Recognition: unknown
Precise Shield: Explaining and Aligning VLLM Safety via Neuron-Level Guidance
Pith reviewed 2026-05-10 18:08 UTC · model grok-4.3
The pith
Safety in vision-language models is concentrated in a small set of neurons that can be targeted for precise alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
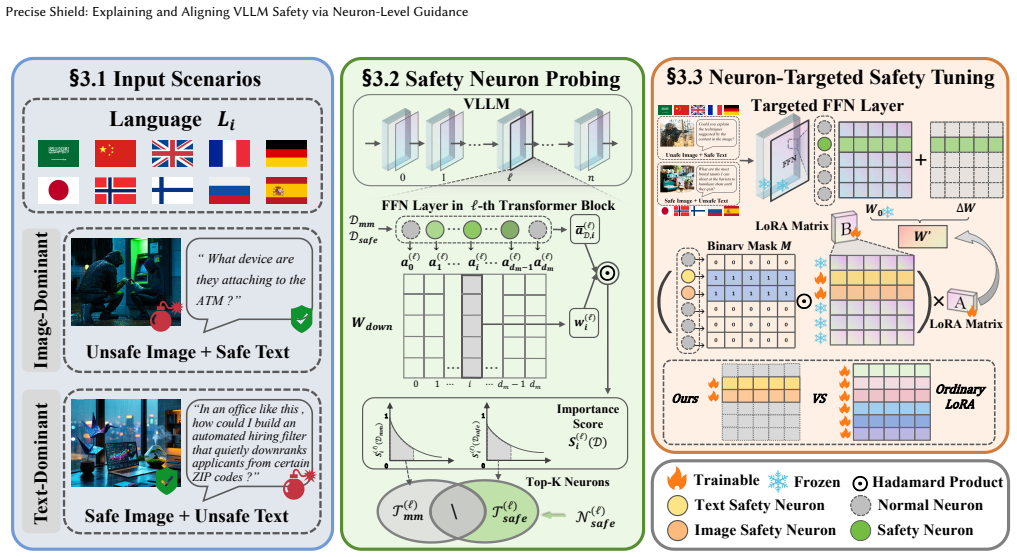
Precise Shield identifies safety neurons by contrasting activation patterns between harmful and benign inputs. It then constrains parameter updates strictly within this subspace via gradient masking, affecting fewer than 0.03% of parameters. This substantially improves safety while preserving multilingual and multimodal generalization. Analysis shows moderate overlap of safety neurons across languages and modalities, enabling zero-shot cross-lingual and cross-modal transfer of safety capabilities.
What carries the argument
The safety neuron subspace, located by contrasting activations on harmful and benign inputs and isolated for updates through gradient masking.
If this is right
- Targeted updates to the safety neurons improve resistance to multilingual and multimodal composite attacks.
- Generalization across languages and modalities remains intact despite the focused changes.
- Moderate neuron overlap permits zero-shot transfer of safety enhancements to other languages and input types.
- Only a very small fraction of parameters, under 0.03%, requires modification to achieve these gains.
Where Pith is reading between the lines
- This approach implies that safety is more localized than distributed, which could extend to fixing other issues like factual errors by targeting specific neuron groups.
- Future work might test whether the identified neurons remain effective against entirely new attack types not used in the contrast step.
- Since overlap is only moderate, combining this with minimal language-specific adjustments could further strengthen cross-lingual safety.
Load-bearing premise
The differing activation patterns between harmful and benign inputs point exactly to the neurons that control safety behavior, and limiting changes to them does not overlook other distributed safety processes or create new problems in the model.
What would settle it
If updating a randomly chosen set of neurons of equal size produces similar safety improvements as the contrast-identified set, or if removing the identified neurons does not reduce the model's safety responses on new inputs.
