Recognition: unknown
Decoupling Vector Data and Index Storage for Space Efficiency
Pith reviewed 2026-05-10 16:41 UTC · model grok-4.3
The pith
Decoupling vector data from index metadata in disk-based approximate nearest neighbor search systems can reduce storage space by up to 58.7% while maintaining competitive or improved query and update performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DecoupleVS is a storage management framework that decouples vector data from auxiliary index metadata in disk-based ANNS systems. It applies specialized techniques for compression, data layouts, query processing, and update handling on the separated components, achieving substantial storage reduction while preserving high search and update performance and accuracy on billion-scale datasets.
What carries the argument
DecoupleVS, the framework that separates vector data storage from index metadata storage to allow independent optimizations for compression, layout, and access patterns.
Load-bearing premise
The primary storage, read, and write problems in existing ANNS systems come from co-locating vector data with index metadata rather than from other design choices.
What would settle it
Measuring storage size and query/update latency on the same billion-scale dataset with both DecoupleVS and a monolithic system; if storage savings fall below 20% or performance degrades noticeably, the claimed benefit would not hold.
Figures






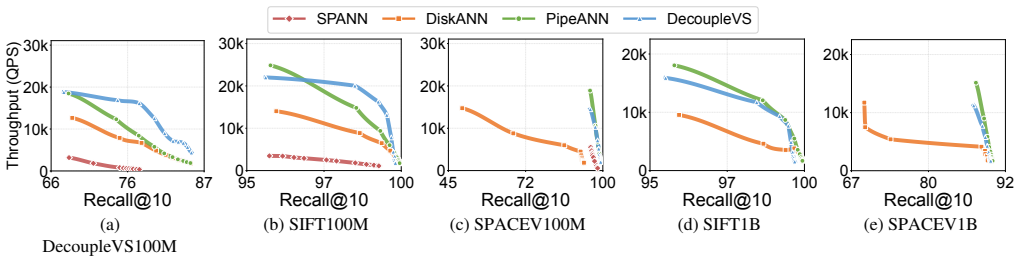
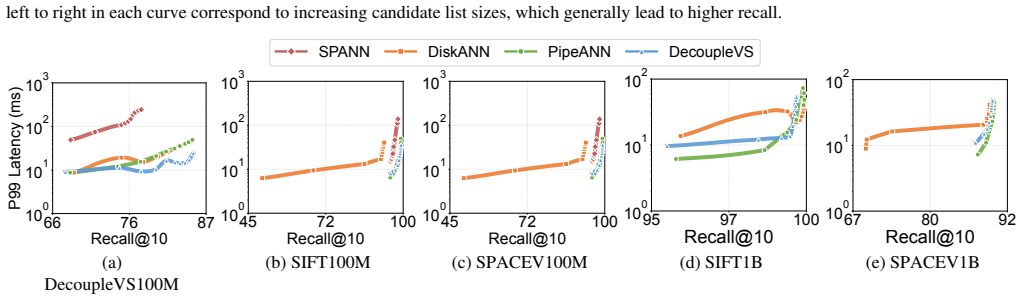


read the original abstract
Managing large-scale vector datasets with disk-based approximate nearest neighbor search (ANNS) systems faces critical efficiency challenges stemming from the co-location of vector data and auxiliary index metadata. Our analysis of state-of-the-art ANNS systems reveals that such co-location incurs substantial storage overhead, generates excessive reads during search queries, and causes severe write amplification during updates. We present DecoupleVS, a decoupled vector storage management framework that enables specialized optimizations for vector data and auxiliary index metadata. DecoupleVS incorporates various design techniques for effective compression, data layouts, search queries, and updates, so as to significantly reduce storage space, while maintaining high search and update performance and high search accuracy. Evaluation on real-world public and proprietary billion-scale datasets shows that DecoupleVS reduces storage space by up to 58.7\%, while delivering competitive or improved search query and update performance, compared to state-of-the-art monolithic disk-based ANNS systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DecoupleVS, a decoupled vector storage management framework for disk-based approximate nearest neighbor search (ANNS) systems. It identifies storage overhead, read amplification during queries, and write amplification during updates as consequences of co-locating vector data with auxiliary index metadata in monolithic designs. DecoupleVS applies specialized compression, data layouts, and separate query/update paths to reduce space while preserving search accuracy and performance. Evaluation on real-world public and proprietary billion-scale datasets reports up to 58.7% storage reduction with competitive or improved query and update performance relative to state-of-the-art monolithic disk-based ANNS systems.
