Recognition: unknown
PAS: Estimating the target accuracy before domain adaptation
Pith reviewed 2026-05-10 17:37 UTC · model grok-4.3
The pith
PAS estimates target accuracy after domain adaptation using only pre-trained feature embeddings from source and target data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
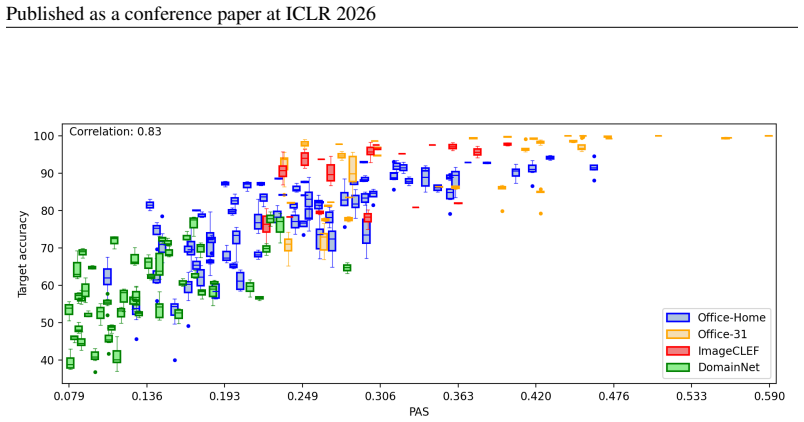
PAS is a score that assesses source-target compatibility from pre-trained feature embeddings and correlates strongly with the actual target accuracy obtained after domain adaptation, allowing a framework to identify the most suitable pre-trained model and source domain among multiple candidates without performing adaptation or accessing target labels.
What carries the argument
PAS score, which quantifies compatibility between source and target using pre-trained feature embeddings to predict post-adaptation accuracy.
If this is right
- The source and pre-trained model with the highest PAS score will produce the best target accuracy after adaptation.
- The selection framework avoids running adaptation for every candidate combination.
- PAS maintains strong correlation with target accuracy across standard image classification benchmarks.
- Using PAS reduces overall computational cost while still achieving higher final performance than random or heuristic selection.
Where Pith is reading between the lines
- PAS could be applied early to decide whether any adaptation is worthwhile for a given target before committing resources.
- The embedding-based compatibility idea might extend to other transfer settings such as object detection where source selection is also costly.
- Pre-training pipelines could be optimized by maximizing expected PAS against common target distributions.
Load-bearing premise
Compatibility assessed solely from pre-trained feature embeddings on source and target data accurately predicts post-adaptation target accuracy without needing to run the adaptation or access target labels.
What would settle it
Select several source-model pairs for a given target dataset, compute PAS for each, run the actual domain adaptation on all pairs, and check whether the pair with the highest PAS score yields the highest measured target accuracy on held-out labels.
Figures





read the original abstract
The goal of domain adaptation is to make predictions for unlabeled samples from a target domain with the help of labeled samples from a different but related source domain. The performance of domain adaptation methods is highly influenced by the choice of source domain and pre-trained feature extractor. However, the selection of source data and pre-trained model is not trivial due to the absence of a labeled validation set for the target domain and the large number of available pre-trained models. In this work, we propose PAS, a novel score designed to estimate the transferability of a source domain set and a pre-trained feature extractor to a target classification task before actually performing domain adaptation. PAS leverages the generalization power of pre-trained models and assesses source-target compatibility based on the pre-trained feature embeddings. We integrate PAS into a framework that indicates the most relevant pre-trained model and source domain among multiple candidates, thus improving target accuracy while reducing the computational overhead. Extensive experiments on image classification benchmarks demonstrate that PAS correlates strongly with actual target accuracy and consistently guides the selection of the best-performing pre-trained model and source domain for adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PAS, a score to estimate target-domain accuracy in unsupervised domain adaptation before running adaptation. PAS is computed from source and target embeddings produced by a frozen pre-trained feature extractor and is used to rank candidate pre-trained models and source domains. The authors claim that PAS exhibits strong correlation with post-adaptation target accuracy and reliably selects the best-performing combination, thereby reducing the need to execute multiple adaptation runs. Experiments on standard image-classification DA benchmarks are reported to support the correlation and selection claims.
