Recognition: no theorem link
MuPPet: Multi-person 2D-to-3D Pose Lifting
Pith reviewed 2026-05-10 19:14 UTC · model grok-4.3
The pith
Explicitly modeling relationships between people allows more accurate lifting of their 2D poses into 3D, especially when some are occluded.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MuPPet is a multi-person 2D-to-3D pose lifting framework that explicitly models inter-person correlations. It does so through Person Encoding to structure individual representations, Permutation Augmentation to enhance training diversity, and Dynamic Multi-Person Attention to adaptively model correlations between individuals. Extensive experiments on group interaction datasets show that this approach significantly outperforms state-of-the-art single- and multi-person 2D-to-3D pose lifting methods while improving robustness in occlusion scenarios.
What carries the argument
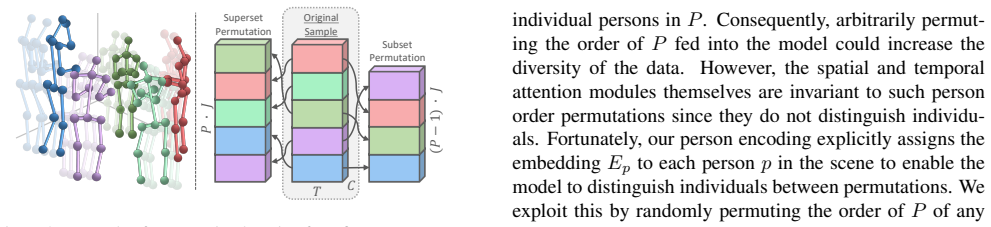
Dynamic Multi-Person Attention that adaptively models correlations between individuals, supported by Person Encoding to structure representations and Permutation Augmentation to increase training variety.
If this is right
- The model can process scenes with any number of people without requiring a fixed group size.
- Accuracy holds up better when one or more individuals are partially hidden from the camera.
- The resulting 3D poses carry richer information about social spatial arrangements.
- Downstream tasks that rely on group pose, such as interaction analysis, receive more reliable input.
Where Pith is reading between the lines
- Extending the same attention structure to video frames could enforce consistency across time without major redesign.
- The emphasis on group context may transfer to related problems like multi-person tracking or collective activity recognition.
- Real-world deployment would benefit from checking performance on crowds larger than those in current benchmark datasets.
Load-bearing premise
That adding explicit modeling of inter-person relationships through encoding, permutation, and attention will consistently raise 3D accuracy and handle changing group sizes and occlusions better than single-person methods.
What would settle it
A new test set containing large groups with frequent mutual occlusions on which MuPPet fails to exceed the accuracy of the strongest single-person lifting baseline.
Figures




read the original abstract
Multi-person social interactions are inherently built on coherence and relationships among all individuals within the group, making multi-person localization and body pose estimation essential to understanding these social dynamics. One promising approach is 2D-to-3D pose lifting which provides a 3D human pose consisting of rich spatial details by building on the significant advances in 2D pose estimation. However, the existing 2D-to-3D pose lifting methods often neglect inter-person relationships or cannot handle varying group sizes, limiting their effectiveness in multi-person settings. We propose MuPPet, a novel multi-person 2D-to-3D pose lifting framework that explicitly models inter-person correlations. To leverage these inter-person dependencies, our approach introduces Person Encoding to structure individual representations, Permutation Augmentation to enhance training diversity, and Dynamic Multi-Person Attention to adaptively model correlations between individuals. Extensive experiments on group interaction datasets demonstrate MuPPet significantly outperforms state-of-the-art single- and multi-person 2D-to-3D pose lifting methods, and improves robustness in occlusion scenarios. Our findings highlight the importance of modeling inter-person correlations, paving the way for accurate and socially-aware 3D pose estimation. Our code is available at: https://github.com/Thomas-Markhorst/MuPPet
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MuPPet, a multi-person 2D-to-3D pose lifting framework that explicitly models inter-person correlations via three introduced components: Person Encoding to structure individual representations, Permutation Augmentation to enhance training diversity, and Dynamic Multi-Person Attention to adaptively model correlations between individuals. It evaluates the approach on group interaction datasets and claims significant outperformance over state-of-the-art single- and multi-person 2D-to-3D lifting methods along with improved robustness under occlusion.
