Recognition: unknown
Through Their Eyes: Fixation-aligned Tuning for Personalized User Emulation
Pith reviewed 2026-05-10 16:18 UTC · model grok-4.3
The pith
Aligning a vision-language model's visual attention with individual user gaze patterns improves simulation of clicks on recommendation interfaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Probing a vision-language model's internal visual attention via interpretability operators yields a slot-level relevance distribution that can be aligned with human fixation data; learning user-specific soft prompts then steers the model toward each individual's characteristic gaze pattern, producing measurable improvements in attention alignment and downstream click prediction on visual recommendation layouts.
What carries the argument
Fixation-Aligned Tuning for user Emulation (FixATE), which extracts comparable relevance distributions from VLM attention probes and optimizes personalized soft prompts to match observed human fixation distributions.
If this is right
- Attention alignment improves consistently when using any of the three tested interpretability-based probing operators.
- Click prediction accuracy rises for both of the architecturally distinct VLM backbones examined.
- Simulators gain the ability to perceive recommendations through visual interfaces rather than text or metadata alone.
- The method produces user-specific emulation that better reproduces how individuals scan and act on layouts.
Where Pith is reading between the lines
- The same prompting technique could be tested on other visual interfaces such as product grids or social feeds where gaze variation also drives choices.
- If soft prompts can be adapted from limited new gaze samples, simulators might support rapid personalization for different demographic segments without retraining entire models.
- Combining fixation alignment with existing text-based user models could create hybrid simulators that capture both visual scanning and preference reasoning.
- The approach raises the possibility of measuring simulation quality directly through attention metrics rather than relying solely on downstream task accuracy.
Load-bearing premise
Users maintain stable individual gaze patterns that are strongly predictive of their click behavior, and these patterns can be captured and matched by steering a VLM's attention with learned soft prompts.
What would settle it
Collect new eye-tracking and click data from the same carousel setting, apply FixATE to align a fresh VLM instance, then measure click-prediction accuracy on held-out recommendations; if accuracy shows no reliable improvement over an untuned baseline VLM, the value of the alignment step is not supported.
Figures






read the original abstract
Large language model (LLM) agents are increasingly deployed as scalable user simulators for recommender system evaluation. Yet existing simulators perceive recommendations through text or structured metadata rather than the visual interfaces real users browse-a critical gap, since attention over recommendation layouts is both visually driven and highly personalized. We investigate whether aligning a vision-language model's (VLM's) visual attention with user-specific gaze patterns can improve simulation fidelity. Analysis of a real-world eye-tracking dataset collected in a carousel-based recommendation setting reveals that users exhibit stable individual gaze patterns strongly predictive of click behavior. Building on this finding, we propose Fixation-Aligned Tuning for user Emulation (FixATE). Our approach first probes the VLM's internal visual attention via interpretability operators to obtain a slot-level relevance distribution comparable with human fixation, and then learns personalized soft prompts to steer the model's attention toward each user's characteristic fixation pattern. Experiments across three interpretability-based probing operators and two architecturally distinct VLM backbones demonstrate consistent improvements in both attention alignment and click prediction accuracy. These results suggest that making the model "see like the user" is a viable path toward simulators that more faithfully reproduce how users perceive and act in recommendation interfaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that users show stable, individualized gaze patterns in carousel-based recommendation interfaces that are predictive of clicks, and that a VLM's internal visual attention (probed via interpretability operators) can be aligned to these patterns via learned personalized soft prompts. The proposed FixATE method is evaluated across three probing operators and two architecturally distinct VLM backbones, reporting consistent gains in attention alignment and click-prediction accuracy over baselines.
Significance. If the empirical gains hold under rigorous controls, the work would meaningfully advance personalized user emulation for recommender-system evaluation by moving beyond text-only simulators to incorporate visually grounded, user-specific attention. The multi-operator, multi-backbone design is a strength that supports claims of robustness rather than operator-specific artifacts.
