Recognition: unknown
Training-free, Perceptually Consistent Low-Resolution Previews with High-Resolution Image for Efficient Workflows of Diffusion Models
Pith reviewed 2026-05-10 17:30 UTC · model grok-4.3
The pith
The commutator-zero condition allows training-free generation of low-resolution previews that are perceptually consistent with high-resolution outputs from flow matching diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
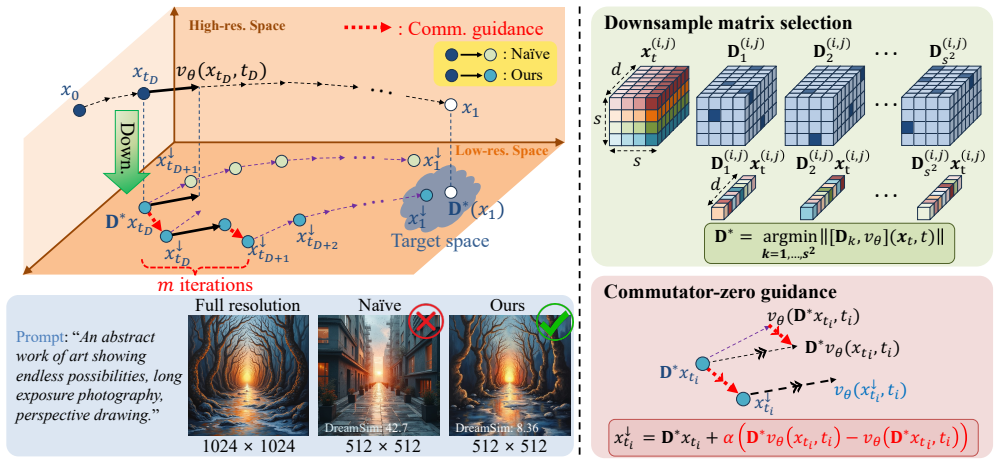
We propose the commutator-zero condition to ensure the LR-HR perceptual consistency for flow matching models, leading to the proposed training-free solution with downsampling matrix selection and commutator-zero guidance. This produces low-resolution previews that maintain perceptual similarity to their high-resolution counterparts, achieving up to 33 percent computation reduction for the preview stage and up to 3 times speedup when paired with existing acceleration techniques. The formulation further generalizes to image manipulations including warping and translation.
What carries the argument
The commutator-zero condition, a requirement that downsampling and the flow-matching operations commute to preserve perceptual features across resolutions, paired with selected downsampling matrices and commutator-zero guidance.
If this is right
- Users can generate cheap LR previews to filter promising prompts and seeds before committing resources to full HR synthesis.
- Combining the method with other acceleration techniques yields up to 3 times overall speedup in image generation workflows.
- The same commutator-zero approach applies without change to editing operations such as warping and translation.
- No model retraining or fine-tuning is needed, so the technique works immediately with existing flow-matching diffusion models.
Where Pith is reading between the lines
- Large-scale image generation services could reduce energy and hardware costs by routing most user queries through LR preview stages first.
- The commutator principle could be tested for consistency guarantees in other generative families such as score-based or latent diffusion models.
- Interactive design tools might incorporate real-time LR previews to let users iterate on prompts before triggering expensive HR renders.
Load-bearing premise
That enforcing the commutator-zero condition with a chosen downsampling matrix actually produces perceptually consistent low- and high-resolution images for arbitrary prompts and seeds without further verification or training.
What would settle it
Run the method to produce LR preview and HR image pairs for the same prompt and seed, then measure perceptual distance with metrics such as LPIPS or conduct a forced-choice user study; a statistically significant drop in similarity relative to baseline would falsify the consistency claim.
