Recognition: 2 theorem links
· Lean TheoremBelief-State RWKV for Reinforcement Learning under Partial Observability
Pith reviewed 2026-05-13 21:53 UTC · model grok-4.3
The pith
Interpreting RWKV recurrent states as explicit belief states with mean and uncertainty improves RL performance under partial observability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By deriving a compact uncertainty-aware state b_t = (μ_t, Σ_t) from RWKV-style recurrent statistics and conditioning control on both memory and uncertainty, belief-state policies achieve performance that nearly matches the best recurrent baseline overall while slightly improving return on the hardest in-distribution regime and under a held-out noise shift in a pilot RL experiment with hidden episode-level observation noise.
What carries the argument
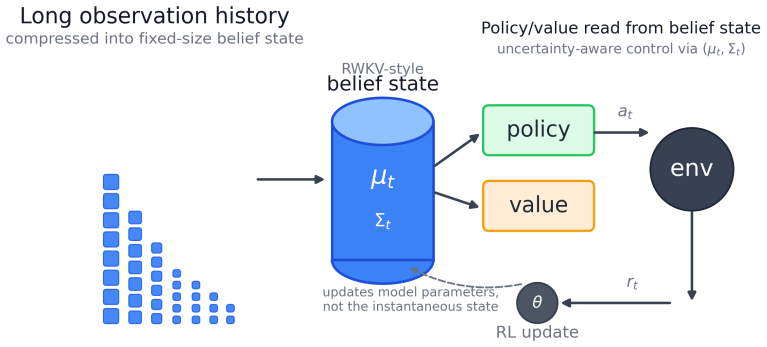
The belief state b_t = (μ_t, Σ_t) derived from RWKV-style recurrent statistics, which allows the policy to depend on both memory content and its associated uncertainty.
Load-bearing premise
The compact uncertainty-aware state b_t = (μ_t, Σ_t) derived from RWKV-style recurrent statistics provides a faithful and useful representation of belief and uncertainty that improves control under partial observability.
What would settle it
A controlled experiment showing that belief-state policies consistently underperform standard recurrent policies across multiple partial observability tasks with varying noise levels.
Figures


read the original abstract
We propose a stronger formulation of RL on top of RWKV-style recurrent sequence models, in which the fixed-size recurrent state is explicitly interpreted as a belief state rather than an opaque hidden vector. Instead of conditioning policy and value on a single summary h_t, we maintain a compact uncertainty-aware state b_t = (\mu_t, \Sigma_t) derived from RWKV-style recurrent statistics and let control depend on both memory and uncertainty. This design targets a key weakness of plain fixed-state policies in partially observed settings: they may store evidence, but not necessarily confidence. We present the method, a theoretical program, and a pilot RL experiment with hidden episode-level observation noise together with a test-time noise sweep. The pilot shows that belief-state policies nearly match the best recurrent baseline overall while slightly improving return on the hardest in-distribution regime and under a held-out noise shift. Additional ablations show that this simple belief readout is currently stronger than two more structured extensions, namely gated memory control and privileged belief targets, underscoring the need for richer benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes interpreting the fixed-size recurrent state of RWKV-style sequence models as an explicit belief state b_t = (μ_t, Σ_t) for RL under partial observability. Instead of conditioning policies and values on an opaque hidden vector h_t, the method derives a compact uncertainty-aware state directly from RWKV recurrent statistics and feeds both memory and uncertainty into the control networks. A pilot experiment on POMDPs with hidden episode-level observation noise and a test-time noise sweep shows belief-state policies nearly match the strongest recurrent baseline overall while yielding modest gains on the hardest in-distribution cases and under a held-out noise shift; ablations indicate that adding gated memory or privileged belief targets does not improve further.
Significance. If the empirical pattern holds under more rigorous evaluation, the approach supplies a parameter-free mechanism for injecting uncertainty awareness into recurrent policies without enlarging the state or introducing new learned components. This directly targets a known limitation of fixed-state recurrent RL in POMDPs and could be useful for domains with sensor noise or distribution shift. The pilot's internal consistency (simple readout outperforming more elaborate extensions) and the absence of circularity in the derivation are positive features.
major comments (2)
- [Experiments] Experimental section: the central claim of slight improvement on the hardest in-distribution regime and under held-out noise rests on pilot results that omit exact baseline implementations, hyperparameter ranges, number of seeds, statistical tests, and any data-exclusion criteria. Without these details the reported gains cannot be independently verified or assessed for robustness.
