Recognition: no theorem link
FashionStylist: An Expert Knowledge-enhanced Multimodal Dataset for Fashion Understanding
Pith reviewed 2026-05-10 18:05 UTC · model grok-4.3
The pith
FashionStylist supplies expert-annotated data to benchmark and train models on three outfit-level fashion tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
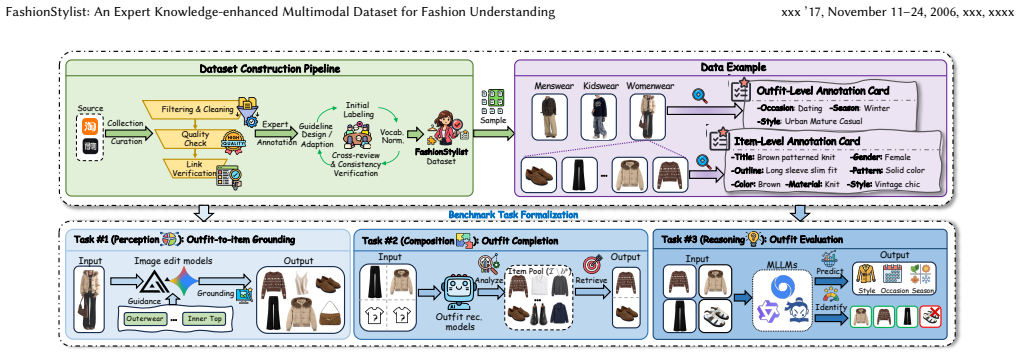
FashionStylist is assembled via a dedicated expert annotation pipeline that yields grounded labels for items inside complex outfits and for whole-outfit properties. The three supported tasks are outfit-to-item grounding that recovers specific garments amid layering and accessories, compatibility-aware outfit completion that goes beyond simple co-occurrence, and outfit evaluation that assesses style, season, occasion, and overall coherence. Experiments indicate the resource functions simultaneously as a unified benchmark across these tasks and as training material that raises performance in grounding, completion, and semantic evaluation for multimodal large language model fashion systems.
What carries the argument
The expert annotation pipeline that supplies item-level and outfit-level labels for the three tasks of grounding, completion, and evaluation.
If this is right
- Models gain improved recovery of individual items from outfits that include layering and accessories.
- Outfit completion becomes driven by compatibility rules rather than frequency of past pairings.
- Outfit evaluation incorporates expert judgment on style, season, occasion, and internal coherence.
- A single annotated collection can replace multiple task-specific datasets for both testing and fine-tuning.
Where Pith is reading between the lines
- The same expert-pipeline approach could be replicated for other visual domains that combine appearance with cultural rules, such as interior styling or product photography.
- Wider adoption might shift fashion AI away from scraping social media tags toward curated professional knowledge.
- Direct ablation studies that swap expert labels for weak labels on the same images would isolate the contribution of annotation quality.
- Integration with generative models could test whether the dataset improves synthesized outfits that satisfy the same coherence criteria.
Load-bearing premise
Expert annotations produced by the dedicated pipeline are reliably better than weak textual supervision and the three tasks together capture holistic fashion understanding.
What would settle it
Training identical multimodal models on prior fashion collections versus FashionStylist and observing no measurable gain in grounding accuracy, completion quality, or agreement with expert outfit scores.
Figures


read the original abstract
Fashion understanding requires both visual perception and expert-level reasoning about style, occasion, compatibility, and outfit rationale. However, existing fashion datasets remain fragmented and task-specific, often focusing on item attributes, outfit co-occurrence, or weak textual supervision, and thus provide limited support for holistic outfit understanding. In this paper, we introduce FashionStylist, an expert-annotated benchmark for holistic and expert-level fashion understanding. Constructed through a dedicated fashion-expert annotation pipeline, FashionStylist provides professionally grounded annotations at both the item and outfit levels. It supports three representative tasks: outfit-to-item grounding, outfit completion, and outfit evaluation. These tasks cover realistic item recovery from complex outfits with layering and accessories, compatibility-aware composition beyond co-occurrence matching, and expert-level assessment of style, season, occasion, and overall coherence. Experimental results show that FashionStylist serves not only as a unified benchmark for multiple fashion tasks, but also as an effective training resource for improving grounding, completion, and outfit-level semantic evaluation in MLLM-based fashion systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FashionStylist, an expert-annotated multimodal dataset for holistic fashion understanding constructed via a dedicated fashion-expert annotation pipeline. It supports three tasks—outfit-to-item grounding, outfit completion, and outfit evaluation—and claims that experimental results establish it as both a unified benchmark for multiple fashion tasks and an effective training resource for improving grounding, completion, and outfit-level semantic evaluation in MLLM-based systems.
