Recognition: unknown
Seeing is Believing: Robust Vision-Guided Cross-Modal Prompt Learning under Label Noise
Pith reviewed 2026-05-10 17:11 UTC · model grok-4.3
The pith
Visual guidance via cross-modal attention makes prompt learning robust to label noise without retraining the backbone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VisPrompt exploits a cross-modal attention mechanism to reversely inject visual semantics into prompt representations so that prompt tokens selectively aggregate relevant visual information for the current sample. A lightweight conditional modulation mechanism then adaptively controls the strength of this injection on a per-sample basis, striking a balance between text-side semantic priors and image-side instance evidence. This suppresses noise-induced disturbances, reduces instability in prompt updates, and alleviates memorization of mislabeled samples while keeping the pretrained VLM backbone frozen and adding only a small number of trainable parameters.
What carries the argument
cross-modal attention plus conditional modulation that reversely injects visual semantics into prompt tokens
If this is right
- Prompt updates remain stable even when a substantial fraction of labels are wrong.
- Only a small set of additional parameters needs training while the large pretrained vision-language backbone stays frozen.
- The approach reduces the tendency of prompt learning to memorize mislabeled examples.
- Performance gains hold across both synthetic noise and real-world noisy datasets on seven different benchmarks.
Where Pith is reading between the lines
- The same visual-anchoring idea could be applied to other parameter-efficient adaptation techniques such as adapters or low-rank updates.
- If visual evidence is the stable anchor, the method might also improve robustness when noise is present in the images themselves rather than only in the labels.
- The per-sample modulation could be replaced by a learned gating network without changing the core claim that vision should guide prompt updates.
Load-bearing premise
Visual content stays reliably more robust than prompt tokens under label noise, and the attention-plus-modulation step can selectively pull in useful visual evidence without creating new instabilities or needing per-dataset tuning.
What would settle it
A controlled experiment on one of the seven benchmarks in which VisPrompt produces lower accuracy than a standard prompt-learning baseline when the same noisy labels are used.
Figures
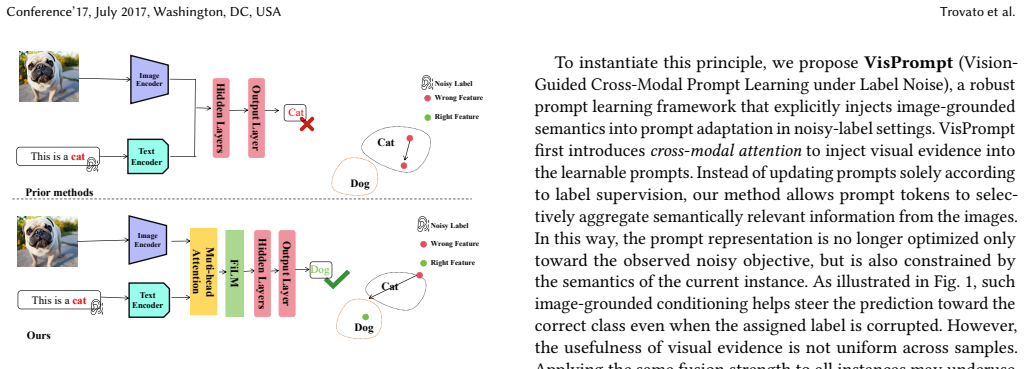



read the original abstract
Prompt learning is a parameter-efficient approach for vision-language models, yet its robustness under label noise is less investigated. Visual content contains richer and more reliable semantic information, which remains more robust under label noise. However, the prompt itself is highly susceptible to label noise. Motivated by this intuition, we propose VisPrompt, a lightweight and robust vision-guided prompt learning framework for noisy-label settings. Specifically, we exploit a cross-modal attention mechanism to reversely inject visual semantics into prompt representations. This enables the prompt tokens to selectively aggregate visual information relevant to the current sample, thereby improving robustness by anchoring prompt learning to stable instance-level visual evidence and reducing the influence of noisy supervision. To address the instability caused by using the same way of injecting visual information for all samples, despite differences in the quality of their visual cues, we further introduce a lightweight conditional modulation mechanism to adaptively control the strength of visual information injection, which strikes a more robust balance between text-side semantic priors and image-side instance evidence. The proposed framework effectively suppresses the noise-induced disturbances, reduce instability in prompt updates, and alleviate memorization of mislabeled samples. VisPrompt significantly improves robustness while keeping the pretrained VLM backbone frozen and introducing only a small amount of additional trainable parameters. Extensive experiments under synthetic and real-world label noise demonstrate that VisPrompt generally outperforms existing baselines on seven benchmark datasets and achieves stronger robustness. Our code is publicly available at https://github.com/gezbww/Vis_Prompt.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VisPrompt, a lightweight vision-guided prompt learning framework for vision-language models under label noise. It uses cross-modal attention to inject visual semantics into prompt tokens for anchoring to instance-level evidence, combined with a conditional modulation mechanism to adaptively scale the injection strength per sample. The VLM backbone remains frozen, adding only a small number of trainable parameters. Experiments under synthetic and real-world label noise on seven benchmark datasets show that VisPrompt generally outperforms baselines and achieves stronger robustness.
