Recognition: no theorem link
Seven simple steps for log analysis in AI systems
Pith reviewed 2026-05-15 22:07 UTC · model grok-4.3
The pith
A seven-step pipeline turns AI system logs into rigorous, reproducible analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
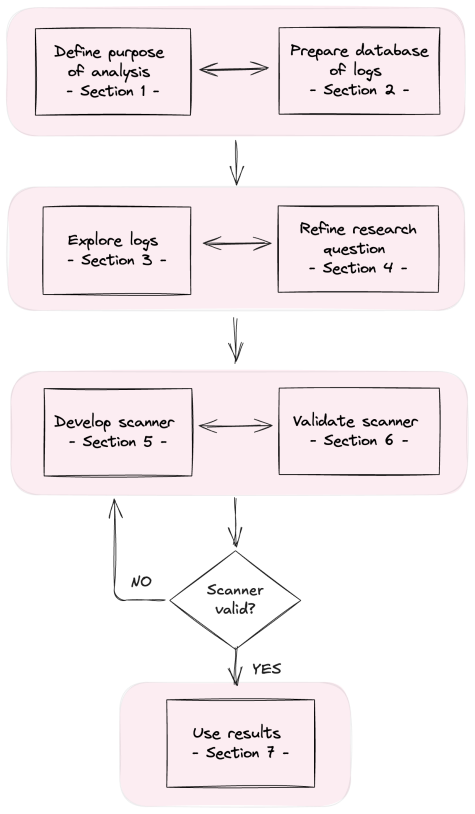
The authors introduce a seven-step pipeline grounded in existing best practices for analyzing logs from AI systems. The steps are illustrated with code examples and include explicit guidance on each stage plus warnings about frequent errors, with the overall goal of enabling rigorous and reproducible insights into model performance and evaluation validity.
What carries the argument
The seven-step pipeline, which structures log processing from initial collection through cleaning, analysis, interpretation, and validation.
If this is right
- Researchers gain a shared structure for reviewing AI interactions that reduces variability in reported findings.
- Evaluations of model behavior become easier to verify as having worked as intended.
- Common pitfalls such as incomplete cleaning or misinterpretation of logs are addressed systematically.
- Reproducibility of log-derived conclusions increases because each step is documented and illustrated.
- Future work can build on this pipeline by adding automated checks or domain-specific extensions.
Where Pith is reading between the lines
- Wider adoption could improve how AI papers document and share evidence from system logs.
- The steps might encourage benchmark designers to generate logs that are easier to analyze in standardized ways.
- Teams could test whether partial automation of the pipeline reduces analysis time without losing rigor.
- The approach may connect to broader efforts in making AI evaluations more transparent and auditable.
Load-bearing premise
The seven steps capture current best practices comprehensively enough to serve most log analysis needs without major gaps or the need for substantial custom adjustments.
What would settle it
Finding that teams following the seven steps still produce inconsistent or incomplete insights on the same logs compared to experienced ad-hoc analysts would show the pipeline is insufficient.
Figures

read the original abstract
AI systems produce large volumes of logs as they interact with tools and users. Analysing these logs can help understand model capabilities, propensities, and behaviours, or assess whether an evaluation worked as intended. Researchers have started developing methods for log analysis, but a standardised approach is still missing. Here we suggest a pipeline based on current best practices. We illustrate it with concrete code examples in the Inspect Scout library, provide detailed guidance on each step, and highlight common pitfalls. Our framework provides researchers with a foundation for rigorous and reproducible log analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a seven-step pipeline for log analysis in AI systems, derived from current best practices. It illustrates the approach with concrete code examples from the Inspect Scout library, supplies detailed guidance for each step, and flags common pitfalls. The central claim is that this framework supplies researchers with a foundation for rigorous and reproducible log analysis.
