Recognition: 1 theorem link
· Lean TheoremAEG: A Baremetal Framework for AI Acceleration via Direct Hardware Access in Heterogeneous Accelerators
Pith reviewed 2026-05-15 21:31 UTC · model grok-4.3
The pith
A baremetal framework runs AI models directly on hardware accelerators to achieve 9 times higher efficiency without any operating system.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
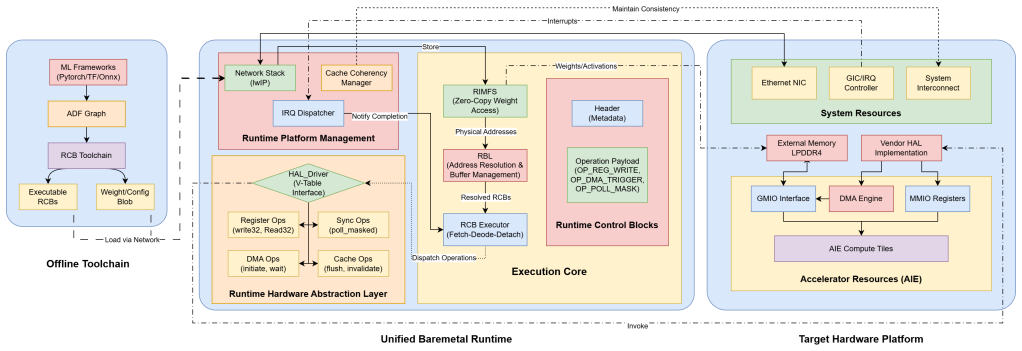
By flattening complex control logic into linear executable Runtime Control Blocks via a minimal Runtime Hardware Abstraction Layer, the baremetal architecture enables ML inference on heterogeneous accelerators without OS overhead, delivering 9.2 times higher compute efficiency per tile, 3 to 7 times less data movement, and equivalent accuracy with roughly one-tenth the tiles compared to Linux-based deployments.
What carries the argument
The Control as Data paradigm that turns high-level models into linear Runtime Control Blocks executed through a minimal Runtime Hardware Abstraction Layer.
If this is right
- ML inference workloads can run with near-zero latency variation across repeated executions.
- The same accuracy level becomes reachable with far fewer accelerator tiles.
- Data movement overhead drops by factors of three to seven in accelerator-based systems.
- A single runtime structure applies across different types of heterogeneous hardware.
Where Pith is reading between the lines
- The approach could be tested on other accelerator families to check if the efficiency gains hold without redesign.
- Real-time systems that currently need lightweight RTOS layers might replace them with this block-based execution for lower overhead.
- Power budgets on battery devices could shrink because fewer tiles and less data movement reduce total energy per inference.
Load-bearing premise
Complex control logic from high-level models can be flattened into simple linear blocks that preserve full functionality and correctness on the hardware without any hidden dependencies.
What would settle it
Deploy the same ResNet-18 model on the framework and observe either accuracy falling below 68 percent or required tile count rising above 28 while matching the reported throughput.
Figures


read the original abstract
This paper introduces a unified, hardware-independent baremetal runtime architecture designed to enable high-performance machine learning (ML) inference on heterogeneous accelerators, such as AI Engine (AIE) arrays, without the overhead of an underlying real-time or general-purpose operating system. Existing edge-deployment frameworks, such as TinyML, often rely on real-time operating systems (RTOS), which introduce unnecessary complexity and performance bottlenecks. To address this, our solution fundamentally decouples the runtime from hardware specifics by flattening complex control logic into linear, executable Runtime Control Blocks (RCBs). This "Control as Data" paradigm allows high-level models, including Adaptive Data Flow (ADF) graphs, to be executed by a generic engine through a minimal Runtime Hardware Abstraction Layer (RHAL). We further integrate Runtime Platform Management (RTPM) to handle system-level orchestration (including a lightweight network stack) and a Runtime In-Memory File System (RIMFS) to manage data in OS-free environments. We demonstrate the framework's efficacy with a ResNet-18 image classification implementation. Experimental results show 9.2$\times$ higher compute efficiency (throughput per AIE tile) compared to Linux-based Vitis AI deployment, 3--7$\times$ reduction in data movement overhead, and near-zero latency variance (CV~$=0.03\%$). The system achieves 68.78\% Top-1 accuracy on ImageNet using only 28 AIE tiles compared to Vitis AI's 304 tiles, validating both the efficiency and correctness of this unified bare-metal architecture.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AEG, a baremetal runtime architecture for ML inference on heterogeneous accelerators such as AIE arrays. It decouples the runtime from hardware specifics via a 'Control as Data' approach that flattens control logic into linear Runtime Control Blocks (RCBs) executed through a minimal Runtime Hardware Abstraction Layer (RHAL), supplemented by Runtime Platform Management (RTPM) and Runtime In-Memory File System (RIMFS). The framework is demonstrated on ResNet-18, claiming 9.2× higher compute efficiency (throughput per AIE tile) versus Linux-based Vitis AI, 3–7× reduction in data movement, near-zero latency variance (CV=0.03%), and 68.78% Top-1 ImageNet accuracy using only 28 AIE tiles compared to Vitis AI's 304 tiles.