Significance. If the empirical results hold with proper validation, the work would be significant for the field by shifting 2D-to-3D lifting from single-person assumptions to explicit inter-person modeling, which is relevant for social scene understanding and related applications. The release of code at the provided GitHub link supports reproducibility.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: The central claim that MuPPet 'significantly outperforms' SOTA methods and improves occlusion robustness is asserted without any quantitative metrics (e.g., MPJPE or PCK), ablation results isolating the contribution of each of the three components, dataset details, or error analysis. This is load-bearing for the empirical claim and prevents verification that the data supports the assertions.
- [Method] Method section (Dynamic Multi-Person Attention): The description of how the attention mechanism handles varying group sizes (e.g., via masking, padding, or fixed-size assumptions) is not specified in sufficient detail to assess whether it generalizes as claimed beyond the tested datasets.
minor comments (2)
- [Abstract] The abstract would benefit from including one or two key quantitative results and the names of the group interaction datasets used to make the contribution clearer at a glance.
- [Figures and Tables] Ensure that all figures (e.g., architecture diagrams) include clear labels for the three proposed components and that tables compare against both single-person and multi-person baselines with consistent metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our empirical results and methodological details. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The central claim that MuPPet 'significantly outperforms' SOTA methods and improves occlusion robustness is asserted without any quantitative metrics (e.g., MPJPE or PCK), ablation results isolating the contribution of each of the three components, dataset details, or error analysis. This is load-bearing for the empirical claim and prevents verification that the data supports the assertions.
Authors: We agree that the abstract states the performance claim at a high level without numbers (standard for abstracts) and that the Experiments section would benefit from greater explicitness. The current version includes MPJPE results on group interaction datasets and some comparisons, but we acknowledge the absence of dedicated ablations isolating Person Encoding, Permutation Augmentation, and Dynamic Multi-Person Attention, as well as limited dataset statistics and occlusion-specific error analysis. In the revision we will add: (1) a summary table of key MPJPE/PCK numbers in the Experiments section, (2) an ablation study subsection quantifying each component's contribution, (3) expanded dataset descriptions (including group size distributions and occlusion statistics), and (4) error analysis focused on occlusion robustness. These changes will make the supporting evidence fully verifiable. revision: yes
-
Referee: [Method] Method section (Dynamic Multi-Person Attention): The description of how the attention mechanism handles varying group sizes (e.g., via masking, padding, or fixed-size assumptions) is not specified in sufficient detail to assess whether it generalizes as claimed beyond the tested datasets.