Significance. If the empirical claims hold, the work addresses a practical bottleneck in large-scale vector databases where storage costs dominate. The decoupling strategy enables independent optimization of data and metadata, which is a direct systems contribution. Credit is due for the evaluation on both public and proprietary billion-scale datasets and for reporting non-degraded query/update performance alongside the space savings.
minor comments (3)
- The abstract states that DecoupleVS 'incorporates various design techniques for effective compression, data layouts, search queries, and updates'; a concise summary table or diagram early in the paper (e.g., in the system overview section) would clarify which techniques apply to which component and how they interact.
- The 58.7% space reduction is presented as the maximum observed; specifying the exact dataset, index type, and compression configuration that achieves this figure would strengthen the central empirical claim.
- The paper compares against 'state-of-the-art monolithic disk-based ANNS systems'; an explicit list of the baselines (with version numbers or citations) and a summary table of storage, latency, throughput, and recall metrics would improve readability and reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of DecoupleVS and the recommendation for minor revision. The review correctly identifies the core challenges of co-located vector and index storage in disk-based ANNS and acknowledges the practical value of our decoupling approach, including the evaluation on billion-scale datasets. No major comments were raised in the report.
Circularity Check
No significant circularity detected
full rationale
The paper is a systems/empirical contribution that identifies storage co-location overheads in existing disk-based ANNS systems, proposes a decoupled framework (DecoupleVS) with compression, layout, query, and update techniques, and validates the approach via direct evaluation on public and proprietary billion-scale datasets. No derivation chain, fitted parameters, self-referential predictions, or load-bearing self-citations appear in the abstract or described structure. Central claims (up to 58.7% space reduction with competitive performance) rest on external experimental comparison rather than reduction to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cassandra
Apache. Cassandra. https://cassandra.apache. org/, 2025
2025
-
[2]
Language models are few-shot learners.Proc
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared D Kaplan, Prafulla Dhariwal, Arvind Nee- lakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Proc. of NeurIPS, 2020
2020
-
[3]
Zhichao Cao, Siying Dong, Sagar Vemuri, and David H. C. Du. Characterizing, modeling, and benchmarking RocksDB key-value workloads at Facebook. InProc. of USENIX FAST, 2020
2020
-
[4]
Hsieh, Deborah A
Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E Gruber. Bigtable: A distributed storage system for structured data. InProc. of USENIX OSDI, 2006
2006
-
[5]
Sptag: A li- brary for fast approximate nearest neighbor search
Qi Chen, Haidong Wang, Mingqin Li, Gang Ren, Scarlett Li, Jeffery Zhu, Jason Li, Chuanjie Liu, Lin- tao Zhang, and Jingdong Wang. Sptag: A li- brary for fast approximate nearest neighbor search. https://github.com/Microsoft/SPTAG, 2018
2018
-
[6]
SPANN: Highly-efficient billion-scale approx- imate nearest neighborhood search.Proc
Qi Chen, Bing Zhao, Haidong Wang, Mingqin Li, Chuanjie Liu, Zengzhong Li, Mao Yang, and Jingdong Wang. SPANN: Highly-efficient billion-scale approx- imate nearest neighborhood search.Proc. of NeurIPS, 2021
2021
-
[7]
Yann Collet. LZ4. https://github.com/lz4/lz4, 2011
2011
-
[8]
Deep neural networks for YouTube recommendations
Paul Covington, Jay Adams, and Emre Sargin. Deep neural networks for YouTube recommendations. In Proc. of ACM RecSys, 2016
2016
-
[9]
Jarek Duda. Asymmetric numeral systems: Entropy coding combining speed of Huffman coding with com- pression rate of arithmetic coding.arXiv preprint arXiv:1311.2540, 2013
work page Pith review arXiv 2013
-
[10]
Efficient storage and retrieval by content and address of static files.Journal of the ACM (JACM), 21(2):246--260, 1974
Peter Elias. Efficient storage and retrieval by content and address of static files.Journal of the ACM (JACM), 21(2):246--260, 1974
1974
-
[11]
Massachusetts Institute of Technology, Project MAC, 1971
Robert Mario Fano.On the number of bits required to implement an associative memory. Massachusetts Institute of Technology, Project MAC, 1971
