Recognition: unknown
Structural Evaluation Metrics for SVG Generation via Leave-One-Out Analysis
Pith reviewed 2026-05-10 17:02 UTC · model grok-4.3
The pith
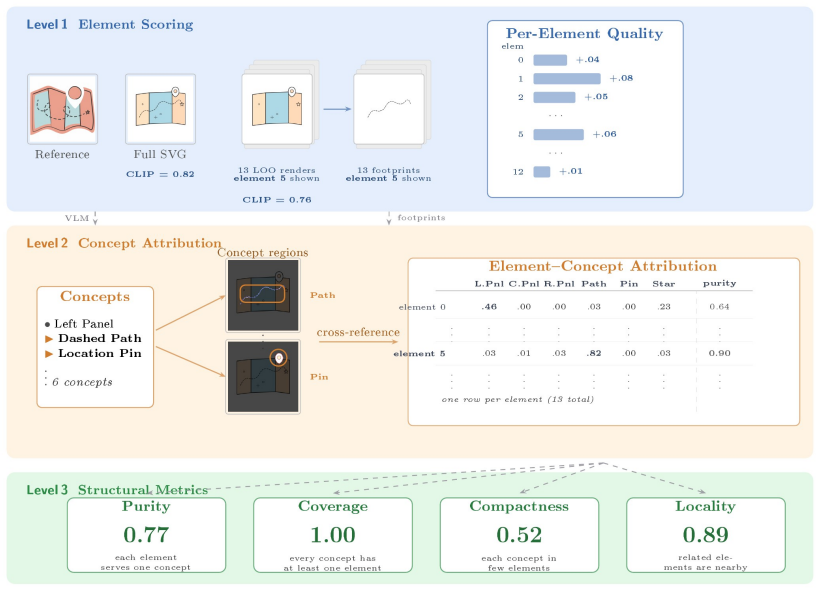
Leave-one-out rendering of each SVG element isolates its structural contribution to yield four modularity metrics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a single leave-one-out mechanism—rendering the full SVG and versions with each element removed—produces element-level signals sufficient to derive per-element quality scores, element-to-concept attributions, and four complementary structural metrics (purity, coverage, compactness, locality) that quantify SVG modularity and enable structural diagnosis of generated code.
What carries the argument
Element-level leave-one-out (LOO) analysis, which computes the visual impact of removing one SVG element at a time to isolate its structural contribution.
If this is right
- Per-element quality scores enable zero-shot detection of artifacts in generated SVGs.
- LOO footprints combined with VLM concept heatmaps enable attribution of visual concepts to individual elements.
- The purity, coverage, compactness, and locality metrics quantify SVG modularity from complementary angles.
- Evaluation extends from image similarity to code structure, supporting element-level diagnosis of how concepts are represented and organized.
Where Pith is reading between the lines
- If the LOO signals remain stable under different rendering engines, the metrics could be added to training losses to encourage generators to produce more modular code.
- The same removal-based signals might apply to other hierarchical outputs such as scene graphs or layered illustrations where element dependencies matter.
- Running the metrics on both AI-generated and hand-crafted SVGs could establish quantitative baselines for what counts as well-organized vector code.
- The four metrics together might serve as a diagnostic tool for comparing how different generation systems partition visual information into reusable elements.
Load-bearing premise
The visual difference caused by removing one element accurately isolates that element's structural contribution without being confounded by rendering order, overlaps, or interactions with other elements.
What would settle it
A controlled experiment in which removing an element produces a visual change that does not match its semantic role, or in which the four metrics give high modularity scores to visibly tangled SVGs, would show that LOO does not isolate structural properties.
Figures





read the original abstract
SVG generation is typically evaluated by comparing rendered outputs to reference images, which captures visual similarity but not the structural properties that make SVG editable, decomposable, and reusable. Inspired by the classical jackknife, we introduce element-level leave-one-out (LOO) analysis. The procedure renders the SVG with and without each element, which yields element-level signals for quality assessment and structural analysis. From this single mechanism, we derive (i) per-element quality scores that enable zero-shot artifact detection; (ii) element-concept attribution via LOO footprints crossed with VLM-grounded concept heatmaps; and (iii) four structural metrics: purity, coverage, compactness, and locality, which quantify SVG modularity from complementary angles. These metrics extend SVG evaluation from image similarity to code structure, enabling element-level diagnosis and comparison of how visual concepts are represented, partitioned, and organized within SVG code. Their practical relevance is validated on over 19,000 edits (5 types) across 5 generation systems and 3 complexity tiers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces element-level leave-one-out (LOO) analysis for SVG generation: render each SVG with and without individual elements to obtain per-element signals. From this, it derives (i) quality scores for zero-shot artifact detection, (ii) element-concept attributions by crossing LOO footprints with VLM concept heatmaps, and (iii) four structural metrics (purity, coverage, compactness, locality) that quantify modularity. The approach is validated on >19,000 edits (5 types) across 5 generation systems and 3 complexity tiers, extending evaluation beyond image similarity to code structure.
