Recognition: 1 theorem link
· Lean TheoremWhy Smaller Is Slower? Dimensional Misalignment in Compressed LLMs
Pith reviewed 2026-05-15 15:36 UTC · model grok-4.3
The pith
Compressed LLMs often run no faster than uncompressed ones because their tensor dimensions misalign with GPU hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
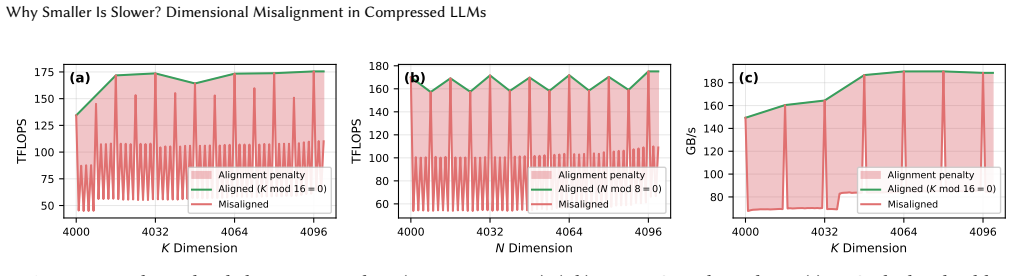
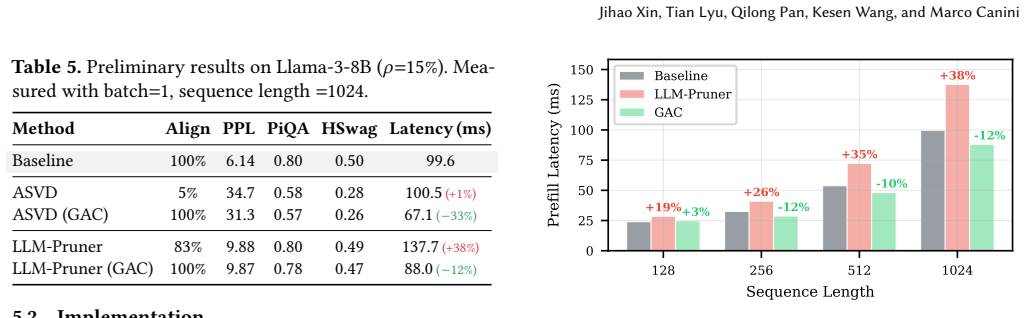
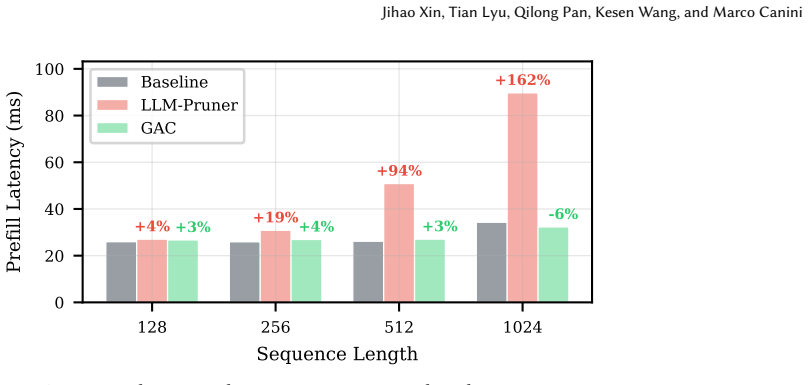
The paper shows that dimensional misalignment in compressed LLMs prevents expected performance gains from parameter reduction, with 95 percent of dimensions in an ASVD-compressed Llama-3-8B proving unfriendly to the GPU execution stack. GAC solves this by wrapping any dimension-reducing compressor and applying multi-choice knapsack optimization to pick hardware-aligned dimensions within the original parameter count, achieving full alignment and restoring runtime speedups up to 1.5 times on tested models without quality loss.
