Recognition: no theorem link
From OSS to Open Source AI: an Exploratory Study of Collaborative Development Paradigm Divergence
Pith reviewed 2026-05-10 17:53 UTC · model grok-4.3
The pith
Open source AI models show lower collaboration intensity and a shift to adaptive user-innovation compared with traditional open source software.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Compared with the traditional open source software development paradigm, the open source AI model development paradigm exhibits significantly lower collaboration intensity, lower collaboration openness regarding direct contribution while persisting relatively open knowledge exchange, and a divergence toward adaptive utilization user-innovation rather than collaborative improvement.
What carries the argument
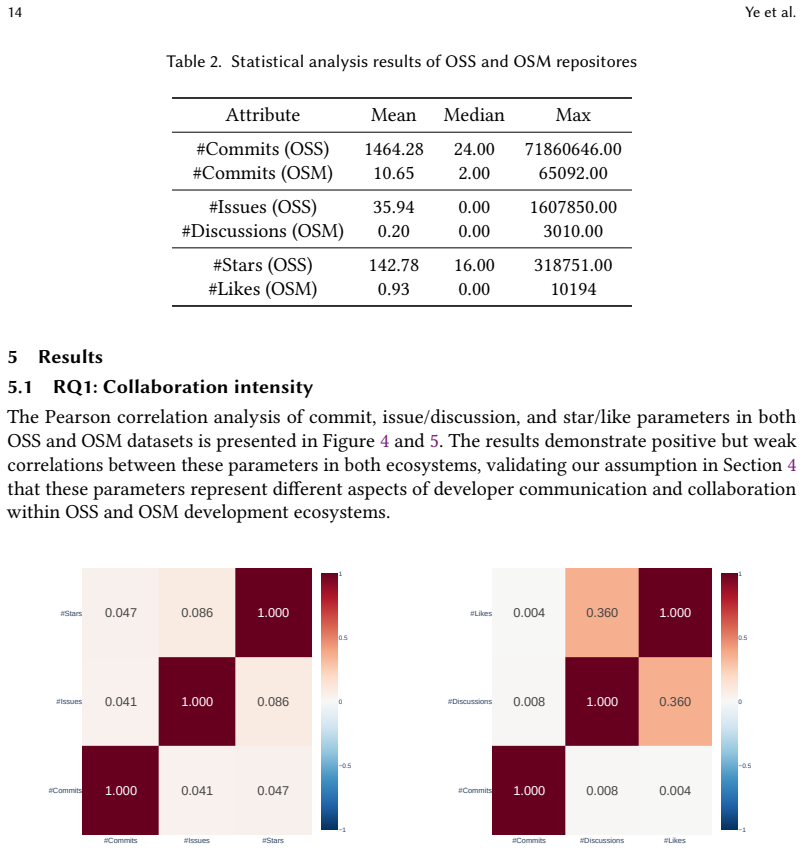
Large-scale comparative analysis of collaboration intensity, openness, and user-innovation metrics drawn from repository data on GitHub and Hugging Face Hub, augmented by social-network and content analyses plus semi-structured interviews.
Load-bearing premise
The chosen metrics from repository data and the interview sample accurately capture and explain the underlying collaborative paradigms without significant selection bias or unmeasured confounders.
What would settle it
Re-running the same intensity and openness calculations on a fresh, randomly sampled set of repositories or on contributor survey responses and finding no statistically significant difference between the two paradigms.