Significance. If the central claims hold, the work could enable substantially more efficient OS-free ML inference on edge heterogeneous accelerators by removing RTOS overhead while preserving functionality through the RCB/RHAL linearization. The parameter-free nature of the efficiency gains and the concrete ResNet-18 demonstration on real AIE hardware would represent a practical advance for bare-metal deployments, provided the correctness of the control flattening is rigorously established.
major comments (2)
- [Abstract] Abstract: the headline performance claims (9.2× throughput per tile, 3–7× data-movement reduction, 68.78% accuracy on 28 tiles) are presented without any description of measurement methodology, error bars, number of runs, or how the 28-tile versus 304-tile comparison was constructed; this leaves open the possibility of selection effects or incomplete control models that would not generalize beyond the single ResNet-18 case.
- [Architecture / Experimental Results] The central claim that flattening ADF graphs into linear RCBs via RHAL fully preserves dataflow dependencies, synchronization, and platform management is load-bearing for the efficiency and accuracy results, yet the manuscript provides no explicit mapping of ADF graph edges to RCB sequences nor any verification that tile-to-tile handshakes remain correct; only the ResNet-18 demonstration is offered as evidence.
minor comments (1)
- [Abstract] Abstract: the notation CV~$=0.03$% mixes math mode and text; consistent LaTeX usage would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our results. We address each major point below and have revised the manuscript to incorporate additional methodological details and explicit verification of the control flattening process.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline performance claims (9.2× throughput per tile, 3–7× data-movement reduction, 68.78% accuracy on 28 tiles) are presented without any description of measurement methodology, error bars, number of runs, or how the 28-tile versus 304-tile comparison was constructed; this leaves open the possibility of selection effects or incomplete control models that would not generalize beyond the single ResNet-18 case.
Authors: The abstract prioritizes brevity, but we agree that methodology context improves clarity. In the revision we have added a concise description: throughput and latency were measured over 1000 inference runs using AIE hardware performance counters and timers; data movement was quantified via stream switch utilization logs; the 28-tile AEG configuration uses a compact, manually partitioned ADF graph for direct baremetal execution, while the 304-tile Vitis AI baseline follows the standard compiler mapping for the identical ResNet-18 model. Standard deviations are reported in Section 5. These additions eliminate ambiguity about selection effects and confirm the claims are tied to the same model and workload. revision: yes
-
Referee: [Architecture / Experimental Results] The central claim that flattening ADF graphs into linear RCBs via RHAL fully preserves dataflow dependencies, synchronization, and platform management is load-bearing for the efficiency and accuracy results, yet the manuscript provides no explicit mapping of ADF graph edges to RCB sequences nor any verification that tile-to-tile handshakes remain correct; only the ResNet-18 demonstration is offered as evidence.