major comments (2)
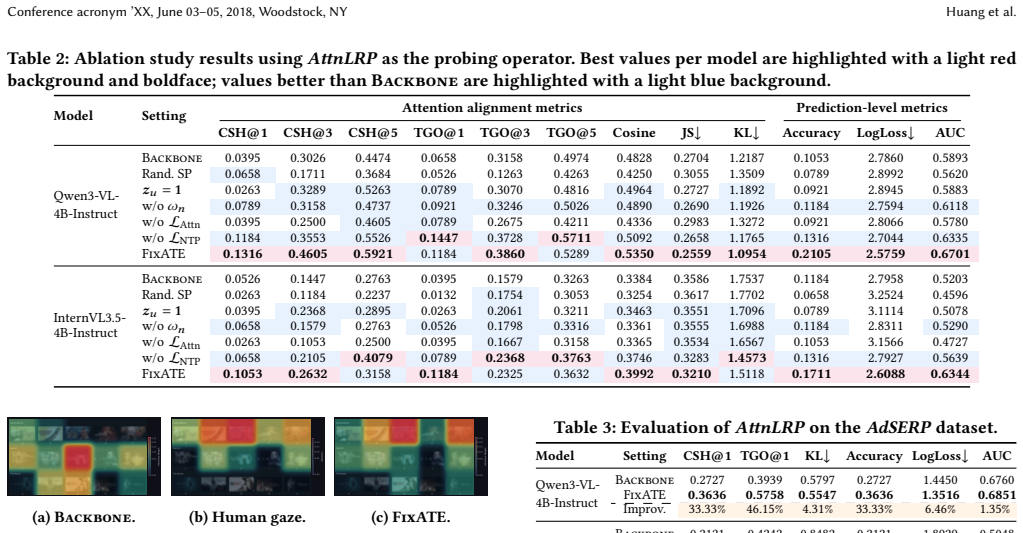
- [eye-tracking analysis] The central claim that fixation alignment improves simulation fidelity rests on the assumption that per-user gaze patterns are stable and predictive of clicks. The eye-tracking analysis section must report quantitative evidence (intra- vs. inter-user variance, correlation coefficients with click labels, and statistical tests) rather than qualitative statements; without these numbers the predictive link remains unverified and load-bearing for the subsequent tuning results.
- [experiments] Table or figure reporting click-prediction accuracy: the manuscript must include per-user or per-condition breakdowns, baseline comparisons with confidence intervals or p-values, and an ablation that isolates the contribution of the fixation-alignment objective versus the soft-prompt parameterization alone. Absent these, it is impossible to determine whether the reported gains are attributable to the proposed mechanism.
minor comments (2)
- [method] Notation for the three interpretability-based probing operators should be defined explicitly (e.g., equations for slot-level relevance distributions) so readers can reproduce the attention extraction step.
- [abstract] The abstract and introduction would benefit from a concise statement of dataset size (number of users, sessions, and items) and the exact VLM backbones used, to allow immediate assessment of scope.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help strengthen the rigor of our claims regarding user gaze stability and the effectiveness of FixATE. We address each major point below and commit to incorporating the requested quantitative analyses and experimental details in the revised manuscript.
read point-by-point responses
-
Referee: [eye-tracking analysis] The central claim that fixation alignment improves simulation fidelity rests on the assumption that per-user gaze patterns are stable and predictive of clicks. The eye-tracking analysis section must report quantitative evidence (intra- vs. inter-user variance, correlation coefficients with click labels, and statistical tests) rather than qualitative statements; without these numbers the predictive link remains unverified and load-bearing for the subsequent tuning results.
Authors: We agree that the current qualitative description of stable gaze patterns is insufficient to fully substantiate the central assumption. In the revised version, the eye-tracking analysis section will be expanded to include: (1) intra-user versus inter-user variance metrics (e.g., standard deviation of fixation distributions within and across users), (2) correlation coefficients (Pearson and Spearman) between per-user fixation maps and binary click labels, and (3) statistical significance tests such as paired t-tests or ANOVA to confirm that intra-user consistency exceeds inter-user variability. These statistics will be computed directly from the collected carousel eye-tracking dataset and reported with exact values and p-values. revision: yes
-
Referee: [experiments] Table or figure reporting click-prediction accuracy: the manuscript must include per-user or per-condition breakdowns, baseline comparisons with confidence intervals or p-values, and an ablation that isolates the contribution of the fixation-alignment objective versus the soft-prompt parameterization alone. Absent these, it is impossible to determine whether the reported gains are attributable to the proposed mechanism.
