Recognition: 2 theorem links
· Lean TheoremTaxPraBen: A Scalable Benchmark for Structured Evaluation of LLMs in Chinese Real-World Tax Practice
Pith reviewed 2026-05-10 17:55 UTC · model grok-4.3
The pith
TaxPraBen benchmark shows closed-source large LLMs outperform others in real Chinese tax tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
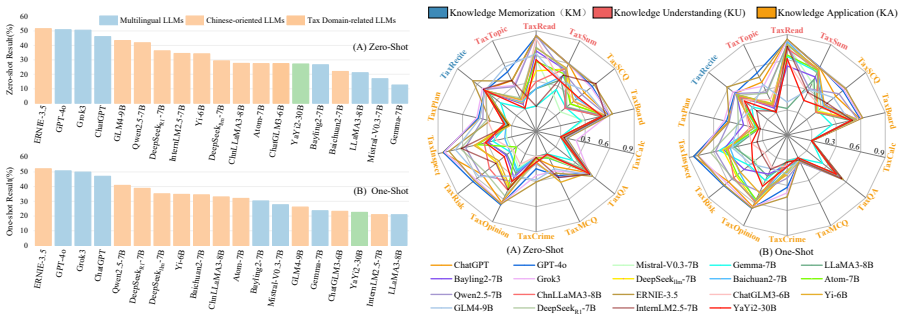
TaxPraBen introduces a scalable structured evaluation paradigm for end-to-end assessment of LLMs in Chinese tax practice. It covers ten traditional tasks plus three new scenarios in risk prevention, inspection analysis, and strategy planning. Testing nineteen models finds that all closed-source large-parameter LLMs perform strongly, Chinese LLMs such as Qwen2.5 generally surpass multilingual ones, and the YaYi2 model fine-tuned on some tax data shows only limited gains.
What carries the argument
The structured evaluation paradigm of structured parsing followed by field alignment, extraction, and numerical and textual matching that turns raw model outputs into comparable scores across tax scenarios.
If this is right
- Closed-source large models are currently better positioned for deployment in tax-related applications than smaller or open models.
- Language-specific training gives Chinese LLMs an edge over multilingual models when handling tax regulations and terminology.
- Fine-tuning on limited tax data produces only modest gains, suggesting broader or higher-quality data is needed for strong results.
- The same structured paradigm can be reused to build benchmarks in other regulated professional domains.
Where Pith is reading between the lines
- Developers of tax tools may gain more from scaling up general models than from narrow fine-tuning on existing tax datasets.
- The benchmark could guide creation of new training data that targets the specific gaps observed in inspection analysis and strategy planning.
- Similar structured matching approaches might help evaluate LLMs in other high-stakes legal or financial fields where outputs must match precise rules.
Load-bearing premise
The chosen real-world scenarios and the parsing-alignment-matching process together measure practical tax capabilities without missing important regulated aspects of the work.
What would settle it
A model that scores low on TaxPraBen yet handles actual tax filings, audits, or planning tasks accurately in professional settings would indicate the benchmark misses key capabilities.
