Recognition: unknown
EdgeFlow: Fast Cold Starts for LLMs on Mobile Devices
Pith reviewed 2026-05-10 17:00 UTC · model grok-4.3
The pith
EdgeFlow reduces mobile LLM cold-start latency by up to 4x through adaptive per-weight quantization that respects NPU hardware limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EdgeFlow demonstrates that an NPU-aware adaptive quantization algorithm, an SIMD-friendly packing format, and a synergistic granular pipeline together allow the cold-start phase of mobile LLM inference to load only the precision needed for each weight, cutting startup time by up to 4.07 times versus llama.cpp, MNN, and llm.npu while keeping end-to-end accuracy comparable.
What carries the argument
NPU-aware adaptive quantization that assigns different precisions to individual weights according to their estimated importance and the target NPU's data-type constraints.
If this is right
- Cold-start time becomes short enough for interactive mobile apps that must load the model on demand.
- Larger models can fit in the same flash footprint because lower-precision weights occupy less space during the initial load.
- The same importance map can be reused across multiple inferences without recomputation.
- Existing mobile inference engines could adopt the packing format to avoid format-conversion overhead on every launch.
Where Pith is reading between the lines
- The technique may generalize to other hardware accelerators whose native data types are also fixed-width.
- If importance scores prove stable across related tasks, the same map could support quick model switching on the device.
- Combining the method with runtime monitoring of actual accuracy could allow dynamic precision increases when needed.
Load-bearing premise
Parameter importance can be estimated reliably in advance and reducing precision on less important weights will not push end-to-end accuracy outside acceptable bounds on real NPUs.
What would settle it
Run the same model on a production mobile NPU, apply the importance-based precision map, and measure whether accuracy on standard benchmarks falls more than a few percent below the full-precision baseline.
Figures









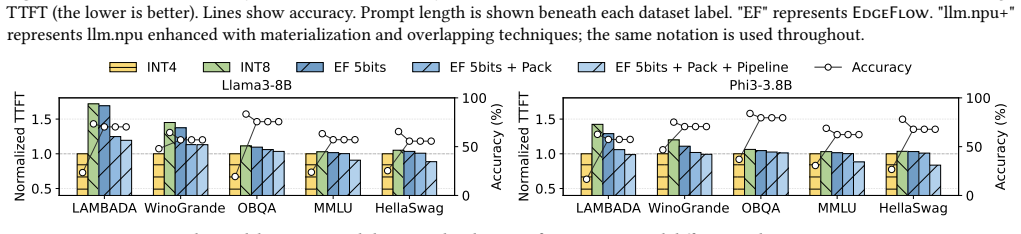


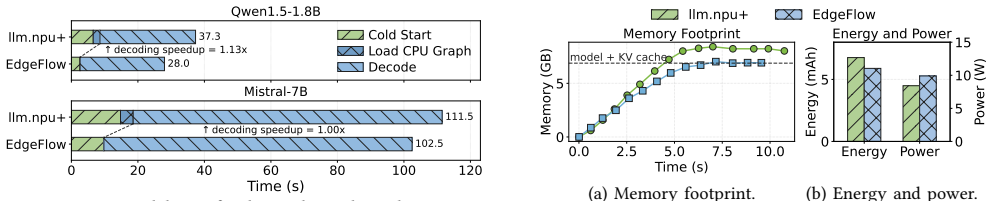


read the original abstract
Deploying large language models (LLMs) on mobile devices is an emerging trend to enable data privacy and offline accessibility of LLM applications. Modern mobile neural processing units (NPUs) make such deployment increasingly feasible. However, existing mobile LLM inference frameworks suffer from high start-up latency due to their inevitable cold starts, i.e., launching LLM inferences when the model is not hosted in device memory. In this paper, we identify the key bottleneck of mobile LLM cold starts as the waste of flash bandwidth on unimportant model parameters. We design EdgeFlow, a mobile LLM inference framework that mitigates the cold start issue by adaptively adjusting the precisions of LLM parameters. Specifically, EdgeFlow leverages 1) an NPU-aware adaptive quantization algorithm that assigns different precisions to weights in a finer granularity according to their importance and NPU constraints, 2) an SIMD-friendly packing format that accelerates the transformation of various-precision weights into fixed-sized NPU-native data types, and 3) a synergistic granular pipeline that coordinates CPU and NPU computation in a fine-grained and dynamic manner. Experimental results show that EdgeFlow reduces cold-start latency by up to 4.07x compared with three state-of-the-art mobile LLM inference frameworks, i.e., llama.cpp, MNN, and llm.npu, under comparable model accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EdgeFlow, a mobile LLM inference framework that targets high cold-start latency caused by flash bandwidth waste on unimportant parameters. It proposes an NPU-aware adaptive quantization algorithm to assign varying precisions to weights based on importance and NPU constraints, an SIMD-friendly packing format for efficient data transformation, and a granular CPU-NPU pipeline. The central claim is that these techniques yield up to 4.07x lower cold-start latency versus llama.cpp, MNN, and llm.npu while preserving comparable model accuracy.
