Recognition: no theorem link
Training Deep Visual Networks Beyond Loss and Accuracy Through a Dynamical Systems Approach
Pith reviewed 2026-05-10 18:57 UTC · model grok-4.3
The pith
Dynamical systems measures from layer activations reveal training dynamics beyond loss and accuracy in deep visual networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
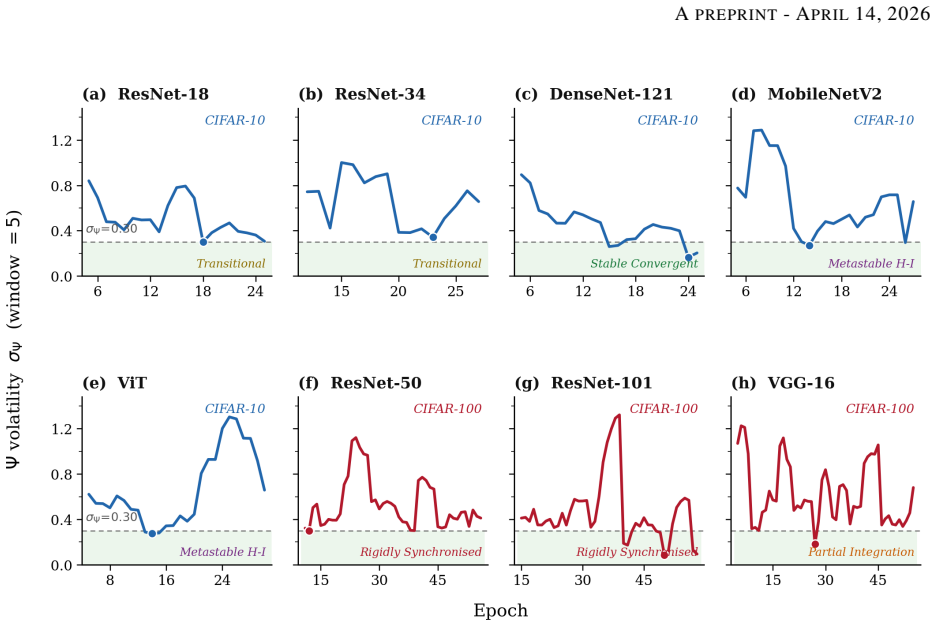
Drawing on dynamical systems ideas, we define three measures from layer activations: integration reflecting long-range coordination across layers, metastability capturing shifts between synchronized states, and a combined stability index. Applied to ResNet variants, DenseNet, MobileNetV2, VGG-16, and Vision Transformer on CIFAR-10 and CIFAR-100, the results indicate that integration separates easier from harder datasets, volatility in stability may signal convergence before accuracy plateaus, and the relationship between integration and metastability corresponds to different training behaviors.
What carries the argument
The integration score, metastability score, and dynamical stability index computed from layer activations using techniques from signal analysis.
If this is right
- The integration measure can distinguish training on easier versus more difficult datasets consistently.
- Volatility changes in the stability index may serve as an early indicator of convergence.
- The interplay between integration and metastability can characterize different styles of training behavior.
- These measures offer a complementary view to loss and accuracy for monitoring deep network optimization.
Where Pith is reading between the lines
- If validated further, these measures could guide adaptive training strategies by monitoring internal dynamics in real time.
- Extending the analysis to other domains like reinforcement learning or natural language processing might uncover similar or different patterns in how networks learn.
- Comparing these dynamical measures across more diverse architectures could help identify which design choices promote stable or metastable training behaviors.
Load-bearing premise
The newly defined integration, metastability, and stability measures from layer activations provide information about training dynamics that is distinct from and additive to loss and accuracy curves.
What would settle it
Observing no difference in integration scores between CIFAR-10 and CIFAR-100 trainings, or no predictive power of stability volatility for convergence timing in additional experiments, would falsify the usefulness of these measures.
