Recognition: 2 theorem links
· Lean TheoremStaRPO: Stability-Augmented Reinforcement Policy Optimization
Pith reviewed 2026-05-10 18:07 UTC · model grok-4.3
The pith
StaRPO augments RL rewards for LLMs with autocorrelation and path efficiency to improve both accuracy and logical stability in reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
StaRPO decomposes reasoning stability into the autocorrelation function for measuring local step-to-step coherence and path efficiency for measuring global goal-directedness of the trajectory. These metrics are combined with standard task rewards to supply complementary process-aware signals during policy optimization, resulting in models that reduce logic errors while raising final-answer accuracy on reasoning benchmarks.
What carries the argument
The stability-augmented reward that integrates the autocorrelation function for local coherence and path efficiency for global directedness with task rewards during reinforcement policy optimization.
If this is right
- The combined reward produces higher final-answer accuracy together with fewer logical inconsistencies on four reasoning benchmarks.
- ACF and PE rewards correlate with logic errors across two different backbone models, confirming their utility as stability signals.
- The framework delivers consistent gains over baselines that use only final-answer feedback.
- Logical stability improves without requiring new model architectures or extensive additional tuning.
Where Pith is reading between the lines
- The same lightweight stability proxies might transfer to other sequential generation tasks such as planning or code synthesis.
- The approach could be combined with existing process-supervision methods to produce even stronger consistency gains.
- If the correlation between these metrics and errors generalizes, it suggests a broader class of cheap trajectory-quality signals for RL in language models.
Load-bearing premise
The assumption that the autocorrelation function and path efficiency serve as valid lightweight proxies for logical stability whose addition to the reward will reduce inconsistencies without creating new failure modes or demanding extensive hyperparameter tuning.
What would settle it
A new set of experiments on the same benchmarks where the ACF and PE rewards show no measurable correlation with logic errors or fail to improve logical stability metrics beyond standard RL baselines.
Figures



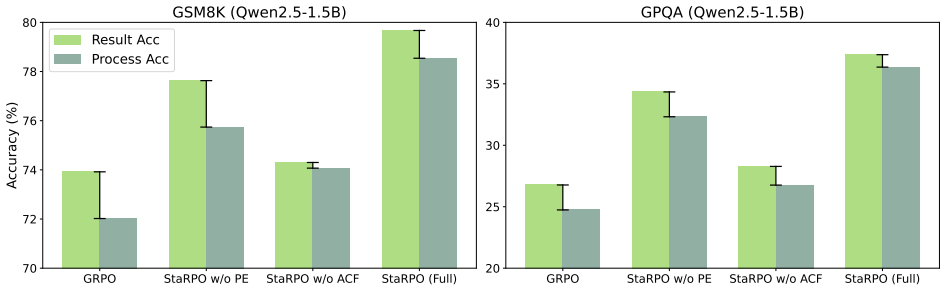
read the original abstract
Reinforcement learning (RL) is effective in enhancing the accuracy of large language models in complex reasoning tasks. Existing RL policy optimization frameworks rely on final-answer correctness as feedback signals and rarely capture the internal logical structure of the reasoning process. Consequently, the models would generate fluent and semantically relevant responses but logically inconsistent, structurally erratic, or redundant. To this end, we propose StaRPO, a stability-augmented reinforcement learning framework that explicitly incorporates reasoning stability into the optimization objective. Our StaRPO decomposes stability into two computable lightweight metrics: the Autocorrelation Function (ACF) to evaluate local step-to-step coherence, and Path Efficiency (PE) to evaluate global goal-directedness of the reasoning trajectory. These stability rewards are combined with task rewards to provide complementary and process-aware feedback. We validate the effectiveness of using ACF and PE rewards by showing their correlation with logic errors on two backbone models. Experiments on four reasoning benchmarks show that StaRPO consistently outperforms compared baselines and can enhance both final-answer accuracy and logical stability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes StaRPO, a stability-augmented RL policy optimization framework for LLMs on reasoning tasks. It decomposes reasoning stability into two lightweight metrics—Autocorrelation Function (ACF) for local step-to-step coherence and Path Efficiency (PE) for global goal-directedness—combines them with task rewards, validates the metrics via correlation with logic errors on two backbone models, and reports consistent outperformance over baselines on four reasoning benchmarks for both final-answer accuracy and logical stability.
