Recognition: unknown
MV3DIS: Multi-View Mask Matching via 3D Guides for Zero-Shot 3D Instance Segmentation
Pith reviewed 2026-05-10 17:39 UTC · model grok-4.3
The pith
MV3DIS uses coarse 3D segments as a shared reference to match 2D masks across views and refine them into consistent zero-shot 3D instances.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
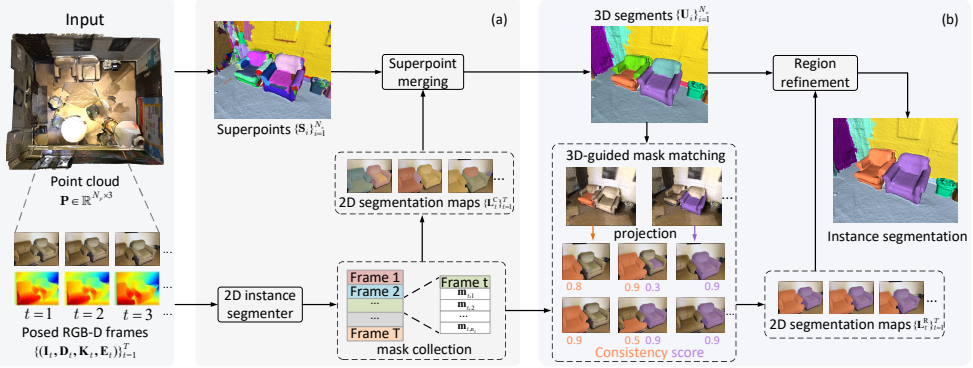
MV3DIS is a coarse-to-fine framework that first extracts coarse 3D segments from geometric primitives, then applies a 3D-guided mask matching procedure that uses these segments as a common reference to pair 2D masks across views while enforcing consistency via 3D coverage distributions; a depth consistency weighting scheme further quantifies projection reliability to mitigate occlusion ambiguities, after which the view-consistent 2D masks are used to refine the coarse segments into precise 3D instances.
What carries the argument
The 3D-guided mask matching strategy, which treats coarse 3D segments derived from geometric primitives as a common reference to align 2D masks from multiple views and consolidate their consistency through 3D coverage distributions.
If this is right
- Zero-shot 3D instance segmentation becomes possible without labor-intensive 3D annotations.
- Multi-view correlations are used explicitly rather than processing frames independently with only 2D scores.
- Inconsistent and fragmented 3D segmentations are reduced by enforcing view-consistent masks.
- Projection ambiguities from inter-object occlusions are suppressed by depth-based reliability weighting.
- Superior results are obtained on ScanNetV2, ScanNet200, ScanNet++, Replica, and Matterport3D.
Where Pith is reading between the lines
- The approach indicates that even approximate geometric primitives can bootstrap reliable fusion of 2D foundation-model outputs in 3D scenes.
- It could be tested on outdoor or dynamic scenes if multi-view video and coarse geometry are available.
- Integration with other 2D foundation models beyond SAM would be a direct next step to broaden object coverage.
- Efficiency measurements on streaming video would reveal whether the coarse-to-fine refinement supports real-time use.
Load-bearing premise
Coarse 3D segments produced by geometric primitives must be accurate enough to serve as a reliable common reference for matching 2D masks without carrying forward errors into the final instances.
What would settle it
Running the same pipeline on ScanNetV2 but replacing the 3D-guided matching step with independent per-view 2D processing and observing equal or higher instance segmentation accuracy would show that the 3D reference is not necessary.
