Recognition: no theorem link
Connections Between Determinantal Point Processes and Gramians in Control
Pith reviewed 2026-05-10 17:51 UTC · model grok-4.3
The pith
Observability and controllability Gramians act as determinantal point processes when parameterized over sensor and actuator node subsets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By showing that the observability (controllability) Gramian parameterized by sensor (control) node subsets is a DPP, the work supplies a probabilistic and spectral perspective on sensor (actuator) selection for linear dynamic systems. The induced probability measure over configurations favors diverse selections, produces an effective observable rank condition, balances individual node contributions against collective diversity, and satisfies node-inclusion monotonicity together with negative dependence. The same formulation recovers classical greedy optimization bounds and admits a maximum-a-posteriori interpretation of the placement problem.
What carries the argument
The Gramian matrix parameterized by node subsets, serving as the kernel matrix that defines subset probabilities via its principal minors.
If this is right
- Sensor and actuator selection acquires an explicit probabilistic interpretation in which diverse configurations receive higher likelihood.
- The induced measure exhibits negative dependence, so adding one informative node lowers the marginal probability of redundant others.
- Node-inclusion monotonicity holds: enlarging a feasible set never decreases the probability of its subsets.
- Classical greedy algorithms for Gramian-based optimization are recovered as approximations to the maximum-a-posteriori solution.
- An effective rank condition on the Gramian replaces the classical full-rank observability test for subset selection.
Where Pith is reading between the lines
- DPP sampling algorithms could be imported directly to generate near-optimal sensor sets without exhaustive search.
- The same parameterization might apply to other quadratic forms arising in control, such as solutions of Lyapunov or Riccati equations.
- In large networks the spectral view could guide placement heuristics that explicitly penalize information overlap rather than just trace or determinant objectives.
Load-bearing premise
The Gramian submatrices, when indexed by every possible node subset, must induce a valid probability measure obeying the negative-dependence and diversity properties of a determinantal point process.
What would settle it
A concrete linear system and choice of nodes where the determinant-based probabilities either fail to sum to one across all subsets or assign higher likelihood to redundant rather than complementary selections.
Figures



read the original abstract
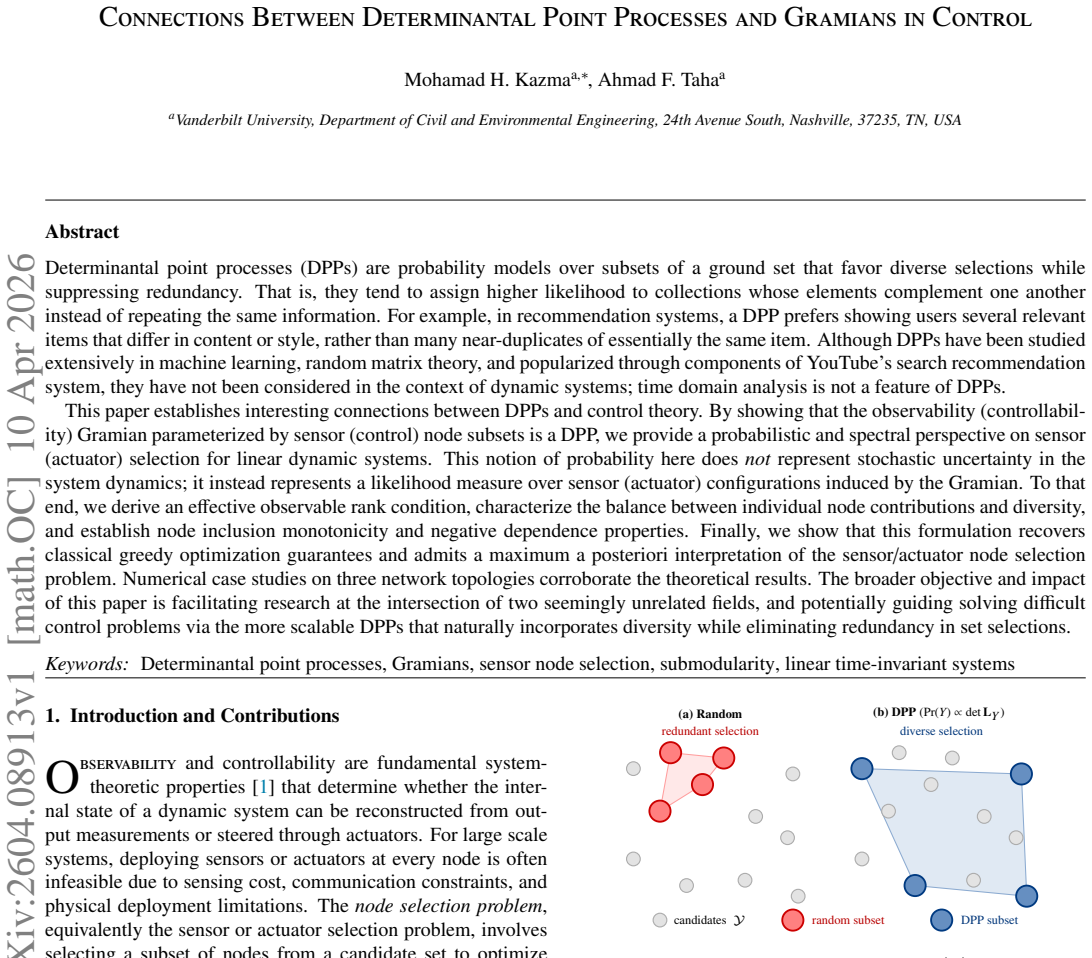
