Recognition: no theorem link
Tuning Qwen2.5-VL to Improve Its Web Interaction Skills
Pith reviewed 2026-05-15 20:47 UTC · model grok-4.3
The pith
Fine-tuning a vision-language model raises its success rate on web clicking tasks from 86 percent to 94 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
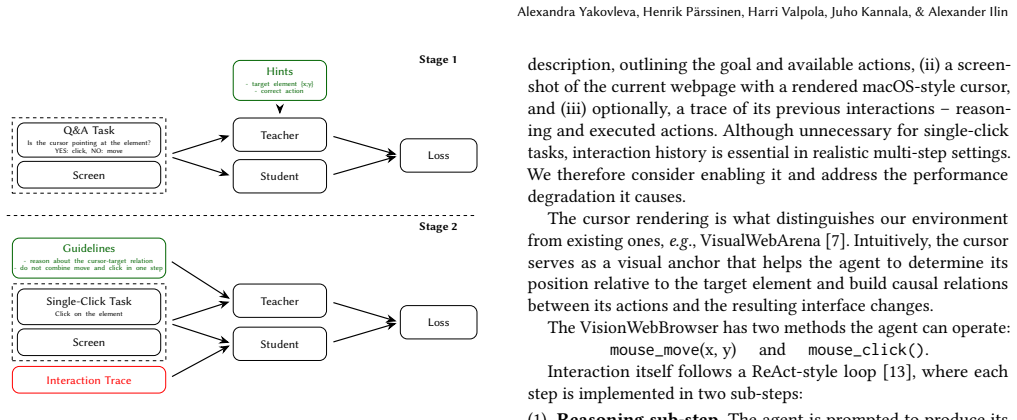
By applying a two-stage fine-tuning pipeline to Qwen2.5-VL-32B, first teaching the model to decide if the cursor needs to move to a target element described in natural language and then to issue and verify single mouse commands one at a time, the success rate on challenging single-click web tasks increases from 86% to 94%. This directly tackles the model's inaccurate localization, phrasing sensitivity, and overoptimistic bias toward its own actions.
What carries the argument
A two-stage fine-tuning pipeline that trains the model to first assess whether the cursor hovers over the target and then execute one mouse action at a time while verifying the outcome.
If this is right
- The model becomes better at determining cursor position relative to targets from images alone.
- It learns to issue single commands rather than assuming multi-step success.
- Overall reliability in visual web control increases substantially.
- Open-source VLMs can handle basic web agent tasks more effectively after targeted tuning.
Where Pith is reading between the lines
- The technique of forcing step-by-step verification could apply to other agentic tasks involving visual feedback.
- Extending this to multi-action sequences might enable more complex web automation without additional human oversight.
- Similar training could reduce instruction sensitivity in other vision-language models.
Load-bearing premise
The custom benchmark of single-click web tasks is representative of real-world web interaction challenges and the observed improvements will generalize beyond the tested model and task distribution.
What would settle it
Evaluating the fine-tuned model on a diverse set of unseen real-world websites or more complex multi-click tasks, where the success rate fails to reach or exceed 94% compared to the untuned version.
Figures
read the original abstract
Recent advances in vision-language models (VLMs) have sparked growing interest in using them to automate web tasks, yet their feasibility as independent agents that reason and act purely from visual input remains underexplored. We investigate this setting using Qwen2.5-VL-32B, one of the strongest open-source VLMs available, and focus on improving its reliability in web-based control. Through initial experimentation, we observe three key challenges: (i) inaccurate localization of target elements, the cursor, and their relative positions, (ii) sensitivity to instruction phrasing, and (iii) an overoptimistic bias toward its own actions, often assuming they succeed rather than analyzing their actual outcomes. To address these issues, we fine-tune Qwen2.5-VL-32B for a basic web interaction task: moving the mouse and clicking on a page element described in natural language. Our training pipeline consists of two stages: (1) teaching the model to determine whether the cursor already hovers over the target element or whether movement is required, and (2) training it to execute a single command (a mouse move or a mouse click) at a time, verifying the resulting state of the environment before planning the next action. Evaluated on a custom benchmark of single-click web tasks, our approach increases success rates from 86% to 94% under the most challenging setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that fine-tuning Qwen2.5-VL-32B via a two-stage pipeline—first teaching cursor hover detection and then single-command execution with state verification—addresses localization errors, phrasing sensitivity, and action bias, yielding an 8pp success-rate gain (86% to 94%) on a custom benchmark of single-click web tasks.