Significance. If the LOO differences reliably isolate structural contributions, the work offers a principled, label-free route to assess editability, decomposability, and concept organization in generated SVGs. The scale of the empirical validation and the zero-shot nature of the derived scores are concrete strengths that could influence downstream SVG generation research.
major comments (2)
- [Abstract / LOO procedure] The central derivation of all four structural metrics and the per-element scores rests on the assumption that pixel/feature differences after element removal isolate that element's contribution (abstract and the LOO procedure). This is load-bearing; however, SVG rendering involves z-order, opacity blending, clip paths, and attribute inheritance, so removal can produce residual visual effects on other elements. The manuscript does not appear to quantify or mitigate these interactions, which risks conflating code structure with rendering side-effects.
- [Element-concept attribution] The VLM-grounded attribution step (LOO footprints crossed with concept heatmaps) introduces an external model dependency whose independence from the structural metrics is unclear. If the VLM itself relies on similar visual cues, the attribution may not provide an independent structural signal; the paper should report ablation or correlation analysis between VLM attributions and the four metrics.
minor comments (2)
- [Structural metrics] Provide explicit equations or pseudocode for purity, coverage, compactness, and locality; the current high-level descriptions leave the precise aggregation from LOO differences ambiguous.
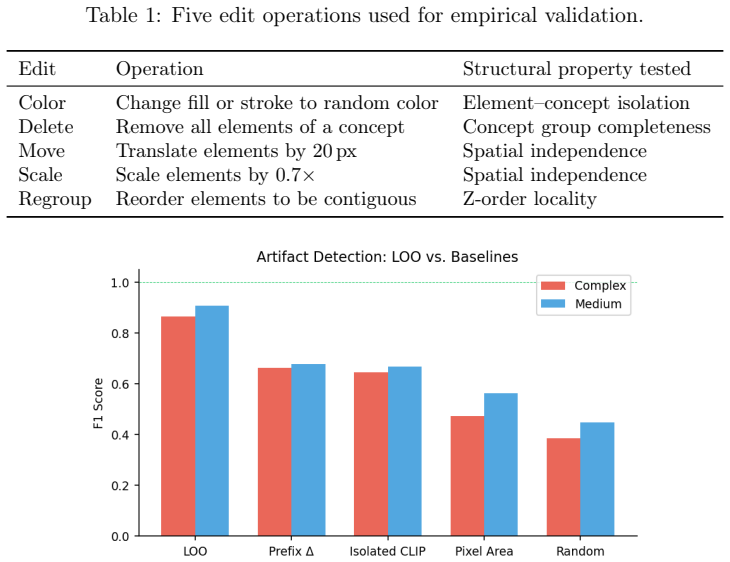
- [Validation] The validation reports 19,000 edits but lacks detail on statistical significance testing or controls for SVG complexity; adding these would strengthen the claim that the metrics generalize across tiers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We address the major concerns regarding the LOO procedure assumptions and the VLM attribution independence below. We will incorporate additional analyses and discussions in the revised manuscript to clarify these points.
read point-by-point responses
-
Referee: The central derivation of all four structural metrics and the per-element scores rests on the assumption that pixel/feature differences after element removal isolate that element's contribution (abstract and the LOO procedure). This is load-bearing; however, SVG rendering involves z-order, opacity blending, clip paths, and attribute inheritance, so removal can produce residual visual effects on other elements. The manuscript does not appear to quantify or mitigate these interactions, which risks conflating code structure with rendering side-effects.