Figures



read the original abstract
While Large Language Models (LLMs) excel in various general domains, they exhibit notable gaps in the highly specialized, knowledge-intensive, and legally regulated Chinese tax domain. Consequently, while tax-related benchmarks are gaining attention, many focus on isolated NLP tasks, neglecting real-world practical capabilities. To address this issue, we introduce TaxPraBen, the first dedicated benchmark for Chinese taxation practice. It combines 10 traditional application tasks, along with 3 pioneering real-world scenarios: tax risk prevention, tax inspection analysis, and tax strategy planning, sourced from 14 datasets totaling 7.3K instances. TaxPraBen features a scalable structured evaluation paradigm designed through process of "structured parsing-field alignment extraction-numerical and textual matching", enabling end-to-end tax practice assessment while being extensible to other domains. We evaluate 19 LLMs based on Bloom's taxonomy. The results indicate significant performance disparities: all closed-source large-parameter LLMs excel, and Chinese LLMs like Qwen2.5 generally exceed multilingual LLMs, while the YaYi2 LLM, fine-tuned with some tax data, shows only limited improvement. TaxPraBen serves as a vital resource for advancing evaluations of LLMs in practical applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TaxPraBen, the first benchmark dedicated to Chinese taxation practice. It integrates 10 traditional NLP application tasks with 3 novel real-world scenarios (tax risk prevention, tax inspection analysis, and tax strategy planning) sourced from 14 datasets totaling 7.3K instances. The work proposes a scalable structured evaluation paradigm based on structured parsing, field alignment, extraction, and numerical/textual matching to enable end-to-end assessment of practical tax capabilities. The authors evaluate 19 LLMs using Bloom's taxonomy and report performance disparities: closed-source large-parameter models excel, Chinese LLMs (e.g., Qwen2.5) generally outperform multilingual models, and the tax-fine-tuned YaYi2 shows only limited improvement.
Significance. If the evaluation paradigm proves reliable, TaxPraBen fills an important gap by moving beyond isolated NLP tasks to assess LLMs in a knowledge-intensive, legally regulated domain. The combination of traditional tasks with pioneering real-world scenarios and the extensible structured matching approach are strengths that could support broader domain adaptation. The reported model-type disparities offer useful initial signals for LLM development in practical applications, and the benchmark's scale (7.3K instances) and public intent add value for the community.
major comments (2)
- [Abstract] Abstract: the reported 'significant performance disparities' (closed-source vs. open, Chinese vs. multilingual, limited gain from YaYi2 fine-tuning) are presented without any reference to statistical significance testing, error bars, or controls for dataset quality and annotation bias; this is load-bearing for the central empirical claims about LLM capabilities.
- [Evaluation Method] Evaluation paradigm description: no details are supplied on validation of the 'structured parsing-field alignment extraction-numerical and textual matching' method against expert human judgments, inter-annotator agreement, or coverage of regulated tax work aspects; without such evidence the claim that the paradigm accurately measures end-to-end practical capabilities cannot be assessed.
minor comments (1)
- The manuscript would benefit from explicit dataset citations and provenance details for the 14 source datasets to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below and will incorporate revisions to strengthen the statistical rigor and validation of our evaluation paradigm.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported 'significant performance disparities' (closed-source vs. open, Chinese vs. multilingual, limited gain from YaYi2 fine-tuning) are presented without any reference to statistical significance testing, error bars, or controls for dataset quality and annotation bias; this is load-bearing for the central empirical claims about LLM capabilities.
Authors: We agree that the abstract and main results would benefit from greater statistical rigor. The current manuscript presents performance tables for 19 LLMs but omits significance testing and error bars. We will revise to include bootstrap confidence intervals or paired statistical tests comparing model categories (e.g., closed- vs. open-source, Chinese vs. multilingual). We will also expand the dataset section to detail curation procedures, expert annotation protocols, and steps taken to address potential quality or bias issues. revision: yes
-
Referee: [Evaluation Method] Evaluation paradigm description: no details are supplied on validation of the 'structured parsing-field alignment extraction-numerical and textual matching' method against expert human judgments, inter-annotator agreement, or coverage of regulated tax work aspects; without such evidence the claim that the paradigm accurately measures end-to-end practical capabilities cannot be assessed.
