Recognition: unknown
Sim-to-Real Transfer for Muscle-Actuated Robots via Generalized Actuator Networks
Pith reviewed 2026-05-10 16:49 UTC · model grok-4.3
The pith
Neural network models nonlinear muscle actuation from position data to enable sim-to-real policy transfer on tendon-driven robot.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose the Generalized Actuator Network (GeAN) that learns an actuation model directly from joint position trajectories. When integrated with rigid body dynamics simulation, this permits training of control policies entirely in simulation that transfer successfully to the real robot, as shown by precise goal-reaching and dynamic ball-in-a-cup behaviors on a tendon-driven pneumatic muscle arm.
What carries the argument
Generalized Actuator Network (GeAN), which is a neural network trained to reproduce actuator responses from position data and substitutes for direct modeling of nonlinear muscle dynamics in the simulation pipeline.
Load-bearing premise
A neural network fitted to joint position trajectories alone can capture the nonlinear actuator dynamics including friction and hysteresis with enough fidelity to allow zero-shot transfer of policies to the real robot.
What would settle it
Running the ball-in-a-cup policy on the physical PAMY2 robot and finding that the success rate does not match simulation results, or that adaptation is required, would show the actuator model does not support adequate transfer.
Figures











read the original abstract
Tendon drives paired with soft muscle actuation enable faster and safer robots while potentially accelerating skill acquisition. Still, these systems are rarely used in practice due to inherent nonlinearities, friction, and hysteresis, which complicate modeling and control. So far, these challenges have hindered policy transfer from simulation to real systems. To bridge this gap, we propose a sim-to-real pipeline that learns a neural network model of this complex actuation and leverages established rigid body simulation for the arm dynamics and interactions with the environment. Our method, called Generalized Actuator Network (GeAN), enables actuation model identification across a wide range of robots by learning directly from joint position trajectories rather than requiring torque sensors. Using GeAN on PAMY2, a tendon-driven robot powered by pneumatic artificial muscles, we successfully deploy precise goal-reaching and dynamic ball-in-a-cup policies trained entirely in simulation. To the best of our knowledge, this result constitutes the first successful sim-to-real transfer for a four-degrees-of-freedom muscle-actuated robot arm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Generalized Actuator Network (GeAN), a neural network trained exclusively on joint position trajectories to model nonlinear actuator dynamics (friction, hysteresis) in tendon-driven muscle-actuated robots. It integrates GeAN with rigid-body simulation to train policies entirely in simulation and reports zero-shot deployment on the physical PAMY2 4-DoF pneumatic artificial muscle robot for precise goal-reaching and dynamic ball-in-a-cup tasks, claiming this as the first successful sim-to-real transfer for such a system.
Significance. If the quantitative results hold, the work would be significant for enabling practical use of soft, nonlinear actuators in robotics by avoiding torque sensors and real-world adaptation, potentially accelerating development of faster and safer systems. The ball-in-a-cup result would be particularly notable as a falsifiable demonstration of dynamic transfer.
major comments (2)
- [Abstract] Abstract and experimental results section: the claim of successful real-hardware deployment of goal-reaching and ball-in-a-cup policies provides no quantitative metrics (success rates, position errors, timing statistics), baselines, ablations, or error analysis, so the support for zero-shot transfer cannot be evaluated.