Figures





read the original abstract
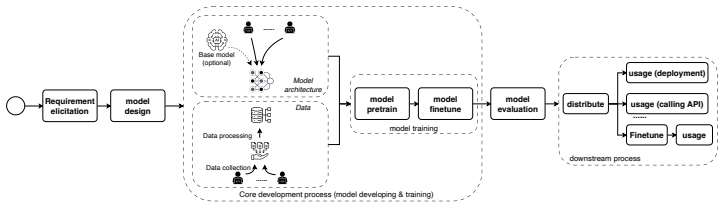
AI development is embracing open-source paradigm, but the fundamental distinction between AI models and traditional software artifacts may lead to a divergent open-source development paradigm with different collaborative practices, which remains unexplored. We therefore bridge the knowledge gap by quantifying and characterizing the differences in the collaborative development paradigms of traditional open source software (OSS) and open source AI models (OSM), and investigating the underlying factors that may drive these distinctions. We collect 1,428,792 OSS repositories from GitHub and 1,440,527 OSM repositories from HF Hub, and conduct comprehensive statistical, social network and content analyses to measure and understand the differences in collaboration intensity, collaboration openness, and user innovation across the two development paradigms, complementing these quantitative results with semi-structured interviews. In consequence, we find that compared to OSS development paradigm, the OSM development paradigm exhibits significantly lower collaboration intensity; lower collaboration openness regarding direct contribution while persisting relatively open knowledge exchange; and a divergence toward adaptive utilization user-innovation rather than collaborative improvement. Through semi-structured interviews, we further elucidate the socio-technical factors underlying these differences. These findings reveal the paradigmatic divergence in open source development between traditional OSS and OSM across three critical dimensions of open source collaboration and potential underlying factors, shedding light on how to improve collaborative work techniques and practices within the context of AI development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that open-source AI model (OSM) development on Hugging Face Hub diverges from traditional OSS on GitHub: using data from 1.4M+ repositories each plus SNA, stats, content analysis, and interviews, it finds OSM shows significantly lower collaboration intensity, lower openness on direct contributions (while retaining open knowledge exchange), and a shift toward adaptive utilization/user-innovation rather than collaborative improvement. Socio-technical factors are explored via interviews.
Significance. If the platform-comparability issues are resolved, the work offers a large-scale descriptive baseline on how artifact type (models vs. code) shapes open collaboration, with practical implications for AI dev practices. Strengths include the repository scale supporting statistical comparisons, mixed-methods design, and grounding in public platform data.
major comments (1)
- [Data Collection and Quantitative Analysis] The central claims of significantly lower collaboration intensity and lower direct-contribution openness in OSM (abstract; results sections) rest on treating GitHub and HF Hub repositories as equivalent units for counting contributors, interaction edges, and collaboration signals. GitHub captures commits/PRs/issues as primary signals, while HF Hub hosts serialized weights/configs/model cards with most adaptation occurring externally; without explicit normalization for these affordances in the extraction pipeline, the quantitative divergences risk being partly artifactual. This is load-bearing for the 'significantly lower' and 'divergence toward adaptive utilization' statements.
minor comments (3)
- [Methodology] Clarify the exact operationalization of 'collaboration intensity' and 'openness' metrics (e.g., how unique contributors and interaction edges are defined and normalized across platforms) to allow replication.
- [Interviews] Provide more detail on interview sampling strategy, participant demographics, and how themes were derived to assess selection bias in the qualitative component.
- [Results] Report effect sizes or confidence intervals alongside p-values in statistical comparisons to strengthen the 'significantly lower' claims.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address the major comment on data collection and quantitative analysis below, agreeing that platform differences require careful consideration. We will revise the manuscript to strengthen the discussion on comparability.
read point-by-point responses
-
Referee: The central claims of significantly lower collaboration intensity and lower direct-contribution openness in OSM (abstract; results sections) rest on treating GitHub and HF Hub repositories as equivalent units for counting contributors, interaction edges, and collaboration signals. GitHub captures commits/PRs/issues as primary signals, while HF Hub hosts serialized weights/configs/model cards with most adaptation occurring externally; without explicit normalization for these affordances in the extraction pipeline, the quantitative divergences risk being partly artifactual. This is load-bearing for the 'significantly lower' and 'divergence toward adaptive utilization' statements.