Authors: The structured evaluation paradigm is presented as a scalable, extensible approach in the methods section. We acknowledge the absence of explicit human validation or IAA metrics. In the revision we will add a new subsection reporting a human judgment study, inter-annotator agreement scores, and an analysis of coverage for core regulated tax practices, thereby providing direct evidence for the paradigm's reliability. revision: yes
Circularity Check
No significant circularity in empirical benchmark construction
full rationale
The paper constructs TaxPraBen by aggregating 14 external datasets into 10 tasks plus 3 new scenarios and applies a standard structured parsing/matching evaluation paradigm. No mathematical derivations, fitted parameters, or predictions are present; performance disparities are reported directly from model evaluations on held-out instances. Bloom's taxonomy and the matching procedure are imported as external standards rather than defined in terms of the benchmark outputs. No self-citation chains, ansatzes, or renamings reduce the central claims to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bloom's taxonomy is a suitable framework for evaluating LLM performance in specialized tax practice tasks
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, and others . 2023. Qwen technical report. arXiv preprint arXiv:2309.16609
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [4]
-
[5]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and others . 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877--1901
2020
-
[6]
Yan Cai, Linlin Wang, Ye Wang, Gerard de Melo, Ya Zhang, Yanfeng Wang, and Liang He. 2024 a . Medbench: A large-scale chinese benchmark for evaluating medical large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 17709--17717
2024
- [7]
-
[8]
Ilias Chalkidis, Abhik Jana, Dirk Hartung, Michael Bommarito, Ion Androutsopoulos, Daniel Katz, and Nikolaos Aletras. 2022. Lexglue: A benchmark dataset for legal language understanding in english. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, pages 4310--4330
2022
-
[9]
Yating Chen, Siqi Lv, Peiyuan Xia, Zhenxu Wang, Yiming Qin, Qingqing Wang, and Gang Hu. 2025. Taxben: Benchmarking the chinese tax knowledge of large language models. In CCF International Conference on Natural Language Processing and Chinese Computing, pages 307--321. Springer
2025
-
[10]
Yirong Chen, Zhenyu Wang, Xiaofen Xing, Zhipei Xu, Kai Fang, Junhong Wang, Sihang Li, Jieling Wu, Qi Liu, Xiangmin Xu, and others . 2023 a . Bianque: Balancing the questioning and suggestion ability of health llms with multi-turn health conversations polished by chatgpt. arXiv preprint arXiv:2310.15896
- [11]
- [12]
- [13]
-
[14]
Yongfu Dai, Duanyu Feng, Jimin Huang, Haochen Jia, Qianqian Xie, Yifang Zhang, Weiguang Han, Wei Tian, and Hao Wang. 2025. Laiw: A chinese legal large language models benchmark. In Proceedings of the 31st International conference on computational linguistics, pages 10738--10766
2025
-
[15]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, and others . 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. 2024. Detecting hallucinations in large language models using semantic entropy. Nature, 630(8017):625--630
2024
-
[17]
Zhiwei Fei, Xiaoyu Shen, Dawei Zhu, Fengzhe Zhou, Zhuo Han, Alan Huang, Songyang Zhang, Kai Chen, Zhixin Yin, Zongwen Shen, and others . 2024. Lawbench: Benchmarking legal knowledge of large language models. In Proceedings of the 2024 conference on empirical methods in natural language processing, pages 7933--7962
2024
-
[18]
Leo Gao, Jonathan Tow, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Kyle McDonell, Niklas Muennighoff, and others . 2021. A framework for few-shot language model evaluation. Zenodo
2021
-
[19]
Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Hanlin Zhao, and others . 2024. Chatglm: A family of large language models from glm-130b to glm-4 all tools. arXiv preprint arXiv:2406.12793
work page internal anchor Pith review arXiv 2024
-
[20]
Cyril Goutte and Eric Gaussier. 2005. A probabilistic interpretation of precision, recall and f-score, with implication for evaluation. In European conference on information retrieval, pages 345--359. Springer
2005
-
[21]
Zhouhong Gu, Xiaoxuan Zhu, Haoning Ye, Lin Zhang, Jianchen Wang, Yixin Zhu, Sihang Jiang, Zhuozhi Xiong, Zihan Li, Weijie Wu, and others . 2024. Xiezhi: An ever-updating benchmark for holistic domain knowledge evaluation. In Proceedings of the AAAI conference on artificial intelligence, volume 38, pages 18099--18107
2024
-
[22]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, and others . 2025 a . Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Xin Guo, Haotian Xia, Zhaowei Liu, Hanyang Cao, Zhi Yang, Zhiqiang Liu, Sizhe Wang, Jinyi Niu, Chuqi Wang, Yanhui Wang, and others . 2025 b . Fineval: A chinese financial domain knowledge evaluation benchmark for large language models. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguis...