Significance. If the experimental claims are substantiated, the work addresses a practical deployment barrier for on-device LLMs, enabling faster startup for privacy-preserving and offline applications on NPUs. The selective bandwidth reduction via importance-aware quantization offers a hardware-targeted optimization that could influence future mobile inference systems.
major comments (2)
- [Abstract] Abstract: The headline result of a 4.07x cold-start latency reduction is stated without any accompanying experimental methodology, model sizes, datasets, hardware platforms, run counts, or error bars. This absence directly undermines verification of the performance claim and its robustness under the stated comparable-accuracy condition.
- [Abstract] Abstract: The NPU-aware adaptive quantization is asserted to maintain 'comparable model accuracy' by reducing precision on low-importance weights, yet no per-layer accuracy degradation figures, sensitivity analysis, or NPU-specific validation of the importance estimator are supplied. Because the latency gain depends on loading fewer bytes without accuracy loss, this unverified link is load-bearing for the central result.
minor comments (1)
- [Abstract] The abstract would benefit from a single sentence naming the LLM model sizes and mobile NPU platforms used in the reported experiments to give immediate context to the 4.07x figure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that the abstract can be strengthened to better support the central claims and have revised it accordingly while preserving conciseness. Below we respond point by point.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline result of a 4.07x cold-start latency reduction is stated without any accompanying experimental methodology, model sizes, datasets, hardware platforms, run counts, or error bars. This absence directly undermines verification of the performance claim and its robustness under the stated comparable-accuracy condition.
Authors: We agree that the abstract would benefit from a concise summary of the evaluation setup to allow readers to contextualize the 4.07x claim. The full experimental methodology, including model sizes, datasets for accuracy evaluation, target hardware platforms, run counts, and statistical reporting, is presented in detail in Sections 5 and 6. In the revised manuscript we have updated the abstract to include a brief statement of the setup (e.g., representative LLM sizes, mobile NPU hardware, and averaged results with variability). revision: yes
-
Referee: [Abstract] Abstract: The NPU-aware adaptive quantization is asserted to maintain 'comparable model accuracy' by reducing precision on low-importance weights, yet no per-layer accuracy degradation figures, sensitivity analysis, or NPU-specific validation of the importance estimator are supplied. Because the latency gain depends on loading fewer bytes without accuracy loss, this unverified link is load-bearing for the central result.