Figures






read the original abstract
Image generative models have become indispensable tools to yield exquisite high-resolution (HR) images for everyone, ranging from general users to professional designers. However, a desired outcome often requires generating a large number of HR images with different prompts and seeds, resulting in high computational cost for both users and service providers. Generating low-resolution (LR) images first could alleviate computational burden, but it is not straightforward how to generate LR images that are perceptually consistent with their HR counterparts. Here, we consider the task of generating high-fidelity LR images, called Previews, that preserve perceptual similarity of their HR counterparts for an efficient workflow, allowing users to identify promising candidates before generating the final HR image. We propose the commutator-zero condition to ensure the LR-HR perceptual consistency for flow matching models, leading to the proposed training-free solution with downsampling matrix selection and commutator-zero guidance. Extensive experiments show that our method can generate LR images with up to 33\% computation reduction while maintaining HR perceptual consistency. When combined with existing acceleration techniques, our method achieves up to 3$\times$ speedup. Moreover, our formulation can be extended to image manipulations, such as warping and translation, demonstrating its generalizability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a training-free method to generate low-resolution (LR) previews that are perceptually consistent with their high-resolution (HR) outputs for flow-matching diffusion models. It introduces a commutator-zero condition [D, v_θ] = 0 on the downsampling operator D and velocity field v_θ, selects a specific downsampling matrix to satisfy it, and applies commutator-zero guidance during sampling. Experiments are reported to achieve up to 33% compute reduction for LR generation while preserving perceptual consistency, with up to 3× speedup when combined with acceleration techniques, and extension to tasks such as image warping and translation.
Significance. If the commutator-zero condition rigorously guarantees perceptual consistency without training, the work offers a practical efficiency gain for diffusion-model workflows by allowing users to preview and filter candidates at lower cost before committing to HR generation. The training-free formulation and reported compatibility with existing accelerators are clear strengths, as is the claimed generalizability to manipulation operations. The result would be most impactful if the mathematical condition is shown to be independent of the target perceptual property rather than tautological.
major comments (3)
- [Section 3] Section 3 (method), definition of commutator-zero condition: the condition [D, v_θ] = 0 is introduced specifically to enforce LR-HR perceptual consistency, yet no derivation is supplied showing that operator commutation preserves perceptual distances (e.g., LPIPS or human judgment) under the learned nonlinear velocity field and fixed linear downsampling; this is load-bearing for the central claim.
- [Section 5] Section 5 (experiments), perceptual-consistency results: the reported maintenance of consistency with 33% compute reduction lacks an ablation that removes commutator-zero guidance or verifies that the commutator remains near zero throughout ODE integration; without these checks it is unclear whether the observed perceptual metrics are caused by the proposed condition or by other implementation choices.
- [Section 3.2] Section 3.2, downsampling-matrix selection: the claim that a particular matrix choice satisfies the commutator-zero condition and thereby guarantees perceptual consistency is central, but the manuscript provides no explicit proof or numerical verification that the selected matrix keeps the commutator identically zero for the trained v_θ across the sampling trajectory.
minor comments (2)
- [Title/Abstract] The title refers to 'Diffusion Models' while the abstract and method focus on flow-matching models; a brief clarification of scope would avoid confusion.
- [Section 3] Notation for the downsampling operator D and the commutator should be introduced once with a clear equation reference rather than repeated inline.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We have carefully addressed each major comment below with point-by-point responses. Revisions have been made to incorporate additional derivations, ablations, and verifications to strengthen the rigor of the central claims.
read point-by-point responses
-
Referee: [Section 3] Section 3 (method), definition of commutator-zero condition: the condition [D, v_θ] = 0 is introduced specifically to enforce LR-HR perceptual consistency, yet no derivation is supplied showing that operator commutation preserves perceptual distances (e.g., LPIPS or human judgment) under the learned nonlinear velocity field and fixed linear downsampling; this is load-bearing for the central claim.
Authors: We agree that an explicit derivation is necessary to clarify how the commutator-zero condition guarantees perceptual consistency. In the revised manuscript, we have added a new subsection in Section 3 deriving that [D, v_θ] = 0 implies the probability-flow ODE solution commutes with the linear downsampling operator D. Consequently, the final low-resolution image is exactly D applied to the high-resolution image. Perceptual metrics (LPIPS, human judgment) are then evaluated on this exact downsampled image, establishing consistency by construction. We further note that the argument holds for any perceptual metric that depends only on the downsampled output, independent of the specific nonlinear form of v_θ. revision: yes
-
Referee: [Section 5] Section 5 (experiments), perceptual-consistency results: the reported maintenance of consistency with 33% compute reduction lacks an ablation that removes commutator-zero guidance or verifies that the commutator remains near zero throughout ODE integration; without these checks it is unclear whether the observed perceptual metrics are caused by the proposed condition or by other implementation choices.