2025
-
[24]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2009. Measuring massive multitask language understanding, 2021. URL https://arxiv. org/abs, page 20
2009
-
[25]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[26]
Gang Hu, Ke Qin, Chenhan Yuan, Min Peng, Alejandro Lopez-Lira, Benyou Wang, Sophia Ananiadou, Jimin Huang, and Qianqian Xie. 2024. No language is an island: Unifying chinese and english in financial large language models, instruction data, and benchmarks. arXiv preprint arXiv:2403.06249
-
[27]
Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Yao Fu, and others . 2023. C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models. Advances in Neural Information Processing Systems, 36:62991--63010
2023
-
[28]
Huang Jiajia, Zhu Haoran, Xu Chao, Zhan Tianming, Xie Qianqian, and Huang Jimin. 2024. Auditwen: An open-source large language model for audit. In Proceedings of the 23rd Chinese National Conference on Computational Linguistics (Volume 1: Main Conference), pages 1351--1365
2024
-
[29]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. https://arxiv.org/abs/2310.0...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Michael Krumdick, Rik Koncel-Kedziorski, Viet Dac Lai, Varshini Reddy, Charles Lovering, and Chris Tanner. 2024. Bizbench: A quantitative reasoning benchmark for business and finance. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pages 8309--8332
2024
-
[31]
Yanyang Li, Jianqiao Zhao, Duo Zheng, Zi-Yuan Hu, Zhi Chen, Xiaohui Su, Yongfeng Huang, Shijia Huang, Dahua Lin, Michael Lyu, and others . 2023. Cleva: Chinese language models evaluation platform. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 186--217
2023
-
[32]
Mianxin Liu, Weiguo Hu, Jinru Ding, Jie Xu, Xiaoyang Li, Lifeng Zhu, Zhian Bai, Xiaoming Shi, Benyou Wang, Haitao Song, and others . 2024. Medbench: A comprehensive, standardized, and reliable benchmarking system for evaluating chinese medical large language models. Big Data Mining and Analytics, 7(4):1116--1128
2024
- [33]
-
[34]
Brian W Matthews. 1975. Comparison of the predicted and observed secondary structure of t4 phage lysozyme. Biochimica et Biophysica Acta (BBA)-Protein Structure, 405(2):442--451
1975
-
[35]
Ziyang Miao, Qiyu Sun, Jingyuan Wang, Yuchen Gong, Yaowei Zheng, Shiqi Li, and Richong Zhang. 2025. Easy dataset: A unified and extensible framework for synthesizing llm fine-tuning data from unstructured documents. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 960--968
2025
-
[36]
Louis Brulé Naudet. 2023. Livre des procédures fiscales, non-instruct (11-12-2023). https://hf-mirror.com/datasets/louisbrulenaudet/lpf
2023
-
[37]
John J Nay, David Karamardian, Sarah B Lawsky, Wenting Tao, Meghana Bhat, Raghav Jain, Aaron Travis Lee, Jonathan H Choi, and Jungo Kasai. 2024. Large language models as tax attorneys: a case study in legal capabilities emergence. Philosophical Transactions of the Royal Society A, 382(2270):20230159
2024
-
[38]
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. 2022. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. In Conference on health, inference, and learning, pages 248--260. PMLR
2022
-
[39]
Xueqing Peng, Triantafillos Papadopoulos, Efstathia Soufleri, Polydoros Giannouris, Ruoyu Xiang, Yan Wang, Lingfei Qian, Jimin Huang, Qianqian Xie, and Sophia Ananiadou. 2025. Plutus: Benchmarking large language models in low-resource greek finance. arXiv preprint arXiv:2502.18772. https://arxiv.org/abs/2502.18772
-
[40]
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. Squad: 100,000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383--2392
2016
-
[41]
Thomas Rixen and Brigitte Unger. 2022. Taxation: A regulatory multilevel governance perspective. Regulation & Governance, 16(3):621--633
2022
-
[42]
Daniel Steinigen, Marcin Namysl, Markus Hepperle, Jan Krekeler, and Susanne Landgraf. 2023. Semantic extraction of key figures and their properties from tax legal texts using neural models. In ASAIL@ ICAIL, pages 60--71
2023
-
[43]
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivi \`e re, Mihir Sanjay Kale, Juliette Love, and others . 2024. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, and Others . 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. 2018. Glue: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of the 2018 EMNLP workshop BlackboxNLP: Analyzing and interpreting neural networks for NLP, pages 353--355
2018
- [46]
-
[47]
Xidong Wang, Guiming Chen, Song Dingjie, Zhang Zhiyi, Zhihong Chen, Qingying Xiao, Junying Chen, Feng Jiang, Jianquan Li, Xiang Wan, and others . 2024. Cmb: A comprehensive medical benchmark in chinese. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 6...