Authors: We acknowledge the referee's concern about rendering interactions in SVGs. The LOO procedure is intended to capture the net effect of each element on the rendered output, which is relevant for assessing visual decomposability and editability. However, we agree that explicitly addressing potential side-effects from z-order, blending, and other factors would strengthen the paper. In the revision, we will add a dedicated discussion on these rendering considerations, including examples of interaction effects and an empirical quantification of their prevalence in the evaluated SVGs. This will help distinguish structural contributions from rendering artifacts. revision: yes
-
Referee: The VLM-grounded attribution step (LOO footprints crossed with concept heatmaps) introduces an external model dependency whose independence from the structural metrics is unclear. If the VLM itself relies on similar visual cues, the attribution may not provide an independent structural signal; the paper should report ablation or correlation analysis between VLM attributions and the four metrics.
Authors: The four structural metrics are derived solely from the LOO difference signals and do not depend on the VLM. The VLM is employed only to map these signals to semantic concepts for enhanced interpretability. To demonstrate the independence of the structural metrics from the VLM-based attributions, we will include a correlation analysis (e.g., Pearson coefficients) between the VLM attribution scores and the values of purity, coverage, compactness, and locality across our dataset of over 19,000 edits. We anticipate that this will show that the metrics provide complementary structural information independent of the VLM. revision: yes
Circularity Check
No circularity: metrics defined directly from LOO rendering differences
full rationale
The paper introduces element-level leave-one-out analysis as a new procedure and explicitly derives the per-element scores and four structural metrics (purity, coverage, compactness, locality) by definition from the with/without-element rendering differences. No equations reduce a claimed prediction or first-principles result to the inputs by construction. No self-citations are load-bearing for the core mechanism (inspired by classical jackknife, an external reference). The VLM attribution step uses an external model but does not create a self-referential loop. The derivation chain is self-contained and does not rely on fitted parameters renamed as predictions or uniqueness theorems from the authors' prior work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Single-element removal in rendered SVG produces a clean, additive difference signal that isolates structural contribution
Reference graph
Works this paper leans on
-
[1]
M. H. Quenouille. Notes on bias in estimation.Biometrika, 43(3–4):353–360, 1956
1956
-
[2]
J. W. Tukey. Bias and confidence in not-quite large samples (abstract).The Annals of Math- ematical Statistics, 29(2):614, 1958
1958
-
[3]
Rodríguez, Abhay Puri, Shubham Agarwal, Issam H
Juan A. Rodríguez, Abhay Puri, Shubham Agarwal, Issam H. Laradji, Pau Rodríguez, Sai Ra- jeswar, David Vázquez, Christopher Pal, and Marco Pedersoli. Starvector: Generating scalable vector graphics code from images and text. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16175–16186, 2025
2025
-
[4]
Omnisvg: A unified scalable vector graphics generation model.arXiv preprint arXiv:2504.06263, 2025b
Yiying Yang, Wei Cheng, Sijin Chen, Xianfang Zeng, Fukun Yin, Jiaxu Zhang, Liao Wang, Gang Yu, Xingjun Ma, and Yu-Gang Jiang. Omnisvg: A unified scalable vector graphics generation model.arXiv preprint arXiv:2504.06263, 2025
-
[5]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InPro- ceedings of the 38th International Conference on Machine Learning (ICML), pages 8748–8763, 2021
2021
-
[6]
James and C
W. James and C. Stein. Estimation with quadratic loss. InProceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, volume 1, pages 361–379, 1961
1961
-
[7]
Neuralsvg: An implicit representation for text-to-vector generation
Sagi Polaczek, Yuval Alaluf, Elad Richardson, Yael Vinker, and Daniel Cohen-Or. Neuralsvg: An implicit representation for text-to-vector generation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[8]
Text-to-vector generation with neural path representation.ACM Transactions on Graphics, 43(4):36:1–36:13, 2024
Peiying Zhang, Nanxuan Zhao, and Jing Liao. Text-to-vector generation with neural path representation.ACM Transactions on Graphics, 43(4):36:1–36:13, 2024
2024
-
[9]
A neural representation of sketch drawings