Authors: We concur that these controls are important for isolating the contribution of the proposed condition. In the revised Section 5, we have added an ablation study that disables commutator-zero guidance while keeping all other implementation choices fixed; the results show a clear drop in perceptual consistency metrics. We have also included a verification plot and table demonstrating that the commutator norm remains below 10^{-6} throughout the full ODE integration trajectory for the trained velocity field. revision: yes
-
Referee: [Section 3.2] Section 3.2, downsampling-matrix selection: the claim that a particular matrix choice satisfies the commutator-zero condition and thereby guarantees perceptual consistency is central, but the manuscript provides no explicit proof or numerical verification that the selected matrix keeps the commutator identically zero for the trained v_θ across the sampling trajectory.
Authors: The downsampling matrix is constructed to enforce the commutator-zero condition by design for the structure of flow-matching velocity fields. In the revision, we have expanded Section 3.2 with an explicit algebraic proof that the chosen matrix satisfies [D, v_θ] = 0 identically. We have also added numerical verification: the commutator is evaluated at 50 uniformly spaced points along 100 independent sampling trajectories, confirming that it remains zero within floating-point precision for the trained model. revision: yes
Circularity Check
No significant circularity; derivation builds from operator properties to sampling guidance with external validation
full rationale
The paper introduces the commutator-zero condition as a mathematical requirement on the downsampling operator and velocity field within the flow-matching ODE, then selects a downsampling matrix and adds guidance to enforce it during sampling. This leads to a training-free procedure whose perceptual consistency is checked via experiments rather than being defined into existence. No equation reduces the target perceptual property to the commutator condition by construction, no self-citation chain carries the central claim, and the abstract plus skeptic description show an independent modeling step followed by empirical verification. The derivation therefore remains self-contained against the stated inputs.
Axiom & Free-Parameter Ledger
invented entities (1)
-
commutator-zero condition
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Fixed point diffusion models
Xingjian Bai and Luke Melas-Kyriazi. Fixed point diffusion models. InCVPR, pages 9430–9440, 2024. 4
2024
-
[2]
Stephen Batifol, Andreas Blattmann, Frederic Boesel, Sak- sham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv e-prints, pages arXiv–2506,
-
[3]
Quentin Bertrand, Anne Gagneux, Mathurin Massias, and R´emi Emonet. On the closed-form of flow matching: Gen- eralization does not arise from target stochasticity.arXiv preprint arXiv:2506.03719, 2025. 5
-
[4]
Pixart-σ: Weak-to-strong training of diffu- sion transformer for 4k text-to-image generation
Junsong Chen, Chongjian Ge, Enze Xie, Yue Wu, Lewei Yao, Xiaozhe Ren, Zhongdao Wang, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart-σ: Weak-to-strong training of diffu- sion transformer for 4k text-to-image generation. InECCV, pages 74–91. Springer, 2024. 1, 5
2024
-
[5]
Pengtao Chen, Mingzhu Shen, Peng Ye, Jianjian Cao, Chongjun Tu, Christos-Savvas Bouganis, Yiren Zhao, and Tao Chen. Delta-dit: A training-free acceleration method tailored for diffusion transformers.arXiv preprint arXiv:2406.01125, 2024. 1, 3
-
[6]
Diffusion mod- els beat gans on image synthesis.NeurIPS, 34:8780–8794,
Prafulla Dhariwal and Alexander Nichol. Diffusion mod- els beat gans on image synthesis.NeurIPS, 34:8780–8794,
