Simulating Organized Group Behavior: New Framework, Benchmark, and Analysis
Pith reviewed 2026-05-10 16:40 UTC · model grok-4.3
The pith
A structured analytical framework builds traceable behavioral models from group decision events and predicts future choices more accurately than summarization or retrieval baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
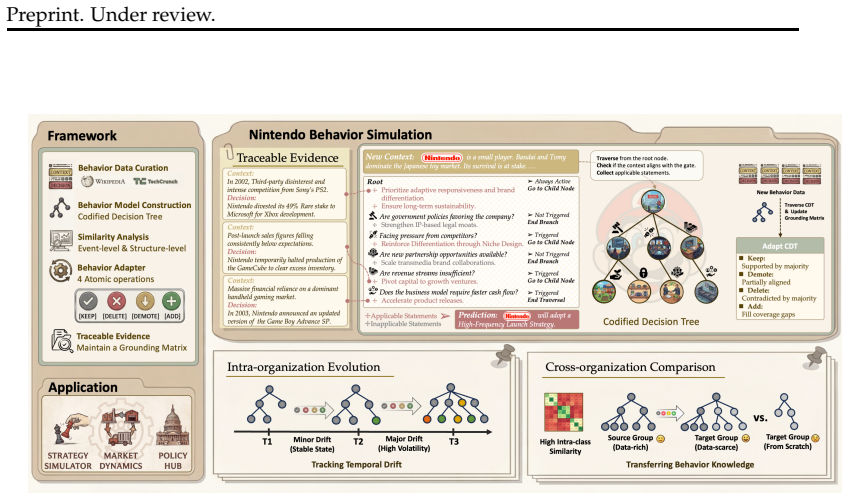
Converting collective decision-making events into an interpretable, adaptive, and traceable behavioral model, together with a time-aware adapter for evolution and group-aware transfer, produces stronger prediction of group decisions than summarization- and retrieval-based baselines; the adapter captures temporal behavioral drift and the similarity structure enables transfer to data-scarce groups.
What carries the argument
The structured analytical framework that converts decision events into a behavioral model with traceable evidence nodes and an adapter mechanism for time-aware evolution plus cross-group transfer.
If this is right
- The time-aware adapter captures temporal drift in group behavior and improves prediction accuracy over static models.
- Cross-group similarity patterns enable effective knowledge transfer to organizations with fewer recorded decisions.
- Traceable evidence nodes link each rule in the behavioral model to specific past events, supporting interpretability.
- The end-to-end protocol using consistency, initiative, scope, magnitude, and horizon provides a structured way to score simulated group actions.
Where Pith is reading between the lines
- The same event-to-model conversion could be tested on live market events to check whether simulated competitor moves align with subsequent real actions.
- Extending the framework to non-corporate groups such as regulatory bodies or activist networks would test whether the temporal and similarity mechanisms generalize.
- Replacing the source documents with internal company logs or meeting transcripts might reveal whether the performance gain depends on public narrative framing.
Load-bearing premise
Wikipedia and TechCrunch entries accurately and comprehensively represent the internal decision processes of the 44 groups, and the five criteria adequately measure the quality of simulated behavior.
What would settle it
Gather actual decisions made by the same 44 groups after the data collection cutoff and test whether the framework's outputs match those decisions more closely than baseline outputs on the five criteria.