Figures
read the original abstract
Deep visual recognition models are usually trained and evaluated using metrics such as loss and accuracy. While these measures show whether a model is improving, they reveal very little about how its internal representations change during training. This paper introduces a complementary way to study that process by examining training through the lens of dynamical systems. Drawing on ideas from signal analysis originally used to study biological neural activity, we define three measures from layer activations collected across training epochs: an integration score that reflects long-range coordination across layers, a metastability score that captures how flexibly the network shifts between more and less synchronised states, and a combined dynamical stability index. We apply this framework to nine combinations of model architecture and dataset, including several ResNet variants, DenseNet-121, MobileNetV2, VGG-16, and a pretrained Vision Transformer on CIFAR-10 and CIFAR-100. The results suggest three main patterns. First, the integration measure consistently distinguishes the easier CIFAR-10 setting from the more difficult CIFAR-100 setting. Second, changes in the volatility of the stability index may provide an early sign of convergence before accuracy fully plateaus. Third, the relationship between integration and metastability appears to reflect different styles of training behaviour. Overall, this study offers an exploratory but promising new way to understand deep visual training beyond loss and accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces three dynamical systems-inspired measures derived from layer activations—an integration score reflecting long-range coordination across layers, a metastability score capturing shifts between synchronized states, and a combined dynamical stability index—and applies them to nine architecture-dataset combinations (ResNet variants, DenseNet-121, MobileNetV2, VGG-16, and a pretrained Vision Transformer on CIFAR-10 and CIFAR-100). It reports three exploratory patterns: the integration measure distinguishes easier (CIFAR-10) from harder (CIFAR-100) settings, volatility in the stability index may signal convergence before accuracy plateaus, and the integration-metastability relationship reflects different training behaviors. The work positions these as complementary to loss and accuracy for understanding internal representation changes.
Significance. If the measures can be shown to capture dynamics independent of and additive to loss/accuracy (via correlations, mutual information, or regression ablations), the framework could offer a useful new lens for diagnosing training trajectories and comparing architectures in computer vision. The consistent patterns across multiple models and datasets are a strength, but the absence of statistical controls, error bars, or validation of non-redundancy limits the current significance to exploratory observations rather than a robust methodological advance.
major comments (3)
- [Abstract] Abstract and results: The central claim that the integration, metastability, and stability measures provide information 'beyond loss and accuracy' is load-bearing but unsupported; no Pearson/Spearman correlations, mutual information values, or ablation regressions are reported to demonstrate that the new metrics explain additional variance in convergence, generalization, or trajectory shape once loss/accuracy are controlled for.
- [Results] Results (patterns across nine combinations): The reported patterns lack error bars, statistical significance tests, or controls for multiple comparisons, and the measure definitions receive no ablation (e.g., sensitivity to window size or normalization choices in activation collection), undermining claims of consistent distinction between CIFAR-10 and CIFAR-100 or early convergence signals.
- [Methods] Methods: The integration, metastability, and stability index are defined directly from collected activations and applied to observed trajectories without reduction to fitted parameters or self-referential equations, leaving open whether they are circular or redundant with standard training curves.
minor comments (1)
- [Abstract] The abstract and conclusion could more explicitly state the exploratory nature and limitations of the current evidence base.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We appreciate the acknowledgment of the consistent patterns observed across multiple architectures and datasets. We agree that the manuscript would benefit from additional quantitative analyses to support the claims of complementarity to loss and accuracy, as well as greater statistical rigor. We address each major comment below and outline the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract and results: The central claim that the integration, metastability, and stability measures provide information 'beyond loss and accuracy' is load-bearing but unsupported; no Pearson/Spearman correlations, mutual information values, or ablation regressions are reported to demonstrate that the new metrics explain additional variance in convergence, generalization, or trajectory shape once loss/accuracy are controlled for.
Authors: We acknowledge that the abstract positions the measures as providing information beyond loss and accuracy, yet we did not include explicit correlation or regression analyses to quantify this. The observed patterns (e.g., integration distinguishing CIFAR-10 from CIFAR-100) are suggestive but observational. In the revision we will add Pearson and Spearman correlations between each dynamical measure and both loss and accuracy across all training trajectories. We will also include linear regression ablations predicting convergence timing and final accuracy using loss/accuracy alone versus augmented with the new measures, reporting the increase in explained variance (R²). revision: yes
-
Referee: [Results] Results (patterns across nine combinations): The reported patterns lack error bars, statistical significance tests, or controls for multiple comparisons, and the measure definitions receive no ablation (e.g., sensitivity to window size or normalization choices in activation collection), undermining claims of consistent distinction between CIFAR-10 and CIFAR-100 or early convergence signals.