Authors: We thank the referee for this insightful observation. While GitHub and HF Hub have different primary signals, our quantitative analysis focuses on comparable metrics of collaboration intensity (e.g., average contributors per repo, network density) and openness (e.g., proportion of external vs internal contributions where measurable). We did apply some normalization by repository size and activity in our statistical comparisons. Nevertheless, we acknowledge that full normalization for external adaptations is not feasible with available data, as HF Hub does not track downstream uses comprehensively. We will add a new paragraph in the Discussion section elaborating on these socio-technical differences and their impact on measurement, and include it as a limitation. Additionally, the mixed-methods approach with interviews helps triangulate the findings beyond pure quantitative counts. We believe this addresses the concern without invalidating the core claims, which are supported by multiple lines of evidence. revision: partial
Circularity Check
No circularity: empirical measurements from external public repositories
full rationale
The paper performs an exploratory empirical study by collecting 1.4M+ OSS repos from GitHub and 1.4M+ OSM repos from HF Hub, then applies statistical, social-network, and content analyses plus new semi-structured interviews. No equations, fitted parameters, or derivations are present. Central claims (lower collaboration intensity, lower direct-contribution openness, shift to adaptive user-innovation) are direct outputs of these external data measurements rather than reductions to self-citations, ansatzes, or prior results by the same authors. The analysis is therefore self-contained against external benchmarks with no load-bearing step that collapses to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Public repositories on GitHub and HF Hub accurately represent the collaborative development practices of OSS and OSM paradigms
- domain assumption Statistical, social network, and content analyses can reliably measure collaboration intensity, openness, and user-innovation type
Reference graph
Works this paper leans on
-
[1]
Ahmad Abdellatif, Mairieli Wessel, Igor Steinmacher, Marco A Gerosa, and Emad Shihab. 2022. BotHunter: An approach to detect software bots in GitHub. InProceedings of the 19th International Conference on Mining Software Repositories. 6–17
2022
-
[2]
Karan Aggarwal, Abram Hindle, and Eleni Stroulia. 2014. Co-evolution of project documentation and popularity within github. InProceedings of the 11th working conference on mining software repositories. 360–363
2014
-
[3]
2022.Stable diffusion public release
Stability AI. 2022.Stable diffusion public release. Retrieved April 1, 2025 from https://stability.ai/blog/stable-diffusion- public-release
2022
-
[4]
Adem Ait, Javier Luis Cánovas Izquierdo, and Jordi Cabot. 2025. On the suitability of hugging face hub for empirical studies.Empirical Software Engineering30, 2 (2025), 1–48
2025
-
[5]
Adem Ait, Javier Luis Cánovas Izquierdo, and Jordi Cabot. 2023. Hfcommunity: A tool to analyze the hugging face hub community. In2023 IEEE international conference on software analysis, evolution and reengineering (SANER). IEEE, 728–732
2023
-
[6]
Christopher Akiki, Giada Pistilli, Margot Mieskes, Matthias Gallé, Thomas Wolf, Suzana Ilić, and Yacine Jernite
- [7]
-
[8]
Mohammad AlMarzouq, Li Zheng, Guang Rong, and Varun Grover. 2005. Open source: Concepts, benefits, and challenges.Communications of the Association for Information Systems16, 1 (2005), 37
2005
-
[9]
2022.a project to record the public github timeline, archive it, and make it easily accessible for further analysis