Figures




read the original abstract
Conventional 3D instance segmentation methods rely on labor-intensive 3D annotations for supervised training, which limits their scalability and generalization to novel objects. Recent approaches leverage multi-view 2D masks from the Segment Anything Model (SAM) to guide the merging of 3D geometric primitives, thereby enabling zero-shot 3D instance segmentation. However, these methods typically process each frame independently and rely solely on 2D metrics, such as SAM prediction scores, to produce segmentation maps. This design overlooks multi-view correlations and inherent 3D priors, leading to inconsistent 2D masks across views and ultimately fragmented 3D segmentation. In this paper, we propose MV3DIS, a coarse-to-fine framework for zero-shot 3D instance segmentation that explicitly incorporates 3D priors. Specifically, we introduce a 3D-guided mask matching strategy that uses coarse 3D segments as a common reference to match 2D masks across views and consolidates multi-view mask consistency via 3D coverage distributions. Guided by these view-consistent 2D masks, the coarse 3D segments are further refined into precise 3D instances. Additionally, we introduce a depth consistency weighting scheme that quantifies projection reliability to suppress ambiguities from inter-object occlusions, thereby improving the robustness of 3D-to-2D correspondence. Extensive experiments on the ScanNetV2, ScanNet200, ScanNet++, Replica, and Matterport3D datasets demonstrate the effectiveness of MV3DIS, which achieves superior performance over previous methods
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MV3DIS, a coarse-to-fine zero-shot 3D instance segmentation framework. It derives coarse 3D segments from unsupervised geometric primitives, uses these as a common reference for 3D-guided mask matching to consolidate multi-view SAM 2D masks via 3D coverage distributions, refines the segments into precise instances, and applies depth consistency weighting to modulate projection reliability under occlusions. The abstract claims superior performance over prior methods on ScanNetV2, ScanNet200, ScanNet++, Replica, and Matterport3D.
Significance. If the quantitative results and robustness claims hold, the work provides a scalable alternative to supervised 3D instance segmentation by combining 2D foundation models with 3D geometric priors, addressing fragmentation issues in multi-view mask aggregation without requiring 3D annotations.
major comments (2)
- [Abstract] Abstract: the central claim of superior performance is asserted without any quantitative metrics, tables, ablation studies, or error analysis provided in the manuscript text, preventing verification of the effectiveness of the 3D-guided matching and depth weighting components.
- [Method] Method (coarse-to-fine pipeline): the 3D segments derived from geometric primitives serve as the sole common reference for cross-view 2D mask matching; no quantitative bound or sensitivity analysis is given on how initial grouping errors (common in cluttered indoor scenes) propagate through the matching and refinement steps, as the depth consistency weighting is applied only after matching.
minor comments (1)
- [Abstract] The abstract and method description would benefit from explicit notation for the 3D coverage distribution and depth consistency weight formulas to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address the two major comments point by point below, offering clarifications from the manuscript and committing to targeted revisions that strengthen the presentation without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of superior performance is asserted without any quantitative metrics, tables, ablation studies, or error analysis provided in the manuscript text, preventing verification of the effectiveness of the 3D-guided matching and depth weighting components.
Authors: The full manuscript contains quantitative metrics, comparison tables, and ablation studies in Sections 4 and 5 that report mAP, mIoU, and other metrics across ScanNetV2, ScanNet200, ScanNet++, Replica, and Matterport3D, along with component-wise ablations for the 3D-guided matching and depth consistency weighting. The abstract is intentionally concise and summarizes rather than enumerates these results. To improve verifiability, we will revise the abstract to include key performance numbers (e.g., average mAP gains) while preserving its length. revision: yes
-
Referee: [Method] Method (coarse-to-fine pipeline): the 3D segments derived from geometric primitives serve as the sole common reference for cross-view 2D mask matching; no quantitative bound or sensitivity analysis is given on how initial grouping errors (common in cluttered indoor scenes) propagate through the matching and refinement steps, as the depth consistency weighting is applied only after matching.