Significance. If the experimental claims are substantiated, the dataset would address fragmentation in existing fashion resources by providing professionally grounded item- and outfit-level annotations, potentially enabling more robust multimodal models for style, compatibility, and coherence reasoning. The emphasis on expert-level tasks beyond weak supervision or co-occurrence matching could serve as a valuable benchmark and training resource in the fashion CV and MLLM communities.
major comments (2)
- [Abstract] Abstract: The central claim that 'experimental results show that FashionStylist serves ... as an effective training resource for improving grounding, completion, and outfit-level semantic evaluation' is unsupported, as the manuscript provides no quantitative metrics, baselines, ablation studies, data splits, or performance comparisons on the three tasks. This directly undermines verification of the training-resource assertion.
- [Experimental evaluation] Experimental evaluation section: No inter-annotator agreement scores, comparisons against prior weak-supervision datasets, or results tables are presented to demonstrate that the expert annotation pipeline yields reliably superior labels or measurable gains in MLLM performance, leaving the superiority assumption untested.
minor comments (1)
- The description of the three tasks would benefit from additional concrete examples or illustrative figures to clarify distinctions from prior task-specific datasets.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript introducing FashionStylist. The comments highlight important gaps in substantiating our claims about the dataset's utility as both a benchmark and training resource. We address each point below and will revise the manuscript to incorporate the requested evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'experimental results show that FashionStylist serves ... as an effective training resource for improving grounding, completion, and outfit-level semantic evaluation' is unsupported, as the manuscript provides no quantitative metrics, baselines, ablation studies, data splits, or performance comparisons on the three tasks. This directly undermines verification of the training-resource assertion.
Authors: We acknowledge that the current manuscript version presents the dataset construction, task definitions, and high-level experimental claims without the detailed quantitative support referenced in the abstract. To rectify this, we will add a comprehensive experimental section that includes quantitative metrics (e.g., accuracy, IoU for grounding; compatibility scores for completion; coherence ratings for evaluation), baseline MLLM comparisons, ablation studies on training with FashionStylist versus other data, data splits, and performance gains demonstrating its value as a training resource. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation section: No inter-annotator agreement scores, comparisons against prior weak-supervision datasets, or results tables are presented to demonstrate that the expert annotation pipeline yields reliably superior labels or measurable gains in MLLM performance, leaving the superiority assumption untested.
Authors: We agree that explicit validation of the expert annotation pipeline's quality is necessary to support claims of superiority over weak-supervision approaches. In the revised manuscript, we will include inter-annotator agreement scores (e.g., Cohen's kappa or percentage agreement) for key annotation aspects, direct comparisons against prior fashion datasets relying on weak supervision or co-occurrence, and results tables quantifying MLLM performance improvements attributable to FashionStylist's expert labels. revision: yes
Circularity Check
No circularity: dataset introduction with no derivations or self-referential predictions
full rationale
The paper introduces FashionStylist as a new expert-annotated multimodal dataset supporting three tasks (outfit-to-item grounding, outfit completion, outfit evaluation). No equations, fitted parameters, or first-principles derivations are present in the provided text. Claims rest on dataset construction via an expert pipeline and unspecified experimental results, without any reduction of outputs to inputs by definition, self-citation chains, or renaming of known results. This matches the default expectation for a dataset paper: self-contained contribution without circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert fashion knowledge can be captured through a dedicated annotation pipeline to produce higher-quality labels than weak textual supervision for multimodal models.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, et al . 2025. Qwen3-VL technical report. arXiv:2511.21631 [cs.CV] https://arxiv.org/abs/2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, et al. 2025. Qwen2.5-VL technical report. arXiv:2502.13923 [cs.CV] https://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Mikołaj Bińkowski, Danica J Sutherland, Michael Arbel, and Arthur Gretton
