Recognition: unknown
BadSkill: Backdoor Attacks on Agent Skills via Model-in-Skill Poisoning
Pith reviewed 2026-05-10 17:05 UTC · model grok-4.3
The pith
A third-party agent skill can embed a poisoned model that activates hidden malicious behavior only when its parameters match attacker-chosen semantic combinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
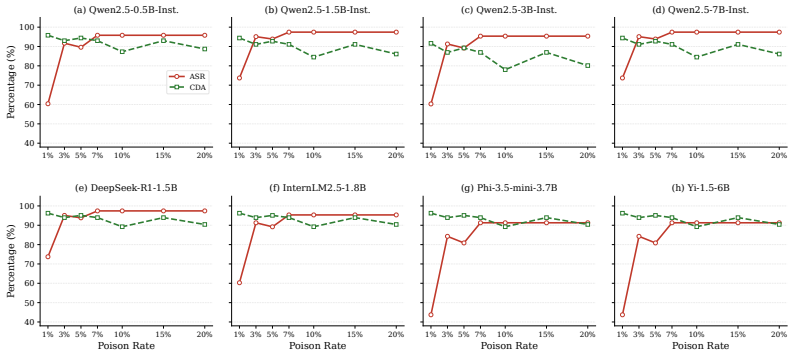
BadSkill poisons the model inside a published skill so the model outputs a hidden payload exactly when skill parameters satisfy attacker-defined semantic trigger combinations. The embedded classifier is trained with a composite objective that includes classification loss, margin-based separation, and poison-focused optimization. In an environment that reproduces third-party skill installation, execution, and parameter handling, the attack produces up to 99.5 percent average success on eight triggered skills across eight architectures while preserving high accuracy on 571 negative-class queries, and remains effective at a 3 percent poison rate and under several text perturbations.
What carries the argument
The backdoor-fine-tuned embedded classifier inside the skill that activates only on chosen semantic trigger combinations in the skill parameters.
If this is right
- Model-bearing skills create a supply-chain risk that cannot be addressed by prompt injection defenses alone.
- A 3 percent poison rate already produces over 90 percent attack success, so small amounts of tainted data suffice.
- The attack works across model sizes from hundreds of millions to billions of parameters and survives common text perturbations.
- Third-party skills therefore require provenance checks and behavioral testing of any bundled models before installation.
Where Pith is reading between the lines
- If many agent platforms adopt model-in-skill bundles, attackers could target high-traffic skills to reach large numbers of users with a single upload.
- Runtime monitoring that flags unusual output patterns on parameter inputs could serve as a practical countermeasure beyond static vetting.
- The same poisoning approach might transfer to skills that bundle other model types, such as generators or planners, if their inputs contain similar semantic structure.
Load-bearing premise
The simulation environment used for testing accurately reflects how real agent platforms install, execute, and handle parameters from third-party skills.
What would settle it
Releasing a BadSkill-poisoned skill in a live agent platform and measuring whether the hidden payload executes on trigger-parameter queries without triggering normal detection mechanisms.