Authors: We acknowledge that the existing aggregate results do not provide sufficient granularity. We will revise the experimental section to add: (1) per-user and per-condition breakdowns of click-prediction accuracy in new tables, (2) baseline comparisons (including all original baselines) augmented with 95% confidence intervals and p-values from appropriate statistical tests (e.g., McNemar's test or Wilcoxon signed-rank), and (3) a dedicated ablation study comparing the full FixATE objective against a soft-prompt-only variant without the fixation-alignment loss. These additions will be presented in updated figures and tables with clear labeling of conditions and statistical results. revision: yes
Circularity Check
No significant circularity; claims rest on external data and empirical tests
full rationale
The paper's derivation begins with analysis of an independent real-world eye-tracking dataset to establish stable per-user gaze patterns, then defines FixATE operationally by probing VLM attention via standard interpretability operators and learning soft prompts to align with those patterns. Experiments measure improvements on held-out data across three operators and two backbones, without any step that reduces a claimed prediction to a fitted input by construction, invokes self-citations as load-bearing uniqueness theorems, or renames known results. The chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- personalized soft prompts
axioms (1)
- domain assumption Users exhibit stable individual gaze patterns strongly predictive of click behavior.
Reference graph
Works this paper leans on
-
[1]
Samira Abnar and Willem Zuidema. 2020. Quantifying Attention Flow in Transformers. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (Eds.). Association for Computational Linguistics, Online, 4190–4197. doi:10.18653/v1/2020.acl-main.385
-
[2]
Reduan Achtibat, Sayed Mohammad Vakilzadeh Hatefi, Maximilian Dreyer, Aakriti Jain, Thomas Wiegand, Sebastian Lapuschkin, and Wojciech Samek. 2024. AttnLRP: Attention-Aware Layer-Wise Relevance Propagation for Transformers. InProceedings of the 41st International Conference on Machine Learning (ICML’24, Vol. 235). JMLR.org, Vienna, Austria, 135–168
2024
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.21631 2025
-
[4]
Nicolas Bougie and Narimawa Watanabe. 2025. SimUSER: Simulating User Be- havior with Large Language Models for Recommender System Evaluation. In Proceedings of the 63rd Annual Meeting of the Association for Computational Lin- guistics (Volume 6: Industry Track), Georg Rehm and Yunyao Li (Eds.). Association for Computational Linguistics, Vienna, Austria, 4...
-
[5]
Mon Chu Chen, John R. Anderson, and Myeong Ho Sohn. 2001. What Can a Mouse Cursor Tell Us More? Correlation of Eye/Mouse Movements on Web Browsing. InCHI ’01 Extended Abstracts on Human Factors in Computing Systems (CHI EA ’01). Association for Computing Machinery, New York, NY, USA, 281–282. doi:10.1145/634067.634234
-
[6]
Yue Chen, Susen Yang, Tong Zhang, Chao Wang, Mingyue Cheng, Chenyi Lei, and Han Li. 2025. Lasso: Large Language Model-based User Simulator for Cross- Domain Recommendation. InProceedings of the Nineteenth ACM Conference on Recommender Systems. ACM, Prague Czech Republic, 207–216. doi:10.1145/ 3705328.3748048
-
[7]
Santiago de Leon-Martinez, Jingwei Kang, Robert Moro, Maarten de Rijke, Branislav Kveton, Harrie Oosterhuis, and Maria Bielikova. 2025. RecGaze: The First Eye Tracking and User Interaction Dataset for Carousel Interfaces. InPro- ceedings of the 48th International ACM SIGIR Conference on Research and Develop- ment in Information Retrieval (SIGIR ’25). Asso...