-
[4]
Demystifying mmd gans.arXiv preprint arXiv:1801.01401(2018)
work page internal anchor Pith review arXiv 2018
-
[5]
Wen Chen, Pipei Huang, Jiaming Xu, Xin Guo, Cheng Guo, Fei Sun, Chao Li, Andreas Pfadler, Huan Zhao, and Binqiang Zhao. 2019. POG: personalized outfit generation for fashion recommendation at Alibaba iFashion. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2662–2670
2019
-
[6]
Wen-Huang Cheng, Sijie Song, Chieh-Yun Chen, Shintami Chusnul Hidayati, and Jiaying Liu. 2021. Fashion meets computer vision: A survey.Comput. Surveys 54, 4 (2021), 1–41
2021
-
[7]
Patrick John Chia, Giuseppe Attanasio, Federico Bianchi, Silvia Terragni, Ana Rita Magalhaes, Diogo Goncalves, Ciro Greco, and Jacopo Tagliabue. 2022. Contrastive language and vision learning of general fashion concepts.Scientific Reports12, 1 (2022), 18958
2022
-
[8]
Seunghwan Choi, Sunghyun Park, Minsoo Lee, and Jaegul Choo. 2021. Viton- hd: High-resolution virtual try-on via misalignment-aware normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14131–14140
2021
-
[9]
Jacob Cohen. 1960. A coefficient of agreement for nominal scales.Educational and psychological measurement20, 1 (1960), 37–46
1960
- [10]
-
[11]
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. Qlora: Efficient finetuning of quantized llms.Advances in Neural Information Processing Systems(2023), 10088–10115
2023
-
[12]
Yujuan Ding, Zhihui Lai, PY Mok, and Tat-Seng Chua. 2023. Computational technologies for fashion recommendation: A survey.Comput. Surveys56, 5 (2023), 1–45
2023
-
[13]
Yuying Ge, Ruimao Zhang, Xiaogang Wang, Xiaoou Tang, and Ping Luo. 2019. Deepfashion2: A versatile benchmark for detection, pose estimation, segmen- tation and re-identification of clothing images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5337–5345
2019
-
[14]
Weili Guan, Fangkai Jiao, Xuemeng Song, Haokun Wen, Chung-Hsing Yeh, and Xiaojun Chang. 2022. Personalized fashion compatibility modeling via metapath- guided heterogeneous graph learning. InProceedings of the 45th international ACM SIGIR Conference on Research and Development in Information Retrieval. 482–491
2022
-
[15]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. 2017. GANs trained by a two time-scale update rule converge to a local nash equilibrium.Advances in Neural Information Processing Systems (2017)
2017
-
[16]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-rank adaptation of large language models. InProceedings of the International Conference on Learning Representations (ICLR)
2022
-
[17]
Youngseung Jeon, Seungwan Jin, Patrick C Shih, and Kyungsik Han. 2021. Fash- ionQ: An ai-driven creativity support tool for facilitating ideation in fashion design. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems. 1–18
2021
-
[18]
Menglin Jia, Mengyun Shi, Mikhail Sirotenko, Yin Cui, Claire Cardie, Bharath Hariharan, Hartwig Adam, and Serge Belongie. 2020. Fashionpedia: Ontology, segmentation, and an attribute localization dataset. InEuropean Conference on Computer Vision. Springer, 316–332
2020
-
[19]
Peng Jin, Yilin Wen, Mingzhe Yu, Yunshan Ma, Rong Zheng, Jin-tu Fan, and Chong Wah NGO. 2025. GenWardrobe: A fully generative system for travel fashion wardrobe construction. InProceedings of the 33rd ACM International Conference on Multimedia. 13540–13542
2025
-
[20]
Onur Keleş, M Akın Yılmaz, A Murat Tekalp, Cansu Korkmaz, and Zafer Dogan
- [21]
-
[22]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, et al. 2025. FLUX. 1 Kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
J Richard Landis and Gary G Koch. 1977. The measurement of observer agreement for categorical data.biometrics(1977), 159–174
1977
-
[24]
Lizi Liao, You Zhou, Yunshan Ma, Richang Hong, and Tat-seng Chua. 2018. Knowledge-aware multimodal fashion chatbot. InProceedings of the 26th ACM International Conference on Multimedia. 1265–1266
2018
-
[25]
Yen-Liang Lin, Son Tran, and Larry S Davis. 2020. Fashion outfit complementary item retrieval. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3311–3319
2020
-
[26]
Xiaohao Liu, Jie Wu, Zhulin Tao, Yunshan Ma, Yinwei Wei, and Tat-seng Chua
-
[27]
In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Fine-tuning multimodal large language models for product bundling. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 848–858
-
[28]
Ziwei Liu, Ping Luo, Shi Qiu, Xiaogang Wang, and Xiaoou Tang. 2016. Deep- Fashion: Powering robust clothes recognition and retrieval with rich annotations. In2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 1096–1104. https://doi.org/10.1109/CVPR.2016.124
-
[29]
Zhi Lu, Yang Hu, Yunchao Jiang, Yan Chen, and Bing Zeng. 2019. Learning binary code for personalized fashion recommendation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10562–10570
2019
-
[30]
Yunshan Ma, Yujuan Ding, Xun Yang, Lizi Liao, Wai Keung Wong, and Tat-Seng Chua. 2020. Knowledge enhanced neural fashion trend forecasting. InProceedings of the 2020 International Conference on Multimedia Retrieval. 82–90