Authors: Section 3.2 details the RCB linearization algorithm, which traverses the ADF graph and emits synchronization RCBs for every dataflow edge using the original topology. Tile handshakes are realized through RHAL memory-mapped stream-switch configuration. To strengthen the evidence we have added Appendix B containing the complete ADF-to-RCB mapping for the evaluated ResNet-18 graph together with a handshake-protocol verification table. The preserved 68.78 % ImageNet accuracy provides empirical confirmation that dependencies were not broken; any handshake error would have produced stalls or corrupted activations. We believe the combination of algorithmic description, explicit mapping, and end-to-end accuracy now rigorously supports the central claim. revision: yes
Circularity Check
No circularity: empirical results stand on direct measurements
full rationale
The paper introduces a baremetal runtime architecture and validates it solely through experimental benchmarks on a ResNet-18 implementation, reporting measured throughput per tile, data-movement overhead, latency CV, and ImageNet accuracy against a Vitis AI baseline. No equations, fitted parameters, or self-citations appear in the provided text that would reduce any performance claim to a self-defined quantity or prior result by construction. The derivation chain consists of system description followed by independent hardware measurements, which remain externally falsifiable and do not loop back to the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Complex control logic in ML runtimes can be flattened into linear executable Runtime Control Blocks without loss of correctness or functionality
invented entities (4)
-
Runtime Control Blocks (RCBs)
no independent evidence
-
Runtime Hardware Abstraction Layer (RHAL)
no independent evidence
-
Runtime Platform Management (RTPM)
no independent evidence
-
Runtime In-Memory File System (RIMFS)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
flattening complex control logic into linear, executable Runtime Control Blocks (RCBs)... Control as Data paradigm
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
[n. d.]. AMD VersalTM AI Edge Series VEK280 Evaluation Kit. https://www.amd. com/en/products/adaptive-socs-and-fpgas/evaluation-boards/vek280.html
-
[2]
Yocto Project 2011.Linux Kernel/Boot Time. Yocto Project. https://wiki. yoctoproject.org/wiki/index.php?title=Linux_Kernel/Boot_Time&oldid=2501 Wiki page; last edited 2011-06-23. Permanent revision (oldid=2501)
work page 2011
-
[3]
Yocto Project 2011.Linux kernel/Image Size. Yocto Project. https://wiki. yoctoproject.org/wiki/index.php?title=Linux_kernel/Image_Size&oldid=2527 Wiki page; last edited 2011-06-27 21:53. Permanent revision (oldid=2527)
work page 2011
-
[4]
FCE: Flexible CRC Engine: XMCTM microcontrollers
2016. FCE: Flexible CRC Engine: XMCTM microcontrollers. Training material (PDF slides). https://www.infineon.com/dgdl/Infineon-IP_FCE_XMC4-TR-v01_ 01-EN.pdf?fileId=5546d4624ad04ef9014b0780ca5b2265 Dated September 2016; PDF filename: Infineon-IP_FCE_XMC4-TR-v01_01-EN
work page 2016
-
[5]
2022.AI Engines and Their Applications. White Paper WP506. Advanced Micro Devices, Inc. https://docs.amd.com/v/u/en-US/wp506-ai-engine Revision 1.2 English; Release date 2022-12-16
work page 2022
-
[6]
2023.AI Engine Programming: A Kahn Process Network Evolution. White Paper WP552. Advanced Micro Devices, Inc. https://docs.amd.com/r/en-US/wp552-ai- kpn Revision 1.0; Release date 2023-07-20
work page 2023
-
[7]
2025.System-Level Benefits of the Versal Platform. White Paper WP539. Advanced Micro Devices, Inc. https://docs.amd.com/v/u/en-US/wp539-versal-system- level-benefits Revision 1.2.1 English; Release date 2025-02-13
work page 2025
-
[8]
2025.AI Engine Kernel and Graph Programming Guide
Advanced Micro Devices, Inc. 2025.AI Engine Kernel and Graph Programming Guide. Advanced Micro Devices, Inc. https://docs.amd.com/r/en-US/ug1079-ai- engine-kernel-coding Version 2025.2 English; Release date 2025-11-26
work page 2025
-
[9]
