Recognition: unknown
PinpointQA: A Dataset and Benchmark for Small Object-Centric Spatial Understanding in Indoor Videos
Pith reviewed 2026-05-10 16:36 UTC · model grok-4.3
The pith
PinpointQA is a new benchmark dataset that tests whether multimodal models can precisely locate and describe small objects in indoor videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
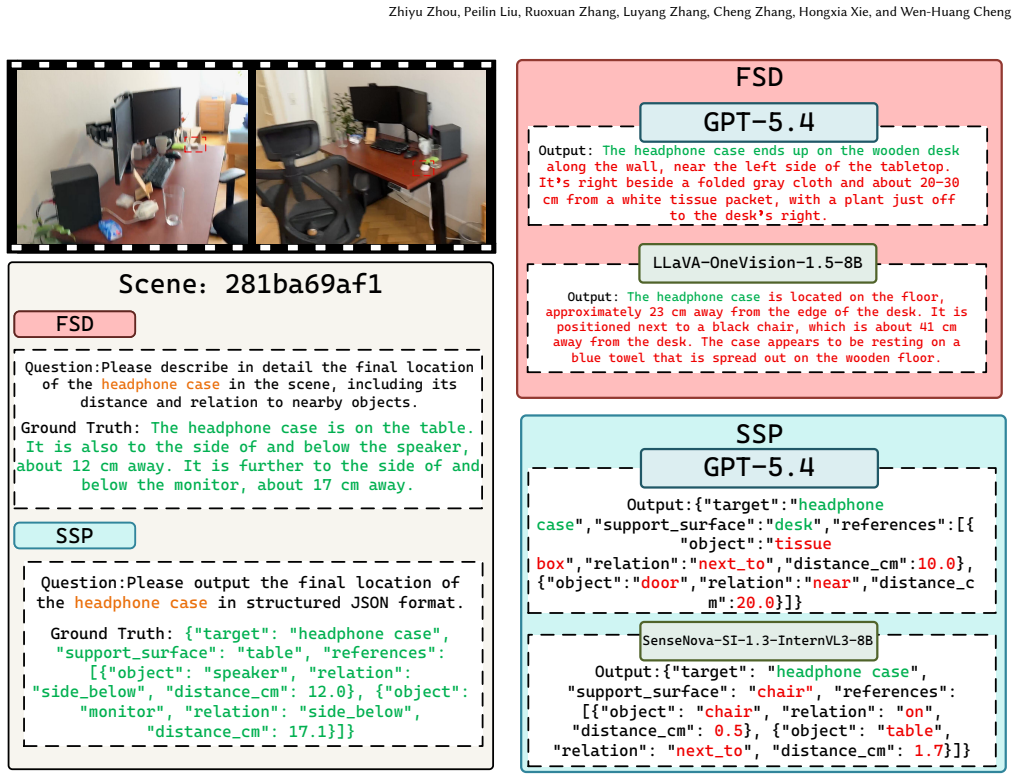
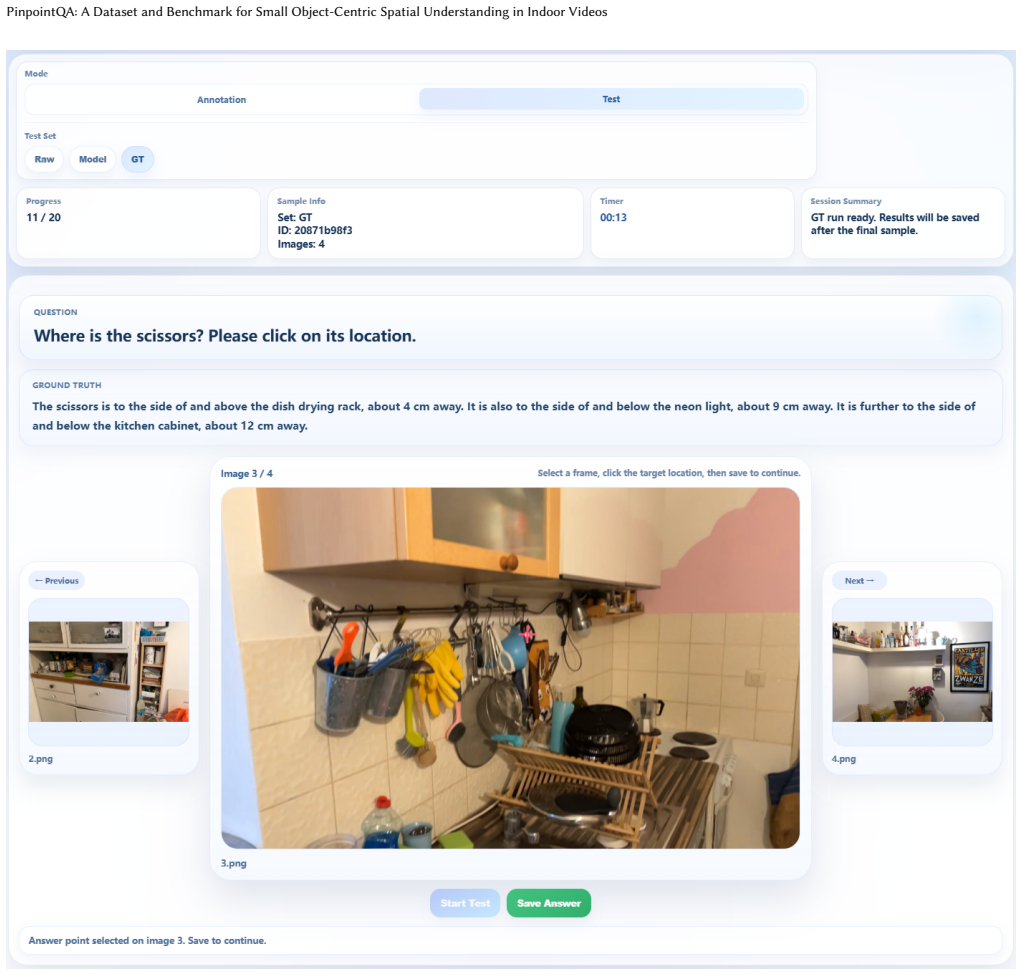
PinpointQA comprises 1,024 scenes and 10,094 QA pairs organized into four progressively challenging tasks: Target Presence Verification, Nearest Reference Identification, Fine-Grained Spatial Description, and Structured Spatial Prediction. Built from intermediate spatial representations in ScanNet++ and ScanNet200 with automatic QA generation and quality control, the benchmark reveals consistent capability gaps in current MLLMs along the progressive chain, with Structured Spatial Prediction remaining particularly difficult, while supervised fine-tuning yields substantial gains especially on harder tasks.
What carries the argument
The PinpointQA dataset, built from ScanNet++ and ScanNet200 with QA pairs generated automatically from intermediate spatial representations and refined by quality control, serving as both diagnostic benchmark and training resource across the four escalating tasks.
Load-bearing premise
The automatically generated QA pairs from intermediate spatial representations in ScanNet++ and ScanNet200 accurately reflect the requirements of small object-centric spatial understanding without introducing bias or missing practical needs.
What would settle it
A test in which models fine-tuned on PinpointQA show no measurable improvement on independent real-world indoor video tasks that require locating and describing small objects with precision usable for assistive applications.
Figures







read the original abstract