Authors: We agree that the exploratory results would be strengthened by error bars, significance testing, and parameter sensitivity analysis. The current patterns derive from single runs per architecture–dataset pair. In the revised version we will repeat key experiments with 3–5 random seeds, report standard deviation error bars on all measures, and apply appropriate statistical tests (e.g., paired t-tests or Wilcoxon rank-sum tests) for the CIFAR-10 vs. CIFAR-100 integration differences, with correction for multiple comparisons. We will also add an ablation subsection examining sensitivity of the measures to activation window size and normalization choices. revision: yes
-
Referee: [Methods] Methods: The integration, metastability, and stability index are defined directly from collected activations and applied to observed trajectories without reduction to fitted parameters or self-referential equations, leaving open whether they are circular or redundant with standard training curves.
Authors: The measures are intentionally computed directly from activation trajectories using dynamical-systems concepts (long-range coordination for integration, state-transition flexibility for metastability) drawn from neuroscience signal-analysis literature; they are not model parameters fitted to the data. To address concerns of circularity or redundancy we will expand the Methods and Results sections with explicit side-by-side plots demonstrating that stability-index volatility precedes accuracy plateaus and is not a monotonic function of loss values. We will also add a brief discussion clarifying that the measures capture inter-layer coordination and state dynamics not encoded in scalar loss or accuracy. revision: partial
Circularity Check
No circularity: measures defined directly from activations and applied observationally
full rationale
The paper defines the integration score, metastability score, and dynamical stability index directly from layer activations collected across training epochs, drawing on signal analysis concepts but without any equations that reduce these quantities to loss, accuracy, or fitted parameters by construction. The three observed patterns (CIFAR-10 vs. CIFAR-100 distinction, volatility as early convergence signal, and integration-metastability relationships) are presented as empirical observations on real training trajectories for multiple architectures and datasets. No self-citation chains, uniqueness theorems, ansatzes smuggled via prior work, or renamings of known results are invoked as load-bearing steps in the derivation. The framework is self-contained: the measures are constructed independently of the target patterns and then applied to data, with no reduction of the reported findings to the inputs by definition.
Axiom & Free-Parameter Ledger
invented entities (3)
-
integration score
no independent evidence
-
metastability score
no independent evidence
-
dynamical stability index
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Visualizing the loss landscape of neural nets,
H. Li, Z. Xu, G. Taylor, C. Studer, and T. Goldstein, “Visualizing the loss landscape of neural nets,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 31, 2018. 11 APREPRINT- APRIL14, 2026
2018
-
[2]
Prevalence of neural collapse during the terminal phase of deep learning training,
V . Papyan, X. Y . Han, and D. L. Donoho, “Prevalence of neural collapse during the terminal phase of deep learning training,”Proceedings of the National Academy of Sciences, vol. 117, no. 40, pp. 24652–24663, 2020
2020
-
[3]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
A. Power, Y . Burda, H. Edwards, I. Babuschkin, and V . Misra, “Grokking: Generalization beyond overfitting on small algorithmic datasets,”arXiv:2201.02177, 2022
work page internal anchor Pith review arXiv 2022
-
[4]
Deep double descent: Where bigger models and more data hurt,
P. Nakkiran, G. Kaplun, Y . Bansal, T. Yang, B. Barak, and I. Sutskever, “Deep double descent: Where bigger models and more data hurt,”Journal of Statistical Mechanics, p. 124003, 2021
2021
-
[5]
Understanding deep learning (still) requires rethinking generalization,