Authors: We thank the referee for highlighting this gap in clarity. The Dynamic Multi-Person Attention handles variable group sizes by padding sequences to a fixed maximum length and applying a binary mask that excludes padded tokens from the attention computation (preventing any fixed-size assumption on the actual number of people). We will revise the Method section to include a precise description of the padding and masking procedure, the corresponding equations, and a short pseudocode snippet. This will explicitly demonstrate generalization to arbitrary group sizes within the tested range and beyond. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper introduces MuPPet as a new framework that explicitly adds three components—Person Encoding, Permutation Augmentation, and Dynamic Multi-Person Attention—to model inter-person correlations on top of existing 2D pose estimators. These additions are presented as novel remedies to limitations of prior single-person lifting methods, with performance gains shown via experiments on group datasets. No derivation step reduces by construction to a fitted parameter, self-definition, or a load-bearing self-citation chain; the central claims rest on the independent design of the new modules and external empirical validation rather than renaming or re-deriving inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- Neural network hyperparameters
axioms (1)
- domain assumption Inter-person relationships improve 3D pose lifting accuracy in group settings
Reference graph
Works this paper leans on
-
[1]
In5th IEEE-RAS International Conference on Humanoid Robots, 2005., pages 418–423
Towards a humanoid museum guide robot that interacts with multiple persons. In5th IEEE-RAS International Conference on Humanoid Robots, 2005., pages 418–423. IEEE, 2005. 1
2005
-
[2]
Analyzing free-standing conversational groups: A multimodal approach
Xavier Alameda-Pineda, Yan Yan, Elisa Ricci, Oswald Lanz, and Nicu Sebe. Analyzing free-standing conversational groups: A multimodal approach. InProceedings of the 23rd ACM international conference on Multimedia, pages 5–14,
-
[3]
Blended diffusion for text-driven editing of natural images
Omri Avrahami, Dani Lischinski, and Ohad Fried. Blended diffusion for text-driven editing of natural images.CoRR, abs/2111.14818, 2021. 3
-
[4]
Bodily be- haviors in social interaction: Novel annotations and state-of- the-art evaluation
Michal Balazia, Philipp M ¨uller, ´Akos Levente T´anczos, Au- gust von Liechtenstein, and Francois Bremond. Bodily be- haviors in social interaction: Novel annotations and state-of- the-art evaluation. InProceedings of the 30th ACM Interna- tional Conference on Multimedia, pages 70–79, 2022. 1
2022
-
[5]
Conditional image generation with score-based diffusion models.arXiv preprint arXiv:2111.13606, 2021
Georgios Batzolis, Jan Stanczuk, Carola-Bibiane Sch ¨onlieb, and Christian Etmann. Conditional image generation with score-based diffusion models.CoRR, abs/2111.13606, 2021. 3
-
[6]
Z. Cao, G. Hidalgo Martinez, T. Simon, S. Wei, and Y . A. Sheikh. Openpose: Realtime multi-person 2d pose estima- tion using part affinity fields.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019. 5
2019
-
[7]
Ju Yong Chang, Gyeongsik Moon, and Kyoung Mu Lee. Ab- sposelifter: Absolute 3d human pose lifting network from a single noisy 2d human pose.CoRR, abs/1910.12029, 2019. 2
-
[8]
3d human pose es- timation= 2d pose estimation+ matching
Ching-Hang Chen and Deva Ramanan. 3d human pose es- timation= 2d pose estimation+ matching. InProceedings of the IEEE conference on computer vision and pattern recog- nition, pages 7035–7043, 2017. 2
2017
-
[9]
Hongsuk Choi, Gyeongsik Moon, JoonKyu Park, and Ky- oung Mu Lee. 3dcrowdnet: 2d human pose-guided3d crowd human pose and shape estimation in the wild.CoRR, abs/2104.07300, 2021. 2
-
[10]
Jeongjun Choi, Dongseok Shim, and H. Jin Kim. DiffuPose: Monocular 3d human pose estimation via denoising diffu- sion probabilistic model. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3773–3780. ISSN: 2153-0866. 2, 3
-
[11]
Op- timizing network structure for 3d human pose estimation