Authors: We acknowledge that the abstract does not explicitly reference the supporting accuracy analysis. The manuscript contains per-layer accuracy degradation results, sensitivity analysis of the importance estimator, and NPU-specific validation experiments (detailed in Section 4 and the evaluation section). In the revised abstract we have added a short clause noting that accuracy is preserved as confirmed by these analyses, directing readers to the relevant sections for the figures and validation. revision: yes
Circularity Check
No circularity; results rest on external experimental comparison
full rationale
The paper's core claim is an empirical 4.07x cold-start latency reduction measured directly against three independent external frameworks (llama.cpp, MNN, llm.npu) under comparable accuracy. No equations, parameter fits, self-definitions, or derivation steps appear in the abstract or description that reduce to the inputs by construction. The techniques (NPU-aware quantization, SIMD packing, granular pipeline) are presented as engineering contributions whose efficacy is validated externally rather than assumed or renamed from prior internal results. This satisfies the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM weights vary in importance such that lower precision on less-important weights preserves overall accuracy
Reference graph
Works this paper leans on
-
[1]
Mistral 7B
2023. Mistral 7B. https://huggingface.co/mistralai/Mistral-7B-Instruct- v0.3. https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.3
2023
-
[2]
Qwen1.5 1.8B
2023. Qwen1.5 1.8B. https://huggingface.co/Qwen/Qwen1.5-1.8B- Chat. https://huggingface.co/Qwen/Qwen1.5-1.8B-Chat
2023
-
[3]
Llama 8B
2024. Llama 8B. https://huggingface.co/meta-llama/Meta-Llama-3- 8B-Instruct. https://huggingface.co/meta-llama/Meta-Llama-3-8B- Instruct
2024
-
[4]
Phi3 3.8B
2024. Phi3 3.8B. https://huggingface.co/microsoft/Phi-3-mini-4k- instruct. https://huggingface.co/microsoft/Phi-3-mini-4k-instruct
2024
-
[5]
Gulavani, Alexey Tumanov, and Ramachandran Ramjee
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S. Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve. InProceedings of the 18th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2024, Santa Clara, USA. USENIX Association, 117–...
2024
-
[6]
Keivan Alizadeh, Iman Mirzadeh, Dmitry Belenko, S. Khatamifard, Minsik Cho, Carlo C. del Mundo, Mohammad Rastegari, and Mehrdad Farajtabar. 2024. LLM in a Flash: Efficient Large Language Model Inference with Limited Memory. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok,...
-
[7]
Android Open Source Project. 2023. Low Memory Killer Daemon. https://source.android.com/docs/core/perf/lmkd
2023
-
[8]
Apple Developer Documentation. 2024. Reducing Terminations in Your App. https://developer.apple.com/documentation/xcode/reduce- terminations-in-your-app
2024
-
[9]
Ioannis Arapakis, Souneil Park, and Martin Pielot. 2021. Impact of Response Latency on User Behaviour in Mobile Web Search. InCHIIR ’21: ACM SIGIR Conference on Human Information Interaction and Re- trieval, Canberra, ACT, Australia, March 14-19, 2021, Falk Scholer, Paul Thomas, David Elsweiler, Hideo Joho, Noriko Kando, and Catherine Smith (Eds.). ACM, 2...
-
[10]
Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L. Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. 2024. QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, Ca...
2024
-
[11]
Ron Banner, Itay Hubara, Elad Hoffer, and Daniel Soudry. 2018. Scal- able Methods for 8-bit Training of Neural Networks. InAdvances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montréal, Canada. 5151–5159. https://proceedings.neurips.cc/paper/2018/hash/e82c4b1 9b8151ddc25d4d93b...
2018
-
[12]
Rune Birkmose, Nathan Mørkeberg Reece, Esben Hofstedt Norvin, Johannes Bjerva, and Mike Zhang. 2025. On-Device LLMs for Home Assistant: Dual Role in Intent Detection and Response Generation. (2025), 57–67. https://aclanthology.org/2025.wnut-1.7/
2025
-
[13]
Le Chen, Dahu Feng, Erhu Feng, Yingrui Wang, Rong Zhao, Yubin Xia, Pinjie Xu, and Haibo Chen. 2025. Characterizing Mobile SoC for Accelerating Heterogeneous LLM Inference. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles, SOSP 2025, Lotte Hotel World, Seoul, Republic of Korea. ACM, 359–374. https: //doi.org/10.1145/3731569.3764808
-
[14]
Zihan Chen, Bike Xie, Jundong Li, and Cong Shen. 2024. Channel- Wise Mixed-Precision Quantization for Large Language Models.CoRR abs/2410.13056 (2024). https://doi.org/10.48550/arXiv.2410.13056
-
[15]
Justin Cosentino, Anastasiya Belyaeva, Xin Liu, Nicholas A. Furlotte, Zhun Yang, Chace Lee, Erik Schenck, Yojan Patel, Jian Cui, Logan Dou- glas Schneider, Robby Bryant, Ryan G. Gomes, Allen Jiang, Roy Lee, Yun Liu, Javier Perez Matos, Jameson K. Rogers, Cathy Speed, Shyam A. Tailor, Megan Walker, Jeffrey Yu, Tim Althoff, Conor Heneghan, John Hernandez, M...