-
[8]
Santiago de Leon-Martinez, Robert Moro, Branislav Kveton, and Maria Bielikova
-
[9]
InProceedings of the 31st International Conference on Intelligent User Interfaces (IUI ’26)
Riding the Carousel: The First Extensive Eye Tracking Analysis of Browsing Behavior in Carousel Recommenders. InProceedings of the 31st International Conference on Intelligent User Interfaces (IUI ’26). Association for Computing Machinery, New York, NY, USA, 2120–2130. doi:10.1145/3742413.3789166
-
[10]
Pablo Villanueva González, Cristobal Subiabre Cuevas, Lino Jeldez, Benjamin Tor- realba Troncoso, María Flavia Guiñazú, and Juan D. Velásquez. 2025. A Gender- Aware Saliency Prediction System for Web Interfaces Using Deep Learning and Eye-Tracking Data.Brain Informatics12, 1 (Oct. 2025), 25. doi:10.1186/s40708- 025-00274-x
-
[11]
Jeff Huang, Ryen White, and Georg Buscher. 2012. User See, User Point: Gaze and Cursor Alignment in Web Search. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’12). Association for Computing Machinery, New York, NY, USA, 1341–1350. doi:10.1145/2207676.2208591
-
[12]
Yanbiao Ji, Dan Luo, Chang Liu, Shaokai Wu, Jing Tong, Qichen He, Deyi Ji, Hongtao Lu, and Yue Ding. 2025. Generating Negative Samples for Multi-Modal Recommendation. InProceedings of the 33rd ACM International Conference on Multimedia (MM ’25). Association for Computing Machinery, New York, NY, USA, 6007–6016. doi:10.1145/3746027.3754977
-
[13]
Kayhan Latifzadeh, Jacek Gwizdka, and Luis A. Leiva. 2025. A Versatile Dataset of Mouse and Eye Movements on Search Engine Results Pages. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, Padua Italy, 3412–3421. doi:10.1145/3726302.3730325
- [14]
-
[15]
Feiran Liu, Yuzhe Zhang, Xinyi Huang, Yinan Peng, Xinfeng Li, Lixu Wang, Yutong Shen, Ranjie Duan, Simeng Qin, Xiaojun Jia, Qingsong Wen, and Wei Dong. 2025. The Eye of Sherlock Holmes: Uncovering User Private Attribute Profiling via Vision-Language Model Agentic Framework. InProceedings of the 33rd ACM International Conference on Multimedia (MM ’25). Ass...
-
[16]
Hongyang Liu, Zhu Sun, Tianjun Wei, Yan Wang, Jiajie Zhu, and Xinghua Qu
-
[17]
Diagnostic-Guided Dynamic Profile Optimization for LLM-based User Simulators in Sequential Recommendation.Proceedings of the AAAI Conference on Artificial Intelligence40, 18 (March 2026), 15306–15314. doi:10.1609/aaai.v40i18. 38556
-
[18]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the Middle: How Language Models Use Long Contexts.Transactions of the Association for Computational Linguistics 12 (2024), 157–173. doi:10.1162/tacl_a_00638
-
[19]
Angela Lopez-Cardona, Carlos Segura, Alexandros Karatzoglou, Sergi Abadal, and Ioannis Arapakis. 2024. Seeing Eye to AI: Human Alignment via Gaze-Based Response Rewards for Large Language Models. InThe Thirteenth International Conference on Learning Representations
2024
-
[20]
Yunshan Ma, Yingzhi He, Wenjun Zhong, Xiang Wang, Roger Zimmermann, and Tat-Seng Chua. 2024. CIRP: Cross-Item Relational Pre-training for Multimodal Product Bundling. InProceedings of the 32nd ACM International Conference on Multimedia (MM ’24). Association for Computing Machinery, New York, NY, USA, 9641–9649. doi:10.1145/3664647.3681349
-
[21]
Fan’an Meng, Chaoran Cui, Hongjun Dai, and Shuai Gong. 2025. Black-Box Test-Time Prompt Tuning for Vision-Language Models.Proceedings of the AAAI Conference on Artificial Intelligence39, 6 (April 2025), 6099–6107. doi:10.1609/ aaai.v39i6.32652
2025
-
[22]
Anupam Pani and Yanchao Yang. 2025. Gaze-VLM: Bridging Gaze and VLMs through Attention Regularization for Egocentric Understanding. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems
2025
-
[23]
Qiyao Peng, Hongtao Liu, Hua Huang, Jian Yang, Qing Yang, and Minglai Shao. 2025. A Survey on LLM-powered Agents for Recommender Systems. InFindings of the Association for Computational Linguistics: EMNLP 2025, Chris- tos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Association for Computational Linguistics, Suzhou, China,...
-
[24]
Jella Pfeiffer, Thies Pfeiffer, Martin Meißner, and Elisa Weiß. 2020. Eye-Tracking- Based Classification of Information Search Behavior Using Machine Learning: 9 Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Huang et al. Evidence from Experiments in Physical Shops and Virtual Reality Shopping Environments.Information Systems Research31, 3 (Sept....