Significance. If the pipeline is shown to be comprehensive and effective, it could standardize log-analysis practices across AI evaluation and interpretability research, improving reproducibility of conclusions about model behavior. The inclusion of reproducible code examples constitutes a concrete strength that would support practical uptake.
major comments (2)
- [Abstract] Abstract: the claim that the framework 'provides researchers with a foundation for rigorous and reproducible log analysis' is unsupported by validation data, error analysis, inter-analyst agreement metrics, or any empirical comparison against ad-hoc log analysis; the manuscript only describes the steps and supplies code examples.
- [Pipeline description] Pipeline description (steps 1-7): no systematic literature review or explicit citation trail identifies the 'current best practices' from which the seven steps were synthesized, nor is any comparison presented against existing log-analysis methods, leaving the comprehensiveness claim untested.
minor comments (1)
- [Code examples] Code examples: the Inspect Scout snippets would be clearer if each step included inline comments explaining the rationale and expected output for readers new to the library.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments on our manuscript. We address each of the major comments below, indicating the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the framework 'provides researchers with a foundation for rigorous and reproducible log analysis' is unsupported by validation data, error analysis, inter-analyst agreement metrics, or any empirical comparison against ad-hoc log analysis; the manuscript only describes the steps and supplies code examples.
Authors: The referee correctly notes that the manuscript does not include empirical validation, error analysis, or comparisons. As a methods-oriented paper, our goal is to propose a structured pipeline synthesized from observed best practices in the field, accompanied by practical code examples. We will revise the abstract to temper the claim, changing 'provides researchers with a foundation' to 'aims to provide researchers with a foundation for rigorous and reproducible log analysis'. Additionally, we will add a clarifying paragraph in the introduction stating the scope and limitations of the work. revision: yes
-
Referee: [Pipeline description] Pipeline description (steps 1-7): no systematic literature review or explicit citation trail identifies the 'current best practices' from which the seven steps were synthesized, nor is any comparison presented against existing log-analysis methods, leaving the comprehensiveness claim untested.
Authors: We acknowledge that the manuscript does not present a systematic literature review. The steps were derived from common practices in AI log analysis as seen in recent literature on model evaluation and interpretability. To address this, we will expand the citations in the manuscript to trace the origins of each step more explicitly and include a short section discussing related methods in log analysis. However, a comprehensive comparison or systematic review would require a different paper format; we will explicitly state this as a limitation in the revised version. revision: partial
Circularity Check
No circularity: methodological synthesis without derivations or self-referential reductions
full rationale
The paper proposes a seven-step pipeline for log analysis presented as a synthesis of external best practices, illustrated with code examples from the Inspect Scout library and guidance on pitfalls. No equations, fitted parameters, predictions, or self-citations appear in the provided text that reduce any claim to its own inputs by construction. The central assertion of providing a foundation for rigorous analysis is an untested recommendation rather than a derived result, so none of the enumerated circularity patterns apply. This is the expected honest non-finding for a purely methodological framework paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
URLhttps://arxiv.org/abs/2410.09024. Atla. What works (and what doesn’t) when automating error analysis. https://atla-ai.com/ post/automating-error-analysis, 2025. Atla Blog. John Burden, Manuel Cebrian, and Jose Hernandez-Orallo. Conversational complexity for assessing risk in large language models.EPJ Data Science, 14(1):1–22, 2025. Mert Cemri, Melissa ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
On Verbalized Confidence Scores for LLMs
URLhttps://arxiv.org/abs/2412.14737. Itay Yona, Amir Sarid, Michael Karasik, and Yossi Gandelsman. In-context representation hijacking,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
"" 28 29class Refusal(BaseModel): 30refusal_exists: bool = Field( 31alias=
URLhttps://arxiv.org/abs/2512.03771. Chen Yueh-Han, Nitish Joshi, Yulin Chen, Maksym Andriushchenko, Rico Angell, and He He. Monitoring decomposition attacks in llms with lightweight sequential monitors.arXiv preprint arXiv:2506.10949, 2025. Andy K. Zhang, Neil Perry, Riya Dulepet, Joey Ji, Celeste Menders, Justin W. Lin, Eliot Jones, Gashon Hussein, Sama...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.