-
[16]
Arm Developer. 2025. Arm Neon. https://developer.arm.com/Architec tures/Neon. Referenced December 2025
2025
-
[17]
Cathy Mengying Fang, Valdemar Danry, Nathan Whitmore, Andria Bao, Andrew Hutchison, Cayden Pierce, and Pattie Maes. 2024. Physi- oLLM: Supporting Personalized Health Insights with Wearables and Large Language Models. InIEEE EMBS International Conference on Biomedical and Health Informatics, BHI 2024, Houston, USA. IEEE, 1–8. https://doi.org/10.1109/BHI626...
-
[18]
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh
-
[19]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
GPTQ: Accurate Post-Training Quantization for Generative Pre-Trained Transformers.CoRRabs/2210.17323 (2022). https: //doi.org/10.48550/arXiv.2210.17323
work page internal anchor Pith review doi:10.48550/arxiv.2210.17323 2022
-
[20]
Yao Fu, Leyang Xue, Yeqi Huang, Andrei-Octavian Brabete, Dmitrii Ustiugov, Yuvraj Patel, and Luo Mai. 2024. ServerlessLLM: Low- Latency Serverless Inference for Large Language Models. InProceed- ings of the 18th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2024, Santa Clara, USA. USENIX Association, 135–153. https://www.usenix.org...
2024
-
[21]
Ggerganov. 2023. llama.cpp - LLM Inference in C/C++. https://github .com/ggerganov/llama.cpp. Referenced November 2025. 13
2023
-
[22]
Zixu Hao, Jianyu Wei, Tuowei Wang, Minxing Huang, Huiqiang Jiang, Shiqi Jiang, Ting Cao, and Ju Ren. 2025. Scaling LLM Test-Time Com- pute with Mobile NPU on Smartphones.CoRRabs/2509.23324 (2025). https://doi.org/10.48550/arXiv.2509.23324
-
[23]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring Massive Multitask Language Understanding. InProceedings of the 9th Interna- tional Conference on Learning Representations, ICLR 2021, Virtual Event, Austria. OpenReview.net. https://openreview.net/forum?id=d7KBjm I3GmQ
2021
-
[24]
Jiacheng Huang, Yunmo Zhang, Junqiao Qiu, Yu Liang, Rachata Ausavarungnirun, Qingan Li, and Chun Jason Xue. 2024. More Apps, Faster Hot-Launch on Mobile Devices via Fore/Background-aware GC-Swap Co-design. InProceedings of the 29th ACM International Con- ference on Architectural Support for Programming Languages and Oper- ating Systems, Volume 3, ASPLOS 2...
-
[25]
Wei Huang, Haotong Qin, Yangdong Liu, Yawei Li, Qinshuo Liu, Xian- glong Liu, Luca Benini, Michele Magno, Shiming Zhang, and Xiaojuan Qi. 2025. SliM-LLM: Salience-Driven Mixed-Precision Quantization for Large Language Models. InForty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025 (Proceedings of Mac...
2025
-
[26]
Apple Inc. 2025. Apple A19: Specs and Benchmarks. https://nanorevi ew.net/en/soc/apple-a19. Referenced November 2025
2025
-
[27]
Qualcomm Technologies Inc. 2025. Qualcomm AI Engine Direct SDK. https://developer.qualcomm.com/software/qualcomm-ai-engine- direct-sdk. Referenced November 2025
2025
-
[28]
Qualcomm Technologies Inc. 2025. Qualcomm Hexagon NPU - Pow- ering the Generative AI Revolution. https://www.qualcomm.com/pro cessors/hexagon. Referenced November 2025
2025
-
[29]
Yongsoo Joo, Junhee Ryu, Sangsoo Park, and Kang G. Shin. 2011. FAST: Quick Application Launch on Solid-State Drives. In9th USENIX Con- ference on File and Storage Technologies, San Jose, CA, USA, February 15-17, 2011. USENIX, 259–272. http://www.usenix.org/events/fast11/t ech/techAbstracts.html#Joo
2011
-
[30]
Evan King, Haoxiang Yu, Sangsu Lee, and Christine Julien. 2024. Sasha: Creative Goal-Oriented Reasoning in Smart Homes with Large Lan- guage Models.Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 8, 1 (2024), 12:1–12:38. https://doi.org/10.1145/3643505
-
[31]
Sha, and Xuehai Zhou
Changlong Li, Zongwei Zhu, Chao Wang, Fangming Liu, Fei Xu, Ed- win H.-M. Sha, and Xuehai Zhou. 2025. Archer: Adaptive Memory Compression with Page-Association-Rule Awareness for High-Speed Response of Mobile Devices. In23rd USENIX Conference on File and Storage Technologies, FAST 2025, Santa Clara, CA, February 25-27, 2025. USENIX Association, 497–511. h...