Determinantal point processes (DPPs) are probability models over subsets of a ground set that favor diverse selections while suppressing redundancy. That is, they tend to assign higher likelihood to collections whose elements complement one another instead of repeating the same information. For example, in recommendation systems, a DPP prefers showing users several relevant items that differ in content or style, rather than many near-duplicates of essentially the same item. Although DPPs have been studied extensively in machine learning, random matrix theory, and popularized through components of YouTube's search recommendation system, they have not been considered in the context of dynamic systems; time domain analysis is not a feature of DPPs. This paper establishes interesting connections between DPPs and control theory. By showing that the observability (controllability) Gramian parameterized by sensor (control) node subsets is a DPP, we provide a probabilistic and spectral perspective on sensor (actuator) selection for linear dynamic systems. This notion of probability here does not represent stochastic uncertainty in the system dynamics; it instead represents a likelihood measure over sensor (actuator) configurations induced by the Gramian. To that end, we derive an effective observable rank condition, characterize the balance between individual node contributions and diversity, and establish node inclusion monotonicity and negative dependence properties. Finally, we show that this formulation recovers classical greedy optimization guarantees and admits a maximum a posteriori interpretation of the sensor/actuator node selection problem. Numerical case studies on three network topologies corroborate the theoretical results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that parameterizing the observability (controllability) Gramian over subsets of sensor (actuator) nodes induces a determinantal point process (DPP). This supplies a probabilistic/spectral view of node selection in linear systems, from which the authors derive an effective rank condition, node-contribution/diversity balance, inclusion monotonicity, negative dependence, recovery of greedy submodular guarantees, and a MAP interpretation of the selection problem. The probability measure is defined via the Gramian determinant rather than stochastic dynamics.
Significance. A correct link between additive Gramian determinants and DPP kernels would give control theorists access to DPP tools for explaining diversity in sensor placement and for analyzing greedy algorithms. The manuscript supplies no machine-checked proofs, reproducible code, or parameter-free derivations that would strengthen the result if the identification held.
major comments (3)
- [Abstract] Abstract and central claim: the assertion that 'the observability (controllability) Gramian parameterized by sensor (control) node subsets is a DPP' does not hold. DPPs require a probability measure of the form P(S) ∝ det(K_S) for a single fixed kernel matrix K on the ground set. The paper instead uses det(W_S) where W_S = ∑_{i∈S} W_i and each W_i is a per-node positive-semidefinite Gramian. These two forms are not equivalent in general.