Significance. If the empirical claims hold, the work addresses an important practical gap in making prompt learning robust to label noise while preserving parameter efficiency. The public code release supports reproducibility. The approach could influence multimodal fine-tuning pipelines in noisy real-world settings, provided the modulation reliably leverages visual robustness without introducing new instabilities.
major comments (2)
- [§3.2] §3.2 (Conditional Modulation): The modulation parameters are optimized end-to-end with the same noisy-label cross-entropy loss used for the rest of the model. This creates a circularity risk: if the modulator cannot reliably distinguish clean from noisy samples (due to corrupted supervision), it may under-inject on clean examples or over-inject on noisy ones, undermining the claimed robustness gain. The manuscript should include an ablation isolating the modulator (e.g., performance on a clean validation subset or comparison against a noise-aware regularizer) to substantiate that it “strikes a more robust balance.”
- [§4] §4 (Experiments, Tables 1–3): The central claim of consistent outperformance and stronger robustness is load-bearing, yet the reported results lack per-dataset noise-rate breakdowns, statistical significance tests (e.g., paired t-tests or confidence intervals), and explicit baseline hyperparameter details. Without these, it is difficult to verify that gains are attributable to the vision-guided components rather than implementation differences.
minor comments (2)
- [Abstract] Abstract: Minor grammatical issues (“reduce instability”, “suppresses … reduce”) and the phrase “generally outperforms” should be replaced with precise quantitative statements once the tables are finalized.
- [§3.1] §3.1: The cross-modal attention formulation would benefit from an explicit equation showing how visual features are projected and attended into the prompt token space, to clarify the “reverse injection” mechanism.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point-by-point below and will incorporate the suggested revisions to strengthen the paper.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Conditional Modulation): The modulation parameters are optimized end-to-end with the same noisy-label cross-entropy loss used for the rest of the model. This creates a circularity risk: if the modulator cannot reliably distinguish clean from noisy samples (due to corrupted supervision), it may under-inject on clean examples or over-inject on noisy ones, undermining the claimed robustness gain. The manuscript should include an ablation isolating the modulator (e.g., performance on a clean validation subset or comparison against a noise-aware regularizer) to substantiate that it “strikes a more robust balance.”
Authors: We appreciate the referee highlighting this potential circularity in end-to-end optimization of the modulation parameters under noisy supervision. While the design leverages the relative robustness of visual features to mitigate noise influence on prompt updates, we agree that isolating the modulator's contribution is important for substantiating the adaptive balance claim. In the revised manuscript, we will add a dedicated ablation study that evaluates the modulator on clean validation subsets (where available in the benchmarks) and compares against fixed-modulation and noise-aware regularizer baselines to demonstrate its effectiveness without introducing instabilities. revision: yes
-
Referee: [§4] §4 (Experiments, Tables 1–3): The central claim of consistent outperformance and stronger robustness is load-bearing, yet the reported results lack per-dataset noise-rate breakdowns, statistical significance tests (e.g., paired t-tests or confidence intervals), and explicit baseline hyperparameter details. Without these, it is difficult to verify that gains are attributable to the vision-guided components rather than implementation differences.
Authors: We agree that these additional details are necessary to rigorously support the empirical claims and enable verification of the gains from the vision-guided components. In the revised version, we will expand Tables 1–3 with per-dataset noise-rate breakdowns for the synthetic noise settings, report statistical significance via paired t-tests (or confidence intervals) across multiple random seeds, and provide explicit hyperparameter configurations for all baselines to ensure fair comparison and reproducibility. revision: yes
Circularity Check
No derivation chain present; engineering framework without mathematical reductions or self-referential fits
full rationale
The manuscript describes VisPrompt as a practical framework that adds cross-modal attention and conditional modulation to frozen VLMs for noisy-label prompt learning. No equations, derivations, or parameter-fitting steps are referenced that reduce a claimed prediction or result back to the inputs by construction. The approach is motivated by intuition about visual robustness and validated through experiments on seven datasets; it contains no self-definitional loops, fitted-input predictions, or load-bearing self-citations that would create circularity. The central claims rest on empirical performance rather than any closed-form equivalence to the training procedure itself.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Visual content contains richer and more reliable semantic information than noisy text labels.