2025
-
[32]
Luchang Li, Sheng Qian, Jie Lu, Lunxi Yuan, Rui Wang, and Qin Xie
-
[33]
arXiv:2403.20041 doi:10.48550/ARXIV.2403.20041
Transformer-Lite: High-Efficiency Deployment of Large Lan- guage Models on Mobile Phone GPUs.CoRRabs/2403.20041 (2024). arXiv:2403.20041 doi:10.48550/ARXIV.2403.20041
-
[34]
Shiyao Li, Xuefei Ning, Ke Hong, Tengxuan Liu, Luning Wang, Xi- uhong Li, Kai Zhong, Guohao Dai, Huazhong Yang, and Yu Wang. 2023. LLM-Mq: Mixed-Precision Quantization for Efficient LLM Deployment. InThe Efficient Natural Language and Speech Processing Workshop with NeurIPS, Vol. 9. 3
2023
-
[35]
Wentong Li, Li-Pin Chang, Yu Mao, and Liang Shi. 2025. PMR: Fast Application Response via Parallel Memory Reclaim on Mobile Devices. InProceedings of the 2025 USENIX Annual Technical Conference, USENIX ATC 2025, Boston, USA. USENIX Association, 1569–1584. https://ww w.usenix.org/conference/atc25/presentation/li-wentong
2025
-
[36]
Yu Liang, Jinheng Li, Rachata Ausavarungnirun, Riwei Pan, Liang Shi, Tei-Wei Kuo, and Chun Jason Xue. 2020. Acclaim: Adaptive Memory Reclaim to Improve User Experience in Android Systems. In Proceedings of the 2020 USENIX Annual Technical Conference, USENIX ATC 2020, July 15-17, 2020. USENIX Association, 897–910. https: //www.usenix.org/conference/atc20/p...
2020
-
[37]
Yu Liang, Aofeng Shen, Chun Jason Xue, Riwei Pan, Haiyu Mao, Nika Mansouri-Ghiasi, Qingcai Jiang, Rakesh Nadig, Lei Li, Rachata Ausavarungnirun, Mohammad Sadrosadati, and Onur Mutlu. 2025. Ariadne: A Hotness-Aware and Size-Adaptive Compressed Swap Tech- nique for Fast Application Relaunch and Reduced CPU Usage on Mo- bile Devices. InIEEE International Sym...
-
[38]
Geunsik Lim, Donghyun Kang, MyungJoo Ham, and Young Ik Eom
-
[39]
SWAM: Revisiting Swap and OOMK for Improving Application Responsiveness on Mobile Devices. InProceedings of the 29th Annual International Conference on Mobile Computing and Networking, ACM MobiCom 2023, Madrid, Spain. ACM, 16:1–16:15. https://doi.org/10.1 145/3570361.3592518
-
[40]
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. 2024. AWQ: Activation-Aware Weight Quantization for On-Device LLM Compression and Acceleration. InProceedings of the Seventh Annual Conference on Machine Learning and Systems, MLSys 2024, Santa Clara, USA. mlsys.org. https:/...
2024
-
[41]
Lian Liu, Long Cheng, Haimeng Ren, Zhaohui Xu, Yudong Pan, Mengdi Wang, Xiaowei Li, Yinhe Han, and Ying Wang. 2025. COMET: Towards Practical W4A4KV4 LLMs Serving. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ASPLOS 2025, Rotterdam, Netherlands. ACM, 131–146. http...