C. Zhang, S. Bengio, M. Hardt, B. Recht, and O. Vinyals, “Understanding deep learning (still) requires rethinking generalization,”Communications of the ACM, vol. 64, no. 3, pp. 107–115, 2021
2021
-
[6]
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
J. Frankle and M. Carbin, “The lottery ticket hypothesis: Finding sparse, trainable neural networks,” arXiv:1803.03635, 2019
work page Pith review arXiv 2019
-
[7]
H. Ugail and N. Howard, “Quantifying the dynamics of consciousness using hierarchical integration, organised complexity and metastability,”arXiv:2512.10972, 2025
-
[8]
On large-batch training for deep learning: Generalization gap and sharp minima,
N. S. Keskar, D. Mudigere, J. Nocedal, M. Smelyanskiy, and P. T. P. Tang, “On large-batch training for deep learning: Generalization gap and sharp minima,” inInternational Conference on Learning Representations (ICLR), 2017
2017
-
[9]
Opening the Black Box of Deep Neural Networks via Information
R. Shwartz-Ziv and N. Tishby, “Opening the black box of deep neural networks via information,” arXiv:1703.00810, 2017
work page Pith review arXiv 2017
-
[10]
Neural collapse under MSE loss: Proximity to and dynamics on the central path,
X. Y . Han, V . Papyan, and D. L. Donoho, “Neural collapse under MSE loss: Proximity to and dynamics on the central path,” inInternational Conference on Learning Representations (ICLR), 2022
2022
-
[11]
A geometric analysis of neural collapse with unconstrained features,
Z. Zhu, T. Ding, J. Zhou, X. Li, C. You, J. Sulam, and Q. Qu, “A geometric analysis of neural collapse with unconstrained features,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 34, pp. 29820– 29834, 2021
2021
-
[12]
Multi-scale feature learning dynamics: Insights for double descent,
M. Pezeshki, A. Mitra, Y . Bengio, and G. Lajoie, “Multi-scale feature learning dynamics: Insights for double descent,” inInternational Conference on Machine Learning (ICML), vol. 162, pp. 17669–17690, 2022
2022
-
[13]
Mosaic organization of DNA nucleotides,
C.-K. Peng, S. V . Buldyrev, S. Havlin, M. Simons, H. E. Stanley, and A. L. Goldberger, “Mosaic organization of DNA nucleotides,”Physical Review E, vol. 49, no. 2, pp. 1685–1689, 1994
1994
-
[14]
Multifractal detrended fluctuation analysis of nonstationary time series,
J. W. Kantelhardt, S. A. Zschiegner, E. Koscielny-Bunde, S. Havlin, A. Bunde, and H. E. Stanley, “Multifractal detrended fluctuation analysis of nonstationary time series,”Physica A, vol. 316, pp. 87–114, 2002
2002
-
[15]
Kuramoto,Chemical Oscillations, Waves, and Turbulence, Springer Series in Synergetics, vol
Y . Kuramoto,Chemical Oscillations, Waves, and Turbulence, Springer Series in Synergetics, vol. 19. Berlin: Springer, 1984
1984
-
[16]
The metastable brain,
E. Tognoli and J. A. S. Kelso, “The metastable brain,”Neuron, vol. 81, no. 1, pp. 35–48, 2014
2014
-
[17]
Metastability demystified: The foundational past, the pragmatic present and the promising future,
F. Hancock, F. E. Rosas, A. I. Luppi, M. Zhang, P. A. M. Mediano, J. Cabral, G. Deco, M. L. Kringelbach, M. Breakspear, J. A. S. Kelso, and F. E. Turkheimer, “Metastability demystified: The foundational past, the pragmatic present and the promising future,”Nature Reviews Neuroscience, vol. 26, no. 2, pp. 82–100, 2025
2025
-
[18]
Dynamical properties and mechanisms of metastability: A perspective in neuroscience,
K. L. Rossi, R. C. Budzinski, E. S. Medeiros, B. R. R. Boaretto, L. Muller, and U. Feudel, “Dynamical properties and mechanisms of metastability: A perspective in neuroscience,”Physical Review E, vol. 111, no. 2, p. 021001, 2025
2025
-
[19]
Scale-free brain activity: Past, present, and future,
B. J. He, “Scale-free brain activity: Past, present, and future,”Trends in Cognitive Sciences, vol. 18, no. 9, pp. 480–487, 2014
2014
-
[20]
Computation at the edge of chaos: Phase transitions and emergent computation,
C. G. Langton, “Computation at the edge of chaos: Phase transitions and emergent computation,”Physica D, vol. 42, pp. 12–37, 1990
1990
-
[21]
The functional benefits of criticality in the cortex,
W. L. Shew and D. Plenz, “The functional benefits of criticality in the cortex,”The Neuroscientist, vol. 19, no. 1, pp. 88–100, 2013