- domain assumption Cross-modal attention can selectively aggregate relevant visual information into prompt tokens.
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
Haw-Shiuan Chang, Erik Learned-Miller, and Andrew McCallum. 2017. Active Bias: Training More Accurate Neural Networks by Emphasizing High Variance Samples.Advances in Neural Information Processing Systems30 (2017)
2017
-
[4]
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and An- drea Vedaldi. 2014. Describing Textures in the Wild. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 3606–3613
2014
-
[5]
Marco Cuturi. 2013. Sinkhorn Distances: Lightspeed Computation of Optimal Transport. InAdvances in Neural Information Processing Systems, C.J. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K.Q. Weinberger (Eds.), Vol. 26. Cur- ran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/2013/file/ af21d0c97db2e27e13572cbf59eb343d-Paper.pdf
2013
-
[6]
Li Fei-Fei, Rob Fergus, and Pietro Perona. 2004. Learning Generative Visual Models from Few Training Examples: An Incremental Bayesian Approach Tested on 101 Object Categories. In2004 Conference on Computer Vision and Pattern Recognition Workshop. IEEE, 178–178
2004
-
[7]
Lei Feng, Senlin Shu, Zhuoyi Lin, Fengmao Lv, Li Li, and Bo An. 2021. Can Cross Entropy Loss Be Robust to Label Noise?. InProceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence. 2206–2212
2021
-
[8]
Shanti Sastry
Aritra Ghosh, Himanshu Kumar, and P. Shanti Sastry. 2017. Robust Loss Func- tions under Label Noise for Deep Neural Networks. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 31
2017
-
[9]
Guo et al
Y. Guo et al. 2024. JoAPR: Cleaning the Lens of Prompt Learning for Vision- Language Models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2024
-
[10]
Zhang, Shaoqing Ren, and Jian Sun
Kaiming He, X. Zhang, Shaoqing Ren, and Jian Sun. 2015. Deep Residual Learning for Image Recognition.2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)(2015), 770–778. https://api.semanticscholar.org/CorpusID: 206594692
2015
-
[11]
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. 2019. Eurosat: A Novel Dataset and Deep Learning Benchmark for Land Use and Land Cover Classification.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing12, 7 (2019), 2217–2226
2019
-
[12]
Dan Hendrycks, Kimin Lee, and Mantas Mazeika. 2019. Using Pre-Training Can Improve Model Robustness and Uncertainty. InInternational Conference on Machine Learning. PMLR, 2712–2721
2019
-
[13]
Changhui Hu, Bhalaji Nagarajan, Ricardo Marques, and Petia Radeva Ivanova
-
[14]
In36th British Machine Vision Conference 2025, BMVC 2025, Sheffield, UK, November 24-27, 2025
Dual Polarity Prompts with Stochastic Entropy Perturbation for Label Noise. In36th British Machine Vision Conference 2025, BMVC 2025, Sheffield, UK, November 24-27, 2025. BMVA. https://bmva-archive.org.uk/bmvc/2025/assets/ papers/Paper_992/paper.pdf
2025
-
[15]
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. 2021. Scaling up visual and vision-language representation learning with noisy text supervision. InICML. PMLR, 4904–4916
2021
-
[16]
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. 2022. Visual Prompt Tuning. InEuropean Conference on Computer Vision (ECCV)
2022
- [17]
-
[18]
Xuefeng Jiang, Sheng Sun, Yuwei Wang, and Min Liu. 2022. Towards federated learning against noisy labels via local self-regularization. InProceedings of the 31st ACM International Conference on Information & Knowledge Management. 862–873
2022
-
[19]
Xuefeng Jiang, Tian Wen, Sheng Sun, Jinliang Yuan, Huashuo Liu, Peng Li, Lihua Wu, Yuwei Wang, and Min Liu. 2025. Representation Optimal Matching for Federated Learning with Noisy Labels in Remote Sensing.IEEE Transactions on Mobile Computing(2025). doi:10.1109/TMC.2025.3649179
-
[20]
Baoshuo Kan, Teng Wang, Wenpeng Lu, Xiantong Zhen, Weili Guan, and Feng Zheng. 2023. Knowledge-Aware Prompt Tuning for Generalizable Vision- Language Models.2023 IEEE/CVF International Conference on Computer Vision (ICCV)(2023), 15624–15634. https://api.semanticscholar.org/CorpusID:261064889
2023
-
[21]
Muhammad Uzair Khattak, Hanoona Rasheed, Muhammad Maaz, Salman Khan, and Fahad Shahbaz Khan. 2023. Maple: Multi-modal Prompt Learning. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Conference’17, July 2017, Washington, DC, USA Trovato et al. 19113–19122
2023
-
[22]
Alexander Kolesnikov, Alexey Dosovitskiy, Dirk Weissenborn, Georg Heigold, Jakob Uszkoreit, Lucas Beyer, Matthias Minderer, Mostafa Dehghani, Neil Houlsby, Sylvain Gelly, Thomas Unterthiner, and Xiaohua Zhai. 2021. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
2021
-
[23]
Marc Lafon, Elias Ramzi, Clément Rambour, Nicolas Audebert, and Nicolas Thome