GH Archive. 2022.a project to record the public github timeline, archive it, and make it easily accessible for further analysis. Retrieved April 1, 2025 from https://www.gharchive.org
2022
-
[10]
Yochai Benkler and Helen Nissenbaum. 2006. Commons-based peer production and virtue.Journal of political philosophy14, 4 (2006)
2006
-
[11]
Marcus Vinicius Bertoncello, Gustavo Pinto, Igor Scaliante Wiese, and Igor Steinmacher. 2020. Pull requests or commits? which method should we use to study contributors’ behavior?. In2020 IEEE 27th International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 592–601
2020
-
[12]
Dane Bertram, Amy Voida, Saul Greenberg, and Robert Walker. 2010. Communication, collaboration, and bugs: the social nature of issue tracking in small, collocated teams. InProceedings of the 2010 ACM conference on Computer supported cooperative work. 291–300
2010
-
[13]
S Bhaskaran and Raja Marappan. 2023. Enhanced personalized recommendation system for machine learning public datasets: generalized modeling, simulation, significant results and analysis.International Journal of Information Technology15, 3 (2023), 1583–1595
2023
-
[14]
Tegawendé F Bissyandé, David Lo, Lingxiao Jiang, Laurent Réveillere, Jacques Klein, and Yves Le Traon. 2013. Got issues? who cares about it? a large scale investigation of issue trackers from github. In2013 IEEE 24th international symposium on software reliability engineering (ISSRE). IEEE, 188–197
2013
-
[15]
Erling Bjögvinsson, Pelle Ehn, and Per-Anders Hillgren. 2012. Design things and design thinking: Contemporary participatory design challenges.Design issues28, 3 (2012), 101–116
2012
-
[16]
Alexander Boden, Frank Rosswog, Gunnar Stevens, and Volker Wulf. 2014. Articulation spaces: bridging the gap between formal and informal coordination. InProceedings of the 17th ACM conference on Computer supported cooperative work & social computing. 1120–1130
2014
-
[17]
Marcel Bogers and Joel West. 2012. Managing distributed innovation: Strategic utilization of open and user innovation. Creativity and innovation management21, 1 (2012), 61–75
2012
-
[18]
Stephen P Borgatti and Martin G Everett. 2000. Models of core/periphery structures.Social networks21, 4 (2000), 375–395
2000
-
[19]
Hudson Borges and Marco Tulio Valente. 2018. What’s in a github star? understanding repository starring practices in a social coding platform.Journal of Systems and Software146 (2018), 112–129
2018
-
[20]
Virginia Braun and Victoria Clarke. 2006. Using thematic analysis in psychology.Qualitative research in psychology 3, 2 (2006), 77–101. 26 Ye et al
2006
-
[21]
Virginia Braun and Victoria Clarke. 2019. Reflecting on reflexive thematic analysis.Qualitative research in sport, exercise and health11, 4 (2019), 589–597
2019
-
[22]
Scott Brisson, Ehsan Noei, and Kelly Lyons. 2020. We are family: analyzing communication in github software repositories and their forks. In2020 IEEE 27th International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 59–69
2020
-
[23]
John L Campbell, Charles Quincy, Jordan Osserman, and Ove K Pedersen. 2013. Coding in-depth semistructured interviews: Problems of unitization and intercoder reliability and agreement.Sociological methods & research42, 3 (2013), 294–320
2013
-
[24]
Joel Castaño, Silverio Martínez-Fernández, and Xavier Franch. 2024. Lessons learned from mining the hugging face repository. InProceedings of the 1st IEEE/ACM International Workshop on Methodological Issues with Empirical Studies in Software Engineering. 1–6
2024
-
[25]
Joel Castaño, Silverio Martínez-Fernández, Xavier Franch, and Justus Bogner. 2024. Analyzing the evolution and maintenance of ml models on hugging face. InProceedings of the 21st International Conference on Mining Software Repositories. 607–618
2024
-
[26]
Natarajan Chidambaram and Pooya Rostami Mazrae. 2022. Bot detection in github repositories. InProceedings of the 19th International Conference on Mining Software Repositories. 726–728
