Recognition: unknown
Automating Structural Analysis Across Multiple Software Platforms Using Large Language Models
Pith reviewed 2026-05-10 16:33 UTC · model grok-4.3
The pith
Large language models with a two-stage multi-agent architecture can automate frame structural analysis across ETABS, SAP2000, and OpenSees with over 90 percent accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
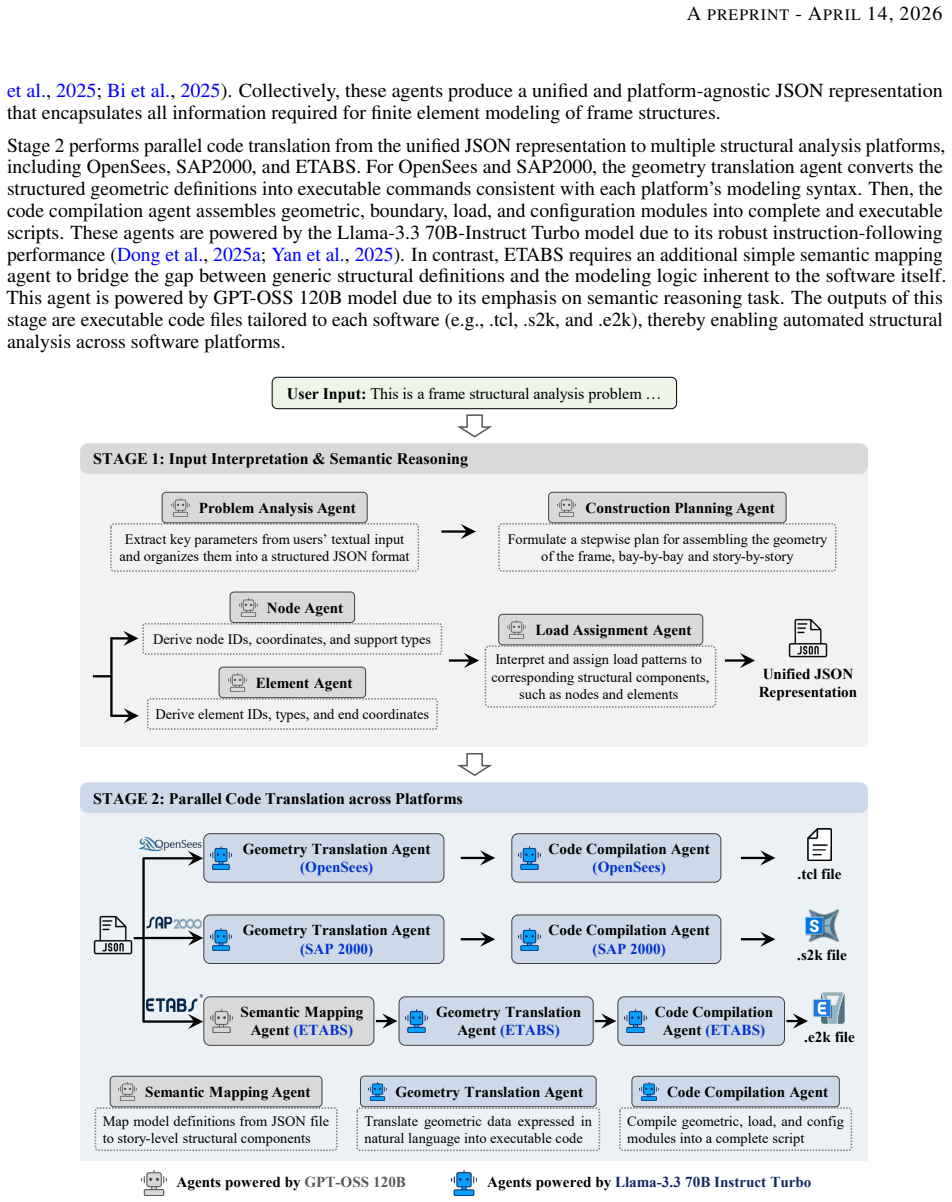
The central claim is that a two-stage multi-agent LLM architecture enables reliable automation of frame structural analysis across three distinct platforms. Stage 1 agents collaborate to interpret user text and produce a unified JSON representation containing all geometric, material, boundary, and load data needed for finite-element modeling. Stage 2 agents then convert this JSON, in parallel, into executable scripts tailored to ETABS, SAP2000, and OpenSees by following each platform's syntax rules and modeling workflow. Evaluation on twenty representative frame problems across ten repeated trials yields consistent accuracy exceeding 90 percent on every platform.
