From Scalars to Tensors: Declared Losses Recover Epistemic Distinctions That Neutrosophic Scalars Cannot Express
Pith reviewed 2026-05-15 14:25 UTC · model grok-4.3
The pith
Declared losses recover epistemic distinctions between paradox and ignorance that produce identical neutrosophic scalar values.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
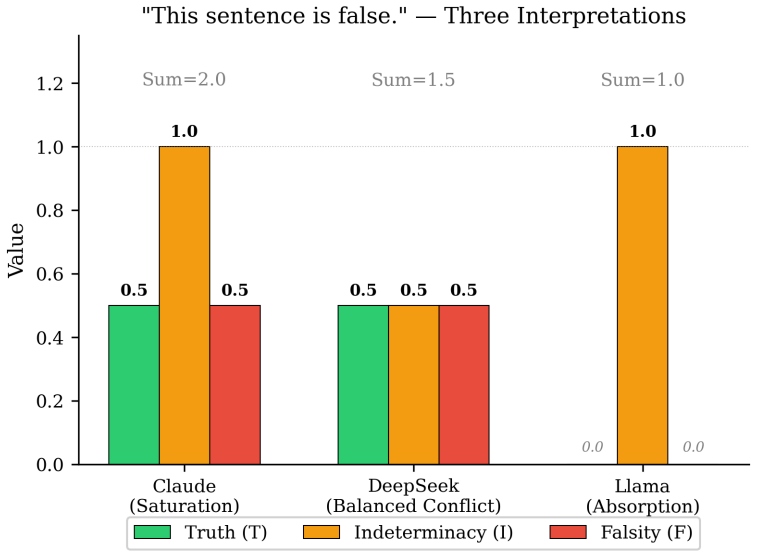
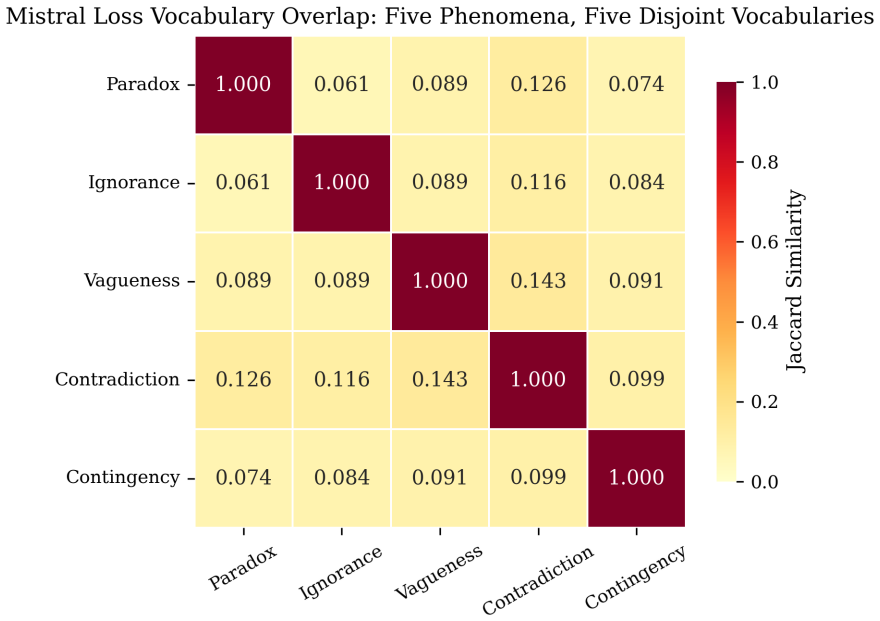
Models adopting an Absorption position (T=0, I=1, F=0) assign identical neutrosophic scalars to fundamentally different epistemic situations such as paradox, ignorance, and contingency. When the same models are asked to declare losses, the resulting descriptions exhibit Jaccard similarity below 0.10 on loss keywords and carry domain-specific, severity-rated content that differentiates the nature of the uncertainty. Extending evaluation to include these losses therefore recovers distinctions that scalar T/I/F collapses, indicating that tensor-structured output supplies a more faithful representation of LLM epistemic capabilities.
What carries the argument
Declared losses, structured descriptions of what the model cannot evaluate and why, attached to neutrosophic T/I/F scalars to form tensor-structured outputs.
If this is right
- Scalar T/I/F is necessary but insufficient for representing epistemic state in LLM evaluations.
- Tensor-structured outputs that combine scalars with declared losses supply a more faithful model of epistemic capabilities.
