Recognition: unknown
Policy-Aware Edge LLM-RAG Framework for Internet of Battlefield Things Mission Orchestration
Pith reviewed 2026-05-10 15:54 UTC · model grok-4.3
The pith
A retrieval-augmented LLM framework with independent command verification detects policy violations in IoBT missions while running at edge speeds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
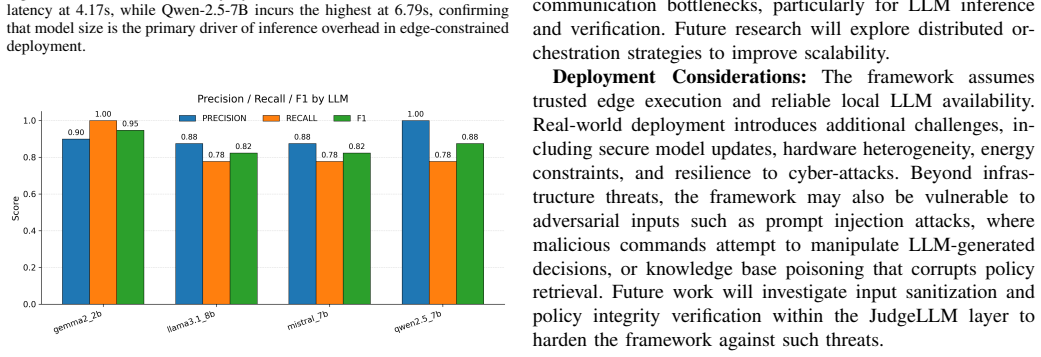
The PA-LLM-RAG framework combines a lightweight retrieval module that grounds decisions in operational policies and telemetry, a locally hosted LLM for mission planning, and a JudgeLLM for validating user-generated commands prior to execution, allowing effective detection of policy-violating requests across baseline, threat, recovery, coordination, and violation scenarios while maintaining low-latency responses suitable for edge deployment.
What carries the argument
The PA-LLM-RAG architecture, which pairs retrieval-augmented generation for policy grounding with a secondary JudgeLLM for command validation.
If this is right
- Intent-driven mission planning can proceed without direct exposure to policy or safety violations.
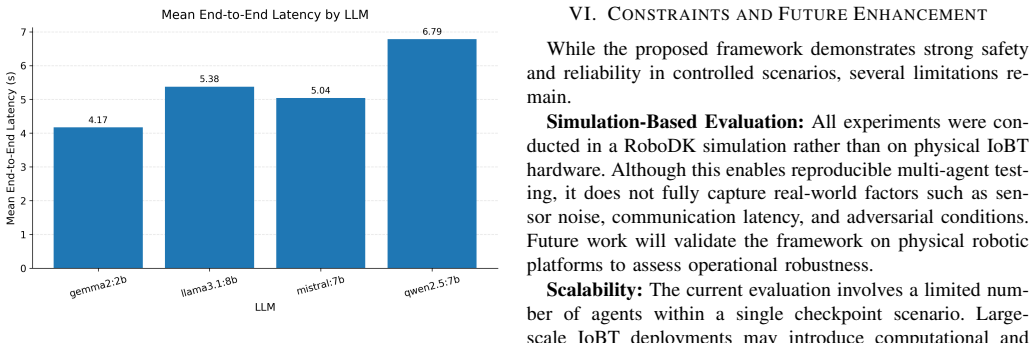
- Open-source models such as Gemma-2B can reach 100 percent success rates in controlled IoBT scenarios at roughly four seconds latency.
- A measurable tradeoff appears between model reasoning capacity and responsiveness across the tested LLMs.
- Combining retrieval-based grounding with independent verification raises overall reliability beyond either safeguard alone.
Where Pith is reading between the lines
- The same layered approach could transfer to other safety-critical robotic or autonomous systems that require policy compliance.
- Unmodeled real-world telemetry variations might reduce retrieval accuracy or increase false negatives not visible in the simulation.
- Extending the framework to larger multi-agent coordination tasks would reveal whether the current verification overhead scales.
Load-bearing premise
The RoboDK simulated IoBT environment and selected mission scenarios capture enough real-world policy complexity, telemetry noise, and adversarial conditions for the observed detection rates and latencies to transfer to physical systems.
What would settle it
A physical IoBT deployment test in which the framework either permits a policy-violating command or exceeds acceptable latency under variable real telemetry.