2022
-
[27]
Prerna Chikersal, Maria Tomprou, Young Ji Kim, Anita Williams Woolley, and Laura Dabbish. 2017. Deep structures of collaboration: Physiological correlates of collective intelligence and group satisfaction. InProceedings of the 2017 ACM conference on computer supported cooperative work and social computing. 873–888
2017
-
[28]
William G Cochran. 1946. Relative accuracy of systematic and stratified random samples for a certain class of populations.The Annals of Mathematical Statistics17, 2 (1946), 164–177
1946
-
[29]
Valerio Cosentino, Javier Luis, and Jordi Cabot. 2016. Findings from GitHub: methods, datasets and limitations. In Proceedings of the 13th International Conference on Mining Software Repositories. 137–141
2016
-
[30]
Laura Dabbish, Colleen Stuart, Jason Tsay, and Jim Herbsleb. 2012. Social coding in GitHub: transparency and collaboration in an open software repository. InProceedings of the ACM 2012 conference on computer supported cooperative work. 1277–1286
2012
-
[31]
Ozren Dabic, Emad Aghajani, and Gabriele Bavota. 2021. Sampling projects in github for MSR studies. In2021 IEEE/ACM 18th International Conference on Mining Software Repositories (MSR). IEEE, 560–564
2021
-
[32]
Pasquale De Meo, Emilio Ferrara, Giacomo Fiumara, and Alessandro Provetti. 2011. Generalized louvain method for community detection in large networks. In2011 11th international conference on intelligent systems design and applications. IEEE, 88–93
2011
-
[33]
2025.DeepSeek-R1 Release
Deepseek. 2025.DeepSeek-R1 Release. Retrieved April 1, 2025 from https://api-docs.deepseek.com/news/news250120
2025
-
[34]
Luis Felipe Dias, Igor Steinmacher, and Gustavo Pinto. 2018. Who drives company-owned OSS projects: internal or external members?Journal of the Brazilian Computer Society24, 1 (2018), 16
2018
-
[35]
O’Reilly Media, Inc
Chris DiBona and Sam Ockman. 1999.Open sources: Voices from the open source revolution. " O’Reilly Media, Inc. "
1999
-
[36]
Jakob Eder. 2019. Innovation in the periphery: A critical survey and research agenda.International Regional Science Review42, 2 (2019), 119–146
2019
-
[37]
2025.Hugging Face Hub
Hugging Face. 2025.Hugging Face Hub. Retrieved April 1, 2025 from https://huggingface.co/models
2025
- [38]
-
[39]
Brian Fitzgerald. 2006. The transformation of open source software.MIS quarterly(2006), 587–598
2006
-
[40]
translation
Joan H Fujimura. 1992. Crafting science: Standardized packages, boundary objects, and “translation. ”.Science as practice and culture168, 1992 (1992), 168–69
1992
-
[41]
R Stuart Geiger, Nelle Varoquaux, Charlotte Mazel-Cabasse, and Chris Holdgraf. 2018. The types, roles, and practices of documentation in data analytics open source software libraries: a collaborative ethnography of documentation work.Computer Supported Cooperative Work (CSCW)27, 3 (2018), 767–802
2018
-
[42]
Fabrizio Gilardi, Meysam Alizadeh, and Maël Kubli. 2023. ChatGPT outperforms crowd workers for text-annotation tasks.Proceedings of the National Academy of Sciences120, 30 (2023), e2305016120
2023
-
[43]
2022.REST API
GitHub. 2022.REST API. Retrieved April 1, 2025 from https://docs.github.com/en/rest
2022
-
[44]
2025.About GitHub
Github. 2025.About GitHub. Retrieved April 1, 2025 from https://github.com/about
2025
-
[45]
Mehdi Golzadeh, Alexandre Decan, and Tom Mens. 2022. On the rise and fall of CI services in GitHub. In2022 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 662–672
2022
-
[46]
Georgios Gousios and Diomidis Spinellis. 2017. Mining software engineering data from GitHub. In2017 IEEE/ACM 39th International Conference on Software Engineering Companion (ICSE-C). IEEE, 501–502
2017
-
[47]
Can I modify the code of an open source project?