What carries the argument
The two-stage multi-agent architecture: Stage 1 agents perform collaborative structured reasoning to extract and compile modeling information into a unified JSON file, while Stage 2 agents translate that file in parallel into platform-specific executable scripts.
If this is right
- Engineers can generate correct analysis models for different platforms from a single natural-language description.
- The workflow removes the need to learn and write separate scripts for each finite-element tool.
- Repeated high accuracy on standard frame problems indicates the system can be deployed for routine modeling tasks.
- Companies using mixed software environments can adopt one LLM-assisted workflow instead of maintaining separate processes.
Where Pith is reading between the lines
- The same two-stage pattern could be tested on nonlinear or dynamic analysis problems once the basic frame capability is established.
- Connecting the JSON intermediate representation to parametric design tools might allow automatic iteration over geometry or load variations.
- Performance on incomplete or noisy real-project text would reveal whether additional clarification agents or external data lookup steps are required.
Load-bearing premise
The assumption that LLM agents can reliably extract complete and accurate geometric, material, boundary, and load information from arbitrary user text and translate it without syntax or modeling errors for real-world project inputs.
What would settle it
Running the system on frame descriptions drawn from actual engineering projects that contain ambiguous wording, omitted details, or non-standard elements and checking whether the generated scripts produce correct models or fail with errors.
Figures












read the original abstract
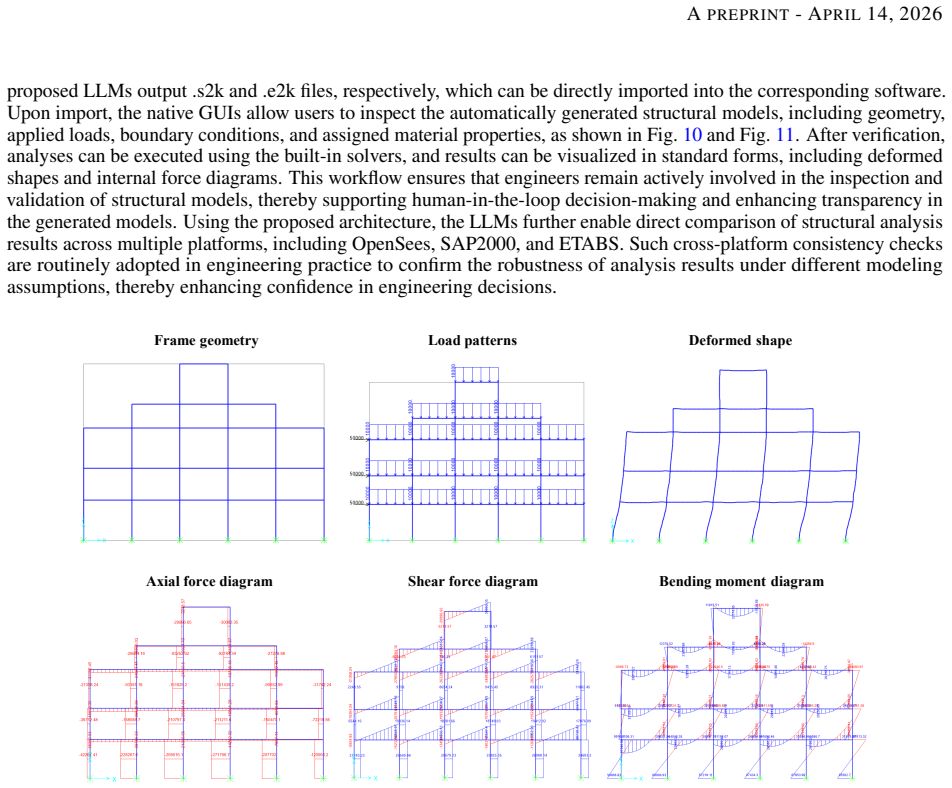
Recent advances in large language models (LLMs) have shown the promise to significantly accelerate the workflow by automating structural modeling and analysis. However, existing studies primarily focus on enabling LLMs to operate a single structural analysis software platform. In practice, structural engineers often rely on multiple finite element analysis (FEA) tools, such as ETABS, SAP2000, and OpenSees, depending on project needs, user preferences, and company constraints. This limitation restricts the practical deployment of LLM-assisted engineering workflows. To address this gap, this study develops LLMs capable of automating frame structural analysis across multiple software platforms. The LLMs adopt a two-stage multi-agent architecture. In Stage 1, a cohort of agents collaboratively interpret user input and perform structured reasoning to infer geometric, material, boundary, and load information required for finite element modeling. The outputs of these agents are compiled into a unified JSON representation. In Stage 2, code translation agents operate in parallel to convert the JSON file into executable scripts across multiple structural analysis platforms. Each agent is prompted with the syntax rules and modeling workflows of its target software. The LLMs