peters. Reinforce- ment learning in robotics: A survey.The International Journal of Robotics Research, 32(11):1238–1274, 2013
2013
-
[37]
Ilya Kostrikov, Laura M Smith, and Sergey Levine. Demonstrating A Walk in the Park: Learning to Walk in 20 Minutes With Model-Free Reinforcement Learning. InProceedings of Robotics: Science and Systems, Daegu, Republic of Korea, July 2023. doi: 10.15607/RSS.2023. XIX.056
-
[38]
Rma: Rapid motor adaptation for legged robots
Ashish Kumar, Zipeng Fu, Deepak Pathak, and Jitendra Malik. Rma: Rapid motor adaptation for legged robots. InProceedings of Robotics: Science and Systems, 2021
2021
-
[39]
World model-based perception for visual legged locomotion
Hang Lai, Jiahang Cao, Jiafeng Xu, Hongtao Wu, Yun- feng Lin, Tao Kong, Yong Yu, and Weinan Zhang. World model-based perception for visual legged locomotion. In 2025 IEEE International Conference on Robotics and Automation (ICRA), pages 11531–11537. IEEE, 2025
2025
-
[40]
Cqm: Curriculum reinforcement learning with a quantized world model.Advances in Neural Information Processing Systems, 36:78824–78845, 2023
Seungjae Lee, Daesol Cho, Jonghae Park, and H Jin Kim. Cqm: Curriculum reinforcement learning with a quantized world model.Advances in Neural Information Processing Systems, 36:78824–78845, 2023
2023
-
[41]
Chenhao Li, Andreas Krause, and Marco Hutter. Offline robotic world model: Learning robotic policies without a physics simulator.arXiv preprint arXiv:2504.16680, 2025
-
[42]
Chenhao Li, Andreas Krause, and Marco Hutter. Robotic world model: A neural network simulator for ro- bust policy optimization in robotics.arXiv preprint arXiv:2501.10100, 2025
-
[43]
Unified video action model
Shuang Li, Yihuai Gao, Dorsa Sadigh, and Shuran Song. Unified video action model. InProceedings of Robotics: Science and Systems, 2025
2025
-
[44]
Harmonydream: Task harmonization inside world models
Haoyu Ma, Jialong Wu, Ningya Feng, Chenjun Xiao, Dong Li, Jianye Hao, Jianmin Wang, and Mingsheng Long. Harmonydream: Task harmonization inside world models. InInternational Conference on Machine Learn- ing, 2024
2024
-
[45]
GenRL: Multimodal- foundation world models for generalization in embodied agents
Pietro Mazzaglia, Tim Verbelen, Bart Dhoedt, Aaron Courville, and Sai Rajeswar. GenRL: Multimodal- foundation world models for generalization in embodied agents. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=za9Jx8yqUA
2024
-
[46]
Transformers are sample-efficient world models
Vincent Micheli, Eloi Alonso, and Franc ¸ois Fleuret. Transformers are sample-efficient world models. InThe Eleventh International Conference on Learning Repre- sentations, 2023. URL https://openreview.net/forum?id= vhFu1Acb0xb
2023
-
[47]
Efficient world models with context-aware tokeniza- tion
Vincent Micheli, Eloi Alonso, and Franc ¸ois Fleuret. Efficient world models with context-aware tokeniza- tion. InForty-first International Conference on Machine Learning, 2024. URL https://openreview.net/forum?id= BiWIERWBFX
2024
-
[48]
Prakhar Mishra, Amir Hossain Raj, Xuesu Xiao, and Dinesh Manocha. Mcarl: Morphology-control-aware re- inforcement learning for generalizable quadrupedal loco- motion.arXiv preprint arXiv:2505.18418, 2025
-
[49]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Mayank Mittal, Pascal Roth, James Tigue, Antoine Richard, Octi Zhang, Peter Du, Antonio Serrano-Mu ˜noz, Xinjie Yao, Ren ´e Zurbr ¨ugg, Nikita Rudin, Lukasz Wawrzyniak, Milad Rakhsha, Alain Denzler, Eric Hei- den, Ales Borovicka, Ossama Ahmed, Iretiayo Akinola, Abrar Anwar, Mark T. Carlson, Ji Yuan Feng, Ani- mesh Garg, Renato Gasoto, Lionel Gulich, Yijie...