Gilles Gravier. 2019.Working with an open source project (aka “Can I modify the code of an open source project?”). Retrieved April 1, 2025 from https://www.finos.org/blog/working-with-an-open-source-project-aka-can-i-modify- the-code-of-an-open-source-project From OSS to Open Source AI: an Exploratory Study of Collaborative Development Paradigm Divergence 27
2019
-
[48]
Greg Guest, Arwen Bunce, and Laura Johnson. 2006. How many interviews are enough? An experiment with data saturation and variability.Field methods18, 1 (2006), 59–82
2006
-
[49]
Carl Gutwin, Steve Benford, Jeff Dyck, Mike Fraser, Ivan Vaghi, and Chris Greenhalgh. 2004. Revealing delay in collaborative environments. InProceedings of the SIGCHI conference on human factors in computing systems. 503–510
2004
-
[50]
Anja Guzzi, Alberto Bacchelli, Michele Lanza, Martin Pinzger, and Arie Van Deursen. 2013. Communication in open source software development mailing lists. In2013 10th Working Conference on Mining Software Repositories (MSR). IEEE, 277–286
2013
-
[51]
Hideaki Hata, Nicole Novielli, Sebastian Baltes, Raula Gaikovina Kula, and Christoph Treude. 2022. GitHub Discussions: An exploratory study of early adoption.Empirical Software Engineering27 (2022), 1–32
2022
-
[52]
Herbsleb and Audris Mockus
James D. Herbsleb and Audris Mockus. 2003. An empirical study of speed and communication in globally distributed software development.IEEE Transactions on software engineering29, 6 (2003), 481–494
2003
-
[53]
James D Herbsleb, Audris Mockus, Thomas A Finholt, and Rebecca E Grinter. 2000. Distance, dependencies, and delay in a global collaboration. InProceedings of the 2000 ACM conference on Computer supported cooperative work. 319–328
2000
-
[54]
Michael Heron, Vicki L Hanson, and Ian Ricketts. 2013. Open source and accessibility: advantages and limitations. Journal of interaction Science1 (2013), 1–10
2013
-
[55]
private-collective
Eric von Hippel and Georg von Krogh. 2003. Open source software and the “private-collective” innovation model: Issues for organization science.Organization science14, 2 (2003), 209–223
2003
-
[56]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al
-
[57]
Lora: Low-rank adaptation of large language models.ICLR1, 2 (2022), 3
2022
-
[58]
2025.Why it’s important for AI companies to open source their models
Yaron Inger. 2025.Why it’s important for AI companies to open source their models. Retrieved April 1, 2025 from https: //www.techzine.eu/experts/analytics/127851/why-its-important-for-ai-companies-to-open-source-their-models/
2025
-
[59]
Carina Jacobi, Wouter Van Atteveldt, and Kasper Welbers. 2018. Quantitative analysis of large amounts of journalistic texts using topic modelling. InRethinking research methods in an age of digital journalism. Routledge, 89–106
2018
-
[60]
Oskar Jarczyk, Błażej Gruszka, Szymon Jaroszewicz, Leszek Bukowski, and Adam Wierzbicki. 2014. Github projects. quality analysis of open-source software. InSocial Informatics: 6th International Conference, SocInfo 2014, Barcelona, Spain, November 11-13, 2014. Proceedings 6. Springer, 80–94
2014
-
[61]
Wenxin Jiang, Nicholas Synovic, Matt Hyatt, Taylor R Schorlemmer, Rohan Sethi, Yung-Hsiang Lu, George K Thiruvathukal, and James C Davis. 2023. An empirical study of pre-trained model reuse in the hugging face deep learning model registry. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 2463–2475
2023
-
[62]
Wenxin Jiang, Nicholas Synovic, Purvish Jajal, Taylor R Schorlemmer, Arav Tewari, Bhavesh Pareek, George K Thiruvathukal, and James C Davis. 2023. Ptmtorrent: A dataset for mining open-source pre-trained model packages. In2023 IEEE/ACM 20th International Conference on Mining Software Repositories (MSR). IEEE, 57–61
2023
-
[63]