are evaluated using 20 representative frame problems across three widely used platforms: ETABS, SAP2000, and OpenSees. Results from ten repeated trials demonstrate consistently reliable performance, achieving accuracy exceeding 90% across all cases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a two-stage multi-agent LLM architecture to automate frame structural analysis across ETABS, SAP2000, and OpenSees. Stage 1 employs collaborative agents to interpret user text and compile geometric, material, boundary, and load data into a unified JSON representation. Stage 2 uses parallel code-translation agents, each prompted with target-platform syntax, to generate executable scripts from the JSON. The system is evaluated on 20 representative frame problems using ten repeated trials per case, with the abstract reporting accuracy exceeding 90% across all platforms.
Significance. If the accuracy metric proves to be a well-defined measure of modeling fidelity (including cross-platform result equivalence within engineering tolerances) and the approach generalizes beyond the tested cases, the work could meaningfully advance practical multi-platform automation in structural engineering by reducing reliance on manual scripting. The unified JSON intermediate representation and use of repeated trials provide a reproducible empirical foundation that strengthens the reported performance claims.
major comments (2)
- [Abstract] Abstract: The headline claim of 'consistently reliable performance, achieving accuracy exceeding 90%' lacks any definition of the accuracy metric. It is unclear whether accuracy refers to syntax-valid script generation, complete and correct extraction of all model parameters from arbitrary text, or equivalence of downstream analysis outputs (e.g., nodal displacements or member forces within tolerance) across platforms. This definition is load-bearing for the central claim of practical automation.
- [Evaluation] Evaluation description: The tests are confined to 20 'representative' frame problems with no reported selection criteria, coverage of input variability (incomplete descriptions, ambiguous phrasing, non-standard units), quantitative error breakdown by failure mode, or verification that generated models produce equivalent engineering results across ETABS/SAP2000/OpenSees. Without these, the generalization to 'real-world project inputs' does not follow from the reported trials.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the scope and limitations of our work. Below, we provide point-by-point responses to the major comments and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim of 'consistently reliable performance, achieving accuracy exceeding 90%' lacks any definition of the accuracy metric. It is unclear whether accuracy refers to syntax-valid script generation, complete and correct extraction of all model parameters from arbitrary text, or equivalence of downstream analysis outputs (e.g., nodal displacements or member forces within tolerance) across platforms. This definition is load-bearing for the central claim of practical automation.