work page internal anchor Pith review arXiv 2025
-
[50]
Model-based reinforcement learning: A survey.Foundations and Trends® in Machine Learning, 16(1):1–118, 2023
Thomas M Moerland, Joost Broekens, Aske Plaat, Catholijn M Jonker, et al. Model-based reinforcement learning: A survey.Foundations and Trends® in Machine Learning, 16(1):1–118, 2023
2023
-
[51]
Deep Dynamics Models for Learning Dexterous Manipulation
Anusha Nagabandi, Kurt Konoglie, Sergey Levine, and Vikash Kumar. Deep Dynamics Models for Learning Dexterous Manipulation. InConference on Robot Learn- ing (CoRL), 2019
2019
-
[52]
Lumos: Language-conditioned imitation learning with world models
Iman Nematollahi, Branton DeMoss, Akshay L Chandra, Nick Hawes, Wolfram Burgard, and Ingmar Posner. Lumos: Language-conditioned imitation learning with world models. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8219–8225,
-
[53]
doi: 10.1109/ICRA55743.2025.11127988
-
[54]
Isaac sim
NVIDIA. Isaac sim. https://github.com/isaac-sim/ IsaacSim, 2025. Version 5.1.0, Apache-2.0 License
2025
-
[55]
Learning to control self- assembling morphologies: a study of generalization via modularity.Advances in Neural Information Processing Systems, 32, 2019
Deepak Pathak, Christopher Lu, Trevor Darrell, Phillip Isola, and Alexei A Efros. Learning to control self- assembling morphologies: a study of generalization via modularity.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[56]
Ting Qiao, Henry Williams, David Valencia, and Bruce MacDonald. Bounded exploration with world model uncertainty in soft actor-critic reinforcement learning algorithm.arXiv preprint arXiv:2412.06139, 2024
-
[57]
General agents need world models
Jonathan Richens, Tom Everitt, and David Abel. General agents need world models. InForty-second International Conference on Machine Learning, 2025
2025
-
[58]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[59]
Planning to explore via self-supervised world models
Ramanan Sekar, Oleh Rybkin, Kostas Daniilidis, Pieter Abbeel, Danijar Hafner, and Deepak Pathak. Planning to explore via self-supervised world models. InInter- national conference on machine learning, pages 8583–
-
[60]
Body transformer: Leveraging robot embodiment for policy learning
Carmelo Sferrazza, Dun-Ming Huang, Fangchen Liu, Jongmin Lee, and Pieter Abbeel. Body transformer: Leveraging robot embodiment for policy learning. In 8th Annual Conference on Robot Learning, 2024. URL https://openreview.net/forum?id=Oce2215aJE
2024
-
[61]
Milad Shafiee, Guillaume Bellegarda, and Auke Ijspeert. Manyquadrupeds: Learning a single locomotion pol- icy for diverse quadruped robots.arXiv preprint arXiv:2310.10486, 2023
-
[62]
Mastering the game of go without human knowledge
David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, et al. Mastering the game of go without human knowledge. nature, 550(7676):354–359, 2017
2017
-
[63]
Richard S. Sutton. Dyna, an integrated architecture for learning, planning, and reacting.SIGART Bull., 2(4): 160–163, July 1991. ISSN 0163-5719. doi: 10.1145/ 122344.122377. URL https://doi.org/10.1145/122344. 122377
-
[64]
Anymorph: Learning transferable polices by inferring agent morphology
Brandon Trabucco, Mariano Phielipp, and Glen Berseth. Anymorph: Learning transferable polices by inferring agent morphology. InInternational Conference on Ma- chine Learning, pages 21677–21691. PMLR, 2022
2022
-
[65]
Making offline RL online: Collaborative world models for offline visual reinforce- ment learning
Qi Wang, Junming Yang, Yunbo Wang, Xin Jin, Wenjun Zeng, and Xiaokang Yang. Making offline RL online: Collaborative world models for offline visual reinforce- ment learning. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=ucxQrked0d
2024
-
[66]
Cross- embodiment robot manipulation skill transfer using la- tent space alignment,
Tianyu Wang, Dwait Bhatt, Xiaolong Wang, and Niko- lay Atanasov. Cross-embodiment robot manipulation skill transfer using latent space alignment.CoRR, abs/2406.01968, 2024. URL https://doi.org/10.48550/ arXiv.2406.01968
-
[67]
Nervenet: Learning structured policy with graph neural networks
Tingwu Wang, Renjie Liao, Jimmy Ba, and Sanja Fidler. Nervenet: Learning structured policy with graph neural networks. InInternational Conference on Learning Rep- resentations, 2018. URL https://openreview.net/forum? id=S1sqHMZCb
2018
-
[68]