Significance. If the predictive link holds, PAS would offer a practical, low-cost method for model and source selection in DA pipelines where many pre-trained backbones and source datasets are available. This addresses a real engineering bottleneck and could be adopted in large-scale DA workflows. The work also contributes an explicit compatibility metric grounded in pre-trained embeddings, which may stimulate further research on transferability estimation.
major comments (2)
- [Experiments section] Experiments section (correlation tables): the reported strong correlation between PAS and post-adaptation accuracy is presented without an accompanying ablation that measures the magnitude of embedding-space shift induced by the adaptation step itself (e.g., Procrustes distance or CKA between pre- and post-adaptation features). Because PAS is defined exclusively on the frozen pre-adaptation embeddings, any substantial geometry change during adaptation directly threatens the validity of the predictive claim; this analysis is load-bearing for the central assertion.
- [Section 3] Section 3 (PAS definition): the compatibility score is constructed from source-target embedding statistics, yet the manuscript provides no derivation or bound showing why this statistic remains monotonic with accuracy after the feature extractor is updated by the chosen adaptation algorithm. The absence of such a link leaves the method empirically driven and vulnerable to the circularity concern that the same adaptation outcomes used to validate PAS may implicitly influence the embedding choices.
minor comments (2)
- [Section 3] Notation for the PAS formula is introduced without an explicit equation number; subsequent references to “the PAS score” become ambiguous when multiple variants are compared.
- [Figure 2] Figure captions for the selection-framework diagrams do not list the exact adaptation algorithms and hyper-parameters used in the reported runs, making reproducibility difficult.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We address each major comment point by point below, indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Experiments section] Experiments section (correlation tables): the reported strong correlation between PAS and post-adaptation accuracy is presented without an accompanying ablation that measures the magnitude of embedding-space shift induced by the adaptation step itself (e.g., Procrustes distance or CKA between pre- and post-adaptation features). Because PAS is defined exclusively on the frozen pre-adaptation embeddings, any substantial geometry change during adaptation directly threatens the validity of the predictive claim; this analysis is load-bearing for the central assertion.
Authors: We agree that an analysis of embedding-space shifts is important for validating the predictive power of PAS. In the revised manuscript, we will add a new ablation subsection that computes Procrustes distance and CKA between pre-adaptation and post-adaptation feature embeddings across the DA methods and benchmarks used. This will quantify the geometric changes and support the claim that pre-adaptation embeddings remain sufficiently representative. revision: yes
-
Referee: [Section 3] Section 3 (PAS definition): the compatibility score is constructed from source-target embedding statistics, yet the manuscript provides no derivation or bound showing why this statistic remains monotonic with accuracy after the feature extractor is updated by the chosen adaptation algorithm. The absence of such a link leaves the method empirically driven and vulnerable to the circularity concern that the same adaptation outcomes used to validate PAS may implicitly influence the embedding choices.
Authors: We acknowledge that PAS is an empirical measure without a formal derivation or bound establishing monotonicity after feature updates. The score is motivated by the transferability of pre-trained representations, and its utility is demonstrated through extensive empirical correlations rather than theory. PAS is computed exclusively on frozen pre-adaptation embeddings, independent of subsequent adaptation steps, which avoids direct circularity in validation. We will expand Section 3 with additional discussion of the empirical motivation, design choices, and limitations. revision: partial
- Providing a rigorous theoretical derivation or bound guaranteeing monotonicity of PAS with post-adaptation accuracy under general adaptation algorithms.