-
[25]
Guanxi Shen. 2025. GLIMPSE: Holistic Cross-Modal Explainability for Large Vision-Language Models. arXiv:2506.18985 [cs] doi:10.48550/arXiv.2506.18985
-
[26]
Florian Strohm, Mihai Bâce, and Andreas Bulling. 2024. Learning User Em- beddings from Human Gaze for Personalised Saliency Prediction.Proc. ACM Hum.-Comput. Interact.8, ETRA (May 2024), 229:1–229:16. doi:10.1145/3655603
-
[27]
Guus van Loon, Felix Hermsen, and Marnix Naber. 2022. Predicting Product Preferences on Retailers’ Web Shops through Measurement of Gaze and Pupil Size Dynamics.Journal of Cognition5, 1 (Oct. 2022). doi:10.5334/joc.240
-
[28]
David Wan, Jaemin Cho, Elias Stengel-Eskin, and Mohit Bansal. 2024. Contrastive Region Guidance: Improving Grounding in Vision-Language Models Without Training. InComputer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part LXXIX. Springer-Verlag, Berlin, Heidelberg, 198–215. doi:10.1007/978-3-031-72986-7_12
-
[29]
Lei Wang, Jingsen Zhang, Hao Yang, Zhi-Yuan Chen, Jiakai Tang, Zeyu Zhang, Xu Chen, Yankai Lin, Hao Sun, Ruihua Song, Xin Zhao, Jun Xu, Zhicheng Dou, Jun Wang, and Ji-Rong Wen. 2025. User Behavior Simulation with Large Language Model-based Agents.ACM Trans. Inf. Syst.43, 2 (Jan. 2025), 55:1–55:37. doi:10. 1145/3708985
2025
-
[30]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, Zhaokai Wang, Zhe Chen, Hongjie Zhang, Ganlin Yang, Haomin Wang, Qi Wei, Jinhui Yin, Wenhao Li, Erfei Cui, Guanzhou Chen, Zichen Ding, Changyao Tian, Zhenyu Wu, Jingjing Xie, Zehao Li, Bowen Yang, Yuchen Duan, Xuehui Wang, Zhi Hou,...
-
[31]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency. arXiv:2508.18265 [cs] doi:10.48550/arXiv.2508.18265
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.18265
-
[32]
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. 2025. Agent Workflow Memory. InForty-Second International Conference on Machine Learning
2025
-
[33]
Tianjun Wei, Huizhong Guo, Yingpeng Du, Zhu Sun, Huang Chen, Dongxia Wang, and Jie Zhang. 2025. Mirroring Users: Towards Building Preference-aligned User Simulator with User Feedback in Recommendation. doi:10.48550/arXiv.2508.18142
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.18142 2025
-
[34]
Haotian Wu, Yingpeng Du, Tianjun Wei, Puay Siew Tan, Jie Zhang, Ong Yew Soon, and Zhu Sun. 2026. Efficient Large Language Models for Recommendation: A Survey. (2026)
2026
-
[35]
Zihao Wu, Xin Wang, Heng Chang, Hong Chen, Lifeng Sun, and Wenwu Zhu
-
[36]
InProceedings of the 2025 International Conference on Multimedia Retrieval (ICMR ’25)
Aligning Large Multimodal Model with Sequential Recommendation via Content-Behavior Guidance. InProceedings of the 2025 International Conference on Multimedia Retrieval (ICMR ’25). Association for Computing Machinery, New York, NY, USA, 1507–1516. doi:10.1145/3731715.3733273
-
[37]
Yanyu Xu, Shenghua Gao, Junru Wu, Nianyi Li, and Jingyi Yu. 2019. Personalized Saliency and Its Prediction.IEEE Transactions on Pattern Analysis and Machine Intelligence41, 12 (Dec. 2019), 2975–2989. doi:10.1109/TPAMI.2018.2866563
-
[38]
Yuki Yada, Sho Akiyama, Ryo Watanabe, Yuta Ueno, Yusuke Shido, and Andre Rusli. 2025. Improving Visual Recommendation on E-commerce Platforms Using Vision-Language Models. InProceedings of the Nineteenth ACM Conference on Recommender Systems (RecSys ’25). Association for Computing Machinery, New York, NY, USA, 975–978. doi:10.1145/3705328.3748128
-
[39]
Kun Yan, Zeyu Wang, Lei Ji, Yuntao Wang, Nan Duan, and Shuai Ma. 2024. Voila- A: Aligning Vision-Language Models with User’s Gaze Attention. InProceedings of the 38th International Conference on Neural Information Processing Systems (NIPS ’24, Vol. 37). Curran Associates Inc., Red Hook, NY, USA, 1890–1918