Figures



read the original abstract
Large Language Models (LLMs) offer a promising interface for intent-driven control of autonomous cyber-physical systems, but their direct use in mission-critical Internet of Battlefield Things (IoBT) environments raises significant safety, reliability, and policy-compliance concerns. This paper presents a Policy-Aware Large Language Model Retrieval-Augmented Generation (referred as PA-LLM-RAG), an edge-deployed LLM orchestration framework for IoBT mission control that integrates retrieval-augmented reasoning and independent command verification. The proposed PA-LLM-RAG framework combines a lightweight retrieval module that grounds decisions in operational policies and telemetry with a locally hosted LLM for mission planning and a secondary JudgeLLM for validating user generated commands prior to execution. To evaluate PA-LLM-RAG, we implement a simulated IoBT environment using RoboDK and assess four open-source LLMs across controlled mission scenarios of increasing complexity, including baseline operations, threat detection, coverage recovery, multi-event coordination, and policy-violation requests. Experimental results demonstrate that the framework effectively detects policy-violating commands while maintaining low-latency response suitable for edge deployment. Gemma-2B achieving the highest overall reliability with 4.17 sec latency and 100% success rate. The findings highlight a clear tradeoff between reasoning capacity and responsiveness across models and show that combining deterministic safeguards with JudgeLLM verification significantly improves reliability in LLM-driven IoBT orchestration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the PA-LLM-RAG framework, an edge-deployed LLM orchestration system for Internet of Battlefield Things (IoBT) mission control. It integrates a lightweight retrieval module that grounds decisions in operational policies and telemetry, a locally hosted LLM for mission planning, and a secondary JudgeLLM for independent verification of user commands. The framework is evaluated in a RoboDK-simulated IoBT environment across four open-source LLMs and five controlled mission scenarios of increasing complexity (baseline operations, threat detection, coverage recovery, multi-event coordination, and policy-violation requests). Results claim effective policy-violation detection with low latency suitable for edge deployment, with Gemma-2B achieving the highest reliability at 4.17 seconds latency and 100% success rate.
Significance. If the simulation results hold under more realistic conditions, the work offers a practical, empirically tested approach to mitigating safety and compliance risks when using LLMs for intent-driven control of autonomous cyber-physical systems in mission-critical settings. The explicit multi-model comparison across scenarios provides concrete data on the tradeoff between reasoning capacity and responsiveness, which is directly relevant to edge deployment constraints. The combination of deterministic RAG-based policy grounding with JudgeLLM verification is a clear methodological strength that addresses hallucination and non-compliance in a falsifiable way through controlled experiments.
major comments (1)
- [Experimental evaluation] Experimental evaluation (RoboDK scenarios): The four controlled scenarios (baseline, threat detection, coverage recovery, multi-event, policy-violation) are described as deterministic and noise-free, with no reported injection of telemetry noise, packet loss, sensor drift, or adversarial/obfuscated commands. Because the central claim is that PA-LLM-RAG reliably detects violations while maintaining low latency suitable for real edge IoBT deployment, the absence of these variability factors means the reported 100% success rate and 4.17s Gemma-2B latency do not yet establish robustness or transferability.
minor comments (2)
- [Abstract] Abstract: Specific performance numbers (4.17 sec latency, 100% success rate) are given without error bars, standard deviations across runs, or explicit baseline comparisons against non-RAG or non-JudgeLLM configurations, which would improve clarity of the reliability claims.
- [Discussion/Conclusion] Overall manuscript: The discussion of simulation limitations and the gap to physical IoBT deployments could be expanded to better contextualize the transferability of the observed metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important considerations for strengthening the claims regarding robustness in our simulated IoBT evaluation. We address the major comment point by point below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: Experimental evaluation (RoboDK scenarios): The four controlled scenarios (baseline, threat detection, coverage recovery, multi-event, policy-violation) are described as deterministic and noise-free, with no reported injection of telemetry noise, packet loss, sensor drift, or adversarial/obfuscated commands. Because the central claim is that PA-LLM-RAG reliably detects violations while maintaining low latency suitable for real edge IoBT deployment, the absence of these variability factors means the reported 100% success rate and 4.17s Gemma-2B latency do not yet establish robustness or transferability.