Hai Ci, Chunyu Wang, Xiaoxuan Ma, and Yizhou Wang. Op- timizing network structure for 3d human pose estimation. In Proceedings of the IEEE/CVF international conference on computer vision, pages 2262–2271, 2019. 2
2019
-
[12]
Gfpose: Learning 3d human pose prior with gradient fields, 2022
Hai Ci, Mingdong Wu, Wentao Zhu, Xiaoxuan Ma, Hao Dong, Fangwei Zhong, and Yizhou Wang. Gfpose: Learning 3d human pose prior with gradient fields, 2022. 2
2022
-
[13]
See- ing is believing: body motion dominates in multisensory conversations.ACM Transactions on Graphics (TOG), 29 (4):1–9, 2010
Cathy Ennis, Rachel McDonnell, and Carol O’Sullivan. See- ing is believing: body motion dominates in multisensory conversations.ACM Transactions on Graphics (TOG), 29 (4):1–9, 2010. 1
2010
-
[14]
Conducting interaction: Patterns of behavior in focused encounters
Susan Fiksdal. Conducting interaction: Patterns of behavior in focused encounters. adam kendon. cambridge: Cambridge university press, 1990. pp. vii+ 292. 16.95 paper.Studies in Second Language Acquisition, 15(1):116–117, 1993. 8
1990
-
[15]
Poseaug: A differentiable pose augmentation framework for 3d hu- man pose estimation
Kehong Gong, Jianfeng Zhang, and Jiashi Feng. Poseaug: A differentiable pose augmentation framework for 3d hu- man pose estimation. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 8575–8584, 2021. 2
2021
-
[16]
Nonverbal communication.Annual review of psychology, 70 (2019):271–294, 2019
Judith A Hall, Terrence G Horgan, and Nora A Murphy. Nonverbal communication.Annual review of psychology, 70 (2019):271–294, 2019. 1
2019
-
[17]
Denoising Diffusion Probabilistic Models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models.CoRR, abs/2006.11239, 2020. 3, 4
work page internal anchor Pith review arXiv 2006
-
[18]
Cascaded diffusion models for high fidelity image generation
Jonathan Ho, Chitwan Saharia, William Chan, David J. Fleet, Mohammad Norouzi, and Tim Salimans. Cascaded dif- fusion models for high fidelity image generation.CoRR, abs/2106.15282, 2021. 3
-
[19]
DiffPose: Multi- hypothesis human pose estimation using diffusion models
Karl Holmquist and Bastian Wandt. DiffPose: Multi- hypothesis human pose estimation using diffusion models. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 15931–15941. IEEE. 3, 4
-
[20]
Exploiting tem- poral information for 3d human pose estimation
Mir Rayat Imtiaz Hossain and James J Little. Exploiting tem- poral information for 3d human pose estimation. InProceed- ings of the European conference on computer vision (ECCV), pages 68–84, 2018. 2
2018
-
[21]
Prodiff: Progressive fast diffusion model for high-quality text-to-speech, 2022
Rongjie Huang, Zhou Zhao, Huadai Liu, Jinglin Liu, Chenye Cui, and Yi Ren. Prodiff: Progressive fast diffusion model for high-quality text-to-speech, 2022. 3
2022
-
[22]
Back to optimization: Diffusion-based zero-shot 3d human pose estimation
Zhongyu Jiang, Zhuoran Zhou, Lei Li, Wenhao Chai, Cheng- Yen Yang, and Jenq-Neng Hwang. Back to optimization: Diffusion-based zero-shot 3d human pose estimation. In 2024 IEEE/CVF Winter Conference on Applications of Com- puter Vision (WACV), pages 6130–6140. IEEE. 2, 3
2024
-
[23]
Towards social artificial intelligence: Nonverbal social signal prediction in a triadic interaction
Hanbyul Joo, Tomas Simon, Mina Cikara, and Yaser Sheikh. Towards social artificial intelligence: Nonverbal social signal prediction in a triadic interaction. 5
-
[24]
Hanbyul Joo, Tomas Simon, Xulong Li, Hao Liu, Lei Tan, Lin Gui, Sean Banerjee, Timothy Godisart, Bart C. Nabbe, Iain A. Matthews, Takeo Kanade, Shohei Nobuhara, and Yaser Sheikh. Panoptic studio: A massively multiview sys- tem for social interaction capture.CoRR, abs/1612.03153,
-
[25]
Harold W. Kuhn. The Hungarian Method for the Assignment Problem.Naval Research Logistics Quarterly, 2(1–2):83– 97, 1955. 8