2024
-
[40]
Yingrui Yang, Yifan Qiao, Shanxiu He, and Tao Yang. 2024. Weighted KL- Divergence for Document Ranking Model Refinement. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Infor- mation Retrieval (SIGIR ’24). Association for Computing Machinery, New York, NY, USA, 2698–2702. doi:10.1145/3626772.3657946
-
[41]
Runpeng Yu, Weihao Yu, and Xinchao Wang. 2024. Attention Prompting on Image for Large Vision-Language Models. InComputer Vision – ECCV 2024: 18th Euro- pean Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part XXX. Springer-Verlag, Berlin, Heidelberg, 251–268. doi:10.1007/978-3-031-73404-5_15
-
[42]
Tong Yu, Yilin Shen, Ruiyi Zhang, Xiangyu Zeng, and Hongxia Jin. 2019. Vision- Language Recommendation via Attribute Augmented Multimodal Reinforcement Learning. InProceedings of the 27th ACM International Conference on Multimedia (MM ’19). Association for Computing Machinery, New York, NY, USA, 39–47. doi:10.1145/3343031.3350935
-
[43]
An Zhang, Yuxin Chen, Leheng Sheng, Xiang Wang, and Tat-Seng Chua. 2024. On Generative Agents in Recommendation. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’24). Association for Computing Machinery, New York, NY, USA, 1807–
2024
-
[44]
doi:10.1145/3626772.3657844
-
[45]
Zeyu Zhang, Quanyu Dai, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. 2025. A Survey on the Memory Mechanism of Large Language Model-based Agents.ACM Trans. Inf. Syst.43, 6 (Sept. 2025), 155:1–155:47. doi:10.1145/3748302
-
[46]
Zijian Zhang, Shuchang Liu, Ziru Liu, Rui Zhong, Qingpeng Cai, Xiangyu Zhao, Chunxu Zhang, Qidong Liu, and Peng Jiang. 2025. LLM-powered User Simulator for Recommender System. InProceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Sympos...
-
[47]
Zheng Zhang, Nuoqian Xiao, Qi Chai, Deheng Ye, and Hao Wang. 2025. Mul- tiMind: Enhancing Werewolf Agents with Multimodal Reasoning and Theory of Mind. InProceedings of the 33rd ACM International Conference on Multimedia (MM ’25). Association for Computing Machinery, New York, NY, USA, 5824–5833. doi:10.1145/3746027.3755752
-
[48]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-judge with MT- bench and Chatbot Arena. InProceedings of the 37th International Conference on Neural Information Processing Systems (NIPS ’23). Curran Ass...
2023
-
[49]
Hanzhang Zhou, Xu Zhang, Panrong Tong, Jianan Zhang, Liangyu Chen, Quyu Kong, Chenglin Cai, Chen Liu, Yue Wang, Jingren Zhou, and Steven Hoi
-
[50]
MAI-UI Technical Report: Real-World Centric Foundation GUI Agents. arXiv:2512.22047 [cs] doi:10.48550/arXiv.2512.22047
-
[51]
Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. 2023. WebArena: A Realistic Web Environment for Building Autonomous Agents. InThe Twelfth International Conference on Learning Representations
2023
-
[52]
Kangyu Zhu, Ziyuan Qin, Huahui Yi, Zekun Jiang, Qicheng Lao, Shaoting Zhang, and Kang Li. 2025. Guiding Medical Vision-Language Models with Diverse Visual Prompts: Framework Design and Comprehensive Exploration of Prompt Varia- tions. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguisti...
-
[53]
Lixi Zhu, Xiaowen Huang, and Jitao Sang. 2024. How Reliable Is Your Simulator? Analysis on the Limitations of Current LLM-based User Simulators for Conver- sational Recommendation. InCompanion Proceedings of the ACM Web Conference 2024 (WWW ’24). Association for Computing Machinery, New York, NY, USA, 1726–1732. doi:10.1145/3589335.3651955 10 Through Thei...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.