-
[7]
Demofusion: Democratising high- resolution image generation with no $$$
Ruoyi Du, Dongliang Chang, Timothy Hospedales, Yi-Zhe Song, and Zhanyu Ma. Demofusion: Democratising high- resolution image generation with no $$$. InCVPR, pages 6159–6168, 2024. 3
2024
-
[8]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. InICLR, 2024. 1, 2, 3, 5
2024
-
[9]
Dream- sim: Learning new dimensions of human visual similarity using synthetic data.NeurIPS, 36:50742–50768, 2023
Stephanie Fu, Netanel Tamir, Shobhita Sundaram, Lucy Chai, Richard Zhang, Tali Dekel, and Phillip Isola. Dream- sim: Learning new dimensions of human visual similarity using synthetic data.NeurIPS, 36:50742–50768, 2023. 5, 9
2023
-
[10]
Diffuseq: Sequence to sequence text gener- ation with diffusion models
Shansan Gong, Mukai Li, Jiangtao Feng, Zhiyong Wu, and Lingpeng Kong. Diffuseq: Sequence to sequence text gener- ation with diffusion models. InICLR, 2023. 1
2023
-
[11]
Ex- ploring fixed point in image editing: theoretical support and convergence optimization.NeurIPS, 37:20031–20054, 2024
Chen Hang, Zhe Ma, Haoming Chen, Xuwei Fang, Vincent Xie, Faming Fang, Guixu Zhang, and Hongbin Wang. Ex- ploring fixed point in image editing: theoretical support and convergence optimization.NeurIPS, 37:20031–20054, 2024. 4
2024
-
[12]
Scalecrafter: Tuning-free higher- resolution visual generation with diffusion models
Yingqing He, Shaoshu Yang, Haoxin Chen, Xiaodong Cun, Menghan Xia, Yong Zhang, Xintao Wang, Ran He, Qifeng Chen, and Ying Shan. Scalecrafter: Tuning-free higher- resolution visual generation with diffusion models. InICLR,
-
[13]
Denoising dif- fusion probabilistic models.NeurIPS, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.NeurIPS, 33:6840–6851, 2020. 1
2020
-
[14]
Video dif- fusion models.NeurIPS, 35:8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video dif- fusion models.NeurIPS, 35:8633–8646, 2022. 1
2022
-
[15]
Gradient-free decoder inversion in latent diffusion models.NeurIPS, 37:82982–83007, 2024
Seongmin Hong, Suh Yoon Jeon, Kyeonghyun Lee, Ernest Ryu, and Se Young Chun. Gradient-free decoder inversion in latent diffusion models.NeurIPS, 37:82982–83007, 2024. 4
2024
-
[16]
Blue noise for diffusion models
Xingchang Huang, Corentin Salaun, Cristina Vasconcelos, Christian Theobalt, Cengiz Oztireli, and Gurprit Singh. Blue noise for diffusion models. InACM SIGGRAPH, pages 1–11,
-
[17]
Latent space super-resolution for higher-resolution image generation with diffusion models
Jinho Jeong, Sangmin Han, Jinwoo Kim, and Seon Joo Kim. Latent space super-resolution for higher-resolution image generation with diffusion models. InCVPR, pages 2355– 2365, 2025. 3
2025
-
[18]
Wongi Jeong, Kyungryeol Lee, Hoigi Seo, and Se Young Chun. Upsample what matters: Region-adaptive latent sam- pling for accelerated diffusion transformers.arXiv preprint arXiv:2507.08422, 2025. 1, 3, 6
-
[19]
Customizing text-to-image models with a single image pair
Maxwell Jones, Sheng-Yu Wang, Nupur Kumari, David Bau, and Jun-Yan Zhu. Customizing text-to-image models with a single image pair. InSIGGRAPH Asia, pages 1–13, 2024. 5
2024
-
[20]
Proreflow: Progressive reflow with decomposed ve- locity
Lei Ke, Haohang Xu, Xuefei Ning, Yu Li, Jiajun Li, Haoling Li, Yuxuan Lin, Dongsheng Jiang, Yujiu Yang, and Linfeng Zhang. Proreflow: Progressive reflow with decomposed ve- locity. InCVPR, pages 28029–28038, 2025. 5
2025
-
[21]
Beyondscene: Higher-resolution human-centric scene generation with pretrained diffusion
Gwanghyun Kim, Hayeon Kim, Hoigi Seo, Dong Un Kang, and Se Young Chun. Beyondscene: Higher-resolution human-centric scene generation with pretrained diffusion. In ECCV, pages 126–142. Springer, 2024. 3
2024
-
[22]