2013
-
[22]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770–778, 2016
2016
-
[23]
Densely connected convolutional networks,
G. Huang, Z. Liu, L. van der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4700–4708, 2017
2017
-
[24]
MobileNetV2: Inverted residuals and linear bottlenecks,
M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “MobileNetV2: Inverted residuals and linear bottlenecks,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4510–4520, 2018. 12 APREPRINT- APRIL14, 2026
2018
-
[25]
Very deep convolutional networks for large-scale image recognition,
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in International Conference on Learning Representations (ICLR), 2015
2015
-
[26]
An image is worth 16×16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16×16 words: Transformers for image recognition at scale,” inInternational Conference on Learning Representations (ICLR), 2021
2021
-
[27]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 30, 2017
2017
-
[28]
Similarity of neural network representations revisited,
S. Kornblith, M. Norouzi, H. Lee, and G. Hinton, “Similarity of neural network representations revisited,” in International Conference on Machine Learning (ICML), vol. 97, pp. 3519–3529, 2019
2019
-
[29]
Representation learning: A review and new perspectives,
Y . Bengio, A. Courville, and P. Vincent, “Representation learning: A review and new perspectives,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 8, pp. 1798–1828, 2013
2013
-
[30]
Transfusion: Understanding transfer learning for medical imaging,
M. Raghu, C. Zhang, J. Kleinberg, and S. Bengio, “Transfusion: Understanding transfer learning for medical imaging,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 32, 2019
2019
-
[31]
Masked autoencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Dollár, and R. Girshick, “Masked autoencoders are scalable vision learners,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 16000–16009, 2022
2022
-
[32]
A stochastic approximation method,
H. Robbins and S. Monro, “A stochastic approximation method,”Annals of Mathematical Statistics, vol. 22, no. 3, pp. 400–407, 1951
1951
-
[33]
Learning multiple layers of features from tiny images,
A. Krizhevsky, “Learning multiple layers of features from tiny images,” University of Toronto, Technical Report, 2009
2009
-
[34]
Batch normalization: Accelerating deep network training by reducing internal covariate shift,
S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” inInternational Conference on Machine Learning (ICML), pp. 448–456, 2015
2015
-
[35]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” inInternational Conference on Learning Representations (ICLR), 2015
2015
-
[36]
ImageNet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “ImageNet: A large-scale hierarchical image database,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 248–255, 2009
2009
-
[37]
Deep transfer learning for visual analysis and attribution of paintings by Raphael,
H. Ugail, D. G. Stork, H. G. M. Edwards, S. C. Seward, and C. Brooke, “Deep transfer learning for visual analysis and attribution of paintings by Raphael,”Heritage Science, vol. 11, no. 1, p. 43, 2023
2023
-
[38]
Evaluation of latent diffusion enhanced face recognition under forensic image degradations,
H. Ugail, H. M. Alawar, A. A. Zehi, A. M. Alkendi, and I. L. Jaleel, “Evaluation of latent diffusion enhanced face recognition under forensic image degradations,”Discover Computing, vol. 29, p. 193, 2026
2026
-
[39]
Deep face recognition using imperfect facial data,
A. Elmahmudi and H. Ugail, “Deep face recognition using imperfect facial data,”Future Generation Computer Systems, vol. 99, pp. 213–225, 2019
2019
-
[40]
Is facial beauty in the eyes? A multi-method approach to interpreting facial beauty prediction in machine learning models,
A. A. Ibrahim, N. H. Ugail, and H. Ugail, “Is facial beauty in the eyes? A multi-method approach to interpreting facial beauty prediction in machine learning models,”Discover Artificial Intelligence, vol. 5, p. 16, 2025. 13
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.