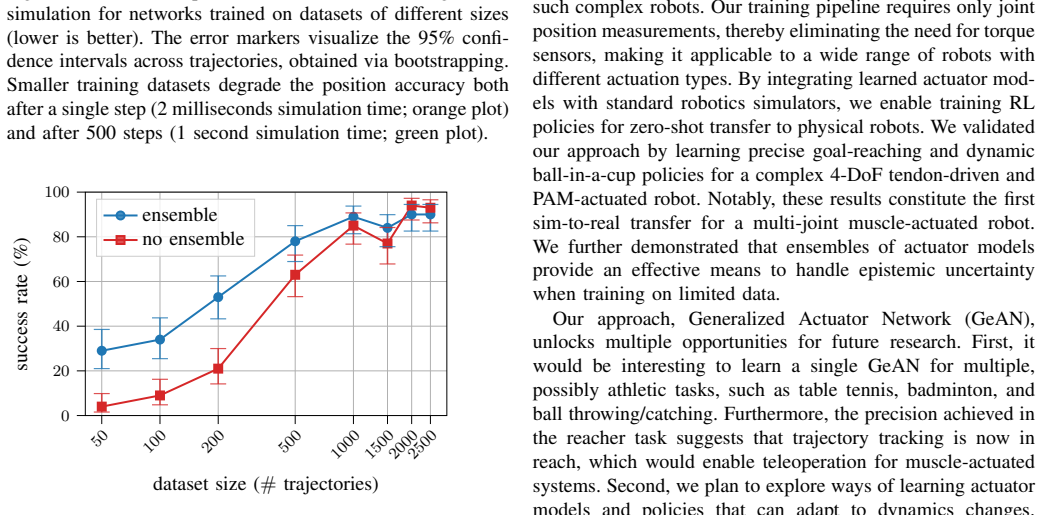
- [Method (GeAN)] GeAN training and data-collection description: training uses only observed joint positions without torque or velocity labels; it is unclear whether the collected trajectories cover the velocity/load/hysteresis regimes of the closed-loop ball-in-a-cup policy, leaving open the possibility that friction and pressure dynamics are mispredicted under rapid state-dependent commands.
minor comments (1)
- [Figures] Figure captions and text should explicitly state the number of real-robot trials and any failure modes observed during deployment.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of clarity and evidence in our presentation of the sim-to-real results. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental results section: the claim of successful real-hardware deployment of goal-reaching and ball-in-a-cup policies provides no quantitative metrics (success rates, position errors, timing statistics), baselines, ablations, or error analysis, so the support for zero-shot transfer cannot be evaluated.
Authors: We agree that the abstract and experimental results would benefit from explicit quantitative support for the zero-shot transfer claims. The manuscript reports successful deployment on the physical system, but to strengthen the evidence we will revise the abstract to include key metrics and expand the results section with success rates, mean position errors, timing statistics, baseline comparisons, and error analysis for both tasks. revision: yes
-
Referee: [Method (GeAN)] GeAN training and data-collection description: training uses only observed joint positions without torque or velocity labels; it is unclear whether the collected trajectories cover the velocity/load/hysteresis regimes of the closed-loop ball-in-a-cup policy, leaving open the possibility that friction and pressure dynamics are mispredicted under rapid state-dependent commands.
Authors: The GeAN training data were collected from a diverse set of position trajectories on the physical robot, including motions at varying speeds and under different loads to capture nonlinear effects such as friction and hysteresis. To address the concern about regime coverage for the ball-in-a-cup policy, we will revise the method section to provide a more detailed description of the data collection protocol and include supporting analysis (e.g., velocity and load distribution statistics) demonstrating that the training trajectories encompass the operating conditions of the closed-loop policy. revision: partial
Circularity Check
No significant circularity in the sim-to-real pipeline
full rationale
The paper describes a data-driven pipeline: collect real joint-position trajectories on the physical PAMY2 robot, train a neural network (GeAN) to model nonlinear actuator dynamics from those trajectories, insert the learned model into a rigid-body simulator, train policies in simulation, and deploy zero-shot on the real robot. No equation, definition, or claim reduces the reported transfer success to a fitted parameter by construction, nor does any load-bearing step rely on a self-citation chain that itself assumes the target result. The central claim remains an empirical demonstration whose validity is independently testable by repeating the data-collection and transfer experiments; it does not collapse into a renaming or tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rigid body dynamics and environmental interactions can be accurately simulated using established physics engines once actuator forces are provided.