Significance. If the central results hold, StaRPO would offer a practical, low-overhead extension to existing RL methods for reasoning that directly targets process-level consistency rather than final-answer correctness alone. This could meaningfully reduce logically inconsistent or redundant outputs in deployed LLM reasoners, with the metrics' claimed lightness making them attractive for scaling.
major comments (3)
- [Abstract] Abstract: The validation of ACF and PE rests solely on reported correlation with logic errors on two backbones, yet no coefficients, p-values, annotation protocol for logic errors, or controls for confounding factors (e.g., length, fluency) are supplied. Without these, the claim that the metrics are reliable proxies for stability cannot be evaluated, and the subsequent assertion that their inclusion in the RL objective will improve both accuracy and stability lacks direct support.
- [Experiments] Experiments section (and §4): No details are given on the exact reward combination formula (weights between ACF, PE, and task reward, normalization, or clipping), the precise definition of reasoning steps or trajectories over which ACF/PE are computed, statistical significance tests for benchmark gains, or full baseline implementations (including whether baselines also received process rewards). These omissions make it impossible to verify that the reported outperformance is attributable to the stability augmentation rather than implementation differences or hyperparameter tuning.
- [Abstract] Abstract and §3: The paper does not address whether maximizing ACF and PE can be achieved by superficially coherent but still erroneous trajectories (reward hacking) or whether the combined objective introduces trade-offs with final-answer accuracy. Correlation with errors on fixed models does not establish that gradient updates on the augmented reward will reduce those errors without new failure modes across scales or tasks.
minor comments (3)
- [§3] Clarify whether ACF is computed on token embeddings, hidden states, or discrete step representations, and provide the exact lag range used.
- [Experiments] Add a table or figure showing per-benchmark accuracy and stability deltas with error bars or multiple seeds to support the 'consistently outperforms' claim.
- [Introduction] Include a brief related-work paragraph contrasting StaRPO with prior process-reward or self-consistency methods.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive feedback on our manuscript. We appreciate the opportunity to clarify key aspects of StaRPO and strengthen the presentation of our results. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The validation of ACF and PE rests solely on reported correlation with logic errors on two backbones, yet no coefficients, p-values, annotation protocol for logic errors, or controls for confounding factors (e.g., length, fluency) are supplied. Without these, the claim that the metrics are reliable proxies for stability cannot be evaluated, and the subsequent assertion that their inclusion in the RL objective will improve both accuracy and stability lacks direct support.
Authors: We agree that the validation section requires more rigorous statistical reporting to support ACF and PE as reliable proxies. The manuscript currently describes the correlation with logic errors but omits coefficients, p-values, the annotation protocol, and controls for confounders. In the revised version, we will add these details (including controls for length and fluency) to the abstract and relevant sections, providing stronger empirical grounding for the metrics' utility in the RL objective. revision: yes
-
Referee: [Experiments] Experiments section (and §4): No details are given on the exact reward combination formula (weights between ACF, PE, and task reward, normalization, or clipping), the precise definition of reasoning steps or trajectories over which ACF/PE are computed, statistical significance tests for benchmark gains, or full baseline implementations (including whether baselines also received process rewards). These omissions make it impossible to verify that the reported outperformance is attributable to the stability augmentation rather than implementation differences or hyperparameter tuning.
Authors: We acknowledge that the current experiments section lacks the necessary implementation details for full reproducibility and attribution of gains. We will expand the Experiments section and §4 to specify the exact reward combination formula (including weights, normalization, and clipping), precise definitions of reasoning steps and trajectories for ACF/PE, statistical significance tests for benchmark results, and complete baseline implementation details (clarifying process reward usage). These additions will enable verification that improvements arise from the stability augmentation. revision: yes
-
Referee: [Abstract] Abstract and §3: The paper does not address whether maximizing ACF and PE can be achieved by superficially coherent but still erroneous trajectories (reward hacking) or whether the combined objective introduces trade-offs with final-answer accuracy. Correlation with errors on fixed models does not establish that gradient updates on the augmented reward will reduce those errors without new failure modes across scales or tasks.