Figures































read the original abstract
Simulating how organized groups (e.g., corporations) make decisions (e.g., responding to a competitor's move) is essential for understanding real-world dynamics and could benefit relevant applications (e.g., market prediction). In this paper, we formalize this problem as a concrete research platform for group behavior understanding, providing: (1) a task definition with benchmark and evaluation criteria, (2) a structured analytical framework with a corresponding algorithm, and (3) detailed temporal and cross-group analysis. Specifically, we propose Organized Group Behavior Simulation, a task that models organized groups as collective entities from a practical perspective: given a group facing a particular situation (e.g., AI Boom), predict the decision it would take. To support this task, we present GROVE (GRoup Organizational BehaVior Evaluation), a benchmark covering 44 entities with 8,052 real-world context-decision pairs collected from Wikipedia and TechCrunch across 9 domains, with an end-to-end evaluation protocol assessing consistency, initiative, scope, magnitude, and horizon. Beyond straightforward prompting pipelines, we propose a structured analytical framework that converts collective decision-making events into an interpretable, adaptive, and traceable behavioral model, achieving stronger performance than summarization- and retrieval-based baselines. It further introduces an adapter mechanism for time-aware evolution and group-aware transfer, and traceable evidence nodes grounding each decision rule in originating historical events. Our analysis reveals temporal behavioral drift within individual groups, which the time-aware adapter effectively captures for stronger prediction, and structured cross-group similarity that enables knowledge transfer for data-scarce organizations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes the Organized Group Behavior Simulation task for modeling how groups (e.g., corporations) make decisions in response to situations. It introduces the GROVE benchmark with 8,052 context-decision pairs from 44 entities across 9 domains, extracted from Wikipedia and TechCrunch articles, along with an end-to-end evaluation protocol using five criteria (consistency, initiative, scope, magnitude, horizon). The authors propose a structured analytical framework that converts decision events into an interpretable behavioral model with a time-aware adapter for capturing drift and enabling group-aware transfer, plus traceable evidence nodes; this framework is reported to outperform summarization- and retrieval-based baselines, with supporting temporal and cross-group analysis.
Significance. If the central claims hold, the work provides a new concrete platform and benchmark for studying collective decision-making, which could support applications such as market prediction. The structured framework's emphasis on interpretability, traceability, and adaptation to temporal drift and cross-group transfer represents a substantive contribution beyond simple prompting. The introduction of a sizable benchmark and the empirical analysis of behavioral patterns are strengths that could enable future research, provided the proxy data faithfully reflects real processes.
major comments (2)
- [GROVE benchmark construction] Benchmark construction (GROVE dataset section): The 8,052 context-decision pairs are extracted solely from secondary Wikipedia and TechCrunch sources without described cross-validation against primary documents (e.g., board minutes or internal records) or expert annotation. Because the central claim of stronger performance and effective drift/transfer capture rests on these pairs accurately representing collective decision processes, the absence of validation is load-bearing and risks the results being artifacts of post-hoc public narratives rather than internal group behavior.
- [Evaluation and results] Evaluation protocol: The abstract and described framework claim stronger performance than baselines on the five criteria, yet no quantitative results, baseline implementation details, error analysis, or statistical significance tests are referenced in the provided summary. This prevents assessment of whether the structured framework's gains are robust or merely reflect the proxy data characteristics.
minor comments (2)
- [Evaluation criteria] Clarify how the five evaluation criteria are operationalized as automated or human judgments, including any inter-annotator agreement metrics, to strengthen reproducibility.
- [Structured analytical framework] The description of the time-aware adapter and traceable evidence nodes would benefit from a concrete algorithmic pseudocode or diagram in the methods section to make the framework's implementation more transparent.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our work. We address each major comment below with clarifications from the full manuscript and indicate where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: Benchmark construction (GROVE dataset section): The 8,052 context-decision pairs are extracted solely from secondary Wikipedia and TechCrunch sources without described cross-validation against primary documents (e.g., board minutes or internal records) or expert annotation. Because the central claim of stronger performance and effective drift/transfer capture rests on these pairs accurately representing collective decision processes, the absence of validation is load-bearing and risks the results being artifacts of post-hoc public narratives rather than internal group behavior.