2024
-
[48]
Qianqian Xie, Weiguang Han, Zhengyu Chen, Ruoyu Xiang, Xiao Zhang, and others . 2024. Finben: A holistic financial benchmark for large language models. Advances in Neural Information Processing Systems, 37:95716--95743
2024
-
[49]
Qianqian Xie, Weiguang Han, Xiao Zhang, Yanzhao Lai, Min Peng, Alejandro Lopez-Lira, and Jimin Huang. 2023. Pixiu: A comprehensive benchmark, instruction dataset and large language model for finance. Advances in Neural Information Processing Systems, 36:33469--33484
2023
- [50]
-
[51]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, and others . 2024. Qwen2 technical report. arXiv preprint arXiv:2407.10671
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Alex Young, Bei Chen, Chao Li, Chengen Huang, Ge Zhang, Guanwei Zhang, Guoyin Wang, Heng Li, Jiangcheng Zhu, Jianqun Chen, and others . 2024. Yi: Open foundation models by 01. ai. https://arxiv.org/abs/2403.04652
work page internal anchor Pith review arXiv 2024
-
[53]
Jingsi Yu, Junhui Zhu, Yujie Wang, Yang Liu, Hongxiang Chang, Jinran Nie, Cunliang Kong, R Chong, Xin Liu, Jiyuan An, and others . 2023. Taoli llama
2023
-
[54]
Wanlong Yu, Wei Wan, Zhenxu Wang, Feng Li, Kang Wang, and Gang Hu. 2025. Open bilingual benchmark and leaderboard for large language models in cybersecurity. In CCF International Conference on Natural Language Processing and Chinese Computing, pages 456--470. Springer
2025
-
[55]
Weizhe Yuan, Graham Neubig, and Pengfei Liu. 2021. Bartscore: Evaluating generated text as text generation. Advances in neural information processing systems, 34:27263--27277
2021
- [56]
- [57]
-
[58]
Hui Zeng, Jingyuan Xue, Meng Hao, Chen Sun, Bin Ning, and Na Zhang. 2024. Withdrawn: Evaluating the generation capabilities of large chinese language models
2024
- [59]
-
[60]
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. 2019. Bertscore: Evaluating text generation with bert. arXiv preprint arXiv:1904.09675
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [61]
- [62]
-
[63]
Yilong Zhao, Chien-Yu Lin, Kan Zhu, Zihao Ye, Lequn Chen, Size Zheng, Luis Ceze, Arvind Krishnamurthy, Tianqi Chen, and Baris Kasikci. 2024. Atom: Low-bit quantization for efficient and accurate llm serving. Proceedings of Machine Learning and Systems, 6:196--209
2024
-
[64]
Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, and Nan Duan. 2024. Agieval: A human-centric benchmark for evaluating foundation models. In Findings of the Association for Computational Linguistics: NAACL 2024, pages 2299--2314
2024
- [65]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.