1955
-
[26]
Talking with hands 16.2 m: A large-scale dataset of synchronized body- finger motion and audio for conversational motion analy- sis and synthesis
Gilwoo Lee, Zhiwei Deng, Shugao Ma, Takaaki Shiratori, Siddhartha S Srinivasa, and Yaser Sheikh. Talking with hands 16.2 m: A large-scale dataset of synchronized body- finger motion and audio for conversational motion analy- sis and synthesis. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 763–772,
-
[27]
Hierarchical graph networks for 3d human pose esti- mation.CoRR, abs/2111.11927, 2021
Han Li, Bowen Shi, Wenrui Dai, Yabo Chen, Botao Wang, Yu Sun, Min Guo, Chenglin Li, Junni Zou, and Hongkai Xiong. Hierarchical graph networks for 3d human pose esti- mation.CoRR, abs/2111.11927, 2021. 2
-
[28]
MHFormer: Multi-hypothesis transformer for 3d human pose estimation
Wenhao Li, Hong Liu, Hao Tang, Pichao Wang, and Luc Van Gool. MHFormer: Multi-hypothesis transformer for 3d human pose estimation. pages 13147–13156. 2
-
[29]
Hourglass tokenizer for efficient transformer-based 3d human pose estimation
Wenhao Li, Mengyuan Liu, Hong Liu, Pichao Wang, Jialun Cai, and Nicu Sebe. Hourglass tokenizer for efficient transformer-based 3d human pose estimation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 604–613, 2024. 2
2024
-
[30]
Attention mechanism exploits tem- poral contexts: Real-time 3d human pose reconstruction
Ruixu Liu, Ju Shen, He Wang, Chen Chen, Sen-ching Che- ung, and Vijayan Asari. Attention mechanism exploits tem- poral contexts: Real-time 3d human pose reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), 2020. 2
2020
-
[31]
Matthew Loper, Naureen Mahmood, Javier Romero, Ger- ard Pons-Moll, and Michael J. Black. SMPL: A skinned multi-person linear model.ACM Trans. Graphics (Proc. SIGGRAPH Asia), 34(6):248:1–248:16, 2015. 2
2015
-
[32]
Decoupled weight de- cay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight de- cay regularization. InInternational Conference on Learning Representations, 2019. 5
2019
-
[33]
Body communicative cue extraction for conversational analysis
Alvaro Marcos-Ramiro, Daniel Pizarro-Perez, Marta Marron-Romera, Laurent Nguyen, and Daniel Gatica-Perez. Body communicative cue extraction for conversational analysis. In2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), pages 1–8. IEEE, 2013. 1
2013
-
[34]
A simple yet effective baseline for 3d human pose esti- mation
Julieta Martinez, Rayat Hossain, Javier Romero, and James J Little. A simple yet effective baseline for 3d human pose esti- mation. InProceedings of the IEEE international conference on computer vision, pages 2640–2649, 2017. 2
2017
-
[35]
Motion- AGFormer: Enhancing 3d human pose estimation with a transformer-GCNFormer network
Soroush Mehraban, Vida Adeli, and Babak Taati. Motion- AGFormer: Enhancing 3d human pose estimation with a transformer-GCNFormer network. In2024 IEEE/CVF Win- ter Conference on Applications of Computer Vision (WACV), pages 6905–6915. IEEE. 2
-
[36]
Mo- tionagformer: Enhancing 3d human pose estimation with a transformer-gcnformer network
Soroush Mehraban, Vida Adeli, and Babak Taati. Mo- tionagformer: Enhancing 3d human pose estimation with a transformer-gcnformer network. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 6920–6930, 2024. 1, 2
2024
-
[37]
Single-shot multi-person 3d pose estimation from monocular RGB
Dushyant Mehta, Oleksandr Sotnychenko, Franziska Mueller, Weipeng Xu, Srinath Sridhar, Gerard Pons-Moll, and Christian Theobalt. Single-shot multi-person 3d pose estimation from monocular RGB. 5, 8
-
[38]
Vnect: Real-time 3d human pose estimation with a single rgb cam- era.Acm transactions on graphics (tog), 36(4):1–14, 2017