-
[42]
Yifei Liu, Jicheng Wen, Yang Wang, Shengyu Ye, Li Lyna Zhang, Ting Cao, Cheng Li, and Mao Yang. 2024. VPTQ: Extreme Low-Bit Vector Post-Training Quantization for Large Language Models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Pro- cessing, EMNLP 2024, Miami, USA. Association for Computational Lin- guistics, 8181–8196. ...
-
[43]
Chiheng Lou, Sheng Qi, Chao Jin, Dapeng Nie, Haoran Yang, Xuanzhe Liu, and Xin Jin. 2025. Towards Swift Serverless LLM Cold Starts with ParaServe.CoRRabs/2502.15524 (2025). https://doi.org/10.48550/arX iv.2502.15524
-
[44]
Xudong Lu, Yinghao Chen, Cheng Chen, Hui Tan, Boheng Chen, Yina Xie, Rui Hu, Guanxin Tan, Renshou Wu, Yan Hu, Yi Zeng, Lei Wu, Liuyang Bian, Zhaoxiong Wang, Long Liu, Yanzhou Yang, Han Xiao, Aojun Zhou, Yafei Wen, Xiaoxin Chen, Shuai Ren, and Hongsheng Li
-
[45]
InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, USA
BlueLM-V-3B: Algorithm and System Co-Design for Multimodal Large Language Models on Mobile Devices. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, USA. Computer Vision Foundation / IEEE, 4145–4155. https://op enaccess.thecvf.com/content/CVPR2025/html/Lu_BlueLM-V- 3B_Algorithm_and_System_Co-Design_for_Multimodal_Lar...
2025
-
[46]
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher
-
[47]
InProcedings of the 5th In- ternational Conference on Learning Representations, ICLR 2017, Toulon, France
Pointer Sentinel Mixture Models. InProcedings of the 5th In- ternational Conference on Learning Representations, ICLR 2017, Toulon, France. OpenReview.net. https://openreview.net/forum?id=Byj72udxe
2017
-
[48]
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal
-
[49]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium. Association for Computational Linguistics, 2381–2391. https://doi.or g/10.18653/v1/d18-1260 14
-
[50]
Jakob Nielsen. 1993. Response Times: the Three Important Limits. Usability Engineering(1993)
1993
-
[51]
Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Quan Ngoc Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. 2016. The LAMBADA Dataset: Word Prediction Requiring a Broad Discourse Context. InProceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2...
-
[52]
Shin, and Kyungtae Kang
Junhee Ryu, Dongeun Lee, Kang G. Shin, and Kyungtae Kang. 2023. Fast Application Launch on Personal Computing/Communication De- vices. InProceedings of the 21st USENIX Conference on File and Storage Technologies, FAST 2023, Santa Clara, USA. USENIX Association, 425–
2023
-
[53]
https://www.usenix.org/conference/fast23/presentation/ryu
-
[54]
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2020. WinoGrande: An Adversarial Winograd Schema Challenge at Scale. InThe Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, New York, USA. AAAI Press, 8732–8740. https://doi.org/ 10.1609/aaai.v34i05.6399
-
[55]
Utkarsh Saxena, Sayeh Sharify, Kaushik Roy, and Xin Wang. 2025. ResQ: Mixed-Precision Quantization of Large Language Models with Low-Rank Residuals. InForty-second International Conference on Ma- chine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025 (Proceedings of Machine Learning Research). PMLR / OpenReview.net. https://proceedings.mlr.pre...
2025
-
[56]
Lee, and Hongil Yoon
Sam Son, Seung Yul Lee, Yunho Jin, Jonghyun Bae, Jinkyu Jeong, Tae Jun Ham, Jae W. Lee, and Hongil Yoon. 2021. ASAP: Fast Mobile Application Switch via Adaptive Prepaging. InProceedings of the 2021 USENIX Annual Technical Conference, USENIX ATC 2021. USENIX As- sociation, 365–380. https://www.usenix.org/conference/atc21/presen tation/son
2021
-
[57]
Junyang Wang, Haiyang Xu, Haitao Jia, Xi Zhang, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. 2024. Mobile-Agent-v2: Mobile Device Operation Assistant with Effective Navigation via Multi- Agent Collaboration. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024...