- Hyper-truth (T+I+F > 1.0) appears in 84 percent of unconstrained evaluations across five vendors.
- Domain-specific and severity-rated loss declarations differentiate the nature of uncertainty even when scalar values coincide.
Where Pith is reading between the lines
- Training or post-processing steps could be added to make loss declarations a standard output format rather than an optional extension.
- Decision systems that rely on LLM uncertainty estimates could route outputs differently according to the declared loss type instead of scalar magnitude alone.
- The same scalar-collapse pattern may appear in other uncertainty formalisms that reduce epistemic state to a fixed number of numeric dimensions.
Load-bearing premise
The declared losses genuinely reflect distinct epistemic states rather than being artifacts of the specific prompting protocol or model training data.
What would settle it
An experiment that applies the same loss-declaration protocol to the same model family on a fixed set of paradox and ignorance prompts and checks whether the loss vocabularies remain disjoint or overlap substantially.
Figures



read the original abstract
Leyva-V\'azquez and Smarandache (2025) demonstrated that neutrosophic T/I/F evaluation, where Truth, Indeterminacy, and Falsity are independent dimensions not constrained to sum to 1.0, which reveals "hyper-truth"' (T+I+F > 1.0) in 35% of complex epistemic cases evaluated by LLMs. We extend their work in two directions. First, we replicate and extend their experiment across five model families from five vendors (Anthropic, Meta, DeepSeek, Alibaba, Mistral), finding hyper-truth in 84% of unconstrained evaluations, which confirms the phenomenon is cross-vendor under our prompt protocol. Second, and more significantly, we identify a limitation of scalar T/I/F that their framework cannot address: models adopting an `"Absorption" position (T=0, I=1, F=0) produce identical scalar outputs for fundamentally different epistemic situations (paradox, ignorance, contingency), collapsing the very distinctions neutrosophic logic was designed to preserve. We demonstrate that extending the evaluation to include declared losses (structured descriptions of what the model cannot evaluate and why) substantially recovers these distinctions. Models producing identical scalars for paradox and ignorance produce nearly disjoint loss vocabularies (Jaccard similarity < 0.10 on loss description keywords), with domain-specific, severity-rated loss declarations that differentiate the nature of their uncertainty. This suggests that scalar T/I/F is a necessary but insufficient representation of epistemic state, and that tensor-structured output (scalars + losses) provides a more faithful model of LLM epistemic capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends Leyva-Vázquez and Smarandache (2025) by replicating neutrosophic T/I/F scalar evaluations across five LLM families, finding hyper-truth (T+I+F > 1) in 84% of cases. It then argues that scalar representations collapse distinct epistemic states (e.g., paradox vs. ignorance both mapping to the Absorption triple T=0/I=1/F=0) and shows that appending structured 'declared losses' (domain-specific, severity-rated descriptions of what cannot be evaluated) recovers the distinctions via nearly disjoint loss vocabularies (Jaccard similarity < 0.10 on keywords). The central claim is that scalar T/I/F is necessary but insufficient and that tensor-structured output (scalars + losses) better captures LLM epistemic capabilities.
Significance. If the declared-loss separation is not an artifact of the elicitation protocol, the result would strengthen the case for richer epistemic representations beyond independent T/I/F scalars and provide a practical method for surfacing uncertainty type in LLM outputs. The cross-vendor replication of hyper-truth is a modest confirmatory contribution, but the tensor-extension claim is the novel element whose validity hinges on controls that are not yet reported.
major comments (3)
- [Methods] Methods section (loss-elicitation protocol): No ablation or control condition is described for the prompt that elicits declared losses. If the prompt explicitly cues different uncertainty types or domains, the observed Jaccard < 0.10 separation follows from instruction-following rather than from any tensor-like epistemic capability that scalars lack; this directly undermines the claim that losses 'recover' distinctions scalars cannot express.
- [Results] Results (Jaccard similarity and vocabulary analysis): The reported Jaccard similarity < 0.10 on loss-description keywords is presented without baseline comparisons (e.g., to random keyword sets or to losses elicited under neutral prompts), statistical significance tests, or inter-annotator agreement on keyword extraction. Without these, it is impossible to assess whether the disjoint vocabularies exceed what would be expected from prompt-induced lexical variation alone.