Authors: We agree that the evaluation uses deterministic, noise-free scenarios in the RoboDK simulator. This design was chosen to isolate the effects of the policy-aware RAG module and JudgeLLM verification on policy compliance without introducing confounding variables, allowing clear attribution of the observed 100% success rates to the framework components. We acknowledge that the absence of telemetry noise, packet loss, sensor drift, or adversarial commands limits direct extrapolation to real-world edge IoBT conditions and that the current results establish baseline performance rather than full robustness or transferability. In the revised manuscript, we have added a dedicated 'Limitations' subsection to the evaluation section that explicitly states these assumptions, discusses how the listed variability factors could affect latency and compliance detection, and outlines future extensions including noise injection and adversarial testing. We have also revised the abstract, results discussion, and conclusion to qualify the deployment suitability claims as applying to controlled simulated environments, providing a more balanced presentation of the work's scope. revision: yes
Circularity Check
No significant circularity: empirical simulation study with direct experimental results
full rationale
The paper presents an empirical framework proposal evaluated via RoboDK simulations across four controlled mission scenarios. No mathematical derivations, equations, parameter fittings, or self-citation chains are used to support central claims; success rates, latencies, and reliability metrics are reported as direct outcomes of the experiments. The work is self-contained with no load-bearing steps that reduce to inputs by construction, satisfying the default expectation for non-circular empirical studies.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can be reliably grounded in operational policies and telemetry through retrieval and independently verified by a secondary model before execution.
Reference graph
Works this paper leans on
-
[1]
The internet of battle things,
A. Kott, A. Swami, and B. J. West, “The internet of battle things,”IEEE Computer, vol. 49, no. 12, pp. 70–75, 2016
2016
-
[2]
The attack on colonial pipeline: What we’ve learned & what we’ve done over the past two years,
Cybersecurity and Infrastructure Security Agency (CISA), “The attack on colonial pipeline: What we’ve learned & what we’ve done over the past two years,” May 2023, accessed: 2026-03-07. [On- line]. Available: https://www.cisa.gov/news-events/news/attack-colonial- pipeline-what-weve-learned-what-weve-done-over-past-two-years
2023
-
[3]
Language models are few-shot learners,
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language models are few-shot learners,”Advances in Neural Information Processing Systems, vol. 33, 2020
2020
-
[4]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
On the Opportunities and Risks of Foundation Models
R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskillet al., “On the opportunities and risks of foundation models,”arXiv preprint arXiv:2108.07258, 2021
work page internal anchor Pith review arXiv 2021
-
[6]
Efficient prompting for llm-based generative internet of things,
B. Xiao, B. Kantarci, J. Kang, D. Niyato, and M. Guizani, “Efficient prompting for llm-based generative internet of things,”arXiv preprint arXiv:2406.10382, 2024
-
[7]
Talk with the things: Integrating llms into iot networks,
A. Kalita, “Talk with the things: Integrating llms into iot networks,” arXiv preprint arXiv:2507.17865, 2025
-
[8]
Edge computing: Vision and challenges,
W. Shi, J. Cao, Q. Zhang, Y . Li, and L. Xu, “Edge computing: Vision and challenges,”IEEE Internet of Things Journal, vol. 3, no. 5, pp. 637–646, 2016
2016
-
[9]
Towards edge general intelligence via large language models: Opportunities and challenges,
H. Chen, W. Deng, S. Yang, J. Xu, Z. Jiang, E. C. H. Ngai, J. Liu, and X. Liu, “Towards edge general intelligence via large language models: Opportunities and challenges,”arXiv preprint arXiv:2410.18125, 2025
-
[10]
Edgeshard: Efficient LLM inference via collaborative edge computing,
M. Zhang, X. Shen, J. Cao, Z. Cui, and S. Jiang, “Edgeshard: Efficient LLM inference via collaborative edge computing,”IEEE Internet of Things Journal, vol. 12, no. 10, pp. 13 119–13 131, 2025
2025
-
[11]
arXiv preprint arXiv:2309.16739 , year=
Z. Lin, G. Qu, Q. Chen, X. Chen, Z. Chen, and K. Huang, “Pushing large language models to the 6g edge: Vision, challenges, and opportunities,” 2025, arXiv preprint. [Online]. Available: https://arxiv.org/abs/2309.16739
