I Can't Believe TTA Is Not Better: When Test-Time Augmentation Hurts Medical Image Classification
Pith reviewed 2026-05-10 18:39 UTC · model grok-4.3
The pith
Aggregating predictions from multiple augmented copies of a test image reduces accuracy on medical image classification tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
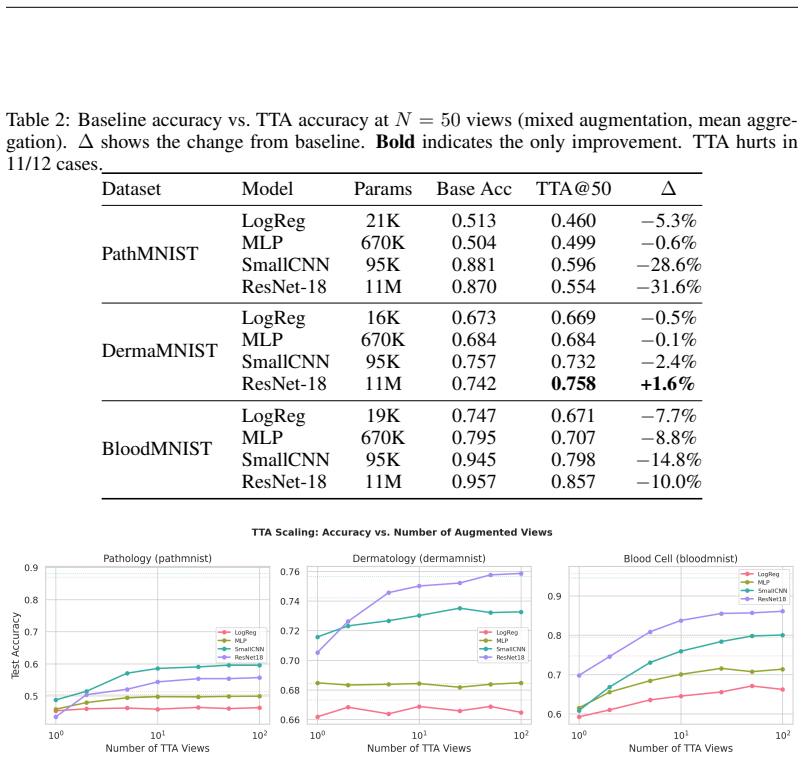
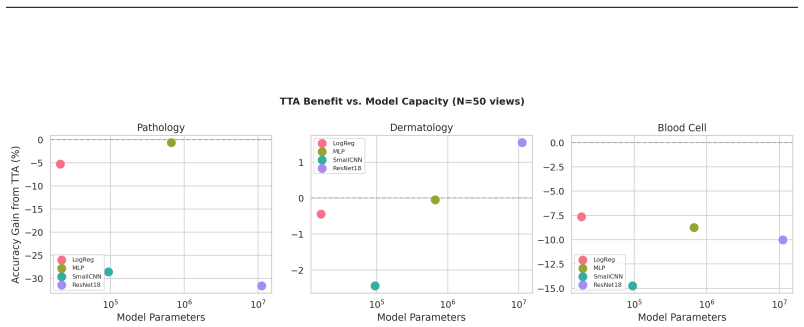
The principal finding is that TTA with standard augmentation pipelines consistently degrades accuracy relative to single-pass inference, with drops as severe as 31.6 percentage points for ResNet-18 on pathology images. This degradation affects all architectures tested, including convolutional models, and worsens with more augmented views. The sole exception is a modest gain of 1.6 percent for ResNet-18 on dermatology images. The identified cause is distribution shift between augmented and training-time inputs amplified by batch normalization statistics mismatch.
What carries the argument
Distribution shift between training-time inputs and test-time augmented inputs, amplified by mismatch in batch normalization statistics.
If this is right
- Test-time augmentation should be validated on each specific model-dataset pair instead of applied as a default step.