- [Method] §3 (method): while the derivation of b_t = (μ_t, Σ_t) from existing RWKV statistics is parameter-free and internally consistent, the paper does not specify how the policy and value heads are architecturally modified to consume the concatenated (μ_t, Σ_t) vector, nor whether any additional normalization or scaling is applied; this leaves the precise interface between belief state and control networks underspecified.
minor comments (2)
- [Introduction] The abstract and introduction refer to a 'theoretical program' that is not expanded in the provided text; if this program contains formal statements or proofs, they should be summarized or referenced.
- [Method] Notation: the symbols μ_t and Σ_t are introduced without an explicit equation showing their computation from the RWKV recurrent update; adding this equation would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of our belief-state formulation. We address each major comment below and commit to revisions that will strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Experiments] Experimental section: the central claim of slight improvement on the hardest in-distribution regime and under held-out noise rests on pilot results that omit exact baseline implementations, hyperparameter ranges, number of seeds, statistical tests, and any data-exclusion criteria. Without these details the reported gains cannot be independently verified or assessed for robustness.
Authors: We agree that the pilot results require substantially more detail to support independent verification. In the revised manuscript we will expand the experimental section to report: exact baseline implementations (including code-level differences from the belief-state variant), the full hyperparameter ranges explored together with the final selected values, the number of random seeds (minimum five per condition), statistical tests (e.g., paired t-tests with confidence intervals), and any data-exclusion criteria. These additions will allow readers to assess the robustness of the modest gains observed on the hardest in-distribution cases and under the held-out noise shift. revision: yes
-
Referee: [Method] §3 (method): while the derivation of b_t = (μ_t, Σ_t) from existing RWKV statistics is parameter-free and internally consistent, the paper does not specify how the policy and value heads are architecturally modified to consume the concatenated (μ_t, Σ_t) vector, nor whether any additional normalization or scaling is applied; this leaves the precise interface between belief state and control networks underspecified.
Authors: We concur that the interface between the belief state and the control networks is currently underspecified. The revised manuscript will explicitly describe the architectural modification: the concatenated vector (μ_t, Σ_t) is fed directly as input to the policy and value heads, which retain the same MLP architecture as the baseline but with input dimensionality adjusted accordingly. We will also state that layer normalization is applied to the concatenated vector before the first linear layer, with no additional scaling beyond standard weight initialization; this detail will be accompanied by a short pseudocode snippet for clarity. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper extracts the compact belief state b_t = (μ_t, Σ_t) directly from existing RWKV recurrent statistics with no additional parameters or self-referential fitting. Policy and value networks are then conditioned on this readout in a standard RL setup. All reported results arise from empirical comparisons against recurrent baselines in a noise-injection POMDP, including ablations and OOD sweeps; no equation reduces to its own inputs by construction, no uniqueness theorem is imported from self-citation, and no ansatz is smuggled via prior work. The construction is internally consistent and externally falsifiable via the pilot experiments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption RWKV-style recurrent statistics can be meaningfully interpreted as parameters of a belief distribution (mean and covariance).
