Recognition: unknown
Few-Shot Contrastive Adaptation for Audio Abuse Detection in Low-Resource Indic Languages
Pith reviewed 2026-05-10 17:17 UTC · model grok-4.3
The pith
CLAP audio representations enable competitive abusive speech detection in ten Indic languages with few-shot projection adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CLAP yields strong cross-lingual audio representations across ten Indic languages, and lightweight projection-only adaptation achieves competitive performance with respect to fully supervised systems trained on complete training data. The benefits of few-shot adaptation are language-dependent and not monotonic with shot size.
What carries the argument
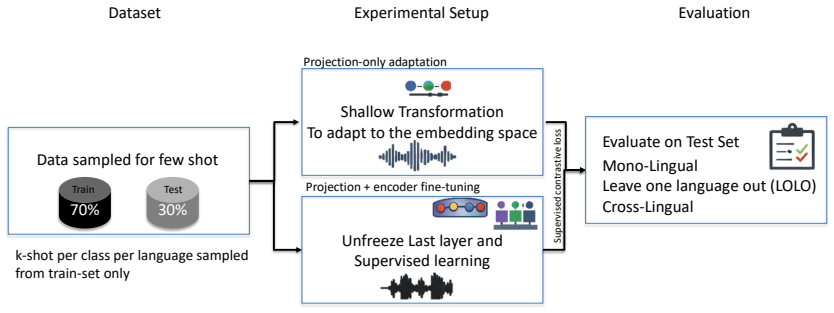
Few-shot supervised contrastive adaptation of CLAP audio embeddings via projection-only layers for direct audio classification of abuse.
If this is right
- CLAP embeddings transfer effectively across the ten Indic languages in ADIMA for abusive speech tasks.
- Projection-only adaptation reaches parity with models trained on the full labeled training set.
- Zero-shot CLAP prompting provides a usable baseline in the same cross-lingual setups.
- Few-shot gains depend on the target language and do not reliably rise as the number of shots increases.
Where Pith is reading between the lines
- Direct audio models could reduce error propagation from ASR in multilingual abuse detection pipelines.
- The same lightweight adaptation pattern may apply to other low-resource language families beyond Indic ones.
- Retaining prosodic cues in audio could help distinguish nuanced forms of abuse such as sarcasm that text alone misses.
Load-bearing premise
The ADIMA dataset contains representative examples of real-world abusive speech whose cross-lingual transfer and few-shot gains will hold for new speakers, recording conditions, and unseen languages without extra tuning.
What would settle it
Testing the adapted CLAP model on audio from an additional Indic language or mismatched recording conditions and finding detection accuracy falls substantially below the full-supervision baseline.
Figures





read the original abstract
Abusive speech detection is becoming increasingly important as social media shifts towards voice-based interaction, particularly in multilingual and low-resource settings. Most current systems rely on automatic speech recognition (ASR) followed by text-based hate speech classification, but this pipeline is vulnerable to transcription errors and discards prosodic information carried in speech. We investigate whether Contrastive Language-Audio Pre-training (CLAP) can support abusive speech detection directly from audio. Using the ADIMA dataset, we evaluate CLAP-based representations under few-shot supervised contrastive adaptation in cross-lingual and leave-one-language-out settings, with zero-shot prompting included as an auxiliary analysis. Our results show that CLAP yields strong cross-lingual audio representations across ten Indic languages, and that lightweight projection-only adaptation achieves competitive performance with respect to fully supervised systems trained on complete training data. However, the benefits of few-shot adaptation are language-dependent and not monotonic with shot size. These findings suggest that contrastive audio-text models provide a promising basis for cross-lingual audio abuse detection in low-resource settings, while also indicating that transfer remains incomplete and language-specific in important ways.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates the use of Contrastive Language-Audio Pre-training (CLAP) for direct audio-based abusive speech detection in ten low-resource Indic languages from the ADIMA dataset. It evaluates zero-shot prompting alongside few-shot supervised contrastive adaptation (projection-only) in cross-lingual and leave-one-language-out settings, claiming that CLAP yields strong cross-lingual audio representations and that the lightweight adaptation achieves competitive performance relative to fully supervised systems trained on complete data, while noting that few-shot benefits are language-dependent and non-monotonic with shot count.
Significance. If the results hold under rigorous controls, the work is significant for showing that pre-trained contrastive audio-text models can enable effective audio abuse detection without ASR pipelines in multilingual low-resource scenarios. The leave-one-language-out protocol and explicit analysis of language-dependent effects are strengths that provide falsifiable, empirical evidence for transfer limits. The paper appropriately tempers its claims rather than overgeneralizing. The skeptic concern about intra-family similarities among Indic languages does not undermine the core contribution, as the evaluation is scoped to this group and the non-monotonic results already signal incomplete transfer.
major comments (2)
- [Abstract and §5] Abstract and §5 (results): the central claim that 'lightweight projection-only adaptation achieves competitive performance with respect to fully supervised systems' is load-bearing but unsupported by any numeric metrics, exact baseline descriptions, error bars, or statistical tests in the provided text; without these the competitiveness cannot be verified.