- [Abstract] Abstract / §3 (presumed derivation of the DPP property): the counter-example with a two-state system, A = 0, finite horizon T, W_1 = T·diag(1,0), W_2 = T·diag(0,1) yields det(W_{{1}}) = det(W_{{2}}) = 0 yet det(W_{{1,2}}) = T² > 0. No real matrix K satisfies K_{11} = K_{22} = 0 and det(K_{{1,2}}) = −K_{12}² = T². Hence the induced measure cannot be a DPP, and all subsequent appeals to DPP negative dependence or diversity properties rest on an invalid identification.
- [§4–5] §4–5 (monotonicity, negative dependence, greedy recovery): these properties are derived under the DPP label. Because the measure is not a DPP, the derivations must be re-checked directly from the additive Gramian structure; the manuscript provides no such independent verification.
minor comments (2)
- Clarify whether the authors intend a different kernel construction or a restricted class of Gramians (e.g., rank-1) under which det(W_S) coincides with a DPP.
- [Abstract] The abstract states that 'time domain analysis is not a feature of DPPs'; this observation is correct but should be expanded to explain why the finite-horizon Gramian still yields a valid probability measure.
Simulated Author's Rebuttal
We thank the referee for the thorough review and for pointing out the inaccuracy in our identification of the Gramian-based measure with a determinantal point process. We agree that this claim does not hold in general and will revise the manuscript to address this issue.
read point-by-point responses
-
Referee: [Abstract] Abstract and central claim: the assertion that 'the observability (controllability) Gramian parameterized by sensor (control) node subsets is a DPP' does not hold. DPPs require a probability measure of the form P(S) ∝ det(K_S) for a single fixed kernel matrix K on the ground set. The paper instead uses det(W_S) where W_S = ∑_{i∈S} W_i and each W_i is a per-node positive-semidefinite Gramian. These two forms are not equivalent in general.
Authors: We acknowledge that the referee is correct. The standard DPP definition relies on the determinant of a principal submatrix of a fixed kernel matrix K. Our construction uses the determinant of a sum of matrices, which is distinct. This was an error in the manuscript's central claim. We will revise the abstract and introduction to remove the assertion that the Gramian induces a DPP and instead present it as a determinantal measure arising from additive Gramians. revision: yes
-
Referee: [Abstract] Abstract / §3 (presumed derivation of the DPP property): the counter-example with a two-state system, A = 0, finite horizon T, W_1 = T·diag(1,0), W_2 = T·diag(0,1) yields det(W_{{1}}) = det(W_{{2}}) = 0 yet det(W_{{1,2}}) = T² > 0. No real matrix K satisfies K_{11} = K_{22} = 0 and det(K_{{1,2}}) = −K_{12}² = T². Hence the induced measure cannot be a DPP, and all subsequent appeals to DPP negative dependence or diversity properties rest on an invalid identification.
Authors: The provided counterexample is valid and illustrates the fundamental difference between the two constructions. No such kernel K exists for this case, confirming that the measure is not a DPP. We will incorporate this example into the revised manuscript to clarify the distinction and will not rely on DPP-specific properties without independent justification. revision: yes
-
Referee: [§4–5] §4–5 (monotonicity, negative dependence, greedy recovery): these properties are derived under the DPP label. Because the measure is not a DPP, the derivations must be re-checked directly from the additive Gramian structure; the manuscript provides no such independent verification.
