Recognition: 2 theorem links
· Lean TheoremMuTSE: A Human-in-the-Loop Multi-use Text Simplification Evaluator
Pith reviewed 2026-05-10 18:00 UTC · model grok-4.3
The pith
MuTSE is a web application that uses a tiered semantic alignment engine with linearity bias to visually map and compare multiple LLM text simplifications at once.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
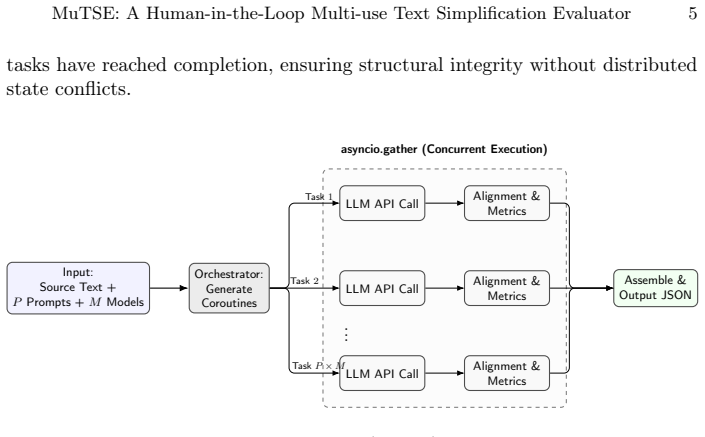
MuTSE supports concurrent execution of P times M prompt-model permutations to produce a comparison matrix for simplifications aimed at arbitrary CEFR proficiency targets, while its tiered semantic alignment engine with linearity bias heuristic lambda visually connects source sentences to simplified versions.
What carries the argument
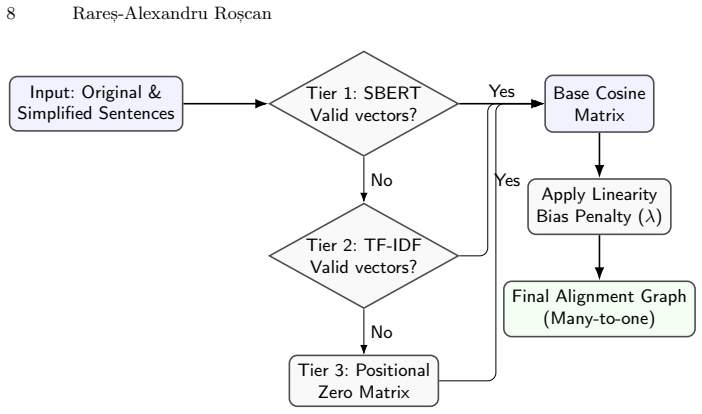
The tiered semantic alignment engine augmented with a linearity bias heuristic (lambda), which performs the visual mapping of source sentences to their simplified counterparts.
If this is right
- Researchers gain the ability to inspect prompt-model permutations side-by-side in real time rather than running separate static scripts.
- Educators obtain a visual framework that supports systematic comparison across proficiency targets without being limited to conversational interfaces.
- Downstream NLP work benefits from more consistent human annotations that can be reused to construct simplification datasets.
- Multi-dimensional evaluation of simplification quality becomes feasible across arbitrary CEFR levels in a single session.
Where Pith is reading between the lines
- The visual mapping approach could be extended to other generation tasks such as summarization or paraphrasing where sentence-level correspondence matters.
- If the linearity bias proves reliable, the same engine might serve as a lightweight component inside automated simplification pipelines.
- Wider adoption would require testing how well the tool scales when many annotators work on large corpora simultaneously.
Load-bearing premise
The tiered semantic alignment engine and linearity bias heuristic will reduce cognitive load and yield reproducible structured annotations even though no validation studies, user tests, or comparisons to existing methods are reported.
What would settle it
A controlled user study that measures annotation time, inter-rater agreement, and error rates when evaluators use MuTSE versus static scripts or standard chat interfaces on the same set of LLM simplifications.
Figures



read the original abstract
As Large Language Models (LLMs) become increasingly prevalent in text simplification, systematically evaluating their outputs across diverse prompting strategies and architectures remains a critical methodological challenge in both NLP research and Intelligent Tutoring Systems (ITS). Developing robust prompts is often hindered by the absence of structured, visual frameworks for comparative text analysis. While researchers typically rely on static computational scripts, educators are constrained to standard conversational interfaces -- neither paradigm supports systematic multi-dimensional evaluation of prompt-model permutations. To address these limitations, we introduce \textbf{MuTSE}\footnote{The project code and the demo have been made available for peer review at the following anonymized URL. https://osf.io/njs43/overview?view_only=4b4655789f484110a942ebb7788cdf2a, an interactive human-in-the-loop web application designed to streamline the evaluation of LLM-generated text simplifications across arbitrary CEFR proficiency targets. The system supports concurrent execution of $P \times M$ prompt-model permutations, generating a comprehensive comparison matrix in real-time. By integrating a novel tiered semantic alignment engine augmented with a linearity bias heuristic ($\lambda$), MuTSE visually maps source sentences to their simplified counterparts, reducing the cognitive load associated with qualitative analysis and enabling reproducible, structured annotation for downstream NLP dataset construction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MuTSE, an interactive human-in-the-loop web application for evaluating LLM-generated text simplifications across P×M prompt-model permutations and arbitrary CEFR targets. It claims that a novel tiered semantic alignment engine augmented with a linearity bias heuristic (λ) visually maps source sentences to simplified outputs, thereby reducing cognitive load in qualitative analysis and enabling reproducible structured annotation for downstream NLP datasets.