Figures



read the original abstract
Agent ecosystems increasingly rely on installable skills to extend functionality, and some skills bundle learned model artifacts as part of their execution logic. This creates a supply-chain risk that is not captured by prompt injection or ordinary plugin misuse: a third-party skill may appear benign while concealing malicious behavior inside its bundled model. We present BadSkill, a backdoor attack formulation that targets this model-in-skill threat surface. In BadSkill, an adversary publishes a seemingly benign skill whose embedded model is backdoor-fine-tuned to activate a hidden payload only when routine skill parameters satisfy attacker-chosen semantic trigger combinations. To realize this attack, we train the embedded classifier with a composite objective that combines classification loss, margin-based separation, and poison-focused optimization, and evaluate it in an OpenClaw-inspired simulation environment that preserves third-party skill installation and execution while enabling controlled multi-model study. Our benchmark spans 13 skills, including 8 triggered tasks and 5 non-trigger control skills, with a combined main evaluation set of 571 negative-class queries and 396 trigger-aligned queries. Across eight architectures (494M--7.1B parameters) from five model families, BadSkill achieves up to 99.5\% average attack success rate (ASR) across the eight triggered skills while maintaining strong benign-side accuracy on negative-class queries. In poison-rate sweeps on the standard test split, a 3\% poison rate already yields 91.7\% ASR. The attack remains effective across the evaluated model scales and under five text perturbation types. These findings identify model-bearing skills as a distinct model supply-chain risk in agent ecosystems and motivate stronger provenance verification and behavioral vetting for third-party skill artifacts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BadSkill, a backdoor attack on agent skills that bundle learned model artifacts. An adversary publishes a seemingly benign skill whose embedded model is fine-tuned with a composite objective (classification loss + margin separation + poison optimization) so that it activates a hidden payload only when routine skill parameters satisfy attacker-chosen semantic trigger combinations. The attack is evaluated in an OpenClaw-inspired simulation environment across 13 skills (8 triggered, 5 controls), 571 negative-class and 396 trigger queries, and eight architectures (494M–7.1B parameters) from five families. Reported results include up to 99.5% average ASR on triggered skills at 3% poison rate while preserving benign accuracy, with additional sweeps and robustness tests under text perturbations.
Significance. If the simulation faithfully reproduces real third-party skill installation, execution, and parameter semantics, the work identifies a distinct model supply-chain risk in agent ecosystems that is not covered by prompt-injection or plugin-misuse defenses. The concrete ASR numbers, poison-rate sweeps, multi-scale evaluation, and perturbation robustness constitute reproducible empirical evidence under the stated conditions and could motivate provenance and behavioral-vetting requirements for model-bearing skills.
major comments (1)
- [Evaluation / Simulation Environment] Evaluation / Simulation Environment (abstract and §4): The headline claims (99.5% ASR at 3% poison rate across eight models) rest entirely on results obtained inside the OpenClaw-inspired simulator. The manuscript asserts that this environment “preserves third-party skill installation and execution” and “parameter-passing semantics,” yet provides no fidelity audit, cross-platform replication on actual agent frameworks, or comparison of how parameters are wrapped/sanitized in real deployments. Because the trigger activation path depends on these semantics, any mismatch would invalidate transfer of the reported ASR numbers to practical settings.
minor comments (2)
- [Abstract] Abstract: states “strong benign-side accuracy” and “remains effective … under five text perturbation types” but supplies neither the exact benign accuracy figures nor the perturbation types or statistical significance tests.
- [Method] The composite training objective is described at a high level; a precise equation or pseudocode for the combined loss (classification + margin + poison term) would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the simulation environment and its implications for the attack's practical relevance. We address the major comment below and have revised the manuscript to improve clarity on the evaluation setup and its limitations.
read point-by-point responses
-
Referee: [Evaluation / Simulation Environment] Evaluation / Simulation Environment (abstract and §4): The headline claims (99.5% ASR at 3% poison rate across eight models) rest entirely on results obtained inside the OpenClaw-inspired simulator. The manuscript asserts that this environment “preserves third-party skill installation and execution” and “parameter-passing semantics,” yet provides no fidelity audit, cross-platform replication on actual agent frameworks, or comparison of how parameters are wrapped/sanitized in real deployments. Because the trigger activation path depends on these semantics, any mismatch would invalidate transfer of the reported ASR numbers to practical settings.