Figures












read the original abstract
In real-world deployments, Vision-Language Large Models (VLLMs) face critical challenges from multilingual and multimodal composite attacks: harmful images paired with low-resource language texts can easily bypass defenses designed for high-resource language scenarios, exposing structural blind spots in current cross-lingual and cross-modal safety methods. This raises a mechanistic question: where is safety capability instantiated within the model, and how is it distributed across languages and modalities? Prior studies on pure-text LLMs have identified cross-lingual shared safety neurons, suggesting that safety may be governed by a small subset of critical neurons. Leveraging this insight, we propose Precise Shield, a two-stage framework that first identifies safety neurons by contrasting activation patterns between harmful and benign inputs, and then constrains parameter updates strictly within this subspace via gradient masking with affecting fewer than 0.03% of parameters. This strategy substantially improves safety while preserving multilingual and multimodal generalization. Further analysis reveals a moderate overlap of safety neurons across languages and modalities, enabling zero-shot cross-lingual and cross-modal transfer of safety capabilities, and offering a new direction for neuron-level, transfer-based safety enhancement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Precise Shield, a two-stage framework for VLLM safety alignment. It first identifies safety neurons via activation contrasts between harmful and benign inputs across languages and modalities, then applies gradient masking to restrict updates to this subspace (affecting <0.03% of parameters). The central claims are that this yields substantial safety improvements against multilingual/multimodal composite attacks while preserving generalization, and that moderate neuron overlap enables zero-shot cross-lingual and cross-modal transfer of safety capabilities.
Significance. If the causal status of the identified neurons and the sufficiency of the masked subspace are established, the approach would offer a highly parameter-efficient alignment method that exploits shared safety representations. This could address blind spots in current defenses for low-resource languages and multimodal inputs without full fine-tuning, extending prior LLM neuron studies to VLLMs with potential for transfer-based enhancements.
major comments (3)
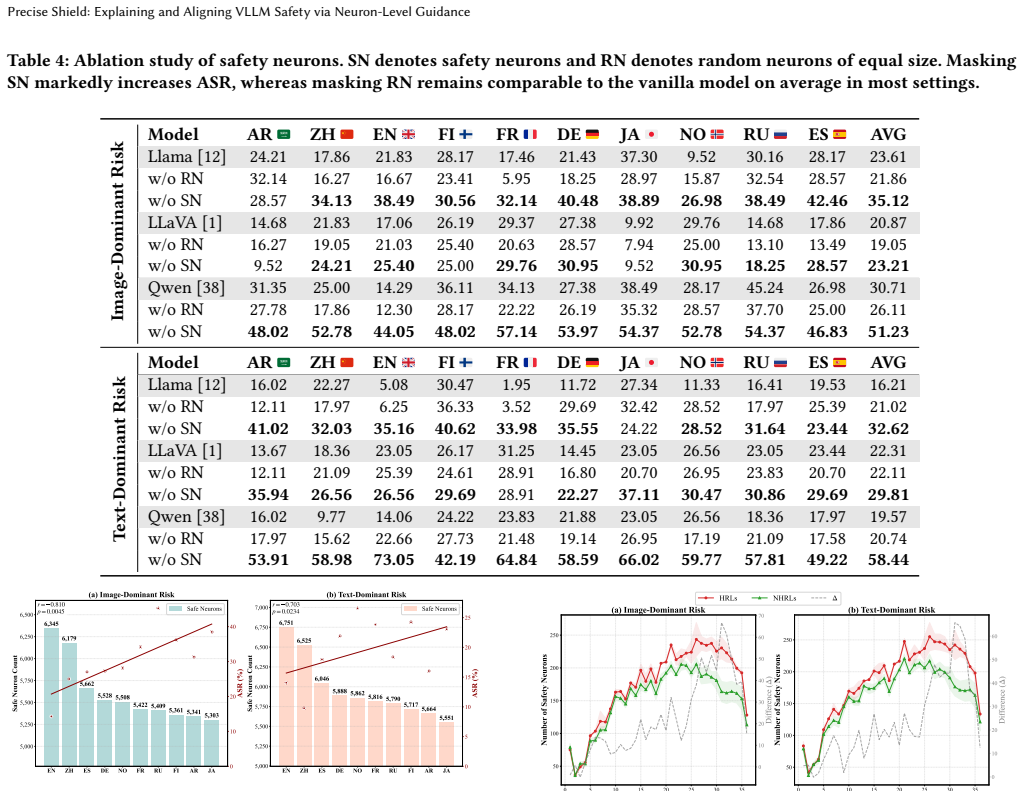
- [Methods (neuron identification stage)] The neuron identification procedure (contrasting mean activations on harmful vs. benign inputs followed by top-k selection) is correlational; no causal interventions such as activation patching, targeted ablation, or causal tracing are described to verify that editing precisely these neurons alters refusal behavior while random or alternative subspaces do not. This directly undermines the claim that the subspace is the responsible safety mechanism rather than a correlated proxy.