invented entities (1)
-
belief state b_t = (μ_t, Σ_t)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanJcost stability and bounded trajectories under contraction echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Assumption 2 (Stable linear recurrence). Each linear recurrent block satisfies ∥A_i∥_2 ≤ ρ <1 ... Proposition 2 (Bounded belief-state trajectory) ... sup_t ∥b_t∥_2 ≤ C/(1−ρ)
-
IndisputableMonolith/Foundation/BranchSelection.leanlow-rank reward-relevant subspace approximation echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Assumption 3 (Low-rank reward relevance) ... |Q^π(b,a)−Q^π(Pr b,a)|≤δ_r ... Proposition 3 (Low-rank adapter approximation)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Philipp Becker, Niklas Freymuth, and Gerhard Neumann. Kalmamba: Towards efficient probabilistic state space models for rl under uncertainty.arXiv preprint arXiv:2406.15131,
-
[2]
Predictive state recurrent neural networks.arXiv preprint arXiv:1705.09353,
Carlton Downey, Ahmed Hefny, Boyue Li, Byron Boots, and Geoffrey Gordon. Predictive state recurrent neural networks.arXiv preprint arXiv:1705.09353,
-
[3]
Ayoub Echchahed and Pablo Samuel Castro. A survey of state representation learning for deep reinforcement learning.arXiv preprint arXiv:2506.17518,
-
[4]
Dibya Ghosh, Jad Rahme, Aviral Kumar, Amy Zhang, Ryan P. Adams, and Sergey Levine. Why generalization in rl is difficult: Epistemic pomdps and implicit partial observability.arXiv preprint arXiv:2107.06277,
-
[5]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Deep recurrent q-learning for partially observable mdps.arXiv preprint arXiv:1507.06527,
Matthew Hausknecht and Peter Stone. Deep recurrent q-learning for partially observable mdps.arXiv preprint arXiv:1507.06527,
-
[7]
Recurrent predictive state policy networks.arXiv preprint arXiv:1803.01489,
Ahmed Hefny, Zita Marinho, Wen Sun, Siddhartha Srinivasa, and Geoffrey Gordon. Recurrent predictive state policy networks.arXiv preprint arXiv:1803.01489,
-
[8]
Dongchi Huang, Jiaqi Wang, Yang Li, Chunhe Xia, Tianle Zhang, and Kaige Zhang. Pigdreamer: Privileged information guided world models for safe partially observable reinforcement learning. arXiv preprint arXiv:2508.02159,
-
[9]
Deep Variational Reinforcement Learning for POMDPs
Maximilian Igl, Luisa Zintgraf, Tuan Anh Le, Frank Wood, and Shimon Whiteson. Deep variational reinforcement learning for pomdps.arXiv preprint arXiv:1806.02426,
-
[10]
Maria Krinner, Elie Aljalbout, Angel Romero, and Davide Scaramuzza
URLhttps://openreview.net/forum?id=r1lyTjAqYX. Maria Krinner, Elie Aljalbout, Angel Romero, and Davide Scaramuzza. Accelerating model-based reinforcement learning with state-space world models.arXiv preprint arXiv:2502.20168,
-
[11]
Guided policy optimization under partial observabil- ity.arXiv preprint arXiv:2505.15418,
Yueheng Li, Guangming Xie, and Zongqing Lu. Guided policy optimization under partial observabil- ity.arXiv preprint arXiv:2505.15418,
-
[12]
Popgym: Benchmarking partially observable reinforcement learning.arXiv preprint arXiv:2303.01859,
Steven Morad, Ryan Kortvelesy, Matteo Bettini, Stephan Liwicki, and Amanda Prorok. Popgym: Benchmarking partially observable reinforcement learning.arXiv preprint arXiv:2303.01859,
-
[13]
8 Tianwei Ni, Benjamin Eysenbach, and Ruslan Salakhutdinov. Recurrent model-free rl can be a strong baseline for many pomdps.arXiv preprint arXiv:2110.05038,
-
[14]
Toshihiro Ota. Decision mamba: Reinforcement learning via sequence modeling with selective state spaces.arXiv preprint arXiv:2403.19925,
-
[15]
Emilio Parisotto, H. Francis Song, Jack W. Rae, Razvan Pascanu, Caglar Gulcehre, Siddhant M. Jayakumar, Max Jaderberg, Raphael Lopez Kaufman, Aidan Clark, Seb Noury, Matthew M. Botvinick, Nicolas Heess, and Raia Hadsell. Stabilizing transformers for reinforcement learning. arXiv preprint arXiv:1910.06764,
-
[16]
RWKV: Reinventing RNNs for the Transformer Era
Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Stella Biderman, Huanqi Cao, Xin Cheng, Michael Chung, Matteo Grella, et al. Rwkv: Reinventing rnns for the transformer era.arXiv preprint arXiv:2305.13048,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Eagle and finch: Rwkv with matrix-valued states and dynamic recurrence
Bo Peng, Daniel Goldstein, Quentin Anthony, Alon Albalak, Eric Alcaide, Stella Biderman, Eugene Cheah, Xingjian Du, Teddy Ferdinan, Haowen Hou, et al. Eagle and finch: Rwkv with matrix- valued states and dynamic recurrence.arXiv preprint arXiv:2404.05892,
-
[18]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Ruo Yu Tao, Kaicheng Guo, Cameron Allen, and George Konidaris. Benchmarking partial observ- ability in reinforcement learning with a suite of memory-improvable domains.arXiv preprint arXiv:2508.00046,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.