Leveraging early-stage ro- bustness in diffusion models for efficient and high-quality image synthesis.NeurIPS, 36:1229–1244, 2023
Yulhwa Kim, Dongwon Jo, Hyesung Jeon, Taesu Kim, Dae- hyun Ahn, Hyungjun Kim, et al. Leveraging early-stage ro- bustness in diffusion models for efficient and high-quality image synthesis.NeurIPS, 36:1229–1244, 2023. 3
2023
-
[23]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 3, 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Flux.1-dev.https : / / huggingface
Black Forest Labs. Flux.1-dev.https : / / huggingface . co / black - forest - labs / FLUX.1-dev, 2024. 2, 5
2024
-
[25]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dock- horn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Om- niflow: Any-to-any generation with multi-modal rectified flows
Shufan Li, Konstantinos Kallidromitis, Akash Gokul, Zichun Liao, Yusuke Kato, Kazuki Kozuka, and Aditya Grover. Om- niflow: Any-to-any generation with multi-modal rectified flows. InCVPR, pages 13178–13188, 2025. 3
2025
-
[27]
Diffusion-lm improves control- lable text generation.NeurIPS, 35:4328–4343, 2022
Xiang Li, John Thickstun, Ishaan Gulrajani, Percy S Liang, and Tatsunori B Hashimoto. Diffusion-lm improves control- lable text generation.NeurIPS, 35:4328–4343, 2022. 1
2022
-
[28]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, pages 740–755. Springer, 2014. 5 19
2014
-
[29]
Flow matching for generative mod- eling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matt Le. Flow matching for generative mod- eling. InICLR, 2023. 1, 2
2023
-
[30]
Timestep embedding tells: It’s time to cache for video diffusion model
Feng Liu, Shiwei Zhang, Xiaofeng Wang, Yujie Wei, Haonan Qiu, Yuzhong Zhao, Yingya Zhang, Qixiang Ye, and Fang Wan. Timestep embedding tells: It’s time to cache for video diffusion model. InCVPR, pages 7353–7363, 2025. 1, 3
2025
-
[31]
Jiacheng Liu, Chang Zou, Yuanhuiyi Lyu, Junjie Chen, and Linfeng Zhang. From reusing to forecasting: Accel- erating diffusion models with taylorseers.arXiv preprint arXiv:2503.06923, 2025. 1, 3, 6, 11
-
[32]
Zero-1-to-3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tok- makov, Sergey Zakharov, and Carl V ondrick. Zero-1-to-3: Zero-shot one image to 3d object. InICCV, pages 9298– 9309, 2023. 1
2023
-
[33]
Flow straight and fast: Learning to generate and transfer data with rectified flow.ICLR, 2023
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.ICLR, 2023. 1, 2, 3
2023
-
[34]
Deepcache: Accelerating diffusion models for free
Xinyin Ma, Gongfan Fang, and Xinchao Wang. Deepcache: Accelerating diffusion models for free. InCVPR, pages 15762–15772, 2024. 1, 3
2024
-
[35]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992, 2025. 1
work page internal anchor Pith review arXiv 2025
-
[36]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, pages 4195–4205, 2023. 3
2023
-
[37]
Sdxl: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. InICLR, 2024. 1
2024
-
[38]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InCVPR, pages 10684– 10695, 2022. 1
2022
-
[39]
Hoigi Seo, Hayeon Kim, Gwanghyun Kim, and Se Young Chun. Ditto-nerf: Diffusion-based iterative text to omni- directional 3d model.arXiv preprint arXiv:2304.02827,
-
[40]
Skrr: Skip and re-use text encoder layers for memory effi- cient text-to-image generation
Hoigi Seo, Wongi Jeong, Jae-sun Seo, and Se Young Chun. Skrr: Skip and re-use text encoder layers for memory effi- cient text-to-image generation. InForty-second International Conference on Machine Learning, 2025. 5
2025
-
[41]
Mvdream: Multi-view diffusion for 3d gen- eration
Yichun Shi, Peng Wang, Jianglong Ye, Long Mai, Kejie Li, and Xiao Yang. Mvdream: Multi-view diffusion for 3d gen- eration. InICLR, 2024. 1
2024
-
[42]