-
[12]
Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models
Y . Zhang, Y . Li, L. Cui, D. Cai, L. Liu, T. Fu, X. Huang, E. Zhao, Y . Zhang, Y . Chen, L. Wang, A. Luu, W. Bi, F. Shi, and S. Shi, “Siren’s song in the AI ocean: A survey on hallucination in large language models,” 2023, arXiv preprint. [Online]. Available: https://arxiv.org/abs/2309.01219
work page internal anchor Pith review arXiv 2023
-
[13]
Retrieval-augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K¨uttler, M. Lewis, W.-t. Yih, T. Rockt¨aschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive nlp tasks,” Advances in Neural Information Processing Systems, vol. 33, 2020
2020
-
[14]
A survey on rag meets llms: Towards retrieval- augmented large language models,
Y . Gao, Y . Xiong, X. Gao, K. Jia, J. Pan, Y . Bi, Y . Dai, J. Sun, and H. Wang, “Retrieval-augmented generation for large language models: A survey,”arXiv preprint arXiv:2405.06211, 2024
-
[15]
R. Qin, Z. Yan, D. Zeng, Z. Jia, D. Liu, J. Liu, A. Abbasi, Z. Zheng, N. Cao, K. Ni, J. Xiong, and Y . Shi, “Robust implementation of retrieval-augmented generation on edge-based computing-in-memory architectures,”arXiv preprint arXiv:2405.04700, 2024
-
[16]
Edgerag: Online-indexed rag for edge devices,
K. Seemakhupt, S. Liu, and S. Khan, “Edgerag: Online-indexed rag for edge devices,”arXiv preprint arXiv:2412.21023, 2024
-
[17]
doi:10.48550/arXiv.2401.00396 , abstract =
Y . Wu, J. Zhu, S. Xu, K. Shum, C. Niu, R. Zhong, J. Song, and T. Zhang, “Ragtruth: A hallucination corpus for developing trustworthy retrieval-augmented language models,” 2024, arXiv preprint. [Online]. Available: https://arxiv.org/abs/2401.00396
-
[18]
Enhancing autonomous driving systems with on-board deployed large language models,
N. Baumann, C. Hu, P. Sivasothilingam, and H. Qin, “Enhancing autonomous driving systems with on-board deployed large language models,” 2025, arXiv preprint. [Online]. Available: https://arxiv.org/abs/2504.11514
-
[19]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. Le Scao, T. Lavril, T. Wang, T. Lacroix, and W. El Sayed, “Mistral 7b,”arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
J. Baiet al., “Qwen technical report,”arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
X. Huang, W. Ruan, W. Huang, G. Jin, Y . Dong, C. Wu, S. Bensalem, R. Mu, Y . Qi, X. Zhao, K. Cai, Y . Zhang, S. Wu, P. Xu, D. Wu, A. Freitas, and M. A. Mustafa, “A survey of safety and trustworthiness of large language models through the lens of verification and validation,” Artificial Intelligence Review, May 2023, arXiv:2305.11391
-
[22]
On the secure and reconfigurable multi-layer network design for critical information dissemination in the internet of battlefield things (iobt),
M. J. Farooq and Q. Zhu, “On the secure and reconfigurable multi-layer network design for critical information dissemination in the internet of battlefield things (iobt),”IEEE Transactions on Wireless Communica- tions, vol. 17, no. 4, pp. 2618–2632, January 2018
2018
-
[23]
When iot meet llms: Applica- tions and challenges,
I. Kok, O. Demirci, and S. ¨Ozdemir, “When iot meet llms: Applica- tions and challenges,” inProceedings of the 2024 IEEE International Conference on Big Data (BigData), November 2024, pp. 1–10
2024
-
[24]
Llm-based multi-class attack analysis and mitigation framework in iot/iiot networks,
S. Ikbarieh, M. Gupta, and E. Mahalal, “Llm-based multi-class attack analysis and mitigation framework in iot/iiot networks,” inIEEE Global Conference on Artificial Intelligence and Internet of Things, 2025
2025
-
[25]
Rag-targeted adversarial attack on llm-based threat detection and mitigation framework,
S. Ikbarieh, K. Aryal, and M. Gupta, “Rag-targeted adversarial attack on llm-based threat detection and mitigation framework,”arXiv preprint arXiv:2511.06212, 2025
-
[26]
Judging llm-as-a-judge with mt-bench and chatbot arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. P. Xing, H. Zhang, J. E. Gonzalez, and I. Stoica, “Judging llm-as-a-judge with mt-bench and chatbot arena,” inNeurIPS 2023 Track on Datasets and Benchmarks, 2023
2023
-
[27]
J. Gu, X. Jiang, Z. Shi, H. Tan, X. Zhai, C. Xu, W. Li, Y . Shen, S. Ma, H. Liu, S. Wang, K. Zhang, Z. Lin, B. Zhang, L. Ni, W. Gao, Y . Wang, and J. Guo, “A survey on llm-as-a-judge,”arXiv preprint arXiv:2411.15594, 2024. APPENDIXA MISSIONCOMMANDSET This appendix provides the complete mission command set used for evaluation. Each command was issued verba...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.