Small object-centric spatial understanding in indoor videos remains a significant challenge for multimodal large language models (MLLMs), despite its practical value for object search and assistive applications. Although existing benchmarks have advanced video spatial intelligence, embodied reasoning, and diagnostic perception, no existing benchmark directly evaluates whether a model can localize a target object in video and express its position with sufficient precision for downstream use. In this work, we introduce PinpointQA, the first dataset and benchmark for small object-centric spatial understanding in indoor videos. Built from ScanNet++ and ScanNet200, PinpointQA comprises 1,024 scenes and 10,094 QA pairs organized into four progressively challenging tasks: Target Presence Verification (TPV), Nearest Reference Identification (NRI), Fine-Grained Spatial Description (FSD), and Structured Spatial Prediction (SSP). The dataset is built from intermediate spatial representations, with QA pairs generated automatically and further refined through quality control. Experiments on representative MLLMs reveal a consistent capability gap along the progressive chain, with SSP remaining particularly difficult. Supervised fine-tuning on PinpointQA yields substantial gains, especially on the harder tasks, demonstrating that PinpointQA serves as both a diagnostic benchmark and an effective training dataset. The dataset and project page are available at https://rainchowz.github.io/PinpointQA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PinpointQA, the first dataset and benchmark for small object-centric spatial understanding in indoor videos. It comprises 1,024 scenes and 10,094 QA pairs derived from ScanNet++ and ScanNet200, organized into four progressively challenging tasks: Target Presence Verification (TPV), Nearest Reference Identification (NRI), Fine-Grained Spatial Description (FSD), and Structured Spatial Prediction (SSP). QA pairs are generated automatically from intermediate spatial representations with quality control. Experiments on representative MLLMs show consistent performance gaps along the task chain (with SSP hardest) and substantial gains from supervised fine-tuning on PinpointQA, positioning it as both a diagnostic benchmark and training resource.