-
[24]
In European Conference on Computer Vision
Gallop: Learning global and local prompts for vision-language models. In European Conference on Computer Vision. Springer, 264–282
-
[25]
Kimin Lee, Sukmin Yun, Kibok Lee, Honglak Lee, Bo Li, and Jinwoo Shin. 2019. Robust Inference via Generative Classifiers for Handling Noisy Labels. InInter- national Conference on Machine Learning. PMLR, 3763–3772
2019
-
[26]
Kuang-Huei Lee, Xiaodong He, Lei Zhang, and Linjun Yang. 2018. Cleannet: Transfer Learning for Scalable Image Classifier Training with Label Noise. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 5447–5456
2018
-
[27]
Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The Power of Scale for Parameter-Efficient Prompt Tuning. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Online and Punta Cana, Dominican Republic, 3045–3059. doi:10. 18653/v1/2021.emnlp-main.243
2021
-
[28]
Junnan Li, Richard Socher, and Steven CH Hoi. 2020. DivideMix: Learning with Noisy Labels as Semi-supervised Learning. InInternational Conference on Learning Representations
2020
-
[29]
Xiang Lisa Li and Percy Liang. 2021. Prefix-Tuning: Optimizing Continuous Prompts for Generation. InProceedings of the 59th Annual Meeting of the Associa- tion for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli (Eds.). Ass...
-
[30]
Zheng Li, Yibing Song, Ming-Ming Cheng, Xiang Li, and Jian Yang. 2025. Ad- vancing textual prompt learning with anchored attributes. InProceedings of the IEEE/CVF International Conference on Computer Vision. 3618–3627
2025
- [31]
- [32]
- [33]
-
[34]
Reddi, and Sanjiv Kumar
Aditya Krishna Menon, Ankit Singh Rawat, Sashank J. Reddi, and Sanjiv Kumar
-
[35]
InInternational Conference on Learning Representations
Can Gradient Clipping Mitigate Label Noise?. InInternational Conference on Learning Representations
-
[36]
Diamos, Erich Elsen, David García, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, and Hao Wu
Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory F. Diamos, Erich Elsen, David García, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, and Hao Wu. 2018. Mixed Precision Training. In6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. ...
2018
-
[37]
Maria-Elena Nilsback and Andrew Zisserman. 2008. Automated Flower Clas- sification over a Large Number of Classes. In2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing. IEEE, 722–729
2008
-
[38]
Pan et al
B. Pan et al. 2025. NLPrompt: Noise-Label Prompt Learning for Vision-Language Models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2025
-
[39]
Parkhi, Andrea Vedaldi, Andrew Zisserman, and C
Omkar M. Parkhi, Andrea Vedaldi, Andrew Zisserman, and C. V. Jawahar. 2012. Cats and Dogs. In2012 IEEE Conference on Computer Vision and Pattern Recogni- tion. IEEE, 3498–3505
2012
-
[40]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gre- gory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, and Luca Antiga
-
[41]
Advances in neural information processing systems32 (2019)
Pytorch: An Imperative Style, High-Performance Deep Learning Library. Advances in neural information processing systems32 (2019)
2019
-
[42]
Deep Patel and P. S. Sastry. 2023. Adaptive Sample Selection for Robust Learn- ing under Label Noise. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 3932–3942
2023
-
[43]
Yuxin Peng, Yunzhen Zhao, and Junchao Zhang. 2018. Two-Stream Collabora- tive Learning with Spatial-Temporal Attention for Video Classification.IEEE Transactions on Circuits and Systems for Video Technology29, 3 (2018), 773–786
2018
-
[44]
Courville
Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron C. Courville. 2018. FiLM: Visual Reasoning with a General Conditioning Layer. In AAAI
2018
-
[45]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, and Jack Clark
-
[46]
In International conference on machine learning
Learning transferable visual models from natural language supervision. In International conference on machine learning. PMLR, 8748–8763
-
[47]
René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. 2021. Vision Transformers for Dense Prediction.ArXiv preprint(2021)
2021
-
[48]
Hwanjun Song, Minseok Kim, and Jae-Gil Lee. 2019. Selfie: Refurbishing Un- clean Samples for Robust Deep Learning. InInternational Conference on Machine Learning. PMLR, 5907–5915
2019
-
[49]
Jie Tan, Yu Rong, Kangfei Zhao, Tian Bian, Tingyang Xu, Junzhou Huang, Hong Cheng, and Helen Meng. 2024. Natural Language-Assisted Multi-modal Med- ication Recommendation. InProceedings of the 33rd ACM International Con- ference on Information and Knowledge Management(Boise, ID, USA)(CIKM ’24). Association for Computing Machinery, New York, NY, USA, 2200–...