Significance. If the asserted benefits are empirically validated, MuTSE could provide a practical structured framework for systematic comparison of text simplification outputs, addressing a gap between static scripts and conversational interfaces in NLP research and intelligent tutoring systems. The open release of code and demo is a positive step toward reproducibility.
major comments (2)
- [Abstract, §3] Abstract and §3 (system description): The central claim that the tiered semantic alignment engine + λ heuristic 'reduces the cognitive load associated with qualitative analysis and enabling reproducible, structured annotation' is asserted without any supporting evidence such as user-study metrics (NASA-TLX, task completion time), inter-annotator agreement (e.g., Cohen's κ), or comparison against baseline interfaces. This is load-bearing for the paper's contribution.
- [§4] §4 (evaluation or results): No performance metrics, error analysis, or ablation of the alignment engine components are reported, leaving the functionality of the 'tiered semantic alignment' and the role of λ untested and unquantified.
minor comments (2)
- [Abstract] The footnote URL for code/demo is anonymized; ensure a permanent, non-anonymized link is provided in the camera-ready version.
- [§2] Notation for P × M permutations and CEFR targets is introduced without a formal definition or example matrix in the main text.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which helps clarify the scope and claims of our system paper. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (system description): The central claim that the tiered semantic alignment engine + λ heuristic 'reduces the cognitive load associated with qualitative analysis and enabling reproducible, structured annotation' is asserted without any supporting evidence such as user-study metrics (NASA-TLX, task completion time), inter-annotator agreement (e.g., Cohen's κ), or comparison against baseline interfaces. This is load-bearing for the paper's contribution.
Authors: We agree that the manuscript asserts these benefits without direct empirical evidence from user studies or agreement metrics. The claims stem from the intended design of the visual mapping and structured output features. In the revised manuscript, we will qualify the language in the abstract and §3 to present these as hypothesized advantages based on the system's architecture, rather than validated outcomes. We will also add a limitations section noting the absence of such evaluations and outlining plans for future validation. revision: yes
-
Referee: [§4] §4 (evaluation or results): No performance metrics, error analysis, or ablation of the alignment engine components are reported, leaving the functionality of the 'tiered semantic alignment' and the role of λ untested and unquantified.
Authors: The manuscript's §4 provides a qualitative demonstration of the platform's use for comparing simplifications rather than a quantitative evaluation of the internal alignment engine. The tiered semantic alignment and λ heuristic serve as supporting visualization aids, not as core models to be benchmarked. We do not claim quantitative superiority for these components. To address the comment, we will expand §4 with additional implementation details and example traces of the alignment process in the revision, though a full ablation study remains outside the paper's primary scope as a system description. revision: partial
Circularity Check
No circularity: claims are descriptive properties of the introduced system
full rationale
The paper presents MuTSE as a newly designed human-in-the-loop web application whose tiered semantic alignment engine and linearity bias heuristic (λ) are introduced by definition to produce visual mappings and structured annotations. No equations, fitted parameters, self-citations, or prior results are invoked to derive the claimed reductions in cognitive load; the benefits are asserted as direct outcomes of the system's architecture rather than obtained by construction from any input data or external theorem. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
free parameters (1)
- linearity bias heuristic λ
axioms (1)
- domain assumption CEFR proficiency levels provide a suitable and arbitrary target for text simplification evaluation
invented entities (2)
-
MuTSE web application
no independent evidence
-
tiered semantic alignment engine
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Score(i, j) = CosineSim(S(i)_orig, S(j)_simp) − |Pos(i)_rel − Pos(j)_rel| × λ
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
tiered semantic alignment engine augmented with a linearity bias heuristic (λ)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Alva-Manchego, F., Martin, L., Bordes, A., Scarton, C., Sagot, B., Specia, L.: ASSET: A dataset for tuning and evaluation of sentence simplification models with multiple rewriting transformations. In: Jurafsky, D., Chai, J., Schluter, N., MuTSE: A Human-in-the-Loop Multi-use Text Simplification Evaluator 13 Tetreault, J. (eds.) Proceedings of the 58th Ann...
-
[2]
Alva-Manchego, F., Martin, L., Scarton, C., Specia, L.: EASSE: Easier automatic sentence simplification evaluation. In: Padó, S., Huang, R. (eds.) Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP): System Demonstrations. pp. 49–54....
-
[3]
In: van Deemter, K., Lin, C., Takamura, H
Amidei, J., Piwek, P., Willis, A.: The use of rating and Likert scales in natu- ral language generation human evaluation tasks: A review and some recommen- dations. In: van Deemter, K., Lin, C., Takamura, H. (eds.) Proceedings of the 12th International Conference on Natural Language Generation. pp. 397–402. As- sociation for Computational Linguistics, Tok...