Significance. If the QA pairs faithfully capture precise small-object spatial relations without systematic bias or error from the source representations, PinpointQA would address a clear gap in existing video spatial benchmarks by focusing on localization precision needed for downstream applications like object search. The progressive task design and SFT results could help diagnose and mitigate MLLM limitations in embodied reasoning scenarios.
major comments (2)
- [Abstract] Abstract and dataset construction description: The central claim that PinpointQA serves as a valid diagnostic benchmark revealing MLLM capability gaps (especially SSP) rests on the automatic QA generation from ScanNet spatial representations accurately reflecting small-object-centric relations. However, the quality control process is described only at a high level with no quantitative details on human verification scale, inter-annotator agreement for spatial precision, error rates in automatic generation, or comparison to manually authored QA pairs. This is load-bearing for interpreting the reported gaps and SFT gains.
- [Experiments] Experiments section: The claims of 'consistent capability gap along the progressive chain' and 'substantial gains' from SFT, especially on harder tasks, are presented without specific quantitative metrics, baselines, error analysis, or statistical significance in the summary. This limits assessment of whether the gaps are meaningful or if SFT improvements are robust across models and scenes.
minor comments (2)
- [Dataset Construction] Clarify the exact criteria and templates used for automatic QA generation to allow reproducibility and independent validation of the task definitions.
- Ensure the project page link and dataset release include the full generation code, quality control logs, and any human annotation guidelines for transparency.
Simulated Author's Rebuttal
We thank the referee for the positive summary and constructive feedback on our manuscript. We address the major comments point by point below, and will make revisions to incorporate additional details as suggested.
read point-by-point responses
-
Referee: [Abstract] Abstract and dataset construction description: The central claim that PinpointQA serves as a valid diagnostic benchmark revealing MLLM capability gaps (especially SSP) rests on the automatic QA generation from ScanNet spatial representations accurately reflecting small-object-centric relations. However, the quality control process is described only at a high level with no quantitative details on human verification scale, inter-annotator agreement for spatial precision, error rates in automatic generation, or comparison to manually authored QA pairs. This is load-bearing for interpreting the reported gaps and SFT gains.
Authors: We agree that more quantitative details on the quality control would strengthen the paper. In the revised manuscript, we will expand the dataset construction section to include specifics such as the number of QA pairs subjected to human review, inter-annotator agreement metrics (e.g., Cohen's kappa for spatial relation judgments), observed error rates from the automatic pipeline, and results from a manual validation subset compared to automatic outputs. This will provide better support for the benchmark's reliability. revision: yes
-
Referee: [Experiments] Experiments section: The claims of 'consistent capability gap along the progressive chain' and 'substantial gains' from SFT, especially on harder tasks, are presented without specific quantitative metrics, baselines, error analysis, or statistical significance in the summary. This limits assessment of whether the gaps are meaningful or if SFT improvements are robust across models and scenes.
Authors: We acknowledge the need for more explicit quantitative presentation. While the full experiments section contains detailed tables with per-task and per-model accuracies, we will revise the high-level summary and abstract to explicitly include key quantitative metrics, such as specific accuracy values showing the capability gaps and SFT gains, add any missing baseline comparisons, incorporate error analysis, and report statistical significance tests for the improvements. This will allow better assessment of the results. revision: yes
Circularity Check
No circularity: dataset/benchmark paper with no derivations or fitted predictions
full rationale
This paper introduces PinpointQA as a new dataset and benchmark built from ScanNet++ and ScanNet200 via automatic QA generation plus quality control. It contains no mathematical derivations, equations, first-principles results, or fitted parameters. The central claims concern dataset construction, progressive task difficulty (TPV→NRI→FSD→SSP), observed MLLM performance gaps, and gains from supervised fine-tuning. None of these reduce by construction to the paper's own inputs; they are empirical observations on an externally sourced dataset. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear in any derivation chain. The work is self-contained as a standard dataset paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ScanNet++ and ScanNet200 provide accurate intermediate spatial representations suitable for generating QA pairs for small object localization.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.