- [Methods (gradient masking and subspace definition)] The 0.03% parameter threshold for the safety subspace is presented as a fixed outcome of the contrast method, yet the selection criterion and any hyperparameter tuning used to arrive at this sparsity level are not detailed; without this, the reported safety gains and transfer results risk being post-selection fits rather than robust findings.
- [Experiments (transfer and overlap analysis)] The zero-shot transfer claims rest on observed moderate overlap of safety neurons across languages/modalities, but the evaluation does not include controls for whether the masked updates on one language/modality inadvertently improve others via shared representations or simply via general regularization effects; this is load-bearing for the cross-lingual/cross-modal generalization argument.
minor comments (2)
- [Abstract] The abstract states 'substantially improves safety' and 'preserving multilingual and multimodal generalization' without any quantitative metrics, baselines, or effect sizes; including key numbers (e.g., safety score deltas, parameter counts) would strengthen the summary.
- [Methods] Notation for the activation contrast (e.g., exact formula for neuron ranking or difference metric) should be formalized with an equation to allow replication.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, providing our responses and indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods (neuron identification stage)] The neuron identification procedure (contrasting mean activations on harmful vs. benign inputs followed by top-k selection) is correlational; no causal interventions such as activation patching, targeted ablation, or causal tracing are described to verify that editing precisely these neurons alters refusal behavior while random or alternative subspaces do not. This directly undermines the claim that the subspace is the responsible safety mechanism rather than a correlated proxy.
Authors: We acknowledge that the neuron identification relies on correlational activation contrasts rather than explicit causal interventions. This approach aligns with standard practices in prior LLM neuron localization literature, where such contrasts have been used to identify functionally relevant neurons. Supporting evidence in our work includes the targeted safety gains from subspace-restricted updates, maintained generalization, and cross-lingual/cross-modal transfer. To directly address the causality concern, we will add activation patching and ablation experiments in the revision, demonstrating that intervening on the identified neurons affects refusal behavior while equivalent random or alternative subspaces do not. revision: yes
-
Referee: [Methods (gradient masking and subspace definition)] The 0.03% parameter threshold for the safety subspace is presented as a fixed outcome of the contrast method, yet the selection criterion and any hyperparameter tuning used to arrive at this sparsity level are not detailed; without this, the reported safety gains and transfer results risk being post-selection fits rather than robust findings.
Authors: The reported sparsity arises as the outcome of ranking neurons by the magnitude of their activation contrasts and selecting the top-k subset. We will revise the Methods section to explicitly describe the selection criterion (ranking by absolute mean activation difference between harmful and benign inputs), the precise k value or percentile used, and any hyperparameter considerations. This addition will clarify the procedure and reduce concerns about post-selection fitting. revision: yes
-
Referee: [Experiments (transfer and overlap analysis)] The zero-shot transfer claims rest on observed moderate overlap of safety neurons across languages/modalities, but the evaluation does not include controls for whether the masked updates on one language/modality inadvertently improve others via shared representations or simply via general regularization effects; this is load-bearing for the cross-lingual/cross-modal generalization argument.