-
[50]
Yusuke Tsuzuku, Issei Sato, and Masashi Sugiyama. 2018. Lipschitz-Margin Train- ing: Scalable Certification of Perturbation Invariance for Deep Neural Networks. InAdvances in Neural Information Processing Systems, S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett (Eds.), Vol. 31. Cur- ran Associates, Inc. https://proceeding...
2018
-
[51]
Tong Wei, Hao-Tian Li, Chun-Shu Li, Jiang-Xin Shi, Yu-Feng Li, and Min-Ling Zhang. 2024. Vision-Language Models are Strong Noisy Label Detectors. In Advances in Neural Information Processing Systems 37
2024
-
[52]
Cheng-En Wu, Yu Tian, Haichao Yu, Heng Wang, Pedro Morgado, Yu Hen Hu, and Linjie Yang. 2023. Why Is Prompt Tuning for Vision-Language Models Robust to Noisy Labels?. InProceedings of the IEEE/CVF International Conference on Computer Vision. 15488–15497
2023
-
[53]
Xiaobo Xia, Tongliang Liu, Bo Han, Chen Gong, Nannan Wang, Zongyuan Ge, and Yi Chang. 2020. Robust Early-Learning: Hindering the Memorization of Noisy Labels. InInternational Conference on Learning Representations
2020
-
[54]
Xiaobo Xia, Tongliang Liu, Nannan Wang, Bo Han, Chen Gong, Gang Niu, and Masashi Sugiyama. 2019. Are Anchor Points Really Indispensable in Label-Noise Learning?Advances in neural information processing systems32 (2019)
2019
-
[55]
Tsang, Ya Zhang, Jun Sun, Chengqi Zhang, and Rui Zhang
Jiangchao Yao, Jiajie Wang, Ivor W. Tsang, Ya Zhang, Jun Sun, Chengqi Zhang, and Rui Zhang. 2018. Deep Learning from Noisy Image Labels with Quality Embedding.IEEE Transactions on Image Processing28, 4 (2018), 1909–1922
2018
-
[56]
Yu Yao, Tongliang Liu, Bo Han, Mingming Gong, Jiankang Deng, Gang Niu, and Masashi Sugiyama. 2020. Dual T: Reducing Estimation Error for Transition Matrix in Label-Noise Learning.Advances in neural information processing systems33 (2020), 7260–7271
2020
-
[57]
Xueyi Zhang, Peiyin Zhu, Yuan Liao, Xiyu Wang, Mingrui Lao, Siqi Cai, Yanming Guo, and Haizhou Li. 2025. TrustCLIP: Learning from Noisy Labels via Semantic Label Verification and Trust-aligned Gradient Projection. InProceedings of the 33rd ACM International Conference on Multimedia(Dublin, Ireland)(MM ’25). Association for Computing Machinery, New York, N...
-
[58]
Zhilu Zhang and Mert R. Sabuncu. 2018. Generalized cross entropy loss for training deep neural networks with noisy labels. InProceedings of the 32nd International Conference on Neural Information Processing Systems(Montréal, Canada)(NIPS’18). Curran Associates Inc., Red Hook, NY, USA, 8792–8802
2018
-
[59]
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. 2022. Conditional Prompt Learning for Vision-Language Models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 16816–16825
2022
-
[60]
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. 2022. Learning to prompt for vision-language models.International Journal of Computer Vision 130, 9 (2022), 2337–2348. ISBN: 0920-5691 Publisher: Springer
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.