invented entities (1)
-
Generalized Actuator Network (GeAN)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A lightweight robotic arm with pneumatic muscles for robot learning,
D. B ¨uchler, H. Ott, and J. Peters, “A lightweight robotic arm with pneumatic muscles for robot learning,” in IEEE International Conference on Robotics and Au- tomation, IEEE, 2016
2016
-
[2]
High-speed and lightweight humanoid robot arm for a skillful badminton robot,
S. Mori, K. Tanaka, S. Nishikawa, R. Niiyama, and Y . Kuniyoshi, “High-speed and lightweight humanoid robot arm for a skillful badminton robot,”IEEE Robotics and Automation Letters, vol. 3, no. 3, 2018
2018
-
[3]
Safe & Accurate at Speed with Tendons: A Robot Arm for Exploring Dynamic Motion,
S. Guist, J. Schneider, H. Ma, L. Chen, V . Berenz, J. Martus, H. Ott, F. Gr ¨uninger, M. Muehlebach, J. Fiene, B. Sch ¨olkopf, and D. B ¨uchler, “Safe & Accurate at Speed with Tendons: A Robot Arm for Exploring Dynamic Motion,” inRobotics: Science and Systems, 2024
2024
-
[4]
Component modularized design of musculoskeletal humanoid platform Musashi to investigate learning control systems,
K. Kawaharazuka, S. Makino, K. Tsuzuki, M. Onitsuka, Y . Nagamatsu, K. Shinjo, T. Makabe, Y . Asano, K. Okada, K. Kawasaki, et al., “Component modularized design of musculoskeletal humanoid platform Musashi to investigate learning control systems,” inIEEE/RSJ International Conference on Intelligent Robots and Sys- tems, IEEE, 2019
2019
-
[5]
Learning with muscles: Benefits for data-efficiency and robustness in anthro- pomorphic tasks,
I. Wochner, P. Schumacher, G. Martius, D. B ¨uchler, S. Schmitt, and D. Haeufle, “Learning with muscles: Benefits for data-efficiency and robustness in anthro- pomorphic tasks,” inConference on Robot Learning, PMLR, 2023
2023
-
[6]
A Learning-based Iterative Control Framework for Controlling a Robot Arm with Pneumatic Artificial Muscles,
H. Ma, D. B ¨uchler, B. Sch ¨olkopf, and M. Muehlebach, “A Learning-based Iterative Control Framework for Controlling a Robot Arm with Pneumatic Artificial Muscles,” inRobotics: Science and Systems, 2022
2022
-
[7]
Learning to play table tennis from scratch using muscular robots,
D. B ¨uchler, S. Guist, R. Calandra, V . Berenz, B. Sch¨olkopf, and J. Peters, “Learning to play table tennis from scratch using muscular robots,”IEEE Transactions on Robotics, vol. 38, no. 6, 2022
2022
-
[8]
Real-world humanoid locomotion with reinforcement learning,
I. Radosavovic, T. Xiao, B. Zhang, T. Darrell, J. Malik, and K. Sreenath, “Real-world humanoid locomotion with reinforcement learning,”Science Robotics, vol. 9, no. 89, 2024
2024
-
[9]
Learning sim-to-real humanoid locomotion in 15 minutes, 2025
Y . Seo, C. Sferrazza, J. Chen, G. Shi, R. Duan, and P. Abbeel, “Learning Sim-to-Real Humanoid Locomotion in 15 Minutes,”arXiv preprint arXiv:2512.01996, 2025
-
[10]
Z. Su, B. Zhang, N. Rahmanian, Y . Gao, Q. Liao, C. Regan, K. Sreenath, and S. S. Sastry, “HITTER: A humanoid table tennis robot via hierarchical planning and learning,”arXiv preprint arXiv:2508.21043, 2025
-
[11]
Learning Agile Striker Skills for Humanoid Soccer Robots from Noisy Sensory Input
Z. Xu, M. Seo, D. Lee, H. Fu, J. Hu, J. Cui, Y . Jiang, Z. Wang, A. Brund, J. Biswas, et al., “Learning Agile Striker Skills for Humanoid Soccer Robots from Noisy Sensory Input,”arXiv preprint arXiv:2512.06571, 2025
work page internal anchor Pith review arXiv 2025