Authors: We agree that the evaluation is conducted entirely within the OpenClaw-inspired simulator and that the transferability of the reported ASR depends on how faithfully the simulation captures real parameter-passing semantics. The original manuscript described the environment as preserving installation, execution, and parameter semantics but did not include an explicit fidelity audit or side-by-side comparisons with live agent frameworks. In the revised manuscript we have expanded Section 4 with: (1) a detailed description of how the simulator implements parameter passing and sanitization based on OpenClaw's documented interfaces, (2) justification that the semantic trigger combinations are designed to be invariant to common low-level wrapping variations, and (3) a new limitations subsection that explicitly states the ASR results apply under the simulated conditions and that empirical validation on production agent platforms remains future work. These changes make the scope of the claims transparent without overstating generalizability. revision: yes
Circularity Check
No significant circularity; empirical ASR measured directly from simulation runs
full rationale
The paper describes an empirical backdoor attack formulation and reports measured attack success rates (ASR) and benign accuracy on held-out query sets inside an OpenClaw-inspired simulator. No equations, uniqueness theorems, or first-principles derivations are presented that reduce the reported ASR values to fitted parameters or self-citations by construction. The composite training objective is described at a high level without algebraic reduction to the target metric, and the 3% poison-rate result is obtained from direct experimental sweeps rather than statistical forcing. The evaluation therefore remains externally falsifiable and does not match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- poison rate
axioms (1)
- domain assumption The simulation environment preserves third-party skill installation and execution semantics
invented entities (1)
-
BadSkill attack formulation
no independent evidence
Forward citations
Cited by 3 Pith papers
-
Under the Hood of SKILL.md: Semantic Supply-chain Attacks on AI Agent Skill Registry
Semantic manipulations of SKILL.md descriptions enable effective supply-chain attacks that bias AI agent skill registries toward adversarial skills in discovery, selection, and governance.
-
AgentTrap: Measuring Runtime Trust Failures in Third-Party Agent Skills
AgentTrap shows that current LLM agents typically complete user tasks while silently accepting unsafe side effects from malicious third-party skills rather than refusing them.
-
SkillSafetyBench: Evaluating Agent Safety under Skill-Facing Attack Surfaces
SkillSafetyBench shows that localized non-user attacks via skills and artifacts can consistently induce unsafe agent behavior across domains and model backends, independent of user intent.
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. Phi-4 technical report.arXiv preprint arXiv:2412.08905, 2024
work page internal anchor Pith review arXiv 2024
-
[2]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Mitigating poison- ing attacks on machine learning models: A data provenance based approach
Nathalie Baracaldo, Bryant Chen, Heiko Ludwig, and Jaehoon Amir Safavi. Mitigating poison- ing attacks on machine learning models: A data provenance based approach. InProceedings of the 10th ACM workshop on artificial intelligence and security, pages 103–110, 2017
2017
-
[4]
Zheng Cai, Maosong Cao, Haojiong Chen, Kai Chen, Keyu Chen, Xin Chen, Xun Chen, Zehui Chen, Zhi Chen, Pei Chu, et al. Internlm2 technical report.arXiv preprint arXiv:2403.17297, 2024
work page internal anchor Pith review arXiv 2024
-
[5]
Langchain, 2022
Harrison Chase et al. Langchain, 2022
2022
-
[6]
Badnl: Backdoor attacks against nlp models with semantic- preserving improvements
Xiaoyi Chen, Ahmed Salem, Dingfan Chen, Michael Backes, Shiqing Ma, Qingni Shen, Zhonghai Wu, and Yang Zhang. Badnl: Backdoor attacks against nlp models with semantic- preserving improvements. InProceedings of the 37th Annual Computer Security Applications Conference, pages 554–569, 2021
2021
-
[7]
Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning
Xinyun Chen, Chang Liu, Bo Li, Kimberly Lu, and Dawn Song. Targeted backdoor attacks on deep learning systems using data poisoning.arXiv preprint arXiv:1712.05526, 2017
work page internal anchor Pith review arXiv 2017
-
[8]
Agentpoison: Red- teaming llm agents via poisoning memory or knowledge bases.Advances in Neural Information Processing Systems, 37:130185–130213, 2024
Zhaorun Chen, Zhen Xiang, Chaowei Xiao, Dawn Song, and Bo Li. Agentpoison: Red- teaming llm agents via poisoning memory or knowledge bases.Advances in Neural Information Processing Systems, 37:130185–130213, 2024
2024
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek DeepSeek-AI. r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025.URL: https://arxiv. org/abs/2501.12948, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Dataset security for machine learning: Data poisoning, backdoor attacks, and defenses.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(2):1563–1580, 2022
Micah Goldblum, Dimitris Tsipras, Chulin Xie, Xinyun Chen, Avi Schwarzschild, Dawn Song, Aleksander M ˛ adry, Bo Li, and Tom Goldstein. Dataset security for machine learning: Data poisoning, backdoor attacks, and defenses.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(2):1563–1580, 2022
2022
-
[11]
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
Evan Hubinger, Carson Denison, Jesse Mu, Mike Lambert, Meg Tong, Monte MacDiarmid, Tamera Lanham, Daniel M Ziegler, Tim Maxwell, Newton Cheng, et al. Sleeper agents: Training deceptive llms that persist through safety training.arXiv preprint arXiv:2401.05566, 2024
work page internal anchor Pith review arXiv 2024
-
[12]
Weight poisoning attacks on pretrained models
Keita Kurita, Paul Michel, and Graham Neubig. Weight poisoning attacks on pretrained models. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 2793–2806, 2020
2020
-
[13]
Backdoor learning: A survey.IEEE transactions on neural networks and learning systems, 35(1):5–22, 2022
Yiming Li, Yong Jiang, Zhifeng Li, and Shu-Tao Xia. Backdoor learning: A survey.IEEE transactions on neural networks and learning systems, 35(1):5–22, 2022
2022
-
[14]
Trojaning attack on neural networks
Yingqi Liu, Shiqing Ma, Yousra Aafer, Wen-Chuan Lee, Juan Zhai, Weihang Wang, and Xiangyu Zhang. Trojaning attack on neural networks. In25th Annual Network And Distributed System Security Symposium (NDSS 2018). Internet Soc, 2018
2018
-
[15]
Ignore Previous Prompt: Attack Techniques For Language Models
Fábio Perez and Ian Ribeiro. Ignore previous prompt: Attack techniques for language models. arXiv preprint arXiv:2211.09527, 2022
work page internal anchor Pith review arXiv 2022
-
[16]
Hidden killer: Invisible textual backdoor attacks with syntactic trigger
Fanchao Qi, Mukai Li, Yangyi Chen, Zhengyan Zhang, Zhiyuan Liu, Yasheng Wang, and Maosong Sun. Hidden killer: Invisible textual backdoor attacks with syntactic trigger. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers...
2021
-
[17]
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. Fine-tuning aligned language models compromises safety, even when users do not intend to! arXiv preprint arXiv:2310.03693, 2023
work page internal anchor Pith review arXiv 2023
-
[18]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis.arXiv preprint arXiv:2307.16789, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
A study of backdoors in instruction fine-tuned language models.arXiv preprint arXiv:2406.07778, 2024
Jayaram Raghuram, George Kesidis, and David J Miller. A study of backdoors in instruction fine-tuned language models.arXiv preprint arXiv:2406.07778, 2024
-
[20]
The dark side of the language: Pre-trained transformers in the darknet
Leonardo Ranaldi, Aria Nourbakhsh, Elena Sofia Ruzzetti, Arianna Patrizi, Dario Onorati, Michele Mastromattei, Francesca Fallucchi, and Fabio Massimo Zanzotto. The dark side of the language: Pre-trained transformers in the darknet. InProceedings of the 14th International Conference on Recent Advances in Natural Language Processing, pages 949–960, 2023
2023
-
[21]
Identifying the Risks of LM Agents with an LM-Emulated Sandbox
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J Maddison, and Tatsunori Hashimoto. Identifying the risks of lm agents with an lm-emulated sandbox.arXiv preprint arXiv:2309.15817, 2023