Dushyant Mehta, Srinath Sridhar, Oleksandr Sotnychenko, Helge Rhodin, Mohammad Shafiei, Hans-Peter Seidel, Weipeng Xu, Dan Casas, and Christian Theobalt. Vnect: Real-time 3d human pose estimation with a single rgb cam- era.Acm transactions on graphics (tog), 36(4):1–14, 2017. 2
2017
-
[39]
A review of mo- tion analysis methods for human nonverbal communication computing.Image and Vision Computing, 31(6-7):421–433,
Dimitris Metaxas and Shaoting Zhang. A review of mo- tion analysis methods for human nonverbal communication computing.Image and Vision Computing, 31(6-7):421–433,
-
[40]
Camera distance-aware top-down approach for 3d multi- person pose estimation from a single RGB image
Gyeongsik Moon, Ju Yong Chang, and Kyoung Mu Lee. Camera distance-aware top-down approach for 3d multi- person pose estimation from a single RGB image. 2
-
[41]
The progress of human pose estimation: A survey and taxonomy of models applied in 2d human pose estimation.Ieee Access, 8:133330–133348, 2020
Tewodros Legesse Munea, Yalew Zelalem Jembre, Hale- fom Tekle Weldegebriel, Longbiao Chen, Chenxi Huang, and Chenhui Yang. The progress of human pose estimation: A survey and taxonomy of models applied in 2d human pose estimation.Ieee Access, 8:133330–133348, 2020. 1
2020
-
[42]
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. GLIDE: towards photorealistic image genera- tion and editing with text-guided diffusion models.CoRR, abs/2112.10741, 2021. 3
work page internal anchor Pith review arXiv 2021
-
[43]
Towards robust and smooth 3d multi-person pose estimation from monocular videos in the wild
Sungchan Park, Eunyi You, Inhoe Lee, and Joonseok Lee. Towards robust and smooth 3d multi-person pose estimation from monocular videos in the wild. In2023 IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 14726–14736. IEEE. 1, 2, 4, 5, 6
-
[44]
3d human pose estimation in video with tem- poral convolutions and semi-supervised training, 2019
Dario Pavllo, Christoph Feichtenhofer, David Grangier, and Michael Auli. 3d human pose estimation in video with tem- poral convolutions and semi-supervised training, 2019. 2
2019
-
[45]
Ktpformer: Kinematics and trajectory prior knowledge-enhanced trans- former for 3d human pose estimation
Jihua Peng, Yanghong Zhou, and PY Mok. Ktpformer: Kinematics and trajectory prior knowledge-enhanced trans- former for 3d human pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1123–1132, 2024. 2
2024
-
[46]
A dual- augmentor framework for domain generalization in 3d hu- man pose estimation
Qucheng Peng, Ce Zheng, and Chen Chen. A dual- augmentor framework for domain generalization in 3d hu- man pose estimation. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 2240–2249, 2024. 1, 2
2024
-
[47]
HSTFormer: Hierarchical spatial-temporal transformers for 3d human pose estimation
Xiaoye Qian, Youbao Tang, Ning Zhang, Mei Han, Jing Xiao, Ming-Chun Huang, and Ruei-Sung Lin. HSTFormer: Hierarchical spatial-temporal transformers for 3d human pose estimation. 2
-
[48]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. 3
-
[49]
3d human pose estimation: A review of the literature and analysis of covariates.Computer Vision and Image Understanding, 152:1–20, 2016
Nikolaos Sarafianos, Bogdan Boteanu, Bogdan Ionescu, and Ioannis A Kakadiaris. 3d human pose estimation: A review of the literature and analysis of covariates.Computer Vision and Image Understanding, 152:1–20, 2016. 2
2016
-
[50]
Diffusion-based 3d human pose estimation with multi- hypothesis aggregation
Wenkang Shan, Zhenhua Liu, Xinfeng Zhang, Zhao Wang, Kai Han, Shanshe Wang, Siwei Ma, and Wen Gao. Diffusion-based 3d human pose estimation with multi- hypothesis aggregation. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 14715– 14725. IEEE. 2, 3, 4, 5, 6, 8
-
[51]
Deep Unsupervised Learning using Nonequilibrium Thermodynamics