-
[4]
In: Proc
Brown, J., Eskénazi, M.: Retrieval of authentic documents for reader-specific lexical practice. In: Proc. InSTIL/ICALL 2004 Symposium on Computer Assisted Learning, paper 006 (2004),https://api.semanticscholar.org/CorpusID:6480264
2004
-
[5]
In: Mitkov, R., Angelova, G
Espinosa-Zaragoza, I., Abreu-Salas, J., Lloret, E., Moreda, P., Palomar, M.: A review of research-based automatic text simplification tools. In: Mitkov, R., Angelova, G. (eds.) Proceedings of the 14th International Conference on Recent Advances in Natural Language Processing. pp. 321–330. INCOMA Ltd., Shoumen, Bulgaria, Varna, Bulgaria (Sep 2023),https://...
2023
- [6]
-
[7]
Journal of Applied Psychology32(3), 221–233 (1948).https://doi.org/10.1037/h0057532
Flesch, R.: A new readability yardstick. Journal of Applied Psychology32(3), 221–233 (1948).https://doi.org/10.1037/h0057532
-
[8]
In: Pareja-Lora, A., Liakata, M., Dipper, S
Graham, Y., Baldwin, T., Moffat, A., Zobel, J.: Continuous measurement scales in human evaluation of machine translation. In: Pareja-Lora, A., Liakata, M., Dipper, S. (eds.) Proceedings of the 7th Linguistic Annotation Workshop and Interoperability withDiscourse.pp.33–41.AssociationforComputationalLinguistics,Sofia,Bulgaria (Aug 2013),https://aclanthology...
2013
-
[9]
In: Davis, B., Graham, Y., Kelleher, J., Sripada, Y
Howcroft, D.M., Belz, A., Clinciu, M.A., Gkatzia, D., Hasan, S.A., Mahamood, S., Mille, S., van Miltenburg, E., Santhanam, S., Rieser, V.: Twenty years of confusion in human evaluation: NLG needs evaluation sheets and standardised definitions. In: Davis, B., Graham, Y., Kelleher, J., Sripada, Y. (eds.) Proceedings of the 13th International Conference on N...
2020
-
[10]
In: Bouamor, H., Pino, J., Bali, K
Kew, T., Chi, A., Vásquez-Rodríguez, L., Agrawal, S., Aumiller, D., Alva- Manchego, F., Shardlow, M.: BLESS: Benchmarking large language models on sentence simplification. In: Bouamor, H., Pino, J., Bali, K. (eds.) Proceed- ings of the 2023 Conference on Empirical Methods in Natural Language Pro- cessing. pp. 13291–13309. Association for Computational Lin...
-
[11]
org/CorpusID:61131325
Kincaid, P., Fishburne, R.P., Rogers, R.L., Chissom, B.S.: Derivation of new readability formulas (automated readability index, fog count and flesch reading 14 Rares ,-Alexandru Ros,can ease formula) for navy enlisted personnel (1975),https://api.semanticscholar. org/CorpusID:61131325
1975
-
[12]
In: Intelligent Tutoring Systems in e-Learning Environments: Design, Implementa- tion and Evaluation
Mostow, J., Aist, G.: Evaluating tutors that listen: An overview of project LISTEN. In: Intelligent Tutoring Systems in e-Learning Environments: Design, Implementa- tion and Evaluation. Information Science Publishing (2001)
2001
-
[13]
Reimers, N., Gurevych, I.: Sentence-bert: Sentence embeddings using siamese bert-networks (2019),https://arxiv.org/abs/1908.10084
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[14]
doi:10.1016/0306-4573(88)90021-0
Salton, G., Buckley, C.: Term-weighting approaches in automatic text re- trieval. Information Processing and Management24(5), 513–523 (1988). https://doi.org/https://doi.org/10.1016/0306-4573(88)90021-0, https:// www.sciencedirect.com/science/article/pii/0306457388900210
-
[15]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Stodden, R., Kallmeyer, L.: TS-ANNO: An annotation tool to build, annotate and evaluate text simplification corpora. In: Basile, V., Kozareva, Z., Stajner, S. (eds.) Proceedings of the 60th Annual Meeting of the Association for Computa- tional Linguistics: System Demonstrations. pp. 145–155. Association for Compu- tational Linguistics, Dublin, Ireland (Ma...
-
[16]
Xu,W.,Napoles,C.,Pavlick,E.,Chen,Q.,Callison-Burch,C.:Optimizingstatistical machine translation for text simplification. Transactions of the Association for Computational Linguistics4, 401–415 (2016).https://doi.org/10.1162/tacl_a_ 00107,https://aclanthology.org/Q16-1029/
-
[17]
Zhang, T., Kishore, V., Wu, F., Weinberger, K.Q., Artzi, Y.: Bertscore: Evaluating text generation with bert (2020),https://arxiv.org/abs/1904.09675
work page internal anchor Pith review Pith/arXiv arXiv 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.