1971
-
[12]
Fast approximate nearest neighbor search with the navi- gating spreading-out graph.Proceedings of the VLDB Endowment, 12(5):461--474, 2019
Cong Fu, Chao Xiang, Changxu Wang, and Deng Cai. Fast approximate nearest neighbor search with the navi- gating spreading-out graph.Proceedings of the VLDB Endowment, 12(5):461--474, 2019
2019
-
[13]
RabitQ: Quantizing high-dimensional vectors with a theoretical error bound for approximate nearest neighbor search.Proc
Jianyang Gao and Cheng Long. RabitQ: Quantizing high-dimensional vectors with a theoretical error bound for approximate nearest neighbor search.Proc. of ACM SIGMOD, 2(3):1--27, 2024
2024
-
[14]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Op- timized product quantization.IEEE Trans
Tiezheng Ge, Kaiming He, Qifa Ke, and Jian Sun. Op- timized product quantization.IEEE Trans. on Pat- tern Analysis and Machine Intelligence, 36(4):744--755, 2013
2013
-
[16]
Succinct
Giuseppe Ottaviano. Succinct. https://github. com/ot/succinct, 2017
2017
-
[17]
Real-time person- alization using embeddings for search ranking at airbnb
Mihajlo Grbovic and Haibin Cheng. Real-time person- alization using embeddings for search ranking at airbnb. InProc. of the 24th ACM SIGKDD, 2018
2018
-
[18]
Achieving low-latency graph- based vector search via aligning best-first search algo- rithm with SSD
Hao Guo and Youyou Lu. Achieving low-latency graph- based vector search via aligning best-first search algo- rithm with SSD. InProc. of USENIX OSDI, 2025
2025
-
[19]
OdinANN: Direct insert for consistently stable performance in billion-scale graph- based vector search
Hao Guo and Youyou Lu. OdinANN: Direct insert for consistently stable performance in billion-scale graph- based vector search. InProc. of USENIX FAST, 2026
2026
-
[20]
Research talk: Approximate nearest neighbor search systems at scale
Harsha Simhadri. Research talk: Approximate nearest neighbor search systems at scale. https://youtu.be/ BnYNdSIKibQ?t=179, 2022
2022
-
[21]
ZipNN: Lossless compression for AI models
Moshik Hershcovitch, Andrew Wood, Leshem Choshen, Guy Girmonsky, Roy Leibovitz, Or Ozeri, Ilias Enn- mouri, Michal Malka, Peter Chin, Swaminathan Sun- 13 dararaman, et al. ZipNN: Lossless compression for AI models. InProc. of IEEE CLOUD, 2025
2025
-
[22]
AI and the future of unstructured data
IBM. AI and the future of unstructured data. https: //www.ibm.com/think/insights/unstructured- data-trends, 2025
2025
-
[23]
AI data centers are swallowing the world’s memory and storage supply, setting the stage for a pricing apocalypse that could last a decade
Luke James. AI data centers are swallowing the world’s memory and storage supply, setting the stage for a pricing apocalypse that could last a decade. https://www.tomshardware.com/pc- components/storage/perfect-storm-of- demand-and-supply-driving-up-storage- costs?ref=aisecret.us, 2025
2025
-
[24]
DiskANN: Fast accurate billion-point near- est neighbor search on a single node.Proc
Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vard- han Simhadri, Ravishankar Krishnawamy, and Rohan Kadekodi. DiskANN: Fast accurate billion-point near- est neighbor search on a single node.Proc. of NeurIPS, 2019
2019
-
[25]
Product quantization for nearest neighbor search.IEEE Trans
Herve Jegou, Matthijs Douze, and Cordelia Schmid. Product quantization for nearest neighbor search.IEEE Trans. on Pattern Analysis and Machine Intelligence, 33(1):117--128, 2010
2010
-
[26]
Searching in one billion vectors: re- rank with source coding
Herv´e J ´egou, Romain Tavenard, Matthijs Douze, and Laurent Amsaleg. Searching in one billion vectors: re- rank with source coding. InProc. of IEEE ICASSP, 2011
2011
-
[27]
Introducing the Mil- vus Sizing Tool: Calculating and Optimizing Your Milvus Deployment Resources
Ken Zhang, Fendy Feng. Introducing the Mil- vus Sizing Tool: Calculating and Optimizing Your Milvus Deployment Resources . https: //milvus.io/blog/introducing-the-milvus- sizing-tool-calculating-and-optimizing- your-milvus-deployment-resources.md, 2025
2025
-
[28]
Dynamic Huffman coding.Journal of Algorithms, 6(2):163--180, 1985
Donald E Knuth. Dynamic Huffman coding.Journal of Algorithms, 6(2):163--180, 1985
1985
-
[29]
Datasets for ap- proximate nearest neighbor search
Laurent Amsaleg and Herv ´e J ´egou. Datasets for ap- proximate nearest neighbor search. http://corpus- texmex.irisa.fr/, 2010
2010
-
[30]
VStore: in-storage graph based vector search accelerator