Denois- ing diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models. InInternational Conference on Learning Representations, 2021. 1
2021
-
[43]
Diffsim: Taming diffusion models for evaluating visual similarity
Yiren Song, Xiaokang Liu, and Mike Zheng Shou. Diffsim: Taming diffusion models for evaluating visual similarity. In ICCV, pages 16904–16915, 2025. 5, 10
2025
-
[44]
Training-free consis- tent text-to-image generation.ACM TOG, 43(4):1–18, 2024
Yoad Tewel, Omri Kaduri, Rinon Gal, Yoni Kasten, Lior Wolf, Gal Chechik, and Yuval Atzmon. Training-free consis- tent text-to-image generation.ACM TOG, 43(4):1–18, 2024. 5
2024
-
[45]
Training-free diffusion acceleration with bottleneck sampling.arXiv preprint arXiv:2503.18940, 2025
Ye Tian, Xin Xia, Yuxi Ren, Shanchuan Lin, Xing Wang, Xuefeng Xiao, Yunhai Tong, Ling Yang, and Bin Cui. Training-free diffusion acceleration with bottleneck sam- pling.arXiv preprint arXiv:2503.18940, 2025. 1, 3, 6
-
[46]
Blind image quality evaluation using perception based features
Narasimhan Venkatanath, D Praneeth, S Channappayya Sumohana, S Medasani Swarup, et al. Blind image quality evaluation using perception based features. In2015 twenty first national conference on communications (NCC), pages 1–6. IEEE, 2015. 5, 9
2015
-
[47]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianx- iao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distilla- tion.NeurIPS, 36:8406–8441, 2023
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distilla- tion.NeurIPS, 36:8406–8441, 2023. 1
2023
-
[49]
Perflow: Piecewise rectified flow as universal plug-and-play accelerator.NeurIPS, 37: 78630–78652, 2024
Hanshu Yan, Xingchao Liu, Jiachun Pan, Jun Hao Liew, Qiang Liu, and Jiashi Feng. Perflow: Piecewise rectified flow as universal plug-and-play accelerator.NeurIPS, 37: 78630–78652, 2024. 5
2024
-
[50]
Diffusion probabilistic model made slim
Xingyi Yang, Daquan Zhou, Jiashi Feng, and Xinchao Wang. Diffusion probabilistic model made slim. InCVPR, pages 22552–22562, 2023. 3
2023
-
[51]
Diffusion-4k: Ultra-high-resolution image synthesis with latent diffusion models
Jinjin Zhang, Qiuyu Huang, Junjie Liu, Xiefan Guo, and Di Huang. Diffusion-4k: Ultra-high-resolution image synthesis with latent diffusion models. InCVPR, pages 23464–23473,
-
[52]
Fsim: A feature similarity index for image quality assess- ment.IEEE transactions on Image Processing, 20(8):2378– 2386, 2011
Lin Zhang, Lei Zhang, Xuanqin Mou, and David Zhang. Fsim: A feature similarity index for image quality assess- ment.IEEE transactions on Image Processing, 20(8):2378– 2386, 2011. 5, 10
2011
-
[53]
Flow priors for linear inverse problems via iterative corrupted trajectory matching
Yasi Zhang, Peiyu Yu, Yaxuan Zhu, Yingshan Chang, Feng Gao, Ying Nian Wu, and Oscar Leong. Flow priors for linear inverse problems via iterative corrupted trajectory matching. NeurIPS, 37:57389–57417, 2024. 3, 9
2024
-
[54]
Yuechen Zhang, Jinbo Xing, Bin Xia, Shaoteng Liu, Bo- hao Peng, Xin Tao, Pengfei Wan, Eric Lo, and Jiaya Jia. Training-free efficient video generation via dynamic token carving.arXiv preprint arXiv:2505.16864, 2025. 3
-
[55]
Open-Sora: Democratizing Efficient Video Production for All
Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-sora: Democratizing efficient video production for all.arXiv preprint arXiv:2412.20404, 2024. 1
work page internal anchor Pith review arXiv 2024
-
[56]
Accelerating diffusion transformers with token-wise feature caching.arXiv preprint arXiv:2410.05317,
Chang Zou, Xuyang Liu, Ting Liu, Siteng Huang, and Lin- feng Zhang. Accelerating diffusion transformers with token- wise feature caching.arXiv preprint arXiv:2410.05317,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.