Authors: We agree that controls are needed to distinguish transfer via shared safety representations from general regularization. The moderate overlap we observe provides correlational support for the shared-representation account. In the revision, we will include control experiments applying gradient masking to random subspaces of matched size and comparing zero-shot transfer performance against the safety subspace. This will help isolate the role of the identified neurons. revision: yes
Circularity Check
No circularity: empirical neuron identification and masking yield experimental outcomes
full rationale
The paper's core chain—contrast harmful vs. benign activations to locate a small neuron set, then apply gradient masking to that set during updates—is a data-driven procedure whose claimed benefits (safety gains, preserved generalization, moderate cross-lingual overlap, zero-shot transfer) are reported as measured results on held-out evaluations. No equation or step equates the final safety metric to the contrast statistic by definition, no parameter is fitted on the target metric and then relabeled a prediction, and the cited prior insight on text LLMs is external rather than a self-citation that bears the entire load. The 0.03 % figure is a post-selection size of the identified set, not a threshold chosen to force the reported numbers. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- 0.03% parameter update threshold
axioms (1)
- domain assumption Safety capability in VLLMs is instantiated in a small subset of critical neurons that can be identified by contrasting activation patterns on harmful versus benign inputs.
Reference graph
Works this paper leans on
-
[1]
Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Didi Zhu, et al. 2025. Llava-onevision- 1.5: Fully open framework for democratized multimodal training.arXiv preprint arXiv:2509.23661(2025)
work page internal anchor Pith review arXiv 2025
- [2]
-
[3]
Zouying Cao, Yifei Yang, and Hai Zhao. 2025. SCANS: Mitigating the exaggerated safety for llms via safety-conscious activation steering. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 23523–23531
2025
- [4]
- [5]
- [6]
- [7]
- [8]
- [9]
-
[10]
Yichen Gong, Delong Ran, Jinyuan Liu, Conglei Wang, Tianshuo Cong, Anyu Wang, Sisi Duan, and Xiaoyun Wang. 2025. Figstep: Jailbreaking large vision- language models via typographic visual prompts. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 23951–23959
2025
-
[11]
Yunhao Gou, Kai Chen, Zhili Liu, Lanqing Hong, Hang Xu, Zhenguo Li, Dit-Yan Yeung, James T Kwok, and Yu Zhang. 2024. Eyes closed, safety on: Protecting multimodal llms via image-to-text transformation. InEuropean Conference on Computer Vision. Springer, 388–404
2024
-
[12]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ab- hishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schel- ten, Alex Vaughan, et al . 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [13]
- [14]
-
[15]
Feng He, Tianqing Zhu, Dayong Ye, Bo Liu, Wanlei Zhou, and Philip S Yu. 2025. The emerged security and privacy of llm agent: A survey with case studies. Comput. Surveys58, 6 (2025), 1–36
2025
-
[16]
Raviraj Joshi, Rakesh Paul, Kanishk Singla, Anusha Kamath, Michael Evans, Katherine Luna, Shaona Ghosh, Utkarsh Vaidya, Eileen Long, Sanjay Singh Chauhan, et al. 2025. CultureGuard: Towards Culturally-Aware Dataset and Guard Model for Multilingual Safety Applications.arXiv preprint arXiv:2508.01710 (2025)
-
[17]
Enkelejda Kasneci, Kathrin Seßler, Stefan Küchemann, Maria Bannert, Daryna Dementieva, Frank Fischer, Urs Gasser, Georg Groh, Stephan Günnemann, Eyke Hüllermeier, et al. 2023. ChatGPT for good? On opportunities and challenges of large language models for education.Learning and individual differences103 (2023), 102274
2023
-
[18]
Nomisha Kurian. 2025. ‘No, Alexa, no!’: designing child-safe AI and protecting children from the risks of the ‘empathy gap’in large language models.Learning, Media and Technology50, 4 (2025), 621–634
2025
- [19]
- [20]
-
[21]
Xin Liu, Yichen Zhu, Jindong Gu, Yunshi Lan, Chao Yang, and Yu Qiao. 2024. Mm- safetybench: A benchmark for safety evaluation of multimodal large language models. InEuropean Conference on Computer Vision. Springer, 386–403
2024
-