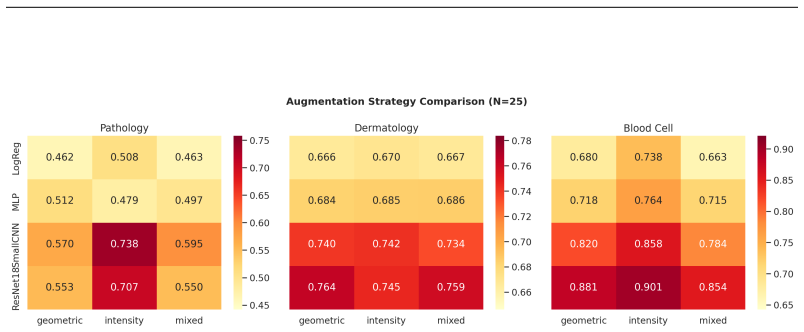
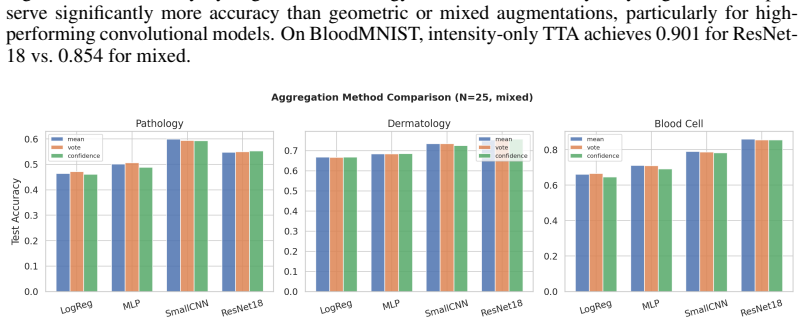
- Intensity-only augmentations preserve more accuracy than those that include geometric transforms.
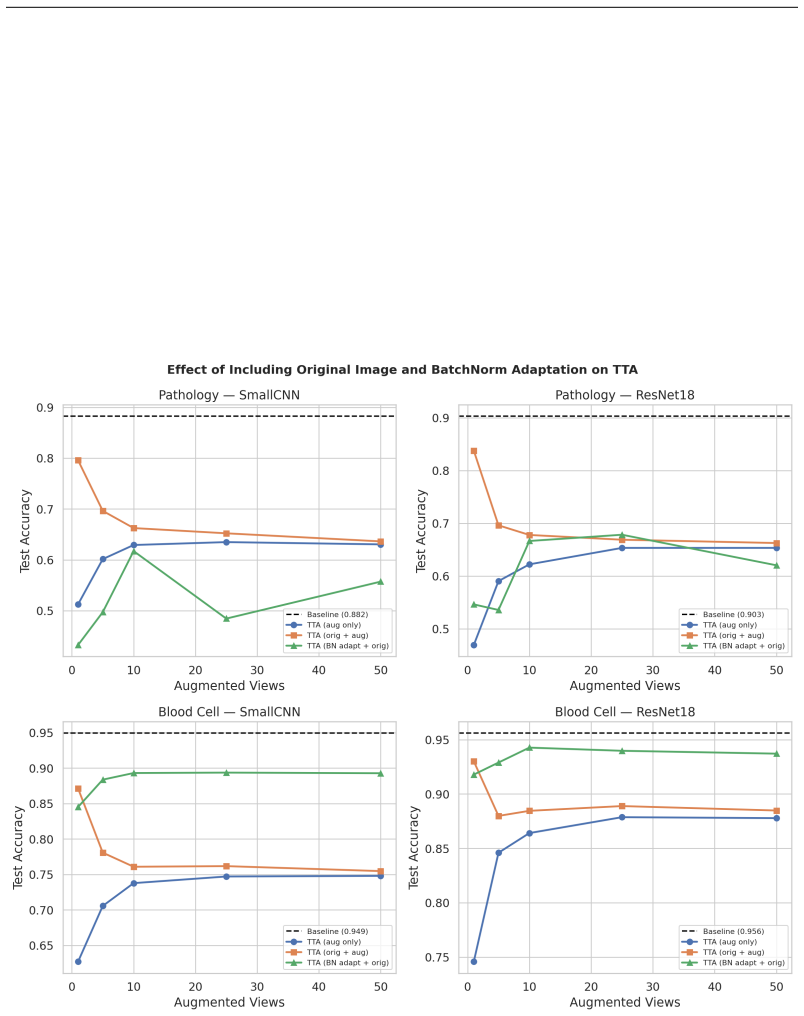
- Including the original unaugmented image in the ensemble reduces but does not eliminate the accuracy drop.
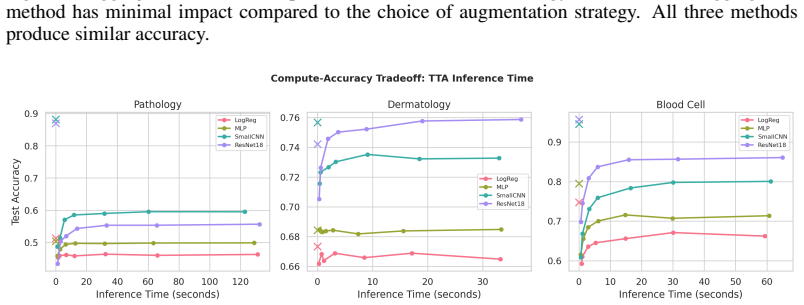
- Increasing the number of augmented views tends to enlarge the performance penalty rather than improve results.