Jascha Sohl-Dickstein, Eric A. Weiss, Niru Mah- eswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics.CoRR, abs/1503.03585, 2015. 3
work page internal anchor Pith review arXiv 2015
-
[52]
Human body model fitting by learned gradient descent
Jie Song, Xu Chen, and Otmar Hilliges. Human body model fitting by learned gradient descent. InEuropean Conference on Computer Vision, pages 744–760. Springer, 2020. 2
2020
-
[53]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models.CoRR, abs/2010.02502, 2020. 4
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[54]
Body movement mirroring and synchrony in human–robot interac- tion.J
Darja Stoeva, Andreas Kriegler, and Margrit Gelautz. Body movement mirroring and synchrony in human–robot interac- tion.J. Hum.-Robot Interact., 13(4), 2024. 1
2024
-
[55]
VirtualPose: Learning generalizable 3d hu- man pose models from virtual data
Jiajun Su, Chunyu Wang, Xiaoxuan Ma, Wenjun Zeng, and Yizhou Wang. VirtualPose: Learning generalizable 3d hu- man pose models from virtual data. 1, 2, 5, 6
-
[56]
Yu Sun, Wu Liu, Qian Bao, Yili Fu, Tao Mei, and Michael J. Black. Putting people in their place: Monocular regression of 3d people in depth. In2022 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 13233– 13242. IEEE. 2, 5
-
[57]
Monocular, one-stage, regression of multiple 3d people,
Yu Sun, Qian Bao, Wu Liu, Yili Fu, and Tao Mei. Centerhmr: a bottom-up single-shot method for multi-person 3d mesh recovery from a single image.CoRR, abs/2008.12272, 2020. 1, 2
-
[58]
3d human pose estimation with spatio- temporal criss-cross attention
Zhenhua Tang, Zhaofan Qiu, Yanbin Hao, Richang Hong, and Ting Yao. 3d human pose estimation with spatio- temporal criss-cross attention. In2023 IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 4790–4799. IEEE. 2
-
[59]
Social diffusion: Long-term multiple hu- man motion anticipation
Julian Tanke, Linguang Zhang, Amy Zhao, Chengcheng Tang, Yujun Cai, Lezi Wang, Po-Chen Wu, Juergen Gall, and Cem Keskin. Social diffusion: Long-term multiple hu- man motion anticipation. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 9567–9577. IEEE. 5
-
[60]
Deeppose: Human pose estimation via deep neural networks
Alexander Toshev and Christian Szegedy. Deeppose: Human pose estimation via deep neural networks. InProceedings of the IEEE conference on computer vision and pattern recog- nition, pages 1653–1660, 2014. 1
2014
-
[61]
Joint estimation of human pose and conversa- tional groups from social scenes.International Journal of Computer Vision, 126(2):410–429, 2018
Jagannadan Varadarajan, Ramanathan Subramanian, Samuel Rota Bul `o, Narendra Ahuja, Oswald Lanz, and Elisa Ricci. Joint estimation of human pose and conversa- tional groups from social scenes.International Journal of Computer Vision, 126(2):410–429, 2018. 1, 8
2018
-
[62]
Black, Bodo Rosenhahn, and Gerard Pons-Moll
Timo von Marcard, Roberto Henschel, Michael J. Black, Bodo Rosenhahn, and Gerard Pons-Moll. Recovering ac- curate 3d human pose in the wild using imus and a mov- ing camera. InProceedings of the European Conference on Computer Vision (ECCV), 2018. 5
2018
-
[63]
Deep 3d human pose estimation: A review.Computer Vision and Image Under- standing, 210:103225, 2021
Jinbao Wang, Shujie Tan, Xiantong Zhen, Shuo Xu, Feng Zheng, Zhenyu He, and Ling Shao. Deep 3d human pose estimation: A review.Computer Vision and Image Under- standing, 210:103225, 2021. 1, 2
2021
-
[64]
Finepose: Fine- grained prompt-driven 3d human pose estimation via diffu- sion models
Jinglin Xu, Yijie Guo, and Yuxin Peng. Finepose: Fine- grained prompt-driven 3d human pose estimation via diffu- sion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 561–570,
-
[65]
Simpoe: Simulated character control for 3d hu- man pose estimation