Authors: We recognize this as a substantive limitation in the current analysis. While we demonstrate correlation on fixed models, the manuscript does not explicitly discuss reward hacking risks or accuracy trade-offs under optimization. In the revision, we will add a discussion in §3 addressing these concerns, including any observed trade-offs from our experiments and notes on potential new failure modes. We will also highlight this as a limitation and outline directions for future validation across scales. revision: partial
Circularity Check
No significant circularity; metrics and claims remain independent of fitted inputs or self-citations
full rationale
The paper defines ACF (local step-to-step coherence) and PE (global goal-directedness) as standalone computable metrics, then reports their empirical correlation with logic errors on two backbone models as validation. This correlation is an external measurement, not a definitional reduction or fitted parameter renamed as prediction. The StaRPO objective simply adds these process rewards to task rewards without any equation or claim reducing by construction to the target accuracy or stability outcomes. No self-citation chains, uniqueness theorems, or ansatzes imported from prior author work are invoked as load-bearing steps. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ACF and PE are computable lightweight metrics that evaluate reasoning stability and correlate with logic errors
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We quantify reasoning stability by decomposing it into two measurable metrics... Autocorrelation Function (ACF) ... Path Efficiency (PE) ... rStaRPO(x, yi) = r(x, yi) + λ_acf · r_acf + λ_pe · r_pe
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments on four reasoning benchmarks show that StaRPO consistently outperforms compared baselines
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Learning to Route Queries to Heads for Attention-based Re-ranking with Large Language Models
RouteHead trains a lightweight router to dynamically select optimal LLM attention heads per query for improved attention-based document re-ranking.
-
CroSearch-R1: Better Leveraging Cross-lingual Knowledge for Retrieval-Augmented Generation
CroSearch-R1 applies search-augmented RL with cross-lingual integration and multilingual rollouts to improve RAG effectiveness on multilingual collections.
Reference graph
Works this paper leans on
-
[1]
Semantic coherence dynamics in large language models through layered syntax-aware memory retention mechanism.Authroea: New York, NY, USA,
[Andersonet al., 2024 ] Carl Anderson, Benjamin Vanden- berg, Christopher Hauser, Alexander Johansson, and Nathaniel Galloway. Semantic coherence dynamics in large language models through layered syntax-aware memory retention mechanism.Authroea: New York, NY, USA,
2024
-
[2]
Thinking machines: A survey of llm based reasoning strategies
[Bandyopadhyayet al., 2025 ] Dibyanayan Bandyopadhyay, Soham Bhattacharjee, and Asif Ekbal. Thinking ma- chines: A survey of llm based reasoning strategies. arXiv:2503.10814,
-
[3]
[Chenet al., 2025a ] Jianghao Chen, Wei Sun, Qixiang Yin, Lingxing Kong, Zhixing Tan, and Jiajun Zhang. Ace-rl: Adaptive constraint-enhanced reward for long-form gen- eration reinforcement learning.arXiv:2509.04903,
-
[4]
Exploration vs exploitation: Rethinking RLVR through clipping, entropy, and spurious reward
[Chenet al., 2025b ] Peter Chen, Xiaopeng Li, Ziniu Li, Wotao Yin, Xi Chen, and Tianyi Lin. Exploration vs ex- ploitation: Rethinking rlvr through clipping, entropy, and spurious reward.arXiv:2512.16912,
-
[5]
Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning Large Language Models
[Chenet al., 2025c ] Qiguang Chen, Libo Qin, Jinhao Liu, Dengyun Peng, Jiannan Guan, Peng Wang, Mengkang Hu, Yuhang Zhou, Te Gao, and Wanxiang Che. Towards rea- soning era: A survey of long chain-of-thought for reason- ing large language models.arXiv:2503.09567,
work page internal anchor Pith review arXiv
-
[6]
[Choet al., 2025 ] Dongkyu Derek Cho, Huan Song, Ari- jit Ghosh Chowdhury, Haotian An, Yawei Wang, Rohit Thekkanal, Negin Sokhandan, Sharlina Keshava, and Han- nah Marlowe. Breaking the safety-capability tradeoff: Reinforcement learning with verifiable rewards maintains safety guardrails in llms.arXiv:2511.21050,
-
[7]
Training Verifiers to Solve Math Word Problems
[Cobbeet al., 2021 ] Karl Cobbe, Vineet Kosaraju, Moham- mad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word prob- lems.arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Using word embedding to evaluate the coherence of topics from twitter data
[Fanget al., 2016 ] Anjie Fang, Craig Macdonald, Iadh Ou- nis, and Philip Habel. Using word embedding to evaluate the coherence of topics from twitter data. InSIGIR,
2016
-
[9]
Group-in-Group Policy Optimization for LLM Agent Training
[Fenget al., 2025 ] Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for llm agent training.arXiv:2505.10978,
work page internal anchor Pith review arXiv 2025
-
[10]
The endorsement of the premises: Assumption-based or belief-based reasoning
[George, 1995] Christian George. The endorsement of the premises: Assumption-based or belief-based reasoning. British Journal of Psychology, 86(1):93–111,
1995
-
[11]
Wadsworth Belmont, CA,
[Govier and others, 2010] Trudy Govier et al.A practical study of argument. Wadsworth Belmont, CA,
2010
-
[12]
A survey on llm- as-a-judge.The Innovation,
[Guet al., 2024 ] Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hex- iang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, et al. A survey on llm- as-a-judge.The Innovation,
2024
-
[13]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
[Guoet al., 2025 ] Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shi- rong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Measuring Mathematical Problem Solving With the MATH Dataset
[Hendryckset al., 2021 ] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv:2103.03874,
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[15]
A review of stability in topic modeling: Metrics for assessing and techniques for improving stability
[Hosseiny Marani and Baumer, 2023] Amin Hos- seiny Marani and Eric PS Baumer. A review of stability in topic modeling: Metrics for assessing and techniques for improving stability
2023
-
[16]
Line: Logical query reasoning over hi- erarchical knowledge graphs
[Huanget al., 2022 ] Zijian Huang, Meng-Fen Chiang, and Wang-Chien Lee. Line: Logical query reasoning over hi- erarchical knowledge graphs. InSIGKDD,
2022
-
[17]
[Linet al., 2025 ] Zhihang Lin, Mingbao Lin, Yuan Xie, and Rongrong Ji. Cppo: Accelerating the training of group relative policy optimization-based reasoning mod- els.arXiv:2503.22342,
-
[18]
[Liuet al., 2024 ] Aixin Liu, Bei Feng, Bing Xue, Bingx- uan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
[Liuet al., 2025a ] Keliang Liu, Dingkang Yang, Ziyun Qian, Weijie Yin, Yuchi Wang, Hongsheng Li, Jun Liu, Peng Zhai, Yang Liu, and Lihua Zhang. Reinforcement learn- ing meets large language models: A survey of ad- vancements and applications across the llm lifecycle. arXiv:2509.16679,
-
[20]
Logic embeddings for com- plex query answering.arXiv:2103.00418,