-
[12]
Learning to walk in minutes using massively parallel deep rein- forcement learning,
N. Rudin, D. Hoeller, P. Reist, and M. Hutter, “Learning to walk in minutes using massively parallel deep rein- forcement learning,” inConference on Robot Learning, PMLR, 2022
2022
-
[13]
Sim-to-real transfer of robotic control with dynamics randomization,
X. B. Peng, M. Andrychowicz, W. Zaremba, and P. Abbeel, “Sim-to-real transfer of robotic control with dynamics randomization,” inIEEE International Con- ference on Robotics and Automation, IEEE, 2018
2018
-
[14]
Robot learning from randomized simulations: A review,
F. Muratore, F. Ramos, G. Turk, W. Yu, M. Gienger, and J. Peters, “Robot learning from randomized simulations: A review,”Frontiers in Robotics and AI, vol. 9, 2022
2022
-
[15]
Modelling of the McKibben artificial mus- cle: A review,
B. Tondu, “Modelling of the McKibben artificial mus- cle: A review,”Journal of Intelligent Material Systems and Structures, vol. 23, no. 3, 2012
2012
-
[16]
Control of musculoskeletal systems using learned dy- namics models,
D. B ¨uchler, R. Calandra, B. Sch ¨olkopf, and J. Peters, “Control of musculoskeletal systems using learned dy- namics models,”IEEE Robotics and Automation Let- ters, vol. 3, no. 4, 2018
2018
-
[17]
Domain Randomization via En- tropy Maximization,
G. Tiboni, P. Klink, J. Peters, T. Tommasi, C. D’Eramo, and G. Chalvatzaki, “Domain Randomization via En- tropy Maximization,” inInternational Conference on Learning Representations, 2024
2024
-
[18]
Hindsight States: Blending sim and real task elements for efficient reinforcement learning,
S. Guist, J. Schneider, A. Dittrich, V . Berenz, B. Sch¨olkopf, and D. B ¨uchler, “Hindsight States: Blending sim and real task elements for efficient reinforcement learning,” inRobotics: Science and Systems, 2023
2023
-
[19]
Learning agile and dynamic motor skills for legged robots,
J. Hwangbo, J. Lee, A. Dosovitskiy, D. Bellicoso, V . Tsounis, V . Koltun, and M. Hutter, “Learning agile and dynamic motor skills for legged robots,”Science Robotics, vol. 4, no. 26, 2019
2019
-
[20]
Learning quadrupedal locomotion over chal- lenging terrain,
J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter, “Learning quadrupedal locomotion over chal- lenging terrain,”Science robotics, vol. 5, no. 47, 2020
2020
-
[21]
DribbleBot: Dynamic Legged Manipulation in the Wild,
Y . Ji, G. B. Margolis, and P. Agrawal, “DribbleBot: Dynamic Legged Manipulation in the Wild,” inIEEE International Conference on Robotics and Automation, IEEE, 2023
2023
-
[22]
LAURON VI: A Six-Legged Robot for Dynamic Walk- ing,
C. Eichmann, S. Bellmann, N. H ¨ugel, L.-E. Enslin, C. Plasberg, G. Heppner, A. Roennau, and R. Dillmann, “LAURON VI: A Six-Legged Robot for Dynamic Walk- ing,” inInternational Conference on Advanced Robotics and Mechatronics, 2025
2025
-
[23]
Re- inforcement learning control for autonomous hydraulic material handling machines with underactuated tools,
F. A. Spinelli, P. Egli, J. Nubert, F. Nan, T. Bleumer, P. Goegler, S. Brockes, F. Hofmann, and M. Hutter, “Re- inforcement learning control for autonomous hydraulic material handling machines with underactuated tools,” inIEEE/RSJ International Conference on Intelligent Robots and Systems, IEEE, 2024
2024
-
[24]
V . Yuryev and J. Hughes, “Tendon Force Model- ing for Sim2Real Transfer of Reinforcement Learning Policies for Tendon-Driven Robots,”arXiv preprint arXiv:2603.04351, 2026