Authors: This observation is correct: the current manuscript does not provide an explicit sensitivity analysis or quantitative bounds on error propagation from the initial unsupervised geometric primitives through the 3D-guided matching stage. Depth consistency weighting occurs after matching, as described. We will add a dedicated analysis in the revised manuscript, including controlled experiments that perturb the coarse 3D segments and measure downstream effects on mask consistency and final instance metrics, to quantify robustness in cluttered scenes. revision: yes
Circularity Check
No circularity; derivation relies on external SAM and unsupervised geometric primitives without self-referential reduction
full rationale
The provided abstract and method outline describe a coarse-to-fine pipeline that starts from independent inputs (SAM 2D masks and coarse 3D segments derived from geometric primitives), applies 3D-guided matching via coverage distributions, refines instances, and adds depth consistency weighting. No equations, fitted parameters renamed as predictions, or self-citation chains are shown that would make the final 3D instances equivalent to the inputs by construction. The central claim of superior performance on multiple datasets is presented as an empirical outcome rather than a definitional or fitted tautology, consistent with the reader's assessment of score 2.0 and absence of load-bearing self-references.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Open-YOLO 3d: Towards fast and accurate open-vocabulary 3d instance segmentation
Mohamed El Amine Boudjoghra, Angela Dai, Jean Lahoud, Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan, and Fahad Shahbaz Khan. Open-YOLO 3d: Towards fast and accurate open-vocabulary 3d instance segmentation. In The Thirteenth International Conference on Learning Rep- resentations, 2025. 2
2025
-
[2]
Zero-shot semantic segmentation.Advances in Neural Information Processing Systems, 32, 2019
Maxime Bucher, Tuan-Hung Vu, Matthieu Cord, and Patrick P´erez. Zero-shot semantic segmentation.Advances in Neural Information Processing Systems, 32, 2019. 2
2019
-
[3]
Matterport3D: Learning from RGB-D Data in Indoor Environments
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from rgb-d data in indoor environments.arXiv preprint arXiv:1709.06158, 2017. 6
work page Pith review arXiv 2017
-
[4]
Hierarchical aggregation for 3d instance segmentation
Shaoyu Chen, Jiemin Fang, Qian Zhang, Wenyu Liu, and Xinggang Wang. Hierarchical aggregation for 3d instance segmentation. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 15467–15476,
-
[5]
Yolo-world: Real-time open-vocabulary object detection
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xing- gang Wang, and Ying Shan. Yolo-world: Real-time open-vocabulary object detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16901–16911, 2024. 2, 3
2024
-
[6]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017. 6
2017
-
[7]
De- coupling zero-shot semantic segmentation
Jian Ding, Nan Xue, Gui-Song Xia, and Dengxin Dai. De- coupling zero-shot semantic segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11583–11592, 2022. 2
2022
-
[8]
Pla: Language-driven open- vocabulary 3d scene understanding
Runyu Ding, Jihan Yang, Chuhui Xue, Wenqing Zhang, Song Bai, and Xiaojuan Qi. Pla: Language-driven open- vocabulary 3d scene understanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7010–7019, 2023. 2
2023
-
[9]
3d-mpa: Multi-proposal ag- gregation for 3d semantic instance segmentation
Francis Engelmann, Martin Bokeloh, Alireza Fathi, Bastian Leibe, and Matthias Nießner. 3d-mpa: Multi-proposal ag- gregation for 3d semantic instance segmentation. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9031–9040, 2020. 2
2020
-
[10]
Efficient graph-based image segmentation.International journal of computer vision, 59(2):167–181, 2004
Pedro F Felzenszwalb and Daniel P Huttenlocher. Efficient graph-based image segmentation.International journal of computer vision, 59(2):167–181, 2004. 3, 6, 7
2004
-
[11]
Scal- ing open-vocabulary image segmentation with image-level labels