What carries the argument
GPU-Aligned Compression (GAC), a wrapper that re-selects hardware-aligned dimensions from any base compressor using multi-choice knapsack optimization under a fixed parameter budget.
If this is right
- Existing compressors such as ASVD and LLM-Pruner can deliver actual speedups when wrapped with alignment selection.
- Compressed models can become both smaller and faster on standard GPUs without extra training steps.
- Compression pipelines must incorporate hardware dimension constraints to realize efficiency benefits.
- Full alignment eliminates the performance penalty from irregular tensor shapes across the GPU stack.
Where Pith is reading between the lines
- The same misalignment problem may appear in compression applied to other model families or hardware accelerators.
- Knapsack-based selection could be extended to optimize additional constraints such as memory bandwidth.
- Inherently aligned compression algorithms might be designed to avoid the need for post-hoc re-selection.
Load-bearing premise
Re-selecting dimensions with multi-choice knapsack optimization under a fixed parameter budget preserves model quality without any retraining or fine-tuning.
What would settle it
Inference benchmarks on GAC-compressed Llama-3-8B that show either accuracy drop or no speedup on GPU hardware would disprove the claim.
Figures









read the original abstract
Post-training compression reduces LLM parameter counts but often produces irregular tensor dimensions that degrade GPU performance -- a phenomenon we call \emph{dimensional misalignment}. We present a full-stack analysis tracing root causes at three levels: framework, library, and hardware. The key insight is that model inference becomes slower because the resulting dimensions are unfriendly with the GPU execution stack. For example, compressing Llama-3-8B with activation-aware singular value decomposition (ASVD) has 15\% fewer parameters yet runs no faster than the uncompressed baseline, because 95\% of its dimensions are misaligned. We propose \textbf{GAC} (GPU-Aligned Compression), a new compression paradigm that wraps any dimension-reducing compressor and re-selects hardware-aligned dimensions via multi-choice knapsack optimization under the same parameter budget. We evaluate GAC on Llama-3-8B with ASVD and LLM-Pruner, achieving 100\% alignment and recovering up to 1.5$\times$ speedup while preserving model quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that post-training compression of LLMs produces irregular tensor dimensions that cause dimensional misalignment with the GPU execution stack, resulting in no inference speedup despite fewer parameters. For example, ASVD compression of Llama-3-8B yields 15% fewer parameters but runs at baseline speed because 95% of dimensions are misaligned. The authors propose GAC, a wrapper around existing compressors (ASVD, LLM-Pruner) that re-selects dimensions via multi-choice knapsack optimization under a fixed parameter budget to achieve 100% alignment and up to 1.5× speedup while preserving model quality.
Significance. If the central result holds, the work identifies a concrete, previously under-appreciated source of performance loss in compressed LLMs and supplies a practical, compressor-agnostic fix that recovers hardware efficiency without retraining. The full-stack tracing from framework through library to hardware is a positive contribution; the knapsack formulation itself is parameter-free once the alignment constraint and budget are fixed.
major comments (2)
- [Abstract and §4] Abstract and §4 (Evaluation): the headline claim that GAC 'preserves model quality' while replacing dimensions chosen by the base compressor is unsupported by any ablation. The knapsack objective encodes only alignment and parameter count; no experiment shows that perplexity or downstream accuracy remains unchanged when high-singular-value dimensions are swapped for lower-importance but aligned ones.
- [§3.2] §3.2 (GAC formulation): the multi-choice knapsack is described as operating 'under the same parameter budget,' yet the manuscript provides neither the precise importance-weighting scheme inherited from the base compressor nor an explicit statement that the original singular-value or pruning scores are folded into the knapsack objective. Without this, the substitution risk identified in the stress-test note cannot be ruled out.
minor comments (2)
- [Abstract] Abstract: supply error bars, exact baseline configurations, and the precise definition of 'alignment' (e.g., divisibility by 128 for tensor-core tiles) so that the reported 95% and 100% figures can be reproduced.