Wenxin Jiang, Jerin Yasmin, Jason Jones, Nicholas Synovic, Jiashen Kuo, Nathaniel Bielanski, Yuan Tian, George K Thiruvathukal, and James C Davis. 2024. Peatmoss: A dataset and initial analysis of pre-trained models in open-source software. InProceedings of the 21st International Conference on Mining Software Repositories. 431–443
2024
-
[64]
Jason Jones, Wenxin Jiang, Nicholas Synovic, George Thiruvathukal, and James Davis. 2024. What do we know about Hugging Face? A systematic literature review and quantitative validation of qualitative claims. InProceedings of the 18th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement. 13–24
2024
-
[65]
Takeshi Kakimoto, Yasutaka Kamei, Masao Ohira, and Kenichi Matsumoto. 2006. Social network analysis on communications for knowledge collaboration in oss communities. InProceedings of the international workshop on supporting knowledge collaboration in software development (KCSD’06). Citeseer, 35–41
2006
-
[66]
Hanna Kallio, Anna-Maija Pietilä, Martin Johnson, and Mari Kangasniemi. 2016. Systematic methodological review: developing a framework for a qualitative semi-structured interview guide.Journal of advanced nursing72, 12 (2016), 2954–2965
2016
-
[67]
Timothy Kinsman, Mairieli Wessel, Marco A Gerosa, and Christoph Treude. 2021. How do software developers use github actions to automate their workflows?. In2021 IEEE/ACM 18th International Conference on Mining Software Repositories (MSR). IEEE, 420–431
2021
-
[68]
Chinmay Kulkarni, Tongshuang Wu, Kenneth Holstein, Q Vera Liao, Min Kyung Lee, Mina Lee, and Hariharan Subramonyam. 2023. LLMs and the Infrastructure of CSCW. InCompanion publication of the 2023 conference on computer supported cooperative work and social computing. 408–410
2023
-
[69]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles. 611–626
2023
-
[70]
Max Langenkamp and Daniel N Yue. 2022. How open source machine learning software shapes ai. InProceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society. 385–395. 28 Ye et al
2022
-
[71]
Jan Marco Leimeister. 2010. Collective intelligence.Business & Information Systems Engineering2, 4 (2010), 245–248
2010
-
[72]
Yueyue Liu, Hongyu Zhang, Zhiqiang Li, and Yuantian Miao. 2024. Optimizing the Utilization of Large Language Models via Schedule Optimization: An Exploratory Study. InProceedings of the 18th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement. 84–95
2024
-
[73]
Yezhou Ma, Huiying Li, Jiyao Hu, Rong Xie, and Yang Chen. 2017. Mining the network of the programmers: a data-driven analysis of GitHub. InProceedings of the 12th Chinese Conference on Computer Supported Cooperative Work and Social Computing. 165–168
2017
-
[74]
Nora McDonald and Sean Goggins. 2013. Performance and participation in open source software on github. InCHI’13 extended abstracts on human factors in computing systems. 139–144
2013
-
[75]
Patrick E McKnight and Julius Najab. 2010. Mann-Whitney U Test.The Corsini encyclopedia of psychology(2010), 1–1
2010
-
[76]
2023.Meta and Microsoft introduce the next generation of Llama
Meta. 2023.Meta and Microsoft introduce the next generation of Llama. Retrieved April 1, 2025 from https://about.fb. com/news/2023/07/llama-2
2023
-
[77]
Audris Mockus, Roy T Fielding, and James D Herbsleb. 2002. Two case studies of open source software development: Apache and Mozilla.ACM Transactions on Software Engineering and Methodology (TOSEM)11, 3 (2002), 309–346
2002
-
[78]
Behnaz Moradi-Jamei, Brandon L Kramer, J Bayoán Santiago Calderón, and Gizem Korkmaz. 2021. Community formation and detection on GitHub collaboration networks. InProceedings of the 2021 IEEE/ACM international conference on advances in social networks analysis and mining. 244–251
2021
-
[79]
Baruch Nevo. 1985. Face validity revisited.Journal of educational measurement22, 4 (1985), 287–293
1985
-
[80]
Tim O’Reilly. 1999. Lessons from open-source software development.Commun. ACM42, 4 (1999), 32–37
1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.