Authors: We agree that the properties should be verified independently of the DPP label. Inclusion monotonicity follows directly from the fact that adding a positive semidefinite matrix cannot decrease the determinant. For negative dependence and the recovery of greedy guarantees, we will provide direct proofs based on the properties of the Gramian determinant in the revision. If some properties do not hold in the same form, we will note the differences. revision: yes
Circularity Check
No circularity: derivation presents Gramian parameterization as inducing DPP-like measure without definitional reduction or load-bearing self-citation
full rationale
The paper's central step defines a measure over sensor subsets via det(W_S) where W_S is the additive Gramian sum, then derives properties (negative dependence, monotonicity, greedy guarantees) directly from the Gramian structure and linear systems theory. This is not equivalent to its inputs by construction, nor does it rely on fitting parameters to the target or importing uniqueness via self-citation chains. External DPP literature is referenced for context but not used to justify the identification itself. The derivation chain remains self-contained against the stated assumptions on the Gramian.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The underlying system is linear time-invariant
- domain assumption The Gramian can be meaningfully parameterized by subsets of nodes
Reference graph
Works this paper leans on
-
[1]
R. E. Kalman, Mathematical Description of Linear Dynamical Systems, Journal of the Society for Industrial and Applied Mathematics Series A Control 1 (2) (1963) 152–192.doi:10.1137/0301010
- [2]
-
[3]
M. Shamaiah, S. Banerjee, H. Vikalo, Greedy sensor selection: Leverag- ing submodularity, Proceedings of the IEEE Conference on Decision and Control (2010) 2572–2577doi:10.1109/CDC.2010.5717225
-
[4]
T. H. Summers, F. L. Cortesi, J. Lygeros, On Submodularity and Control- lability in Complex Dynamical Networks, IEEE Transactions on Con- trol of Network Systems 3 (1) (2016) 91–101.arXiv:1404.7665, doi:10.1109/TCNS.2015.2453711
-
[5]
V . Tzoumas, A. Jadbabaie, G. J. Pappas, Near-optimal sensor scheduling for batch state estimation: Complexity, algorithms, and limits, 2016 IEEE 55th Conference on Decision and Control, CDC (2016) 2695–2702doi: 10.1109/CDC.2016.7798669
-
[6]
G. L. Nemhauser, L. A. Wolsey, M. L. Fisher, An analysis of approxima- tions for maximizing submodular set functions-I, Mathematical Program- ming 14 (1) (1978) 265–294.doi:10.1007/BF01588971
-
[7]
B. Guo, O. Karaca, T. Summers, M. Kamgarpour, Actuator Placement under Structural Controllability Using Forward and Reverse Greedy Al- gorithms, IEEE Transactions on Automatic Control 66 (12) (2021) 5845– 5860.arXiv:1912.05149,doi:10.1109/TAC.2020.3044284
-
[8]
A. Clark, L. Bushnell, R. Poovendran, A supermodular optimization framework for leader selection under link noise in linear multi-agent sys- tems, IEEE Transactions on Automatic Control 59 (2) (2014) 283–296. arXiv:1208.0946,doi:10.1109/TAC.2013.2281473
- [9]
-
[10]
F. Pasqualetti, S. Zampieri, F. Bullo, Controllability metrics, limitations and algorithms for complex networks, IEEE Transactions on Control of Network Systems 1 (1) (2014) 40–52.arXiv:1308.1201,doi: 10.1109/TCNS.2014.2310254
-
[11]
Y . Y . Liu, J. J. Slotine, A. L. Barabási, Controllability of com- plex networks, Nature 473 (7346) (2011) 167–173.doi:10.1038/ nature10011
2011
-
[12]
A. Kulesza, B. Taskar, Determinantal point processes for machine learn- ing, Foundations and Trends in Machine Learning 5 (2-3) (2012) 123– 286.arXiv:1207.6083,doi:10.1561/2200000044
-
[13]