2020
-
[31]
Yunshan Ma, Yingzhi He, Wenjun Zhong, Xiang Wang, Roger Zimmermann, and Tat-Seng Chua. 2024. Cirp: Cross-item relational pre-training for multimodal product bundling. InProceedings of the 32nd ACM International Conference on Multimedia. 9641–9649
2024
-
[32]
Yunshan Ma, Xiaohao Liu, Yinwei Wei, Zhulin Tao, Xiang Wang, and Tat-Seng Chua. 2024. Leveraging multimodal features and item-level user feedback for bundle construction. InProceedings of the 17th ACM International Conference on Web Search and Data Mining. 510–519
2024
-
[33]
Davide Morelli, Matteo Fincato, Marcella Cornia, Federico Landi, Fabio Cesari, and Rita Cucchiara. 2022. Dress code: High-resolution multi-category virtual try-on. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2231–2235
2022
-
[34]
Jianmo Ni, Jiacheng Li, and Julian McAuley. 2019. Justifying recommendations using distantly-labeled reviews and fine-grained aspects. InProceedings of the Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. 188–197
2019
- [35]
-
[36]
Burak Satar, Zhixin Ma, Patrick Amadeus Irawan, Wilfried Ariel Mulyawan, Jing Jiang, Ee-Peng Lim, and Chong-Wah Ngo. 2025. Seeing culture: A benchmark for visual reasoning and grounding. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 22238–22254
2025
-
[37]
Wenda Shi, Waikeung Wong, and Xingxing Zou. 2025. Generative AI in fashion: Overview.ACM Transactions on Intelligent Systems and Technology16, 4 (2025), 1–73
2025
-
[38]
Xuemeng Song, Xianjing Han, Yunkai Li, Jingyuan Chen, Xin-Shun Xu, and Liqiang Nie. 2019. GP-BPR: Personalized compatibility modeling for clothing matching. InProceedings of the 27th ACM international Conference on Multimedia. 320–328
2019
-
[39]
Tianyu Su, Xuemeng Song, Na Zheng, Weili Guan, Yan Li, and Liqiang Nie
-
[40]
In Proceedings of the 29th ACM International Conference on Multimedia
Complementary factorization towards outfit compatibility modeling. In Proceedings of the 29th ACM International Conference on Multimedia. 4073–4081
-
[41]
Zhu Sun, Kaidong Feng, Jie Yang, Xinghua Qu, Hui Fang, Yew-Soon Ong, and Wenyuan Liu. 2024. Adaptive in-context learning with large language models for bundle generation. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 966–976
2024
-
[42]
Gemma Team. 2025. Gemma 3 technical report. arXiv:2503.19786 [cs.CL] https://arxiv.org/abs/2503.19786
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al
-
[44]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: A family of highly capable multimodal models. arXiv 2023.arXiv preprint arXiv:2312.11805(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [45]
-
[46]
Xin Wang, Bo Wu, and Yueqi Zhong. 2019. Outfit compatibility prediction and diagnosis with multi-layered comparison network. InProceedings of the 27th ACM International Conference on Multimedia. 329–337
2019
-
[47]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. 2004. Image quality assessment: From error visibility to structural similarity.IEEE Transactions on Image Processing13, 4 (2004), 600–612
2004
-
[48]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng- ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al . 2025. Qwen-image technical report.arXiv preprint arXiv:2508.02324(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Hui Wu, Yupeng Gao, Xiaoxiao Guo, Ziad Al-Halah, Steven Rennie, Kristen Grauman, and Rogerio Feris. 2021. Fashion IQ: A new dataset towards retrieving images by natural language feedback. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11307–11317. xxx ’17, November 11–24, 2006, xxx, xxxx Feng et al
2021
-
[50]
Yiyan Xu, Wenjie Wang, Fuli Feng, Yunshan Ma, Jizhi Zhang, and Xiangnan He
-
[51]
InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval
Diffusion models for generative outfit recommendation. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1350–1359
-
[52]
Xuewen Yang, Dongliang Xie, Xin Wang, Jiangbo Yuan, Wanying Ding, and Pengyun Yan. 2020. Learning tuple compatibility for conditional outfit recom- mendation. InProceedings of the 28th ACM International Conference on Multimedia. 2636–2644
2020
-
[53]
Xiangyu Zhao, Yuehan Zhang, Wenlong Zhang, and Xiao-Ming Wu. 2024. Uni- fashion: A unified vision-language model for multimodal fashion retrieval and generation. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 1490–1507
2024
-
[54]
Haitian Zheng, Kefei Wu, Jong-Hwi Park, Wei Zhu, and Jiebo Luo. 2021. Person- alized fashion recommendation from personal social media data: An item-to-set metric learning approach. In2021 IEEE International Conference on Big Data. IEEE, 5014–5023
2021
-
[55]
Dongliang Zhou, Haijun Zhang, Jianghong Ma, Jicong Fan, and Zhao Zhang. 2023. Fcboost-net: A generative network for synthesizing multiple collocated outfits via fashion compatibility boosting. InProceedings of the 31st ACM International Conference on Multimedia. 7881–7889
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.