[Luuset al., 2021 ] Francois Luus, Prithviraj Sen, Pavan Ka- panipathi, Ryan Riegel, Ndivhuwo Makondo, Thabang Lebese, and Alexander Gray. Logic embeddings for com- plex query answering.arXiv:2103.00418,
-
[21]
[Math-AI, 2024] Math-AI. Aime
2024
-
[22]
Accessed: 2025-10-06. [Moet al., 2026 ] Fengran Mo, Zhan Su, Yuchen Hui, Jing- han Zhang, Jia Ao Sun, Zheyuan Liu, Chao Zhang, Tet- suya Sakai, and Jian-Yun Nie. Opendecoder: Open large language model decoding to incorporate document quality in rag.arXiv preprint arXiv:2601.09028,
-
[23]
Represen- tation learning in complex logical query answering on knowledge graphs: A survey.ACM Computing Surveys
[Nguyenet al., ] Chau DM Nguyen, Tim French, Michael Stewart, Melinda Hodkiewicz, and Wei Liu. Represen- tation learning in complex logical query answering on knowledge graphs: A survey.ACM Computing Surveys. [OpenAI, 2024] OpenAI. GPT-4o-mini: Advancing Cost- Efficient Intelligence,
2024
-
[24]
[Patilet al., 2023 ] Rajvardhan Patil, Sorio Boit, Venkat Gu- divada, and Jagadeesh Nandigam
Accessed: 2024-10-05. [Patilet al., 2023 ] Rajvardhan Patil, Sorio Boit, Venkat Gu- divada, and Jagadeesh Nandigam. A survey of text repre- sentation and embedding techniques in nlp.IEEe Access, 11:36120–36146,
2024
-
[25]
From reasoning to code: Grpo optimization for underrepresented languages.arXiv:2506.11027,
[Penninoet al., 2025 ] Federico Pennino, Bianca Raimondi, Massimo Rondelli, Andrea Gurioli, and Maurizio Gab- brielli. From reasoning to code: Grpo optimization for underrepresented languages.arXiv:2506.11027,
-
[26]
Gpqa: A graduate-level google-proof q&a benchmark
[Reinet al., 2024 ] David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling,
2024
-
[27]
Proximal Policy Optimization Algorithms
[Schulmanet al., 2017 ] John Schulman, Filip Wolski, Pra- fulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
[Shaoet al., 2024 ] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open lan- guage models.arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Llm-planner: Few-shot grounded planning for embodied agents with large language models
[Songet al., 2023 ] Chan Hee Song, Jiaman Wu, Clayton Washington, Brian M Sadler, Wei-Lun Chao, and Yu Su. Llm-planner: Few-shot grounded planning for embodied agents with large language models. InICCV,
2023
-
[30]
A survey of reasoning with foundation models: Concepts, methodologies, and outlook.ACM Computing Surveys,
[Sunet al., 2023 ] Jiankai Sun, Chuanyang Zheng, Enze Xie, Zhengying Liu, Ruihang Chu, Jianing Qiu, Jiaqi Xu, Mingyu Ding, Hongyang Li, Mengzhe Geng, et al. A survey of reasoning with foundation models: Concepts, methodologies, and outlook.ACM Computing Surveys,
2023
-
[31]
Neural multi-hop logical query answering with concept-level answers
[Tanget al., 2023 ] Zhenwei Tang, Shichao Pei, Xi Peng, Fuzhen Zhuang, Xiangliang Zhang, and Robert Hoehn- dorf. Neural multi-hop logical query answering with concept-level answers. InInternational Semantic Web Conference,
2023
-
[32]
[Team, 2024] Qwen Team. Qwen2 technical report. arXiv:2407.10671, 2,
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [33]
-
[34]
Ctrls: Chain-of-thought rea- soning via latent state-transition.arXiv:2507.08182,
[Wuet al., 2025a ] Junda Wu, Yuxin Xiong, Xintong Li, Zhengmian Hu, Tong Yu, Rui Wang, Xiang Chen, Jingbo Shang, and Julian McAuley. Ctrls: Chain-of-thought rea- soning via latent state-transition.arXiv:2507.08182,
-
[35]
[Wuet al., 2025b ] Xingyu Wu, Yuchen Yan, Shangke Lyu, Linjuan Wu, Yiwen Qiu, Yongliang Shen, Weiming Lu, Jian Shao, Jun Xiao, and Yueting Zhuang. Lapo: Internal- izing reasoning efficiency via length-adaptive policy opti- mization.arXiv:2507.15758,