Drama: Mamba-enabled model-based reinforcement learning is sample and parameter efficient
Wenlong Wang, Ivana Dusparic, Yucheng Shi, Ke Zhang, and Vinny Cahill. Drama: Mamba-enabled model-based reinforcement learning is sample and parameter efficient. InThe Thirteenth International Conference on Learn- ing Representations, 2025. URL https://openreview.net/ forum?id=7XIkRgYjK3
2025
-
[69]
Parallelizing Model-based Reinforcement Learning Over the Sequence Length
ZiRui Wang, Yue Deng, Junfeng Long, and Yin Zhang. Parallelizing Model-based Reinforcement Learning Over the Sequence Length. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, November 2024
2024
-
[70]
Ms- ppo: Morphological-symmetry-equivariant policy for legged robot locomotion,
Sizhe Wei, Xulin Chen, Fengze Xie, Garrett Ethan Katz, Zhenyu Gan, and Lu Gan. Ms-ppo: Morphological- symmetry-equivariant policy for legged robot locomo- tion.arXiv preprint arXiv:2512.00727, 2025
-
[71]
Learning modular robot control policies.IEEE Transac- tions on Robotics, 39(5):4095–4113, 2023
Julian Whitman, Matthew Travers, and Howie Choset. Learning modular robot control policies.IEEE Transac- tions on Robotics, 39(5):4095–4113, 2023
2023
-
[72]
Daydreamer: World models for physical robot learning
Philipp Wu, Alejandro Escontrela, Danijar Hafner, Pieter Abbeel, and Ken Goldberg. Daydreamer: World models for physical robot learning. In Karen Liu, Dana Kulic, and Jeff Ichnowski, editors,Proceedings of The 6th Conference on Robot Learning, volume 205 ofProceed- ings of Machine Learning Research, pages 2226–2240. PMLR, 14–18 Dec 2023. URL https://proce...
2023
-
[73]
V ocaloco: Viability- optimized cost-aware adaptive locomotion.IEEE Robotics and Automation Letters, 11(2):1146–1153, 2025
Stanley Wu, Mohamad H Danesh, Simon Li, Hanna Yurchyk, Amin Abyaneh, Anas El Houssaini, David Meger, and Hsiu-Chin Lin. V ocaloco: Viability- optimized cost-aware adaptive locomotion.IEEE Robotics and Automation Letters, 11(2):1146–1153, 2025
2025
-
[74]
Unilegs: Universal multi-legged robot control through morphology-agnostic policy distil- lation.IEEE/RSJ International Conference on Intelligent Robots and Systems, 2025
Weijie Xi, Zhanxiang Cao, Chenlin Ming, Jianying Zheng, and Guyue Zhou. Unilegs: Universal multi-legged robot control through morphology-agnostic policy distil- lation.IEEE/RSJ International Conference on Intelligent Robots and Systems, 2025
2025
-
[75]
Jiannan Xiang, Guangyi Liu, Yi Gu, Qiyue Gao, Yuting Ning, Yuheng Zha, Zeyu Feng, Tianhua Tao, Shibo Hao, Yemin Shi, Zhengzhong Liu, Eric P. Xing, and Zhiting Hu. Pandora: Towards general world model with natural language actions and video states.arXiv preprint arXiv:2406.09455, 2024
-
[76]
Morphological-symmetry-equivariant heteroge- neous graph neural network for robotic dynamics learn- ing
Fengze Xie, Sizhe Wei, Yue Song, Yisong Yue, and Lu Gan. Morphological-symmetry-equivariant heteroge- neous graph neural network for robotic dynamics learn- ing. In Necmiye Ozay, Laura Balzano, Dimitra Panagou, and Alessandro Abate, editors,Proceedings of the 7th Annual Learning for Dynamics & Control Confer- ence, volume 283 ofProceedings of Machine ...
2025
-
[77]
Uni- versal Morphology Control via Contextual Modulation
Zheng Xiong, Jacob Beck, and Shimon Whiteson. Uni- versal Morphology Control via Contextual Modulation. InProceedings of the 40th International Conference on Machine Learning, pages 38286–38300. PMLR, July 2023
2023
-
[78]
TWIST: Teacher-Student World Model Distillation for Efficient Sim-to-Real Transfer, November 2023
Jun Yamada, Marc Rigter, Jack Collins, and Ingmar Pos- ner. TWIST: Teacher-Student World Model Distillation for Efficient Sim-to-Real Transfer, November 2023
2023
-
[79]
Denis Yarats, Amy Zhang, Ilya Kostrikov, Brandon Amos, Joelle Pineau, and Rob Fergus. Improving sample efficiency in model-free reinforcement learning from images.Proceedings of the AAAI Conference on Artificial Intelligence, 35(12):10674–10681, May 2021. doi: 10.1609/aaai.v35i12.17276. URL https://ojs.aaai. org/index.php/AAAI/article/view/17276
-
[80]
Karen Liu, and Greg Turk
Wenhao Yu, Jie Tan, C. Karen Liu, and Greg Turk. Preparing for the unknown: Learning a universal policy with online system identification. InProceedings of Robotics: Science and Systems, 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.