Macchi, The coincidence approach to stochastic point processes, Ad- vances in Applied Probability 7 (1) (1975) 83–122.doi:10.2307/ 1425855
O. Macchi, The coincidence approach to stochastic point processes, Ad- vances in Applied Probability 7 (1) (1975) 83–122.doi:10.2307/ 1425855
1975
-
[14]
J. B. Hough, M. Krishnapur, Y . Peres, B. Virág, Determinantal processes and independence, Probability Surveys 3 (1) (2006) 206–229.doi:10. 1214/154957806000000078
2006
-
[15]
Tao, Topics in random matrix theory, V ol
T. Tao, Topics in random matrix theory, V ol. 132, American Mathematical Society, 2023
2023
-
[16]
Lyons, Determinantal probability measures, Publications mathéma- tiques de l’IHÉS 98 (1) (2003) 167–212.arXiv:0204325,doi:10
R. Lyons, Determinantal probability measures, Publications mathéma- tiques de l’IHÉS 98 (1) (2003) 167–212.arXiv:0204325,doi:10. 1007/s10240-003-0016-0
2003
-
[17]
A. Borodin, E. M. Rains, Eynard-Mehta theorem, Schur process, and their pfaffian analogs, Journal of Statistical Physics 121 (3-4) (2005) 291–317. arXiv:0409059,doi:10.1007/s10955-005-7583-z
-
[18]
Gillenwater, A
J. Gillenwater, A. Kulesza, Z. Mariet, S. Vassilvitskii, Maximizing in- duced cardinality under a determinantal point process, Advances in Neural Information Processing Systems 2018-Decem (NeurIPS) (2018) 6911–6920
2018
-
[19]
A. Kulesza, B. Taskar, Learning determinantal point processes, Proceed- ings of the 27th Conference on Uncertainty in Artificial Intelligence, UAI 2011 (2011) 419–427arXiv:1202.3738
-
[20]
M. Wilhelm, A. Ramanathan, A. Bonomo, S. Jain, E. H. Chi, J. Gillenwa- ter, Practical diversified recommendations on youtube with determinantal point processes, in: Proceedings of the 27th ACM International Confer- ence on Information and Knowledge Management, 2018, pp. 2165–2173. doi:10.1145/3269206.3272018
-
[21]
Zhang, W.-L
K. Zhang, W.-L. Chao, F. Sha, K. Grauman, Summary transfer: Exemplar-based subset selection for video summarization, in: Proceed- ings of the IEEE Conference on Computer Vision and Pattern Recogni- tion, 2016, pp. 1059–1067
2016
- [22]
-
[23]
S. Lall, J. E. Marsden, S. Glavaški, A subspace approach to balanced truncation for model reduction of nonlinear control systems, International Journal of Robust and Nonlinear Control 12 (6) (2002) 519–535.doi: 10.1002/rnc.657
-
[24]
M. H. Kazma, A. F. Taha, Partitioning and Observability in Linear Sys- tems via Submodular Optimization, IEEE Transactions on Automatic Control (i) (2026) 1–16.arXiv:2505.16169,doi:10.1109/TAC. 2026.3676329
work page doi:10.1109/tac 2026
-
[25]
Conforti, G
M. Conforti, G. Cornuéjols, Submodular set functions, matroids and the greedy algorithm: Tight worst-case bounds and some generalizations of the Rado-Edmonds theorem, Discrete Applied Mathematics 7 (3) (1984) 251–274
1984
-
[26]
In: 2025 IEEE 64th Conference on Decision and Control (CDC)
J. Vendrell, A. Kuhnle, S. Kia, ResQue Greedy: Rewiring Sequential Greedy for Improved Submodular Maximization, in: 2025 IEEE 64th Conference on Decision and Control (CDC), IEEE, 2025, pp. 6885–6890. arXiv:2505.13670,doi:10.1109/CDC57313.2025.11312997
-
[27]
Gillenwater, A
J. Gillenwater, A. Kulesza, B. Taskar, Near-optimal MAP inference for determinantal point processes, Advances in Neural Information Process- ing Systems 4 (2012) 2735–2743
2012
- [28]
-
[29]
D. J. Watts, S. H. Strogatz, Collectivedynamics of ‘small-world’ networks Duncan, Nature 393 (June) (1998) 440–442
1998
-
[30]
Erd ˝os, A
P. Erd ˝os, A. Rényi, On random graphs I, Publicationes Mathematicae De- brecen 6 (1959) 290–297
1959
-
[31]
A.-L. Barabási, R. Albert, Emergence of scaling in random networks, Sci- ence 286 (5439) (1999) 509–512.doi:10.1126/science.286.5439. 509. 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.