Circularity Check
No significant circularity: PAS is defined on pre-trained embeddings and validated empirically against post-adaptation accuracy
full rationale
The paper defines PAS as a compatibility score computed from frozen pre-trained feature embeddings on source and target data, then integrates it into a selection framework and reports empirical correlations with actual target accuracy after domain adaptation on image classification benchmarks. No equation or claim reduces the predicted accuracy to the PAS inputs by construction, no parameter is fitted on the target outcomes and then renamed as a prediction, and no load-bearing step relies on self-citation chains or imported uniqueness theorems. The validation experiments are external to the definition of PAS, so the derivation chain remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained models possess generalization power that can be assessed via their feature embeddings for source-target compatibility
invented entities (1)
-
PAS score
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Universal domain adaptation from foundation models: A baseline study
Bin Deng and Kui Jia. Universal domain adaptation from foundation models: A baseline study. arXiv preprint arXiv:2305.11092,
-
[2]
Concept decompositions for large sparse text data using clustering.Machine learning, 42(1):143–175,
10 Published as a conference paper at ICLR 2026 Inderjit S Dhillon and Dharmendra S Modha. Concept decompositions for large sparse text data using clustering.Machine learning, 42(1):143–175,
2026
-
[3]
Domain-adversarial training of neural net- works.The journal of machine learning research, 17(1):2096–2030,
Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, Franc ¸ois Laviolette, Mario Marchand, and Victor Lempitsky. Domain-adversarial training of neural net- works.The journal of machine learning research, 17(1):2096–2030,
2096
-
[4]
Minimum class confusion for versatile domain adaptation
Ying Jin, Ximei Wang, Mingsheng Long, and Jianmin Wang. Minimum class confusion for versatile domain adaptation. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXI 16, pp. 464–480. Springer,
2020
-
[5]
Trans- ferability estimation using bhattacharyya class separability
11 Published as a conference paper at ICLR 2026 Michal P´andy, Andrea Agostinelli, Jasper Uijlings, Vittorio Ferrari, and Thomas Mensink. Trans- ferability estimation using bhattacharyya class separability. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9172–9182,
2026
-
[6]
Xingchao Peng, Ben Usman, Kuniaki Saito, Neela Kaushik, Judy Hoffman, and Kate Saenko. Syn2real: A new benchmark forsynthetic-to-real visual domain adaptation.arXiv preprint arXiv:1806.09755,
-
[7]
Adapting visual category models to new domains
Kate Saenko, Brian Kulis, Mario Fritz, and Trevor Darrell. Adapting visual category models to new domains. InComputer vision–ECCV 2010: 11th European conference on computer vision, Heraklion, Crete, Greece, September 5-11, 2010, proceedings, part iV 11, pp. 213–226. Springer,
2010
-
[8]
Deep coral: Correlation alignment for deep domain adaptation
Baochen Sun and Kate Saenko. Deep coral: Correlation alignment for deep domain adaptation. In Computer vision–ECCV 2016 workshops: Amsterdam, the Netherlands, October 8-10 and 15-16, 2016, proceedings, part III 14, pp. 443–450. Springer,
2016
-
[9]
Erm++: An improved baseline for domain generalization.arXiv preprint arXiv:2304.01973,
Piotr Teterwak, Kuniaki Saito, Theodoros Tsiligkaridis, Kate Saenko, and Bryan A Plummer. Erm++: An improved baseline for domain generalization.arXiv preprint arXiv:2304.01973,
-
[10]
Deep Domain Confusion: Maximizing for Domain Invariance
Eric Tzeng, Judy Hoffman, Ning Zhang, Kate Saenko, and Trevor Darrell. Deep domain confusion: Maximizing for domain invariance.arXiv preprint arXiv:1412.3474,
-
[11]
Deep hashing network for unsupervised domain adaptation
12 Published as a conference paper at ICLR 2026 Hemanth Venkateswara, Jose Eusebio, Shayok Chakraborty, and Sethuraman Panchanathan. Deep hashing network for unsupervised domain adaptation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5018–5027,
2026
-
[12]
Many images contain more than one object
domain of theImageCLEF benchmark. Many images contain more than one object. The sample may be very similar to a class present in the image. However, the true class refers to another object also contained in the image. In such cases, thePASvalue is high, but the accuracy is low. 13 Published as a conference paper at ICLR 2026 Table 6: Target accuracy of do...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.