- [Figure 1 and §2] Figure 1 and §2: clarify whether the reported 1.5× speedup is measured on the same hardware and batch size as the uncompressed baseline, and whether any tensor-core utilization or memory-bandwidth counters are provided to substantiate the misalignment diagnosis.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that help strengthen the manuscript. We address each major comment below with clarifications and planned revisions.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Evaluation): the headline claim that GAC 'preserves model quality' while replacing dimensions chosen by the base compressor is unsupported by any ablation. The knapsack objective encodes only alignment and parameter count; no experiment shows that perplexity or downstream accuracy remains unchanged when high-singular-value dimensions are swapped for lower-importance but aligned ones.
Authors: In §4 we report that GAC achieves perplexity and downstream accuracy comparable to the base compressors (ASVD, LLM-Pruner) under identical parameter budgets, as shown in Tables 2–3. We acknowledge that an explicit ablation isolating the effect of replacing high-singular-value dimensions with aligned lower-importance ones is absent. We will add this ablation study in the revision to directly confirm quality preservation. revision: partial
-
Referee: [§3.2] §3.2 (GAC formulation): the multi-choice knapsack is described as operating 'under the same parameter budget,' yet the manuscript provides neither the precise importance-weighting scheme inherited from the base compressor nor an explicit statement that the original singular-value or pruning scores are folded into the knapsack objective. Without this, the substitution risk identified in the stress-test note cannot be ruled out.
Authors: We agree the formulation in §3.2 requires clarification. The knapsack objective maximizes the sum of importance scores inherited from the base compressor (singular values for ASVD, pruning scores for LLM-Pruner) subject to the alignment and budget constraints. We will revise §3.2 to state this weighting explicitly and show that high-importance dimensions are prioritized, thereby addressing the substitution concern. revision: yes
Circularity Check
No significant circularity; GAC is an independent optimization wrapper
full rationale
The paper's derivation consists of an empirical root-cause analysis of GPU performance degradation due to irregular dimensions after compression, followed by the introduction of GAC as a post-hoc multi-choice knapsack re-selection step that enforces alignment while respecting the original parameter budget. Speedup and alignment percentages are reported as measured hardware outcomes on Llama-3-8B, not as quantities derived by algebraic reduction from the input compressor outputs. Quality preservation is presented as an empirical evaluation result rather than a definitional necessity. No equations, self-citations, or fitted parameters are shown to collapse the central claims into tautologies or input re-labelings. The approach remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GPU execution stack favors specific tensor dimensions for peak throughput
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
compressing Llama-3-8B with ASVD has 15% fewer parameters yet runs no faster ... because 95% of its dimensions are misaligned. ... GAC ... re-selects hardware-aligned dimensions via multi-choice knapsack optimization under the same parameter budget
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Yucheng Li, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, and Wen Xiao. 2025. PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling. arXiv:2406.02069 [cs.CL]https://arxiv.org/ abs/2406.02069
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Abdelfattah, and Kai-Chiang Wu
Chi-Chih Chang, Wei-Cheng Lin, Chien-Yu Lin, Chong-Yan Chen, Yu-Fang Hu, Pei-Shuo Wang, Ning-Chi Huang, Luis Ceze, Mohamed S. Abdelfattah, and Kai-Chiang Wu. 2025. Palu: KV-Cache Compression with Low-Rank Projection. InThe Thirteenth International Confer- ence on Learning Representations.https://openreview.net/forum?id= LWMS4pk2vK
work page 2025
-
[3]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. FlashAttention: Fast and Memory-Efficient Exact Atten- tion with IO-Awareness. InAdvances in Neural Information Pro- cessing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (Eds.), Vol. 35. Curran Associates, Inc., 16344– 16359.https://proceedings.neurips.cc/p...