Ye Yuan, Shih-En Wei, Tomas Simon, Kris Kitani, and Ja- son Saragih. Simpoe: Simulated character control for 3d hu- man pose estimation. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 7159–7169, 2021. 2
2021
-
[66]
Deep network for the in- tegrated 3d sensing of multiple people in natural images
Andrei Zanfir, Elisabeta Marinoiu, Mihai Zanfir, Alin-Ionut Popa, and Cristian Sminchisescu. Deep network for the in- tegrated 3d sensing of multiple people in natural images. In Advances in Neural Information Processing Systems. Curran Associates, Inc., 2018. 6
2018
-
[67]
Fast human pose estimation
Feng Zhang, Xiatian Zhu, and Mao Ye. Fast human pose estimation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3517–3526,
-
[68]
MixSTE: Seq2seq mixed spatio-temporal en- coder for 3d human pose estimation in video
Jinlu Zhang, Zhigang Tu, Jianyu Yang, Yujin Chen, and Jun- song Yuan. MixSTE: Seq2seq mixed spatio-temporal en- coder for 3d human pose estimation in video. 2, 3, 5
-
[69]
Multi-view emo- tional expressions dataset using 2d pose estimation.Scien- tific Data, 10:649, 2023
Mingming Zhang, Yanan Zhou, Xinye Xu, Zhiwei Ren, Yi- han Zhang, Shenglan Liu, and Wenbo Luo. Multi-view emo- tional expressions dataset using 2d pose estimation.Scien- tific Data, 10:649, 2023. 1
2023
-
[70]
Dynamic inertial poser (dynaip): Part- based motion dynamics learning for enhanced human pose estimation with sparse inertial sensors
Yu Zhang, Songpengcheng Xia, Lei Chu, Jiarui Yang, Qi Wu, and Ling Pei. Dynamic inertial poser (dynaip): Part- based motion dynamics learning for enhanced human pose estimation with sparse inertial sensors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1889–1899, 2024. 2
2024
-
[71]
Poseformerv2: Exploring frequency domain for efficient and robust 3d human pose estimation
Qitao Zhao, Ce Zheng, Mengyuan Liu, Pichao Wang, and Chen Chen. Poseformerv2: Exploring frequency domain for efficient and robust 3d human pose estimation. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8877–8886, 2023. 2
2023
-
[72]
Unleashing text-to-image diffu- sion models for visual perception
Wenliang Zhao, Yongming Rao, Zuyan Liu, Benlin Liu, Jie Zhou, and Jiwen Lu. Unleashing text-to-image diffu- sion models for visual perception. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5729–5739, 2023. 8
2023
-
[73]
SMAP: Single-shot multi- person absolute 3d pose estimation
Jianan Zhen, Qi Fang, Jiaming Sun, Wentao Liu, Wei Jiang, Hujun Bao, and Xiaowei Zhou. SMAP: Single-shot multi- person absolute 3d pose estimation. 2, 5, 6
-
[74]
3d human pose estima- tion with spatial and temporal transformers
Ce Zheng, Sijie Zhu, Matias Mendieta, Taojiannan Yang, Chen Chen, and Zhengming Ding. 3d human pose estima- tion with spatial and temporal transformers. InProceedings of the IEEE/CVF international conference on computer vi- sion, pages 11656–11665, 2021. 2
2021
-
[75]
Deep learning-based human pose estimation: A survey.ACM Computing Surveys, 56(1):1–37, 2023
Ce Zheng, Wenhan Wu, Chen Chen, Taojiannan Yang, Si- jie Zhu, Ju Shen, Nasser Kehtarnavaz, and Mubarak Shah. Deep learning-based human pose estimation: A survey.ACM Computing Surveys, 56(1):1–37, 2023. 1
2023
-
[76]
MotionBERT: A unified perspective on learning human motion representations
Wentao Zhu, Xiaoxuan Ma, Zhaoyang Liu, Libin Liu, Wayne Wu, and Yizhou Wang. MotionBERT: A unified perspective on learning human motion representations. version: 5. 2
-
[77]
Modulated graph convolutional network for 3d human pose estimation
Zhiming Zou and Wei Tang. Modulated graph convolutional network for 3d human pose estimation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11477–11487, 2021. 2
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.