Golnaz Ghiasi, Xiuye Gu, Yin Cui, and Tsung-Yi Lin. Scal- ing open-vocabulary image segmentation with image-level labels. InEuropean conference on computer vision, pages 540–557. Springer, 2022. 2
2022
-
[12]
Sam-guided graph cut for 3d instance segmentation
Haoyu Guo, He Zhu, Sida Peng, Yuang Wang, Yujun Shen, Ruizhen Hu, and Xiaowei Zhou. Sam-guided graph cut for 3d instance segmentation. InEuropean Conference on Com- puter Vision, pages 234–251. Springer, 2024. 3, 6, 7
2024
-
[13]
Clip goes 3d: Leveraging prompt tuning for language grounded 3d recognition
Deepti Hegde, Jeya Maria Jose Valanarasu, and Vishal Pa- tel. Clip goes 3d: Leveraging prompt tuning for language grounded 3d recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2028– 2038, 2023. 2
2028
-
[14]
3d-sis: 3d se- mantic instance segmentation of rgb-d scans
Ji Hou, Angela Dai, and Matthias Nießner. 3d-sis: 3d se- mantic instance segmentation of rgb-d scans. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4421–4430, 2019. 2
2019
-
[15]
Segment3d: Learning fine-grained class-agnostic 3d segmentation without manual labels
Rui Huang, Songyou Peng, Ayca Takmaz, Federico Tombari, Marc Pollefeys, Shiji Song, Gao Huang, and Francis Engel- mann. Segment3d: Learning fine-grained class-agnostic 3d segmentation without manual labels. InEuropean Confer- ence on Computer Vision, pages 278–295. Springer, 2024. 3
2024
-
[16]
Openins3d: Snap and lookup for 3d open-vocabulary instance segmentation
Zhening Huang, Xiaoyang Wu, Xi Chen, Hengshuang Zhao, Lei Zhu, and Joan Lasenby. Openins3d: Snap and lookup for 3d open-vocabulary instance segmentation. InEuropean Conference on Computer Vision, pages 169–185. Springer,
-
[17]
Open-vocabulary instance segmentation via ro- bust cross-modal pseudo-labeling
Dat Huynh, Jason Kuen, Zhe Lin, Jiuxiang Gu, and Ehsan Elhamifar. Open-vocabulary instance segmentation via ro- bust cross-modal pseudo-labeling. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7020–7031, 2022. 2
2022
-
[18]
Conceptfusion: Open-set multimodal 3d mapping.arXiv preprint arXiv:2302.07241, 2023
Krishna Murthy Jatavallabhula, Alihusein Kuwajerwala, Qiao Gu, Mohd Omama, Tao Chen, Alaa Maalouf, Shuang Li, Ganesh Iyer, Soroush Saryazdi, Nikhil Keetha, et al. Conceptfusion: Open-set multimodal 3d mapping.arXiv preprint arXiv:2302.07241, 2023. 2
-
[19]
Pointgroup: Dual-set point grouping for 3d instance segmentation
Li Jiang, Hengshuang Zhao, Shaoshuai Shi, Shu Liu, Chi- Wing Fu, and Jiaya Jia. Pointgroup: Dual-set point grouping for 3d instance segmentation. InProceedings of the IEEE/CVF conference on computer vision and Pattern recognition, pages 4867–4876, 2020. 2
2020
-
[20]
arXiv preprint arXiv:2507.23134 (2025) 9, 12, 13
Sanghun Jung, Jingjing Zheng, Ke Zhang, Nan Qiao, Al- bert YC Chen, Lu Xia, Chi Liu, Yuyin Sun, Xiao Zeng, Hsiang-Wei Huang, et al. Details matter for indoor open-vocabulary 3d instance segmentation.arXiv preprint arXiv:2507.23134, 2025. 3
-
[21]
Multi- modal classifiers for open-vocabulary object detection
Prannay Kaul, Weidi Xie, and Andrew Zisserman. Multi- modal classifiers for open-vocabulary object detection. InIn- ternational Conference on Machine Learning, pages 15946– 15969. PMLR, 2023. 2
2023
-
[22]
Segment anything in high qual- ity.Advances in Neural Information Processing Systems, 36: 29914–29934, 2023
Lei Ke, Mingqiao Ye, Martin Danelljan, Yu-Wing Tai, Chi- Keung Tang, Fisher Yu, et al. Segment anything in high qual- ity.Advances in Neural Information Processing Systems, 36: 29914–29934, 2023. 2, 7
2023
-
[23]
Lerf: Language embedded radiance fields
Justin Kerr, Chung Min Kim, Ken Goldberg, Angjoo Kanazawa, and Matthew Tancik. Lerf: Language embedded radiance fields. InProceedings of the IEEE/CVF interna- tional conference on computer vision, pages 19729–19739,
-
[24]
Segment any- thing
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 4015–4026, 2023. 1, 2, 3
2023
-
[25]
Oneformer3d: One transformer for unified point cloud segmentation
Maxim Kolodiazhnyi, Anna V orontsova, Anton Konushin, and Danila Rukhovich. Oneformer3d: One transformer for unified point cloud segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20943–20953, 2024. 2