Shengwen Liang, Ying Wang, Ziming Yuan, Cheng Liu, Huawei Li, and Xiaowei Li. VStore: in-storage graph based vector search accelerator. InProc. of ACM/IEEE DAC, 2022
2022
-
[31]
Efficient and robust approximate nearest neighbor search using hier- archical navigable small world graphs.IEEE Trans
Yu A Malkov and Dmitry A Yashunin. Efficient and robust approximate nearest neighbor search using hier- archical navigable small world graphs.IEEE Trans. on Pattern Analysis and Machine Intelligence, 42(4):824-- 836, 2018
2018
-
[32]
SPTAG issue #416: Segmentation fault when building SIFT1B
Microsoft. SPTAG issue #416: Segmentation fault when building SIFT1B. https://github.com/ microsoft/SPTAG/issues/416, 2024
2024
-
[33]
Flann-fast library for approximate nearest neighbors user manual.Computer Science Department, University of British Columbia, Vancouver, BC, Canada, 5(6), 2009
Marius Muja and David Lowe. Flann-fast library for approximate nearest neighbors user manual.Computer Science Department, University of British Columbia, Vancouver, BC, Canada, 5(6), 2009
2009
-
[34]
BIG ANN-Benchmarks
NeurIPS. BIG ANN-Benchmarks. https://big-ann- benchmarks.com/neurips21.html, 2021
2021
-
[35]
Fm- delta: Lossless compression for storing massive fine- tuned foundation models.Proc
Wanyi Ning, Jingyu Wang, Qi Qi, Mengde Zhu, Haifeng Sun, Daixuan Cheng, Jianxin Liao, and Ce Zhang. Fm- delta: Lossless compression for storing massive fine- tuned foundation models.Proc. of NeurIPS, 2024
2024
-
[36]
The ChatGPT Retrieval Plugin lets you easily search and find personal or work documents by ask- ing questions in everyday language
OpenAI. The ChatGPT Retrieval Plugin lets you easily search and find personal or work documents by ask- ing questions in everyday language. https://github. com/openai/chatgpt-retrieval-plugin, 2023
2023
-
[37]
Partitioned elias-fano indexes
Giuseppe Ottaviano and Rossano Venturini. Partitioned elias-fano indexes. InProceedings of the 37th Interna- tional ACM SIGIR Conference on Research & Develop- ment in Information Retrieval, 2014
2014
-
[38]
TiKV.https://tikv.org, 2025
PinCap. TiKV.https://tikv.org, 2025
2025
-
[39]
Sentence-bert: Sen- tence embeddings using siamese bert-networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sen- tence embeddings using siamese bert-networks. InProc. of the EMNLP, 2019
2019
-
[40]
FPGA-based lossless data compression using Huffman and LZ77 algorithms
Suzanne Rigler, William Bishop, and Andrew Kennings. FPGA-based lossless data compression using Huffman and LZ77 algorithms. In2007 Canadian conference on electrical and computer engineering, pages 1235--1238. IEEE, 2007
2007
-
[41]
A mathematical theory of commu- nication.The Bell system technical journal, 27(3):379-- 423, 1948
Claude E Shannon. A mathematical theory of commu- nication.The Bell system technical journal, 27(3):379-- 423, 1948
1948
-
[42]
Freshdiskann: A fast and accurate graph-based ann index for streaming similarity search,
Aditi Singh, Suhas Jayaram Subramanya, Ravis- hankar Krishnaswamy, and Harsha Vardhan Simhadri. FreshDiskANN: A fast and accurate graph-based ann index for streaming similarity search.arXiv preprint arXiv:2105.09613, 2021
-
[43]
Scalable billion-point approximate nearest neighbor search using SmartSSDs
Bing Tian, Haikun Liu, Zhuohui Duan, Xiaofei Liao, Hai Jin, and Yu Zhang. Scalable billion-point approximate nearest neighbor search using SmartSSDs. InProc. of USENIX ATC, 2024
2024
-
[44]
Towards high- throughput and low-latency billion-scale vector search via CPU/GPU collaborative filtering and re-ranking
Bing Tian, Haikun Liu, Yuhang Tang, Shihai Xiao, Zhuohui Duan, Xiaofei Liao, Hai Jin, Xuecang Zhang, Junhua Zhu, and Yu Zhang. Towards high- throughput and low-latency billion-scale vector search via CPU/GPU collaborative filtering and re-ranking. In Proc. of USENIX FAST, 2025
2025
-
[45]
The relative neighbourhood graph of a finite planar set.Pattern recognition, 12(4):261--268, 1980
Godfried T Toussaint. The relative neighbourhood graph of a finite planar set.Pattern recognition, 12(4):261--268, 1980
1980
-
[46]
DiskANN: Graph-structured Indices for Scalable, Fast, Fresh and Filtered Approximate Nearest Neighbor Search
Simhadri Harsha Vardhan, Krishnaswamy Ravishankar, Srinivasa Gopal, Subramanya Suhas Jayaram, Antoni- jevic Andrija, Pryce Dax, Kaczynski David, Williams Shane, Gollapudi Siddarth, Sivashankar Varun, Karia 14 Neel, Singh Aditi, Jaiswal Shikhar, Mahapatro Nee- lam, Adams Philip, Tower Bryan, and Patel Yash. DiskANN: Graph-structured Indices for Scalable, F...