work page 2022
-
[4]
Elias Frantar and Dan Alistarh. 2023. SparseGPT: massive language models can be accurately pruned in one-shot. InProceedings of the 40th International Conference on Machine Learning(Honolulu, Hawaii, USA)(ICML’23). JMLR.org, Article 414, 15 pages
work page 2023
-
[5]
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh
-
[6]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers. arXiv:2210.17323 [cs.LG]https://arxiv.org/ abs/2210.17323
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[8]
Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles(Koblenz, Germany)(SOSP ’23). As- sociation for Computing Machinery, New York, NY, USA, 611–626. doi:10.1145/3600006.3613165
-
[9]
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. 2024. AWQ: Activation-aware Weight Quantization for On- Device LLM Compression and Acceleration. InProceedings of Machine Learning and Systems, P. Gibbons, G. Pekhimenko, and C. De Sa (Eds.), Vol. 6. 87–100.https://proceedin...
work page 2024
-
[10]
Xinyin Ma, Gongfan Fang, and Xinchao Wang. 2023. LLM- Pruner: On the Structural Pruning of Large Language Mod- els. InAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Associates, Inc., 21702– 21720.https://proceedings.neurips.cc/paper_files/paper/2023/file/ 44956...
work page 2023
-
[11]
Meta AI. 2024. Llama 3 Model Card.https://github.com/meta-llama/ llama3
work page 2024
-
[12]
Pavlo Molchanov, Arun Mallya, Stephen Tyree, Iuri Frosio, and Jan Kautz. 2019. Importance Estimation for Neural Network Pruning. arXiv:1906.10771 [cs.LG]https://arxiv.org/abs/1906.10771
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[13]
NVIDIA. 2024. NVIDIA TensorRT: Programmable Inference Accelera- tor.https://developer.nvidia.com/tensorrt
work page 2024
-
[14]
NVIDIA Corporation. 2022. NVIDIA H100 Tensor Core GPU Archi- tecture. White Paper.https://resources.nvidia.com/en-us-hopper- architecture/nvidia-h100-tensor-c
work page 2022
-
[15]
SemiAnalysis. 2024. NVIDIA Tensor Core Evolution: From Volta To Blackwell.https://newsletter.semianalysis.com/p/nvidia-tensor-core- evolution-from-volta-to-blackwell
work page 2024
-
[16]
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. 2024. FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. Curran Associates, Inc., 68658–686...
- [17]
-
[18]
Mingjie Sun, Zhuang Liu, Anna Bair, and J Zico Kolter. 2024. A Simple and Effective Pruning Approach for Large Language Models. InThe Twelfth International Conference on Learning Representations.https: //openreview.net/forum?id=PxoFut3dWW
work page 2024
-
[19]
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. 2024. QUEST: query-aware sparsity for efficient long- context LLM inference. InProceedings of the 41st International Con- ference on Machine Learning(Vienna, Austria)(ICML’24). JMLR.org, Article 1955, 11 pages
work page 2024
-
[20]
Xin Wang, Yu Zheng, Zhongwei Wan, and Mi Zhang. 2025. SVD- LLM: Truncation-aware Singular Value Decomposition for Large Lan- guage Model Compression. InThe Thirteenth International Confer- ence on Learning Representations.https://openreview.net/forum?id= LNYIUouhdt
work page 2025
-
[21]
Jinqi Xiao, Chengming Zhang, Yu Gong, Miao Yin, Yang Sui, Lizhi Xiang, Dingwen Tao, and Bo Yuan. 2023. HALOC: hardware-aware automatic low-rank compression for compact neural networks. In Proceedings of the Thirty-Seventh AAAI Conference on Artificial In- telligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thir...
- [22]
-
[23]
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lian- min Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, Zhangyang "Atlas" Wang, and Beidi Chen. 2023. H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models. InAdvances in Neural Information Pro- cessing Systems, A. Oh, T. Naumann, A. Globerson...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.