2024
-
[26]
Mask-attention-free transformer for 3d in- stance segmentation
Xin Lai, Yuhui Yuan, Ruihang Chu, Yukang Chen, Han Hu, and Jiaya Jia. Mask-attention-free transformer for 3d in- stance segmentation. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 3693–3703,
-
[27]
Seg- ment any 3d object with language.arXiv preprint arXiv:2404.02157, 2024
Seungjun Lee, Yuyang Zhao, and Gim Hee Lee. Seg- ment any 3d object with language.arXiv preprint arXiv:2404.02157, 2024. 2
-
[28]
Language-driven semantic segmentation,
Boyi Li, Kilian Q Weinberger, Serge Belongie, Vladlen Koltun, and Ren ´e Ranftl. Language-driven semantic seg- mentation.arXiv preprint arXiv:2201.03546, 2022. 2
-
[29]
Semantic-sam: Segment and recognize anything at any granularity
Feng Li, Hao Zhang, Peize Sun, Xueyan Zou, Shilong Liu, Jianwei Yang, Chunyuan Li, Lei Zhang, and Jianfeng Gao. Semantic-sam: Segment and recognize anything at any gran- ularity.arXiv preprint arXiv:2307.04767, 2023. 2, 6
-
[30]
Hongyang Li, Jinyuan Qu, and Lei Zhang. Ovseg3r: Learn open-vocabulary instance segmentation from 2d via 3d re- construction.arXiv preprint arXiv:2509.23541, 2025. 2
-
[31]
Open-vocabulary object segmenta- tion with diffusion models
Ziyi Li, Qinye Zhou, Xiaoyun Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie. Open-vocabulary object segmenta- tion with diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7667– 7676, 2023. 2
2023
-
[32]
Open-vocabulary semantic segmentation with mask-adapted clip
Feng Liang, Bichen Wu, Xiaoliang Dai, Kunpeng Li, Yinan Zhao, Hang Zhang, Peizhao Zhang, Peter Vajda, and Diana Marculescu. Open-vocabulary semantic segmentation with mask-adapted clip. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 7061–7070, 2023. 2
2023
-
[33]
Instance segmentation in 3d scenes using semantic superpoint tree networks
Zhihao Liang, Zhihao Li, Songcen Xu, Mingkui Tan, and Kui Jia. Instance segmentation in 3d scenes using semantic superpoint tree networks. InProceedings of the IEEE/CVF international conference on computer vision, pages 2783– 2792, 2021. 2
2021
-
[34]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuro- pean conference on computer vision, pages 38–55. Springer,
-
[35]
Query refinement transformer for 3d in- stance segmentation
Jiahao Lu, Jiacheng Deng, Chuxin Wang, Jianfeng He, and Tianzhu Zhang. Query refinement transformer for 3d in- stance segmentation. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 18516– 18526, 2023. 2
2023
-
[36]
Ovir-3d: Open-vocabulary 3d in- stance retrieval without training on 3d data
Shiyang Lu, Haonan Chang, Eric Pu Jing, Abdeslam Boular- ias, and Kostas Bekris. Ovir-3d: Open-vocabulary 3d in- stance retrieval without training on 3d data. InConference on Robot Learning, pages 1610–1620. PMLR, 2023. 3, 6, 7
2023
-
[37]
Open3dis: Open-vocabulary 3d instance segmentation with 2d mask guidance
Phuc Nguyen, Tuan Duc Ngo, Evangelos Kalogerakis, Chuang Gan, Anh Tran, Cuong Pham, and Khoi Nguyen. Open3dis: Open-vocabulary 3d instance segmentation with 2d mask guidance. InCVPR, pages 4018–4028, 2024. 1, 3, 6, 7
2024
-
[38]
Any3dis: Class-agnostic 3d instance segmentation by 2d mask tracking
Phuc Nguyen, Minh Luu, Anh Tran, Cuong Pham, and Khoi Nguyen. Any3dis: Class-agnostic 3d instance segmentation by 2d mask tracking. InProceedings of the Computer Vi- sion and Pattern Recognition Conference, pages 3636–3645,
-
[39]
Openscene: 3d scene understanding with open vocabularies
Songyou Peng, Kyle Genova, Chiyu Jiang, Andrea Tagliasacchi, Marc Pollefeys, Thomas Funkhouser, et al. Openscene: 3d scene understanding with open vocabularies. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 815–824, 2023. 2
2023
-
[40]
Lp-ovod: Open- vocabulary object detection by linear probing
Chau Pham, Truong Vu, and Khoi Nguyen. Lp-ovod: Open- vocabulary object detection by linear probing. InProceed- ings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 779–788, 2024. 2
2024
-
[41]
High-Quality Entity Segmentation, April 2023
Lu Qi, Jason Kuen, Weidong Guo, Tiancheng Shen, Jiuxiang Gu, Jiaya Jia, Zhe Lin, and Ming-Hsuan Yang. High-quality entity segmentation.arXiv preprint arXiv:2211.05776, 2022. 7