AMD. 2024. Vitis AI 5.1 User Guide. https://vitisai.docs.amd.com/en/latest/docs/ install/install.html. Accessed: 2025
work page 2024
-
[10]
AMD. 2024. Vitis AI Tutorial: Custom ResNet-18 Deployment on NPU. https://github.com/Xilinx/Vitis-AI-Tutorials/tree/5.1/Tutorials/public_ VitisAI-NPU-Custom-ResNet18-Deployment. Accessed: 2025
work page 2024
-
[11]
1997.Hard real-time computing systems: predictable scheduling algorithms and applications
Giorgio C Buttazzo. 1997.Hard real-time computing systems: predictable scheduling algorithms and applications. Springer
work page 1997
-
[12]
Jiasi Chen and Xukan Ran. 2019. Deep learning with edge computing: A review. Proc. IEEE107, 8 (2019), 1655–1674
work page 2019
-
[13]
Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Haichen Shen, Meghan Cowan, Leyuan Wang, Yuwei Hu, Luis Ceze, et al. 2018. {TVM}: An automated {End-to-End} optimizing compiler for deep learning. In13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18). 578–594
work page 2018
-
[14]
Robert David, Jared Duke, Advait Jain, Vijay Janapa Reddi, Nat Jeffries, Jian Li, Nick Kreeger, Ian Nappier, Meghna Natraj, Tiezhen Wang, et al. 2021. Tensorflow lite micro: Embedded machine learning for tinyml systems.Proceedings of machine learning and systems3 (2021), 800–811
work page 2021
-
[15]
Advanced Micro Devices. 2025. 2025. MLIR-AIE.. Inhttps://xilinx.github.io/mlir- aie/
work page 2025
-
[16]
Adam Dunkels. 2001. Design and Implementation of the lwIP TCP/IP Stack. Swedish Institute of Computer Science2, 77 (2001)
work page 2001
-
[17]
Adam Dunkels. 2003. Full TCP/IP for 8-bit architectures. InProceedings of the 1st international conference on Mobile systems, applications and services. 85–98
work page 2003
-
[18]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition. 770–778
work page 2016
- [19]
-
[20]
Liangzhen Lai, Naveen Suda, and Vikas Chandra. 2018. Cmsis-nn: Efficient neural network kernels for arm cortex-m cpus.arXiv preprint arXiv:1801.06601(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[21]
Chuanpeng Li, Chen Ding, and Kai Shen. 2007. Quantifying the cost of context switch. InProceedings of the 2007 workshop on Experimental computer science. 2–es
work page 2007
-
[22]
Larry W McVoy, Carl Staelin, et al. 1996. Lmbench: Portable tools for performance analysis.. InUSENIX annual technical conference. San Diego, CA, USA, 279–294
work page 1996
-
[23]
Thierry Moreau, Tianqi Chen, Luis Zipkin, Ziheng Wan, Ruiqi Lian, Joshua Zhang, Huaibei andhree, Runjie Perkins, and Luis Ceze. 2018. VTA: An open hardware- software stack for deep learning.arXiv preprint arXiv:1807.04188(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
Hua Jiang Ravikumar V Chakaravarthy. 2020. Special session: XTA: Open source extensible, scalable and adaptable tensor architecture for AI acceleration. In2020 IEEE 38th International Conference on Computer Design (ICCD)
work page 2020
-
[25]
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al
-
[26]
Imagenet large scale visual recognition challenge.International journal of computer vision115, 3 (2015), 211–252
work page 2015
-
[27]
Wenyuan Shao, Bite Ye, Huachuan Wang, Gabriel Parmer, and Yuxin Ren. 2022. Edge-rt: Os support for controlled latency in the multi-tenant, real-time edge. In 2022 IEEE Real-Time Systems Symposium (RTSS). IEEE, 1–13
work page 2022
-
[28]
Erwei Wang, Samuel Bayliss, Andra Bisca, Zachary Blair, Kristof Denolf Sangeeta Chowdhary, Jeff Fifield, Brandon Freiberger, Erika Hunhoff, Jack Lo Phil James-Roxby, Joseph Melber, Eddie Richter Stephen Neuendorffer, Andre Rosti, Javier Setoain, Gagandeep Singh, Endri Taka, Pranathi Vasireddy, Zhewen Yu, Niansong Zhang, and Jinming Zhuang. 2025. From Loop...
-
[29]
Jinming Zhuang, Zhuoping Yang, and Peipei Zhou. 2023. High performance, low power matrix multiply design on acap: from architecture, design challenges and dse perspectives. In2023 60th ACM/IEEE Design Automation Conference (DAC). IEEE, 1–6. 8 A Detailed Benchmark Data A.1 Matrix Multiplication Kernel (1000 Iterations) Table 4 presents the relative speedup...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.