Authors: We agree that a clear definition of the accuracy metric is essential in the abstract. In our evaluation, accuracy is measured as the success rate across ten trials per problem, where success is determined by the generated script being syntactically correct, executable in the target software, and producing a model that accurately reflects all specified geometric, material, boundary, and load parameters from the input description. This was verified through code inspection and simulation runs. We did not extend to comparing analysis results like displacements across platforms in this study. We will revise the abstract to explicitly state this definition and the scope of the verification performed. revision: yes
-
Referee: [Evaluation] Evaluation description: The tests are confined to 20 'representative' frame problems with no reported selection criteria, coverage of input variability (incomplete descriptions, ambiguous phrasing, non-standard units), quantitative error breakdown by failure mode, or verification that generated models produce equivalent engineering results across ETABS/SAP2000/OpenSees. Without these, the generalization to 'real-world project inputs' does not follow from the reported trials.
Authors: The 20 problems were chosen as representative examples covering simple to moderately complex frame structures with varying numbers of bays and stories, as described in the evaluation section. We acknowledge the lack of explicit selection criteria and coverage of input variabilities such as ambiguous phrasing or non-standard units in the current manuscript. We will add a detailed description of the problem selection process, include examples of input variability tested, and provide a quantitative breakdown of error types observed in the failed trials. Regarding cross-platform result equivalence, our current focus was on the correctness of the modeling process rather than post-analysis outputs; we will add this as a noted limitation and suggest it for future extensions. revision: partial
Circularity Check
No circularity; empirical evaluation on independent tests
full rationale
The paper presents a procedural description of a two-stage multi-agent LLM system for cross-platform structural modeling, followed by direct empirical testing on 20 representative frame problems with repeated trials and reported accuracy rates. No equations, fitted parameters, predictions derived from inputs, self-definitional constructs, or load-bearing self-citations appear in the derivation or evaluation chain. Results are measured against external test cases rather than reducing to the method's own definitions or prior outputs by construction, making the central claims self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents can accurately infer complete structural model parameters from natural-language user input
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
“gpt-oss-120b & gpt-oss-20b model card.”arXiv preprint arXiv:2508.10925. ASDEA Software Technology
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Version: 4.1.0 (accessed 2026-01-19)
“STKO: Scientific toolkit for opensees, <https://www.stko.net/>. Version: 4.1.0 (accessed 2026-01-19). Bai, Y ., Tu, S., Zhang, J., Peng, H., Wang, X., Lv, X., Cao, S., Xu, J., Hou, L., Dong, Y ., et al
2026
-
[3]
“Is gpt-oss all you need? benchmarking large language models for financial intelligence and the surprising efficiency paradox.”arXiv preprint arXiv:2512.14717. Chen, G., Alsharef, A., Ovid, A., Albert, A., and Jaselskis, E
-
[4]
Evaluating long-context reasoning in llm-based webagents.arXiv preprint arXiv:2512.04307,
“Evaluating long-context reasoning in llm-based webagents.”arXiv preprint arXiv:2512.04307. Computers and Structures, Inc. 2025a.ETABS: Integrated Building Design Software. Computers and Structures, Inc., Walnut Creek, CA.https://www.csiamerica.com/products/etabs. Computers and Structures, Inc. 2025b.SAP2000: Integrated Software for Structural Analysis an...
-
[5]
Bimgent: Towards autonomous building modeling via computer-use agents
“Bimgent: Towards autonomous building modeling via computer-use agents.”arXiv preprint arXiv:2506.07217. Dong, J., Zhang, Y ., Liu, Y ., Zhong, Z., Wei, T., Zhang, C., and Qiu, H. 2025a. “Revisiting the reliability of language models in instruction-following.”arXiv preprint arXiv:2512.14754. Dong, Y ., Jiang, X., Qian, J., Wang, T., Zhang, K., Jin, Z., an...