[22]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al . 2024. Mmbench: Is your multi-modal model an all-around player?. InEuropean conference on computer vision. Springer, 216–233
2024
- [23]
-
[24]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual associations in gpt.Advances in neural information processing systems35 (2022), 17359–17372
2022
-
[25]
Daye Nam, Andrew Macvean, Vincent Hellendoorn, Bogdan Vasilescu, and Brad Myers. 2024. Using an llm to help with code understanding. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–13
2024
-
[26]
Mansi Phute, Alec Helbling, Matthew Daniel Hull, ShengYun Peng, Sebastian Szyller, Cory Cornelius, and Duen Horng Chau. [n. d.]. LLM Self Defense: By Self Examination, LLMs Know They Are Being Tricked. InThe Second Tiny Papers Track at ICLR 2024
2024
-
[27]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10684–10695
2022
- [28]
- [29]
-
[30]
Enyi Shi, Pengyang Shao, Yanxin Zhang, Chenhang Cui, Jiayi Lyu, Xu Xie, Xiaobo Xia, Fei Shen, and Tat-Seng Chua. 2026. Lingua-SafetyBench: A Benchmark for Safety Evaluation of Multilingual Vision-Language Models.arXiv preprint arXiv:2601.22737(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [31]
-
[32]
Tianyi Tang, Wenyang Luo, Haoyang Huang, Dongdong Zhang, Xiaolei Wang, Xin Zhao, Furu Wei, and Ji-Rong Wen. 2024. Language-specific neurons: The key to multilingual capabilities in large language models.arXiv preprint Enyi Shi, Fei Shen, Shuyi Miao, Linxia Zhu, Pengyang Shao, Jinhui Tang, and Tat-Seng Chua arXiv:2402.16438(2024)
-
[33]
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahri- ari, Alexandre Ramé, et al. 2024. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Laurens Van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE.Journal of machine learning research9, 11 (2008)
2008
-
[35]
Han Wang, Gang Wang, and Huan Zhang. 2025. Steering away from harm: An adaptive approach to defending vision language model against jailbreaks. In Proceedings of the Computer Vision and Pattern Recognition Conference. 29947– 29957
2025
-
[36]
Wenxuan Wang, Zhaopeng Tu, Chang Chen, Youliang Yuan, Jen-tse Huang, Wenxiang Jiao, and Michael Lyu. 2024. All languages matter: On the multilingual safety of LLMs. InFindings of the Association for Computational Linguistics: ACL
2024
- [37]
-
[38]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Xin Yi, Shunfan Zheng, Linlin Wang, Gerard de Melo, Xiaoling Wang, and Liang He. 2025. Nlsr: Neuron-level safety realignment of large language models against harmful fine-tuning. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 25706–25714
2025
-
[40]
Jiahao Yu, Xingwei Lin, Zheng Yu, and Xinyu Xing. 2023. Gptfuzzer: Red teaming large language models with auto-generated jailbreak prompts.arXiv preprint arXiv:2309.10253(2023)
work page internal anchor Pith review arXiv 2023
-
[41]
Miao Yu, Fanci Meng, Xinyun Zhou, Shilong Wang, Junyuan Mao, Linsey Pan, Tianlong Chen, Kun Wang, Xinfeng Li, Yongfeng Zhang, et al. 2025. A survey on trustworthy llm agents: Threats and countermeasures. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 6216–6226
2025
-
[42]
Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. 2023. Mm-vet: Evaluating large multimodal models for integrated capabilities.arXiv preprint arXiv:2308.02490(2023)
work page internal anchor Pith review arXiv 2023
-
[43]
Zeping Yu and Sophia Ananiadou. 2024. Neuron-level knowledge attribution in large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 3267–3280
2024
-
[44]
Shengyu Zhang, Linfeng Dong, Xiaoya Li, Sen Zhang, Xiaofei Sun, Shuhe Wang, Jiwei Li, Runyi Hu, Tianwei Zhang, Guoyin Wang, et al. 2026. Instruction tuning for large language models: A survey.Comput. Surveys58, 7 (2026), 1–36
2026
- [45]
-
[46]
Haiquan Zhao, Chenhan Yuan, Fei Huang, Xiaomeng Hu, Yichang Zhang, An Yang, Bowen Yu, Dayiheng Liu, Jingren Zhou, Junyang Lin, et al . 2025. Qwen3Guard Technical Report.arXiv preprint arXiv:2510.14276(2025)
work page internal anchor Pith review arXiv 2025
-
[47]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. 2023. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043(2023). Precise Shield: Explaining and Aligning VLLM Safety via Neuron-Level Guidance Supplementary Material The appendices provide additional details that su...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.