Where Pith is reading between the lines
- The same normalization mismatch could appear in non-medical domains that rely on batch normalization without retraining on test distributions.
- Techniques that recompute or adapt batch normalization statistics at test time might recover some of the expected benefit from augmentation.
- Competition entries or deployed systems that use default TTA on medical data may be leaving accuracy on the table compared with simpler single-pass inference.
Load-bearing premise
The accuracy drops are caused primarily by distribution shift from augmentations interacting with batch normalization, and the three MedMNIST v2 datasets plus four architectures represent medical imaging settings broadly enough for the caution to apply elsewhere.
What would settle it
A finding that standard test-time augmentation improves accuracy on additional medical imaging datasets or models outside the MedMNIST v2 collection would contradict the central result.
Figures
read the original abstract
Test-time augmentation (TTA)--aggregating predictions over multiple augmented copies of a test input--is widely assumed to improve classification accuracy, particularly in medical imaging where it is routinely deployed in production systems and competition solutions. We present a systematic empirical study challenging this assumption across three MedMNIST v2 benchmarks and four architectures spanning three orders of magnitude in parameter count (21K to 11M). Our principal finding is that TTA with standard augmentation pipelines consistently degrades accuracy relative to single-pass inference, with drops as severe as 31.6 percentage points for ResNet-18 on pathology images. This degradation affects all architectures, including convolutional models, and worsens with more augmented views. The sole exception is ResNet-18 on dermatology images, which gains a modest +1.6%. We identify the distribution shift between augmented and training-time inputs--amplified by batch normalization statistics mismatch--as the primary mechanism. Our ablation studies show that augmentation strategy matters critically: intensity-only augmentations preserve more performance than geometric transforms, and including the original unaugmented image partially mitigates but does not eliminate the accuracy drop. These findings serve as a cautionary note for practitioners: TTA should not be applied as a default post-hoc improvement but must be validated on the specific model-dataset combination.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a systematic empirical study on three MedMNIST v2 benchmarks (PathMNIST, DermaMNIST, and a third) using four architectures (ResNet-18 to larger models) showing that standard test-time augmentation (TTA) pipelines consistently reduce classification accuracy relative to single-pass inference, with drops reaching 31.6 percentage points for ResNet-18 on pathology images. The degradation is attributed primarily to distribution shift between augmented test inputs and training data, amplified by batch-normalization statistics mismatch; ablations indicate intensity-only augmentations are less harmful than geometric transforms, more views worsen the effect, and including the unaugmented image provides partial mitigation. The authors conclude with a cautionary note against default TTA use in medical imaging without per-model validation.
Significance. If the central empirical observations hold, the work has clear practical value by challenging the routine deployment of TTA in medical imaging pipelines and competitions. The use of public benchmarks, multiple model scales, and targeted ablations on augmentation type and view count provides concrete, falsifiable guidance. However, the significance is tempered by the narrow dataset scope; a confirmed negative result on standardized low-resolution tasks would still prompt re-examination of TTA assumptions but would not yet support broad claims across clinical medical imaging.
major comments (3)
- [Results] Results section (principal finding and Table reporting 31.6 pp drop): the manuscript reports point estimates of accuracy degradation but does not include standard deviations across runs, error bars, or statistical significance tests (e.g., paired t-tests or Wilcoxon tests) comparing TTA versus single-pass inference. Without these, it is impossible to assess whether the observed drops, including the largest ones, are reliably larger than experimental noise.
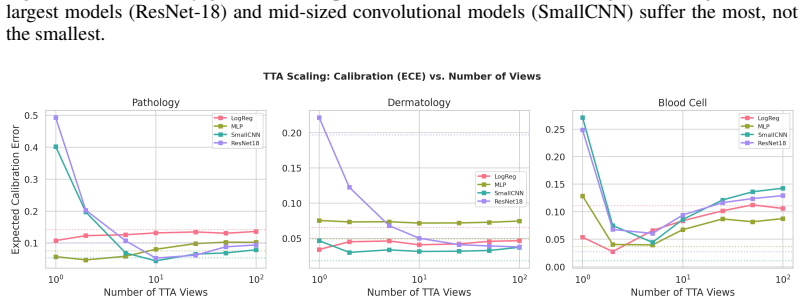
- [Experiments / Discussion] Experiments and Discussion sections: the causal attribution to batch-normalization statistics mismatch is supported only by indirect ablations (intensity vs. geometric, original-image inclusion). Direct evidence such as measuring the shift in BN running statistics between training and augmented test batches, or controlled experiments replacing BN with layer-norm or group-norm, is absent; this leaves the primary mechanism claim plausible but not fully load-bearing.