-
[6]
“A novel multi-agent architecture to reduce hallucinations of large language models in multi-step structural modeling.”arXiv preprint arXiv:2603.07728. Geng, Z., Liu, J., Cao, R., Cheng, L., Wang, H., and Cheng, M
-
[7]
A lightweight large language model-based multi-agent system for 2d frame structural analysis
“A lightweight large language model-based multi-agent system for 2d frame structural analysis.”arXiv preprint arXiv:2510.05414. 14 APREPRINT- APRIL14, 2026 Google DeepMind
-
[8]
Accessed: 2026-01-06
“Gemini 3 pro model card. Accessed: 2026-01-06. Jiang, J., Wang, F., Shen, J., Kim, S., and Kim, S
2026
-
[9]
A Survey on Large Language Models for Code Generation
“A survey on large language models for code generation.” arXiv preprint arXiv:2406.00515. Jiang, Y ., Wang, J., Shen, X., and Dai, K
work page internal anchor Pith review arXiv
-
[10]
“The framework and implementation of using large language models to answer questions about building codes and standards.”Journal of Computing in Civil Engineering, 39 (4): 05025004. Liang, H., Kalaleh, M. T., and Mei, Q. 2025a. “Integrating large language models for automated structural analysis.” arXiv preprint arXiv:2504.09754. Liang, H., Zhou, Y ., Kal...
-
[11]
Longreason: A synthetic long-context reasoning benchmark via context expansion
“Longreason: A synthetic long-context reasoning benchmark via context expansion.”arXiv preprint arXiv:2501.15089. Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. 2024a. “Deepseek-v3 technical report.”arXiv preprint arXiv:2412.19437. Liu, J., Geng, Z., Cao, R., Cheng, L., Bocchini, P., and Cheng, M
-
[12]
Toolace: Winning the points of llm function calling.arXiv preprint arXiv:2409.00920, 2024
“A large language model-empowered agent for reliable and robust structural analysis.”Structure and Infrastructure Engineering, 1–16. Liu, W., Huang, X., Zeng, X., Hao, X., Yu, S., Li, D., Wang, S., Gan, W., Liu, Z., Yu, Y ., et al. 2024b. “Toolace: Winning the points of llm function calling.”arXiv preprint arXiv:2409.00920. Lu, J., Holleis, T., Zhang, Y ....
-
[13]
Toolsandbox: A stateful, conversational, interactive evaluation benchmark for llm tool use capabilities
“Toolsandbox: A stateful, conversational, interactive evaluation benchmark for llm tool use capabilities.”Findings of the Association for Computational Linguistics: NAACL 2025, 1160–1183. McKenna, F
2025
-
[14]
Accessed: 2026-01-06
“Update to gpt-5 system card: Gpt-5.2. Accessed: 2026-01-06. Pu, H., Yang, X., Li, J., and Guo, R
2026
-
[15]
Llm with tools: A survey.arXiv preprint arXiv:2409.18807, 2024
“Llm with tools: A survey.”arXiv preprint arXiv:2409.18807. Wan, Q., Wang, Z., Zhou, J., Wang, W., Geng, Z., Liu, J., Cao, R., Cheng, M., and Cheng, L
-
[16]
Som-1k: A thousand-problem benchmark dataset for strength of materials
“Som-1k: A thousand-problem benchmark dataset for strength of materials.”arXiv preprint arXiv:2509.21079. Xia, Z., Zhong, B., Zhang, S., Zhao, T., and Skibniewski, M. J
-
[17]
“Codeif: Benchmarking the instruction-following capabilities of large language models for code generation.”arXiv preprint arXiv:2502.19166. Zhang, Y ., Wei, S., Huang, Y ., Su, Y ., Lu, S., Jiang, K., and Li, H
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.