-
[42]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 1, 2, 3
2021
-
[43]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open-world mod- els for diverse visual tasks. arxiv 2024.arXiv preprint arXiv:2401.14159. 6
work page internal anchor Pith review arXiv 2024
-
[45]
Language- grounded indoor 3d semantic segmentation in the wild
David Rozenberszki, Or Litany, and Angela Dai. Language- grounded indoor 3d semantic segmentation in the wild. In European conference on computer vision, pages 125–141. Springer, 2022. 6
2022
-
[46]
Jonas Schult, Francis Engelmann, Alexander Hermans, Or Litany, Siyu Tang, and Bastian Leibe. Mask3d: Mask trans- former for 3d semantic instance segmentation.arXiv preprint arXiv:2210.03105, 2022. 1, 2, 6, 7
-
[47]
The Replica Dataset: A Digital Replica of Indoor Spaces
Julian Straub, Thomas Whelan, Lingni Ma, Yufan Chen, Erik Wijmans, Simon Green, Jakob J Engel, Raul Mur-Artal, Carl Ren, Shobhit Verma, et al. The replica dataset: A digital replica of indoor spaces.arXiv preprint arXiv:1906.05797,
work page internal anchor Pith review arXiv 1906
-
[48]
Superpoint transformer for 3d scene instance segmentation
Jiahao Sun, Chunmei Qing, Junpeng Tan, and Xiangmin Xu. Superpoint transformer for 3d scene instance segmentation. InProceedings of the AAAI Conference on Artificial Intelli- gence, pages 2393–2401, 2023. 2
2023
-
[49]
Openmask3d: Open-vocabulary 3d instance segmen- tation,
Ayc ¸a Takmaz, Elisabetta Fedele, Robert W Sumner, Marc Pollefeys, Federico Tombari, and Francis Engelmann. Open- mask3d: Open-vocabulary 3d instance segmentation.arXiv preprint arXiv:2306.13631, 2023. 2, 6, 7
-
[50]
Onlineanyseg: On- line zero-shot 3d segmentation by visual foundation model guided 2d mask merging
Yijie Tang, Jiazhao Zhang, Yuqing Lan, Yulan Guo, Dezun Dong, Chenyang Zhu, and Kai Xu. Onlineanyseg: On- line zero-shot 3d segmentation by visual foundation model guided 2d mask merging. InProceedings of the Computer Vi- sion and Pattern Recognition Conference, pages 3676–3685,
-
[51]
Mask-free ovis: Open-vocabulary instance segmentation without man- ual mask annotations
Vibashan VS, Ning Yu, Chen Xing, Can Qin, Mingfei Gao, Juan Carlos Niebles, Vishal M Patel, and Ran Xu. Mask-free ovis: Open-vocabulary instance segmentation without man- ual mask annotations. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 23539–23549, 2023. 2
2023
-
[52]
Softgroup for 3d instance segmentation on point clouds
Thang Vu, Kookhoi Kim, Tung M Luu, Thanh Nguyen, and Chang D Yoo. Softgroup for 3d instance segmentation on point clouds. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2708–2717,
-
[53]
Chaolei Wang, Yang Luo, Jing Du, Siyu Chen, Yiping Chen, and Ting Han. Sgs-3d: High-fidelity 3d instance segmenta- tion via reliable semantic mask splitting and growing.arXiv preprint arXiv:2509.05144, 2025. 3, 6, 7
-
[54]
Object-aware dis- tillation pyramid for open-vocabulary object detection
Luting Wang, Yi Liu, Penghui Du, Zihan Ding, Yue Liao, Qiaosong Qi, Biaolong Chen, and Si Liu. Object-aware dis- tillation pyramid for open-vocabulary object detection. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 11186–11196, 2023. 2
2023
-
[55]
Be- trayed by captions: Joint caption grounding and generation for open vocabulary instance segmentation
Jianzong Wu, Xiangtai Li, Henghui Ding, Xia Li, Guan- gliang Cheng, Yunhai Tong, and Chen Change Loy. Be- trayed by captions: Joint caption grounding and generation for open vocabulary instance segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 21938–21948, 2023. 2
2023
-
[56]
Diffumask: Synthesizing images with pixel-level annotations for semantic segmentation using dif- fusion models
Weijia Wu, Yuzhong Zhao, Mike Zheng Shou, Hong Zhou, and Chunhua Shen. Diffumask: Synthesizing images with pixel-level annotations for semantic segmentation using dif- fusion models. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 1206–1217,
-
[57]
Groupvit: Semantic segmentation emerges from text supervision
Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, and Xiaolong Wang. Groupvit: Semantic segmentation emerges from text supervision. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 18134–18144, 2022. 2
2022
-
[58]
Sampro3d: Locating sam prompts in 3d for zero-shot instance segmentation
Mutian Xu, Xingyilang Yin, Lingteng Qiu, Yang Liu, Xin Tong, and Xiaoguang Han. Sampro3d: Locating sam prompts in 3d for zero-shot instance segmentation. InIn- ternational Conference on 3D Vision 2025. 3, 6, 7
2025
-
[59]
Maskclus- tering: View consensus based mask graph clustering for open-vocabulary 3d instance segmentation
Mi Yan, Jiazhao Zhang, Yan Zhu, and He Wang. Maskclus- tering: View consensus based mask graph clustering for open-vocabulary 3d instance segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 28274–28284, 2024. 3, 6, 7
2024
-
[60]
Learning ob- ject bounding boxes for 3d instance segmentation on point clouds.Advances in neural information processing systems, 32, 2019
Bo Yang, Jianan Wang, Ronald Clark, Qingyong Hu, Sen Wang, Andrew Markham, and Niki Trigoni. Learning ob- ject bounding boxes for 3d instance segmentation on point clouds.Advances in neural information processing systems, 32, 2019. 2
2019
-
[61]
arXiv preprint arXiv:2306.03908 (2023)
Yunhan Yang, Xiaoyang Wu, Tong He, Hengshuang Zhao, and Xihui Liu. Sam3d: Segment anything in 3d scenes.arXiv preprint arXiv:2306.03908, 2023. 1, 2, 3, 6, 7, 8
-
[62]
Detclipv2: Scal- able open-vocabulary object detection pre-training via word- region alignment
Lewei Yao, Jianhua Han, Xiaodan Liang, Dan Xu, Wei Zhang, Zhenguo Li, and Hang Xu. Detclipv2: Scal- able open-vocabulary object detection pre-training via word- region alignment. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 23497–23506, 2023. 2
2023
-
[63]
Scannet++: A high-fidelity dataset of 3d in- door scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. Scannet++: A high-fidelity dataset of 3d in- door scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12–22, 2023. 6
2023
-
[64]
Gspn: Generative shape proposal network for 3d instance segmentation in point cloud
Li Yi, Wang Zhao, He Wang, Minhyuk Sung, and Leonidas J Guibas. Gspn: Generative shape proposal network for 3d instance segmentation in point cloud. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3947–3956, 2019. 2
2019
-
[65]
Sai3d: Segment any instance in 3d scenes
Yingda Yin, Yuzheng Liu, Yang Xiao, Daniel Cohen-Or, Jingwei Huang, and Baoquan Chen. Sai3d: Segment any instance in 3d scenes. InCVPR, pages 3292–3302, 2024. 1, 2, 3, 5, 6, 7, 8
2024
-
[66]
Open-vocabulary detr with conditional matching
Yuhang Zang, Wei Li, Kaiyang Zhou, Chen Huang, and Chen Change Loy. Open-vocabulary detr with conditional matching. InEuropean conference on computer vision, pages 106–122. Springer, 2022. 2
2022
-
[67]
A simple framework for open-vocabulary segmentation and detection
Hao Zhang, Feng Li, Xueyan Zou, Shilong Liu, Chunyuan Li, Jianwei Yang, and Lei Zhang. A simple framework for open-vocabulary segmentation and detection. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 1020–1031, 2023. 2
2023
-
[68]
Sam2object: Consolidating view consistency via sam2 for zero-shot 3d instance segmentation
Jihuai Zhao, Junbao Zhuo, Jiansheng Chen, and Huimin Ma. Sam2object: Consolidating view consistency via sam2 for zero-shot 3d instance segmentation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19325–19334, 2025. 2, 3, 5, 6, 7
2025
-
[69]
Regionclip: Region- based language-image pretraining
Yiwu Zhong, Jianwei Yang, Pengchuan Zhang, Chun- yuan Li, Noel Codella, Liunian Harold Li, Luowei Zhou, Xiyang Dai, Lu Yuan, Yin Li, et al. Regionclip: Region- based language-image pretraining. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16793–16803, 2022. 2
2022
-
[70]
Segment everything everywhere all at once.Advances in neural information processing systems, 36:19769–19782,
Xueyan Zou, Jianwei Yang, Hao Zhang, Feng Li, Linjie Li, Jianfeng Wang, Lijuan Wang, Jianfeng Gao, and Yong Jae Lee. Segment everything everywhere all at once.Advances in neural information processing systems, 36:19769–19782,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.