Significance. If the performance delta is reproducible and generalizes, the work supplies a concrete, failure-mode-targeted fine-tuning recipe that could improve the reliability of open VLMs as visual web agents. The staged training design is a clear methodological strength that directly targets the three challenges identified in the abstract.
major comments (1)
- [Evaluation] Evaluation section: The headline result (86% → 94% success under the most challenging setting) is load-bearing for the central claim, yet the manuscript supplies no task count, website diversity statistics, run-to-run variance, statistical significance tests, or ablation against other fine-tuning regimes. Without these quantities the observed delta cannot be distinguished from benchmark-specific artifacts.
minor comments (1)
- [Abstract] Abstract: The phrase 'most challenging setting' is undefined; a brief parenthetical (e.g., 'zero-shot websites' or 'long-horizon pages') would clarify scope.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation section. We agree that additional quantitative details are required to support the reported performance gains and will revise the manuscript to incorporate them.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The headline result (86% → 94% success under the most challenging setting) is load-bearing for the central claim, yet the manuscript supplies no task count, website diversity statistics, run-to-run variance, statistical significance tests, or ablation against other fine-tuning regimes. Without these quantities the observed delta cannot be distinguished from benchmark-specific artifacts.
Authors: We agree that these details are necessary for a rigorous evaluation. In the revised manuscript we will report the exact number of tasks and websites in the benchmark, along with diversity statistics (e.g., distribution across domains and page complexities). We will also add results from multiple independent runs with different random seeds to quantify run-to-run variance, include statistical significance tests (such as paired t-tests) comparing the baseline and fine-tuned models, and provide ablations against single-stage fine-tuning and other relevant regimes. These changes will clarify that the 8pp improvement is reproducible and not benchmark-specific. revision: yes
Circularity Check
Empirical fine-tuning results contain no circular derivation chain
full rationale
The paper describes a two-stage fine-tuning procedure on Qwen2.5-VL-32B for single-click web tasks followed by direct evaluation on a custom benchmark, reporting measured success-rate improvement (86% to 94%). No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim is an observed empirical delta on held-out tasks, not a quantity forced by construction from the training data or prior self-references. This is a standard non-circular empirical result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Li YanTao, Jianbing Zhang, and Zhiyong Wu. 2024. SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Bangkok, Thailand, 9313–9332. https://aclanthology.org/2...
work page 2024
-
[4]
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. 2023. Mind2Web: Towards a Generalist Agent for the Web. arXiv:2306.06070 [cs.CL] https://arxiv.org/abs/2306.06070
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. 2024. WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models. arXiv:2401.13919 [cs.CL] https: //arxiv.org/abs/2401.13919
work page internal anchor Pith review arXiv 2024
-
[6]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InProceedings of the International Conference on Learning Representations. https://openreview.net/forum?id=nZeVKeeFYf9
work page 2022
-
[7]
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, and Daniel Fried
-
[8]
arXiv:2401.13649 [cs.CL] https://arxiv.org/abs/2401.13649
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks. arXiv:2401.13649 [cs.CL] https://arxiv.org/abs/2401.13649
-
[9]
Kalle Kujanpää, Pekka Marttinen, Harri Valpola, and Alexander Ilin. 2025. Effi- cient Knowledge Injection in LLMs via Self-Distillation.Transactions on Machine Learning Research(2025). https://openreview.net/forum?id=drYpdSnRJk
work page 2025
- [10]
-
[11]
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. 2025. UI-TARS: Pioneering Automated GUI Interaction with Native Agents. arXiv:2501.12326 [cs.AI] https: //arxiv.org/abs/2501.12326
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [12]
-
[13]
Qwen Team. 2025. Qwen2.5-VL. https://qwenlm.github.io/blog/qwen2.5-vl/
work page 2025
-
[14]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InProceedings of the International Conference on Learning Representations
work page 2023
-
[15]
Boyuan Zheng, Boyu Gou, Jihyung Kil, Huan Sun, and Yu Su. 2024. GPT-4V(ision) is a Generalist Web Agent, if Grounded. InForty-first International Conference on Machine Learning. https://openreview.net/forum?id=piecKJ2DlB
work page 2024
-
[16]
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Yonatan Bisk, Daniel Fried, Uri Alon, et al. 2024. WebArena: A Realistic Web Environment for Building Autonomous Agents. InProceedings of the International Conference on Learning Representations. https://webarena.dev
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.