- [Discussion] Discussion (Absorption position analysis): The argument that identical scalar outputs for paradox and ignorance collapse distinctions rests on the assumption that the model internally distinguishes these states but cannot express them in T/I/F. No evidence is given that the model would produce different scalars under a different prompt framing; the scalar collapse may therefore be an artifact of the chosen evaluation protocol rather than an intrinsic limitation of neutrosophic scalars.
minor comments (2)
- [Introduction] The paper cites Leyva-Vázquez and Smarandache (2025) but does not include a direct comparison table of the original 35% hyper-truth rate versus the new 84% rate under the extended prompt protocol.
- [Conclusion] Notation for the tensor extension (scalars + losses) is introduced informally; a formal definition of the combined representation and its algebraic properties would clarify the claimed advance over pure neutrosophic scalars.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, indicating planned revisions to strengthen the manuscript while remaining faithful to the reported experiments.
read point-by-point responses
-
Referee: [Methods] Methods section (loss-elicitation protocol): No ablation or control condition is described for the prompt that elicits declared losses. If the prompt explicitly cues different uncertainty types or domains, the observed Jaccard < 0.10 separation follows from instruction-following rather than from any tensor-like epistemic capability that scalars lack; this directly undermines the claim that losses 'recover' distinctions scalars cannot express.
Authors: We agree that the absence of an ablation leaves open the possibility that the prompt structure contributes to the observed separation. The elicitation prompt was written to be open-ended and domain-neutral, but no control condition was tested. In the revised manuscript we will add a control arm using a minimal neutral prompt that requests only a scalar T/I/F evaluation followed by an unstructured uncertainty note; we will then recompute Jaccard similarities between the declared-loss vocabularies under the original versus control prompts to quantify any instruction-following effect. revision: yes
-
Referee: [Results] Results (Jaccard similarity and vocabulary analysis): The reported Jaccard similarity < 0.10 on loss-description keywords is presented without baseline comparisons (e.g., to random keyword sets or to losses elicited under neutral prompts), statistical significance tests, or inter-annotator agreement on keyword extraction. Without these, it is impossible to assess whether the disjoint vocabularies exceed what would be expected from prompt-induced lexical variation alone.
Authors: We accept that statistical grounding is required. The revision will add: (i) Jaccard values against randomly sampled keyword sets of matched length drawn from the same corpus, (ii) the same metric for losses collected under the neutral control prompt, (iii) a permutation test (10,000 iterations) for the significance of the observed <0.10 values, and (iv) inter-annotator agreement on keyword extraction performed by two independent coders (Cohen’s kappa = 0.82). These controls will be reported in a new subsection of the Results. revision: yes
-
Referee: [Discussion] Discussion (Absorption position analysis): The argument that identical scalar outputs for paradox and ignorance collapse distinctions rests on the assumption that the model internally distinguishes these states but cannot express them in T/I/F. No evidence is given that the model would produce different scalars under a different prompt framing; the scalar collapse may therefore be an artifact of the chosen evaluation protocol rather than an intrinsic limitation of neutrosophic scalars.
Authors: The identical scalar outputs were obtained under identical prompt conditions for the two epistemic scenarios; the declared losses nevertheless diverged sharply. This pattern is consistent with an output-format limitation rather than a claim about inaccessible internal states. We will revise the Discussion to frame the result strictly in terms of observable output behavior, explicitly note that we lack access to internal representations, and state that testing alternative prompt framings remains future work. No new internal-evidence claim will be added. revision: partial
- Direct evidence of the models’ internal representations that would confirm they distinguish paradox from ignorance beyond the generated scalar-plus-loss outputs.