-
[36]
Enhancing semantic consistency of large language models through model editing: An interpretability-oriented approach
[Yanget al., 2024 ] Jingyuan Yang, Dapeng Chen, Yajing Sun, Rongjun Li, Zhiyong Feng, and Wei Peng. Enhancing semantic consistency of large language models through model editing: An interpretability-oriented approach. In Findings of the Association for Computational Linguistics: ACL 2024, pages 3343–3353,
2024
-
[37]
Tree of thoughts: Deliberate problem solving with large language models
[Yaoet al., 2023 ] Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. InNeurips,
2023
-
[38]
Rlpr: Extrapolating rlvr to general domains without verifiers, 2025
[Yuet al., 2025 ] Tianyu Yu, Bo Ji, Shouli Wang, Shu Yao, Zefan Wang, Ganqu Cui, Lifan Yuan, Ning Ding, Yuan Yao, Zhiyuan Liu, et al. Rlpr: Extrapolating rlvr to general domains without verifiers.arXiv:2506.18254,
-
[39]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
[Yueet al., 2025 ] Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capac- ity in llms beyond the base model?arXiv:2504.13837,
work page internal anchor Pith review arXiv 2025
-
[40]
[Zhanget al., 2024 ] Yadong Zhang, Shaoguang Mao, Tao Ge, Xun Wang, Adrian de Wynter, Yan Xia, Wenshan Wu, Ting Song, Man Lan, and Furu Wei. Llm as a mastermind: A survey of strategic reasoning with large language mod- els.arXiv:2404.01230,
-
[41]
[Zhanget al., 2025a ] Charlie Zhang, Graham Neubig, and Xiang Yue. On the interplay of pre-training, mid-training, and rl on reasoning language models.arXiv:2512.07783,
-
[42]
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
[Zhanget al., 2025b ] Guibin Zhang, Hejia Geng, Xiaohang Yu, Zhenfei Yin, Zaibin Zhang, Zelin Tan, Heng Zhou, Zhongzhi Li, Xiangyuan Xue, Yijiang Li, et al. The land- scape of agentic reinforcement learning for llms: A survey. arXiv:2509.02547,
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
12 Why are Entropy Dynamics and Reasoning Correlated in LLMs? A
[Zhanget al., 2025c ] Jinghan Zhang, Xiting Wang, Fen- gran Mo, Yeyang Zhou, Wanfu Gao, and Kunpeng Liu. Entropy-based exploration conduction for multi-step rea- soning.arXiv:2503.15848,
-
[44]
A survey of reinforcement learning for large reasoning models.arXiv preprint arXiv:2509.08827,
[Zhanget al., 2025e ] Kaiyan Zhang, Yuxin Zuo, Bingxi- ang He, Youbang Sun, Runze Liu, Che Jiang, Yuchen Fan, Kai Tian, Guoli Jia, Pengfei Li, et al. A sur- vey of reinforcement learning for large reasoning models. arXiv:2509.08827,
-
[45]
[Zhanget al., 2025f ] Xingjian Zhang, Siwei Wen, Wenjun Wu, and Lei Huang. Edge-grpo: Entropy-driven grpo with guided error correction for advantage diversity. arXiv:2507.21848,
-
[46]
[Zhanget al., 2025g ] Yi-Fan Zhang, Xingyu Lu, Xiao Hu, Chaoyou Fu, Bin Wen, Tianke Zhang, Changyi Liu, Kaiyu Jiang, Kaibing Chen, Kaiyu Tang, et al. R1-reward: Train- ing multimodal reward model through stable reinforce- ment learning.arXiv:2505.02835,
-
[47]
Blind spot navi- gation in large language model reasoning with thought space explorer
[Zhanget al., 2026 ] Jinghan Zhang, Fengran Mo, Tharindu Cyril Weerasooriya, Xinyue Ye, Dongjie Wang, Yanjie Fu, and Kunpeng Liu. Blind spot navi- gation in large language model reasoning with thought space explorer. In Vera Demberg, Kentaro Inui, and Lluís Marquez, editors,Findings of the Association for Computational Linguistics: EACL 2026, pages 3691– ...
2026
-
[48]
Group Sequence Policy Optimization
Association for Computational Linguistics. [Zhenget al., 2025 ] Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv:2507.18071, 2025
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.