Authors: We acknowledge the referee's concern regarding data provenance and validation. The GROVE benchmark is deliberately built from publicly available secondary sources because the task definition centers on simulating observable group decisions from external contexts, which aligns with practical applications such as market prediction. Wikipedia and TechCrunch entries aggregate documented events and announcements for the selected entities. However, we agree that the manuscript would benefit from explicit discussion of this choice. In revision, we will expand the dataset section to add: (1) rationale for secondary sources as proxies for public-facing behavior, (2) clear limitations on the absence of primary internal records or expert annotation, and (3) suggestions for future validation studies. Primary cross-validation is not feasible here as we lack access to proprietary board documents for the 44 entities. This addition will provide better context without altering the reported results. revision: partial
-
Referee: Evaluation protocol: The abstract and described framework claim stronger performance than baselines on the five criteria, yet no quantitative results, baseline implementation details, error analysis, or statistical significance tests are referenced in the provided summary. This prevents assessment of whether the structured framework's gains are robust or merely reflect the proxy data characteristics.
Authors: The referee's summary appears to reference only an abbreviated version of the submission (e.g., the abstract). The full manuscript contains a complete experimental section with quantitative results, including tables that report performance of the structured framework against summarization- and retrieval-based baselines on all five criteria. Baseline implementation details, including prompting templates and retrieval setups, are specified in the methods section. Error analysis categorizing model outputs and statistical significance testing via paired comparisons are included in the results and analysis sections. We will revise the abstract and introduction to more explicitly reference these elements and their locations to prevent similar issues in future reviews. revision: no
Circularity Check
No significant circularity detected
full rationale
The paper introduces a new benchmark (GROVE) constructed from external sources (Wikipedia/TechCrunch) and a new structured analytical framework with time-aware adapters and traceable nodes. Performance is reported via comparison to independent summarization- and retrieval-based baselines on the five evaluation criteria. No equations, self-citations, or ansatzes are shown to reduce the central claims to fitted parameters or prior self-referential definitions by construction. The derivation chain remains self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Organized groups can be usefully modeled as collective entities whose decisions can be predicted from public historical context-decision pairs.
Reference graph
Works this paper leans on
-
[1]
Curran Associates Inc. ISBN 9781713829546. James G March. Exploration and exploitation in organizational learning.Organization science, 2(1): 71–87, 1991. James G March and Herbert A Simon.Organizations. John wiley & sons, 1993. Raymond E Miles, Charles C Snow, Alan D Meyer, and Henry J Coleman Jr. Organizational strategy, structure, and process.Academy o...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/iccv 1991
-
[2]
What’s the main feature of{group name}’s behavior (Focus on the current topic: "{goal topic}") shown in the given scene-action pairs,other than the already established statements?
-
[3]
Summarize{k}potential common points (grounding statements) of the actions taken by {group name}in the given scenes about the focused topic: "{goal topic}",which is other than the already established statements. - The grounding statements should be general, avoiding too specific action descriptions. - Consider the grounding statements in a general way. - T...
-
[4]
Summarize{k}potential common points of the given scenes that trigger each behavior,which should be different from already proposed common points. - The question should be simple, not ambiguous, and specific to a subset of scenes rather than always applicable. - Focus on thenext actionwhen asking! Don’t ask whether certain event is involved, instead ask wh...
-
[5]
Output the hypothesized scene-action triggers in the following format: action hypotheses = [ ] # A list of grounding statements (strings) scene check hypotheses = [ ] # A list of syntactically complete questions to check the given scene (always mentioning{group name}) Figure 13: Hypothesis generation prompt (Step 2 of CDT construction). Given clustered sc...
-
[6]
Coherence and logic of the decision flow
-
[7]
Generalized understanding of the group’s behavior (avoiding overfitting to specific trivial details)
-
[8]
Here are the candidates: {verbalized candidates} Task:
Clarity and meaningfulness of the gates (questions) and statements (behaviors). Here are the candidates: {verbalized candidates} Task:
-
[9]
Analyze the strengths and weaknesses of each candidate briefly
-
[10]
Select the single best candidate
-
[11]
Output your choice in the following JSON format: {"best candidate index": <1-based index>, "reasoning": "<your reasoning>"} Figure 17: Multi-candidate selection prompt (Step 5). Each of Rsel voting rounds presents the candidates in a random order; the candidate with the most votes is selected. 24 Preprint. Under review. Group:{g} Action:{d i} Classify the...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.