work page internal anchor Pith review arXiv 2023
-
[22]
Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36: 68539–68551, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36: 68539–68551, 2023
2023
-
[23]
Prompt injection attack to tool selection in llm agents.arXiv preprint arXiv:2504.19793, 2025
Jiawen Shi, Zenghui Yuan, Guiyao Tie, Pan Zhou, Neil Zhenqiang Gong, and Lichao Sun. Prompt injection attack to tool selection in llm agents.arXiv preprint arXiv:2504.19793, 2025
-
[24]
Certified defenses for data poisoning attacks.Advances in neural information processing systems, 30, 2017
Jacob Steinhardt, Pang Wei W Koh, and Percy S Liang. Certified defenses for data poisoning attacks.Advances in neural information processing systems, 30, 2017
2017
-
[25]
Identifying vulnerabilities in the machine learning model supply chain, 2019
Gu Tianyu, B Dolan-Gavitt, and S Garg. Identifying vulnerabilities in the machine learning model supply chain, 2019
2019
-
[26]
Poisoning language models during instruction tuning
Alexander Wan, Eric Wallace, Sheng Shen, and Dan Klein. Poisoning language models during instruction tuning. InInternational Conference on Machine Learning, pages 35413–35425. PMLR, 2023
2023
-
[27]
A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
2024
-
[28]
The rise and potential of large language model based agents: A survey.Science China Information Sciences, 68(2):121101, 2025
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. The rise and potential of large language model based agents: A survey.Science China Information Sciences, 68(2):121101, 2025
2025
-
[29]
Instructions as backdoors: Backdoor vulnerabilities of instruction tuning for large language models
Jiashu Xu, Mingyu Ma, Fei Wang, Chaowei Xiao, and Muhao Chen. Instructions as backdoors: Backdoor vulnerabilities of instruction tuning for large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 3111–3126, 2024
2024
-
[30]
Backdooring instruction-tuned large language models with virtual prompt injection
Jun Yan, Vikas Yadav, Shiyang Li, Lichang Chen, Zheng Tang, Hai Wang, Vijay Srinivasan, Xiang Ren, and Hongxia Jin. Backdooring instruction-tuned large language models with virtual prompt injection. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Lo...
2024
-
[31]
Auto-gpt for online decision making: Benchmarks and additional opinions, 2023
Hui Yang, Sifu Yue, and Yunzhong He. Auto-gpt for online decision making: Benchmarks and additional opinions, 2023
2023
-
[32]
Rethinking stealthiness of backdoor attack against nlp models
Wenkai Yang, Yankai Lin, Peng Li, Jie Zhou, and Xu Sun. Rethinking stealthiness of backdoor attack against nlp models. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 5543–5557, 2021. 12
2021
-
[33]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
2022
-
[34]
Toolsword: Unveiling safety issues of large language models in tool learning across three stages
Junjie Ye, Sixian Li, Guanyu Li, Caishuang Huang, Songyang Gao, Yilong Wu, Qi Zhang, Tao Gui, and Xuan-Jing Huang. Toolsword: Unveiling safety issues of large language models in tool learning across three stages. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2181–2211, 2024
2024
-
[35]
Yi: Open Foundation Models by 01.AI
Alex Young, Bei Chen, Chao Li, Chengen Huang, Ge Zhang, Guanwei Zhang, Guoyin Wang, Heng Li, Jiangcheng Zhu, Jianqun Chen, et al. Yi: Open foundation models by 01. ai.arXiv preprint arXiv:2403.04652, 2024
work page internal anchor Pith review arXiv 2024
-
[36]
R-judge: Benchmarking safety risk awareness for llm agents
Tongxin Yuan, Zhiwei He, Lingzhong Dong, Yiming Wang, Ruijie Zhao, Tian Xia, Lizhen Xu, Binglin Zhou, Fangqi Li, Zhuosheng Zhang, et al. R-judge: Benchmarking safety risk awareness for llm agents. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 1467–1490, 2024
2024
-
[37]
compact formatting
Rui Zhang, Hongwei Li, Rui Wen, Wenbo Jiang, Yuan Zhang, Michael Backes, Yun Shen, and Yang Zhang. Instruction backdoor attacks against customized {LLMs}. In33rd USENIX Security Symposium (USENIX Security 24), pages 1849–1866, 2024. 13 A Dataset and Trigger Construction Dataset Overview.The benchmark spans 13 skills in total, including 8 triggered skills ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.