-
[25]
Bridging the Sim-to-Real Gap for Athletic Loco- Manipulation,
N. Fey, G. B. Margolis, M. Peticco, and P. Agrawal, “Bridging the Sim-to-Real Gap for Athletic Loco- Manipulation,” inRobotics: Science and Systems, 2025
2025
-
[26]
An Efficient Learning Control Framework With Sim-to- Real for String-Type Artificial Muscle-Driven Robotic Systems,
J. Tao, Y . Zhang, S. K. Rajendran, and F. Zhang, “An Efficient Learning Control Framework With Sim-to- Real for String-Type Artificial Muscle-Driven Robotic Systems,”IEEE/ASME Transactions on Mechatronics, 2025
2025
-
[27]
Develop- ment of a Variable-Stiffness Musculoskeletal Percussion Robot and Realization of Single-Stroke Motion through Sim-to-Real Transfer,
T. Biyajima, R. Yamazaki, and M. Okui, “Develop- ment of a Variable-Stiffness Musculoskeletal Percussion Robot and Realization of Single-Stroke Motion through Sim-to-Real Transfer,” in51st Annual Conference of the IEEE Industrial Electronics Society, IEEE, 2025
2025
-
[28]
Dynamic modeling and control of pneumatic artificial muscles via Deep Lagrangian Networks and Reinforce- ment Learning,
S. Wang, R. Wang, Y . Liu, Y . Zhang, and L. Hao, “Dynamic modeling and control of pneumatic artificial muscles via Deep Lagrangian Networks and Reinforce- ment Learning,”Engineering Applications of Artificial Intelligence, vol. 148, 2025
2025
-
[29]
Deep Lagrangian Networks: Using Physics as Model Prior for Deep Learning,
M. Lutter, C. Ritter, and J. Peters, “Deep Lagrangian Networks: Using Physics as Model Prior for Deep Learning,” inInternational Conference on Learning Representations, 2019
2019
-
[30]
Learning to Control Emulated Muscles in Real Robots: A Software Test Bed for Bio-Inspired Actuators in Hardware,
P. Schumacher, L. Krause, J. Schneider, D. B ¨uchler, G. Martius, and D. Haeufle, “Learning to Control Emulated Muscles in Real Robots: A Software Test Bed for Bio-Inspired Actuators in Hardware,” in10th IEEE RAS/EMBS International Conference for Biomedical Robotics and Biomechatronics, IEEE, 2024
2024
-
[31]
When to trust your model: Model-based policy optimization,
M. Janner, J. Fu, M. Zhang, and S. Levine, “When to trust your model: Model-based policy optimization,” Advances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[32]
Learning to control highly accelerated ballistic movements on muscular robots,
D. B ¨uchler, R. Calandra, and J. Peters, “Learning to control highly accelerated ballistic movements on muscular robots,”Robotics and Autonomous Systems, vol. 159, 2022
2022
-
[33]
MuJoCo: A physics engine for model-based control,
E. Todorov, T. Erez, and Y . Tassa, “MuJoCo: A physics engine for model-based control,” inIEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems, IEEE, 2012
2012
-
[34]
skrl: Modular and flexible li- brary for reinforcement learning,
A. Serrano-Mu ˜noz, D. Chrysostomou, S. Bøgh, and N. Arana-Arexolaleiba, “skrl: Modular and flexible li- brary for reinforcement learning,”Journal of Machine Learning Research, vol. 24, no. 254, 2023
2023
-
[35]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017. APPENDIXA COMPUTING VELOCITIES AND ACCELERATIONS Letq t be the real robot trajectory and˜q t the simulated trajectory fort∈ {0, . . . , T}. To compute the labels for the torque loss of Equation (1), we need to c...
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.