David Ha and Douglas Eck. A neural representation of sketch drawings. InInternational Conference on Learning Representations (ICLR), 2018
2018
-
[10]
Deepsvg: A hier- archical generative network for vector graphics animation
Alexandre Carlier, Martin Danelljan, Alexandre Alahi, and Radu Timofte. Deepsvg: A hier- archical generative network for vector graphics animation. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, pages 16351–16361, 2020
2020
-
[11]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step.arXiv preprint arXiv:2305.20050, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Solving math word problems with process- and outcome-based feedback
Jonathan Uesato, Nate Kushman, Ramana Kumar, H. Francis Song, Noah Y. Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process- and outcome-based feedback.arXiv preprint arXiv:2211.14275, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Evaluating Large Language Models Trained on Code
Mark Chen et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
Cian Eastwood and Christopher K. I. Williams. A framework for the quantitative evaluation of disentangledrepresentations. InInternational Conference on Learning Representations (ICLR), 2018. 11
2018
-
[15]
Efros, Aleksander Holynski, and Angjoo Kanazawa
Ayaan Haque, Matthew Tancik, Alexei A. Efros, Aleksander Holynski, and Angjoo Kanazawa. Instruct-nerf2nerf: Editing 3d scenes with instructions. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 19683–19693, 2023
2023
-
[16]
Cairosvg.https://cairosvg.org, 2026
CairoSVG Contributors. Cairosvg.https://cairosvg.org, 2026. SVG converter and renderer
2026
-
[17]
Understanding black-box predictions via influence functions
Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence functions. InProceedings of the 34th International Conference on Machine Learning (ICML), pages 1885– 1894, 2017
2017
-
[18]
Timo Lüddecke and Alexander S. Ecker. Image segmentation using text and image prompts. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7076–7086, 2022
2022
-
[19]
Elad Hirsch, Shubham Yadav, Mohit Garg, and Purvanshi Mehta. LICA: Layered image composition annotations for graphic design research.arXiv preprint arXiv:2603.16098, 2026
-
[20]
Svgenius: Benchmarking llms in svg understanding, editing and generation
Siqi Chen, Xinyu Dong, Haolei Xu, Xingyu Wu, Fei Tang, Hang Zhang, Yuchen Yan, Linjuan Wu, Wenqi Zhang, Guiyang Hou, et al. Svgenius: Benchmarking llms in svg understanding, editing and generation. InProceedings of the 33rd ACM International Conference on Multime- dia, pages 13289–13296, 2025
2025
-
[21]
Qwen3-coder: Agentic coding in the world.https://qwenlm.github.io/blog/ qwen3-coder/, 2025
Qwen Team. Qwen3-coder: Agentic coding in the world.https://qwenlm.github.io/blog/ qwen3-coder/, 2025. Official blog post
2025
-
[22]
Vtracer: Raster-to-vector graphics converter.https://www.visioncortex
Vision Cortex. Vtracer: Raster-to-vector graphics converter.https://www.visioncortex. org/vtracer-docs, 2023. Software
2023
-
[23]
Graphic-Design-Bench: A Comprehensive Benchmark for Evaluating AI on Graphic Design Tasks
Adrienne Deganutti, Elad Hirsch, Haonan Zhu, Jaejung Seol, and Purvanshi Mehta. Graphic- design-bench: A comprehensive benchmark for evaluating AI on graphic design tasks.arXiv preprint arXiv:2604.04192, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Juan A. Rodríguez, Haotian Zhang, Abhay Puri, Aarash Feizi, Rishav Pramanik, Pas- cal Wichmann, Arnab Kumar Mondal, Mohammad Reza Samsami, Rabiul Awal, Perouz Taslakian, Spandana Gella, Sai Rajeswar, David Vázquez, Christopher Pal, and Marco Ped- ersoli. Rendering-aware reinforcement learning for vector graphics generation.arXiv preprint arXiv:2505.20793, 2025
-
[25]
Ximing Xing, Yandong Guan, Jing Zhang, Dong Xu, and Qian Yu. Reason-svg: Hybrid reward rl for aha-moments in vector graphics generation.arXiv preprint arXiv:2505.24499, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Svgen: Interpretable vector graphics generation with large language models
Feiyu Wang, Zhiyuan Zhao, Yuandong Liu, Da Zhang, Junyu Gao, Hao Sun, and Xuelong Li. Svgen: Interpretable vector graphics generation with large language models. InProceedings of the 33rd ACM International Conference on Multimedia (ACM MM), pages 9608–9617, 2025
2025
-
[27]
Haomin Wang, Qi Wei, Qianli Ma, Shengyuan Ding, Jinhui Yin, Kai Chen, and Hongjie Zhang. Reliable reasoning in svg-llms via multi-task multi-reward reinforcement learning.arXiv preprint arXiv:2603.16189, 2026. A Medium and Simple Tier Results B Edit Precision Visualization 12 Table 4: Structural metrics, medium tier. Model Purity Cover. Compact. Locality ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.