-
[58]
Junyang Wang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. 2024. Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception.CoRR abs/2401.16158 (2024). https://doi.org/10.48550/arXiv.2401.16158
-
[59]
Zhaode Wang, Jingbang Yang, Xinyu Qian, Shiwen Xing, Xiaotang Jiang, Chengfei Lv, and Shengyu Zhang. 2024. MNN-LLM: A Generic Inference Engine for Fast Large Language Model Deployment on Mobile Devices. InProceedings of the 6th ACM International Con- ference on Multimedia in Asia Workshops (MMAsia ’24 Workshops). Association for Computing Machinery, Artic...
-
[60]
Xingda Wei, Zhuobin Huang, Tianle Sun, Yingyi Hao, Rong Chen, Mingcong Han, Jinyu Gu, and Haibo Chen. 2025. PhoenixOS: Concur- rent OS-Level GPU Checkpoint and Restore with Validated Speculation. InProceedings of the ACM SIGOPS 31st Symposium on Operating Sys- tems Principles, SOSP 2025, Lotte Hotel World, Seoul, Republic of Korea. ACM, 996–1013. https://...
-
[61]
Hao Wen, Yuanchun Li, Guohong Liu, Shanhui Zhao, Tao Yu, Toby Jia- Jun Li, Shiqi Jiang, Yunhao Liu, Yaqin Zhang, and Yunxin Liu. 2024. AutoDroid: LLM-Powered Task Automation in Android. InProceedings of the 30th Annual International Conference on Mobile Computing and Networking, ACM MobiCom 2024, Washington D.C., USA. ACM, 543–557. https://doi.org/10.1145...
-
[62]
Guangxuan Xiao, Ji Lin, Mickaël Seznec, Hao Wu, Julien Demouth, and Song Han. 2023. SmoothQuant: Accurate and Efficient Post- Training Quantization for Large Language Models. InInternational Conference on Machine Learning, ICML 2023, Honolulu, USA (Proceed- ings of Machine Learning Research, Vol. 202). PMLR, 38087–38099. https://proceedings.mlr.press/v202...
2023
-
[63]
Li Xiaochen, Liu Sicong, Guo Bin, Ouyang Yu, Wu Fengmin, Xu Yuan, and Yu Zhiwen. 2026. AppFlow: Memory Scheduling for Cold Launch of Large Apps on Mobile and Vehicle Systems. InProceedings of the 32th Annual International Conference on Mobile Computing and Networking, ACM MobiCom 2026, Austin, Texas, USA. ACM. https://doi.org/10.114 5/3795866.3796690
-
[64]
Xiaomi. 2024. Xiaomi 15 Pro Full Specifications. Xiaomitime.com. https://xiaomitime.com/smartphones/xiaomi-15-pro Referenced November 2025
2024
-
[65]
Daliang Xu, Hao Zhang, Liming Yang, Ruiqi Liu, Gang Huang, Meng- wei Xu, and Xuanzhe Liu. 2025. Fast On-Device LLM Inference with NPUs. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS 2025, Rotterdam, The Netherlands. ACM, 445–462. https://doi.org/10.1145/3669940.3707239
-
[66]
Zhenliang Xue, Yixin Song, Zeyu Mi, Le Chen, Yubin Xia, and Haibo Chen. 2024. PowerInfer-2: Fast Large Language Model Inference on a Smartphone.CoRRabs/2406.06282 (2024). https://doi.org/10.48550/a rXiv.2406.06282
work page doi:10.48550/a 2024
-
[67]
Tingxin Yan, David Chu, Deepak Ganesan, Aman Kansal, and Jie Liu. 2012. Fast app launching for mobile devices using predictive user context. InThe 10th International Conference on Mobile Systems, Applications, and Services, MobiSys’12, Ambleside, United Kingdom - June 25 - 29, 2012. ACM, 113–126. https://doi.org/10.1145/2307636.23 07648