2023
-
[47]
MILC: Inverted list compression in memory.Proceedings of the VLDB Endowment, 10(8):853--864, 2017
Jianguo Wang, Chunbin Lin, Ruining He, Moojin Chae, Yannis Papakonstantinou, and Steven Swanson. MILC: Inverted list compression in memory.Proceedings of the VLDB Endowment, 10(8):853--864, 2017
2017
-
[48]
Starling: An I/O-efficient disk-resident graph index framework for high-dimensional vector similarity search on data segment.Proc
Mengzhao Wang, Weizhi Xu, Xiaomeng Yi, Songlin Wu, Zhangyang Peng, Xiangyu Ke, Yunjun Gao, Xi- aoliang Xu, Rentong Guo, and Charles Xie. Starling: An I/O-efficient disk-resident graph index framework for high-dimensional vector similarity search on data segment.Proc. of ACM SIGMOD, 2024
2024
-
[49]
ZipLLM:towards efficient LLM storage reduction via tensor deduplication and delta com- pression
Zirui Wang, Tingfeng Lan, Zhaoyuan Su, Juncheng Yang, and Yue Cheng. ZipLLM:towards efficient LLM storage reduction via tensor deduplication and delta com- pression. InProc. of USENIX NSDI, 2026
2026
-
[50]
Configure replication in Weaviate ANN service
Weaviate. Configure replication in Weaviate ANN service. https://docs.weaviate.io/deploy/ configuration/replication, 2025
2025
-
[51]
Bernstein, Badrish Chan- dramouli, Richard Wen, and Harsha Vardhan Simhadri
Haike Xu, Magdalen Dobson Manohar, Philip A Bern- stein, Badrish Chandramouli, Richard Wen, and Har- sha Vardhan Simhadri. In-place updates of a graph in- dex for streaming approximate nearest neighbor search. arXiv preprint arXiv:2502.13826, 2025
-
[52]
SPFresh: Incremental in- place update for billion-scale vector search
Yuming Xu, Hengyu Liang, Jin Li, Shuotao Xu, Qi Chen, Qianxi Zhang, Cheng Li, Ziyue Yang, Fan Yang, Yuqing Yang, et al. SPFresh: Incremental in- place update for billion-scale vector search. InProc. of ACM SOSP, 2023
2023
-
[53]
New Generation Entropy coders
Yann Collet. New Generation Entropy coders. https: //github.com/Cyan4973/FiniteStateEntropy, 2019
2019
-
[54]
Finesse: Fine-grained fea- ture locality based fast resemblance detection for post- deduplication delta compression
Yucheng Zhang, Wen Xia, Dan Feng, Hong Jiang, Yu Hua, and Qiang Wang. Finesse: Fine-grained fea- ture locality based fast resemblance detection for post- deduplication delta compression. InProc. of USENIX FAST, 2019
2019
-
[55]
Fast vector query processing for large datasets beyond GPU memory with reordered pipelining
Zili Zhang, Fangyue Liu, Gang Huang, Xuanzhe Liu, and Xin Jin. Fast vector query processing for large datasets beyond GPU memory with reordered pipelining. InProc. of USENIX NSDI, 2024. 15
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.