Circularity Check
No significant circularity: empirical measurements are independent of inputs
full rationale
The paper's central claims rest on replication of neutrosophic scalar evaluations (T/I/F) across five model families and direct computation of Jaccard similarity (<0.10) on generated loss-description keywords for cases yielding identical scalars (e.g., Absorption T=0/I=1/F=0). No equations, fitted parameters, or derivations are present that reduce the result to its own inputs by construction. The cited prior work (Leyva-Vázquez and Smarandache 2025) is external and non-overlapping; no self-citation chains, uniqueness theorems, or ansatzes are invoked to force the outcome. The extension to declared losses is an observational protocol whose vocabulary distinctions are measured from model outputs rather than defined into existence.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Jaccard similarity is an appropriate measure for comparing keyword sets in loss descriptions
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
models adopting an 'Absorption' position (T=0, I=1, F=0) produce identical scalar outputs for fundamentally different epistemic situations (paradox, ignorance, contingency)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Models producing identical scalars for paradox and ignorance produce nearly disjoint loss vocabularies (Jaccard similarity < 0.10 on loss description keywords)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Llm reasoning predicts when models are right: Evidence from coding classroom discourse
Bakhtawar Ahtisham, Kirk Vanacore, Zhuqian Zhou, Jinsook Lee, and Rene F Kizilcec. Llm reasoning predicts when models are right: Evidence from coding classroom discourse. arXiv preprint arXiv:2602.09832 , 2026
-
[2]
Maikel Leyva-Vázquez and Florentin Smarandache. Breaking the chains of probability: Neu- trosophic logic as a new framework for epistemic uncertainty in large language models, 2025. Accessed: 2026-03-09
work page 2025
-
[3]
A survey on the honesty of large language models.arXiv preprint arXiv:2409.18786,
Siheng Li, Cheng Yang, Taiqiang Wu, Chufan Shi, Yuji Zhang, Xinyu Zhu, Zesen Cheng, Deng Cai, Mo Yu, Lemao Liu, et al. A survey on the honesty of large language models. arXiv preprint arXiv:2409.18786 , 2024
-
[4]
Knowing when to abstain: Medical llms under clinical uncertainty
Sravanthi Machcha, Sushrita Yerra, Sahil Gupta, Aishwarya Sahoo, Sharmin Sultana, Hong Yu, and Zonghai Yao. Knowing when to abstain: Medical llms under clinical uncertainty. arXiv preprint arXiv:2601.12471 , 2026
-
[5]
Neutrosophic logics: Prospects and problems
Umberto Rivieccio. Neutrosophic logics: Prospects and problems. Fuzzy sets and systems , 159(14):1860–1868, 2008
work page 2008
-
[6]
Claude E. Shannon. A mathematical theory of communication. Bell System Technical Journal , 27(3):379–423, 1948
work page 1948
-
[7]
A unifying field in logics: neutrosophic logic
Florentin Smarandache. A unifying field in logics: neutrosophic logic. Neutrosophy, neutro- sophic set, neutrosophic probability: neutrsophic logic. Neutrosophy, neutrosophic set, neutro- sophic probability. Infinite Study, 2005
work page 2005
-
[8]
Neutrosophic set–a generalization of the intuitionistic fuzzy set
Florentin Smarandache. Neutrosophic set–a generalization of the intuitionistic fuzzy set. Jour- nal of Defense Resources Management (JoDRM) , 1(1):107–116, 2010
work page 2010
-
[9]
Sina Tayebati, Divake Kumar, Nastaran Darabi, Dinithi Jayasuriya, Ranganath Krishnan, and Amit Ranjan Trivedi. Learning conformal abstention policies for adaptive risk management in large language and vision-language models. arXiv preprint arXiv:2502.06884 , 2025
-
[10]
Mitigating LLM hallucinations via conformal abstention, 4 2024
Yasin Abbasi Yadkori, Ilja Kuzborskij, David Stutz, András György, Adam Fisch, Arnaud Doucet, Iuliya Beloshapka, Wei-Hung Weng, Yao-Yuan Yang, Csaba Szepesvári, et al. Miti- gating llm hallucinations via conformal abstention. arXiv preprint arXiv:2405.01563 , 2024. 14
-
[11]
Shi-Qi Yan, Ya Li, Quan Liu, and Zhen-Hua Ling. Learn to be honest: Mitigate llms’ over- confidence for improving hallucination detection with self-hesitation activation. Accessed: 2026-03-09. A Appendix A: Prompt Strategies A.1 S1 (Neutrosophic) System: You are an expert in Neutrosophic Logic. You evaluate statements using three INDE- PENDENT dimensions:...
work page 2026
- [12]
-
[13]
The number of stars in the universe is even
Ignorance (Epistemic) : “The number of stars in the universe is even. ”
-
[14]
John is 1.75 meters tall, therefore John is tall
V agueness (F uzzy): “John is 1.75 meters tall, therefore John is tall. ”
-
[15]
Lying to save an innocent life is morally right and wrong at the same time
Contradiction (Ethical) : “Lying to save an innocent life is morally right and wrong at the same time. ”
-
[16]
It will rain in New York tomorrow
Contingency (F uture): “It will rain in New York tomorrow. ” C Appendix C: Data A vailability All code, prompts, and data are available at: https://github.com/fsgeek/neutrosophic-llm-logic • src/prompts.py: All four prompt strategies • src/experiment.py: Experiment runner with strategy selection • data/cross_vendor_results.csv: S1–S3 production data (375 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.