- [§4] §4 (experiments): the leave-one-language-out evaluation reports performance across the ten languages but provides no breakdown or correlation analysis by language family (Indo-Aryan vs. Dravidian) or phonetic overlap, which is required to isolate whether observed transfer reflects general cross-lingual capability or relatedness within the Indic group.
minor comments (2)
- [Abstract] The abstract would benefit from one or two key numeric results (e.g., average F1 under few-shot) to make the competitiveness claim immediately verifiable.
- [§3] Notation for the projection layer and contrastive loss in §3 should include explicit dimension sizes and temperature values for reproducibility.
Simulated Author's Rebuttal
We are grateful to the referee for their constructive comments, which have helped us identify areas for improvement in the manuscript. We respond to each major comment below and indicate the changes we will implement.
read point-by-point responses
-
Referee: [Abstract and §5] Abstract and §5 (results): the central claim that 'lightweight projection-only adaptation achieves competitive performance with respect to fully supervised systems' is load-bearing but unsupported by any numeric metrics, exact baseline descriptions, error bars, or statistical tests in the provided text; without these the competitiveness cannot be verified.
Authors: We agree that the competitiveness of the lightweight adaptation needs to be supported by explicit quantitative evidence. In the revised manuscript, we will update the abstract and expand §5 to provide numeric performance metrics for both the few-shot adapted models and the fully supervised baselines, along with detailed baseline descriptions, error bars from multiple runs, and statistical significance tests. This will enable direct verification of the claims. revision: yes
-
Referee: [§4] §4 (experiments): the leave-one-language-out evaluation reports performance across the ten languages but provides no breakdown or correlation analysis by language family (Indo-Aryan vs. Dravidian) or phonetic overlap, which is required to isolate whether observed transfer reflects general cross-lingual capability or relatedness within the Indic group.
Authors: We concur that analyzing the results by language family and phonetic overlap will better contextualize the transfer performance. We will revise §4 to include a breakdown of leave-one-language-out results by Indo-Aryan and Dravidian language families, as well as a correlation analysis with phonetic overlap measures. This addition will help distinguish general cross-lingual capabilities from effects due to linguistic relatedness. revision: yes
Circularity Check
No significant circularity; empirical evaluation on external data
full rationale
The paper conducts an empirical evaluation of CLAP representations for abusive speech detection using the external ADIMA dataset across ten Indic languages. It reports results from few-shot contrastive adaptation, zero-shot prompting, and comparisons to fully supervised baselines in cross-lingual and leave-one-language-out settings. No equations, derivations, or fitted parameters are defined in terms of the target performance metrics, and no self-citations form a load-bearing chain that reduces the central claims to unverified inputs by construction. The work is self-contained against external benchmarks and datasets.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CLAP pre-trained representations capture prosodic and semantic cues relevant to abusive speech
Reference graph
Works this paper leans on
-
[1]
Mfcc based hybrid fingerprinting method for audio classification through lstm.International Jour- nal of Nonlinear Analysis and Applications, 12(Spe- cial Issue):2125–2136. Bharathi Raja Chakravarthi, Ruba Priyadharshini, Sajeetha Thavareesan, Elizabeth Sherly, Saranya Ra- jiakodi, Balasubramanian Palani, Malliga Subrama- nian, Subalalitha Cn, Dhivya Chin...
-
[2]
Learning Transferable Visual Models From Natural Language Supervision
A bert-based transfer learning approach for hate speech detection in online social media. InCom- plex Networks and Their Applications VIII, pages 928–940, Cham. Springer International Publishing. Arpan Nandi, Kamal Sarkar, Arjun Mallick, and Arkadeep De. 2024. Combining multiple pre-trained models for hate speech detection in bengali, marathi, and hindi.M...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
pages 1333–1337
Assessing the semantic space bias caused by asr error propagation and its effect on spoken docu- ment summarization. pages 1333–1337. A Appendix A.1 Additional Cross-Lingual and LOLO Score Tables The tables in this appendix provide a more de- tailed view of the best-performing language-wise results under the multilingual leave-one-language- out (LOLO) and...
-
[4]
as the loss function for projection training. 11 Language ADIMA projection-only projection+fine-tuning Bengali 79.10 76.34 (25) 76.22 (1) Bhojpuri – 71.31 (0) 71.48 (25) Gujarati – 75.52 (0) 75.52 (0) Haryanvi – 80.23 (25) 79.13 (25) Hindi 80.70 77.76 (10) 78.04 (50) Kannada 78.40 76.67 (25) 76.58 (1) Malayalam – 78.18 (50) 77.60 (0) Odia – 79.67 (25) 79....
2076
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.