-
[68]
Rongjie Yi, Ting Cao, Ao Zhou, Xiao Ma, Shangguang Wang, and Mengwei Xu. 2023. Boosting DNN Cold Inference on Edge Devices. InProceedings of the 21st Annual International Conference on Mobile Systems, Applications and Services, MobiSys 2023, Helsinki, Finland. ACM, 516–529. https://doi.org/10.1145/3581791.3596842
-
[69]
Wangsong Yin, Daliang Xu, Mengwei Xu, Gang Huang, and Xu- anzhe Liu. 2025. Dynamic Sparse Attention on Mobile SoCs.CoRR abs/2508.16703 (2025). https://doi.org/10.48550/arXiv.2508.16703
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.16703 2025
- [70]
-
[71]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. HellaSwag: Can a Machine Really Finish Your Sen- tence?. InProceedings of the 57th Conference of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2019, Flo- rence, Italy. Association for Computational Linguistics, 4791–4800. https://doi.org/10.18653/v1/p19-1472
-
[72]
Shaoxun Zeng, Minhui Xie, Shiwei Gao, Youmin Chen, and Youyou Lu. 2025. Medusa: Accelerating Serverless LLM Inference with Ma- terialization. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1, ASPLOS 2025, Rotterdam, The Netherlands. ACM, 653–668. https://doi.org/10.11...
-
[73]
Cheng Zhang, Erhu Feng, Xi Zhao, Yisheng Zhao, Wangbo Gong, Jiahui Sun, Dong Du, Zhichao Hua, Yubin Xia, and Haibo Chen. 2025. MobiAgent: A Systematic Framework for Customizable Mobile Agents. CoRRabs/2509.00531 (2025). https://doi.org/10.48550/arXiv.2509.00531
-
[74]
Dingyan Zhang, Haotian Wang, Yang Liu, Xingda Wei, Yizhou Shan, Rong Chen, and Haibo Chen. 2025. BlitzScale: Fast and Live Large Model Autoscaling with O(1) Host Caching. InProceedings of the 19th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2025, Boston, USA. USENIX Association, 275–293. https://www. 15 usenix.org/conference/osdi...
2025
-
[75]
Tianyu Zhang, Lei Zhu, Qian Zhao, and Kilho Shin. 2019. Neural Net- works Weights Quantization: Target None-Retraining Ternary (TNT). InFifth Workshop on Energy Efficient Machine Learning and Cognitive Computing - NeurIPS Edition, EMC2@NeurIPS 2019, Vancouver, Canada. IEEE, 62–65. https://doi.org/10.1109/EMC2-NIPS53020.2019.00022
-
[76]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhang- hao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing System...
2023
-
[77]
First, we analyze the numerator: 𝑊·𝑊 ′ =𝑊· (𝑊−𝐸)=𝑊·𝑊−𝑊·𝐸=∥𝑊∥ 2 −𝑊·𝐸
-
[78]
Second, we analyze the norm of 𝑊 ′ in the denomina- tor: ∥𝑊 ′ ∥2 =(𝑊−𝐸) · (𝑊−𝐸)=∥𝑊∥ 2 −2𝑊·𝐸+ ∥𝐸∥ 2 To simplify, we adopt two standard assumptions in quan- tization analysis: 1.Small error energy:∥𝐸∥ 2 ≪ ∥𝑊∥ 2
-
[79]
Uncorrelated error: 𝐸 is approximately uncorrelated with𝑊, i.e.,E[𝑊·𝐸] ≈0. Under these assumptions, the denominator can be ex- panded using a first-order Taylor approximation: ∥𝑊 ′ ∥= √︁ ∥𝑊∥ 2 −2𝑊·𝐸+ ∥𝐸∥ 2 ≈ √︁ ∥𝑊∥ 2 + ∥𝐸∥ 2 (since𝑊·𝐸≈0) =∥𝑊∥ √︄ 1+ ∥𝐸∥ 2 ∥𝑊∥ 2 ≈ ∥𝑊∥ 1+ ∥𝐸∥ 2 2∥𝑊∥ 2 (for small∥𝐸∥ 2). Substituting back, the cosine similarity becomes cos𝜃≈ ∥...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.