- [Introduction / Conclusion] Introduction and Conclusion: the cautionary note is framed for 'medical image classification' in general, yet all quantitative results are confined to three low-resolution, single-modality, preprocessed MedMNIST v2 subsets with fixed splits. No experiments address higher-resolution, multi-center, or multi-modal data (e.g., CT with intensity windowing or pathology with stain normalization), which are common in clinical pipelines and could alter the distribution-shift magnitude.
minor comments (2)
- [Abstract] The abstract states 'three MedMNIST v2 benchmarks' but does not name the third dataset; the full text should explicitly list all three (PathMNIST, DermaMNIST, and the remaining one) for reproducibility.
- [Methods] Notation for augmentation pipelines and the exact TTA aggregation method (e.g., mean, max, or learned) should be defined once in a dedicated subsection rather than scattered across the text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and outline the revisions we will incorporate.
read point-by-point responses
-
Referee: [Results] Results section (principal finding and Table reporting 31.6 pp drop): the manuscript reports point estimates of accuracy degradation but does not include standard deviations across runs, error bars, or statistical significance tests (e.g., paired t-tests or Wilcoxon tests) comparing TTA versus single-pass inference. Without these, it is impossible to assess whether the observed drops, including the largest ones, are reliably larger than experimental noise.
Authors: We agree that including measures of variability and statistical tests would strengthen the reliability of the reported accuracy drops. In the revised manuscript, we will rerun the principal experiments across multiple random seeds (minimum of 5 runs per configuration) and report mean accuracy with standard deviations. We will also add paired t-tests (or Wilcoxon signed-rank tests where normality assumptions are violated) to compare single-pass inference against TTA for each model-dataset pair. These updates will appear in the Results section and the main results table. revision: yes
-
Referee: [Experiments / Discussion] Experiments and Discussion sections: the causal attribution to batch-normalization statistics mismatch is supported only by indirect ablations (intensity vs. geometric, original-image inclusion). Direct evidence such as measuring the shift in BN running statistics between training and augmented test batches, or controlled experiments replacing BN with layer-norm or group-norm, is absent; this leaves the primary mechanism claim plausible but not fully load-bearing.
Authors: We acknowledge that the current support for the batch-normalization mismatch mechanism is indirect. In the revision, we will add direct measurements of the divergence in BN running statistics (means and variances) between the training distribution and the augmented test batches; these will be reported in a new table or figure in the Discussion section. Replacing BN layers with GroupNorm or LayerNorm would require full retraining of the models, which is outside the scope of the current computational budget. We will therefore expand the discussion of the existing ablations to more explicitly link them to the BN hypothesis while noting the norm-replacement experiment as valuable future work. revision: partial
-
Referee: [Introduction / Conclusion] Introduction and Conclusion: the cautionary note is framed for 'medical image classification' in general, yet all quantitative results are confined to three low-resolution, single-modality, preprocessed MedMNIST v2 subsets with fixed splits. No experiments address higher-resolution, multi-center, or multi-modal data (e.g., CT with intensity windowing or pathology with stain normalization), which are common in clinical pipelines and could alter the distribution-shift magnitude.
Authors: We agree that the quantitative results are confined to the three MedMNIST v2 subsets and that the cautionary note should not be over-generalized. In the revised Introduction and Conclusion we will explicitly qualify all claims to these low-resolution, single-modality benchmarks and add a statement that similar effects may or may not hold for higher-resolution, multi-center, or multi-modal clinical data. We will also note that per-model validation remains necessary in any new setting. revision: partial
Circularity Check
No circularity: purely empirical study with direct experimental support
full rationale
The paper reports accuracy measurements and ablations on three public MedMNIST v2 datasets using four standard architectures. No mathematical derivations, equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. All claims reduce directly to the reported experimental outcomes on fixed benchmarks rather than any self-referential loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MedMNIST v2 benchmarks and the four tested architectures are representative of medical image classification practice
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
work page internal anchor Pith review Pith/arXiv arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.