Recognition: unknown
The Rise and Fall of G in AGI
Pith reviewed 2026-05-10 15:50 UTC · model grok-4.3
The pith
AI models exhibit a general intelligence factor that rises across early benchmarks then falls as specialized reasoning abilities appear.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
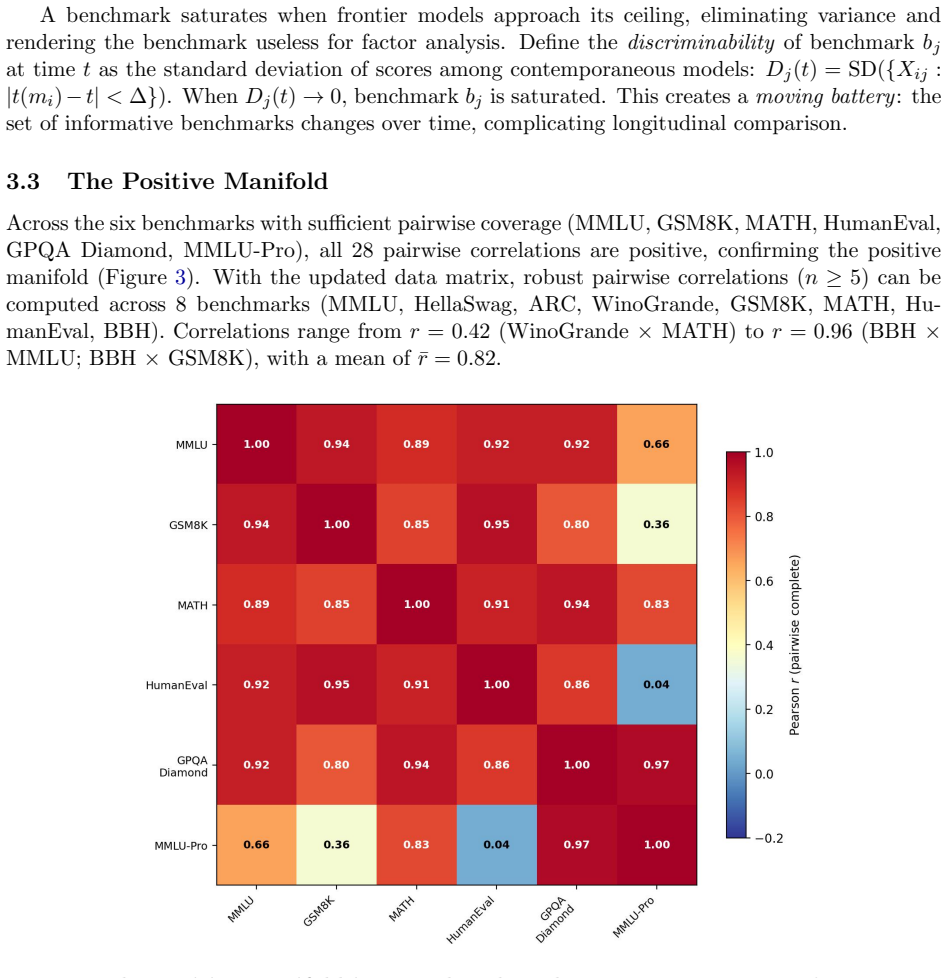
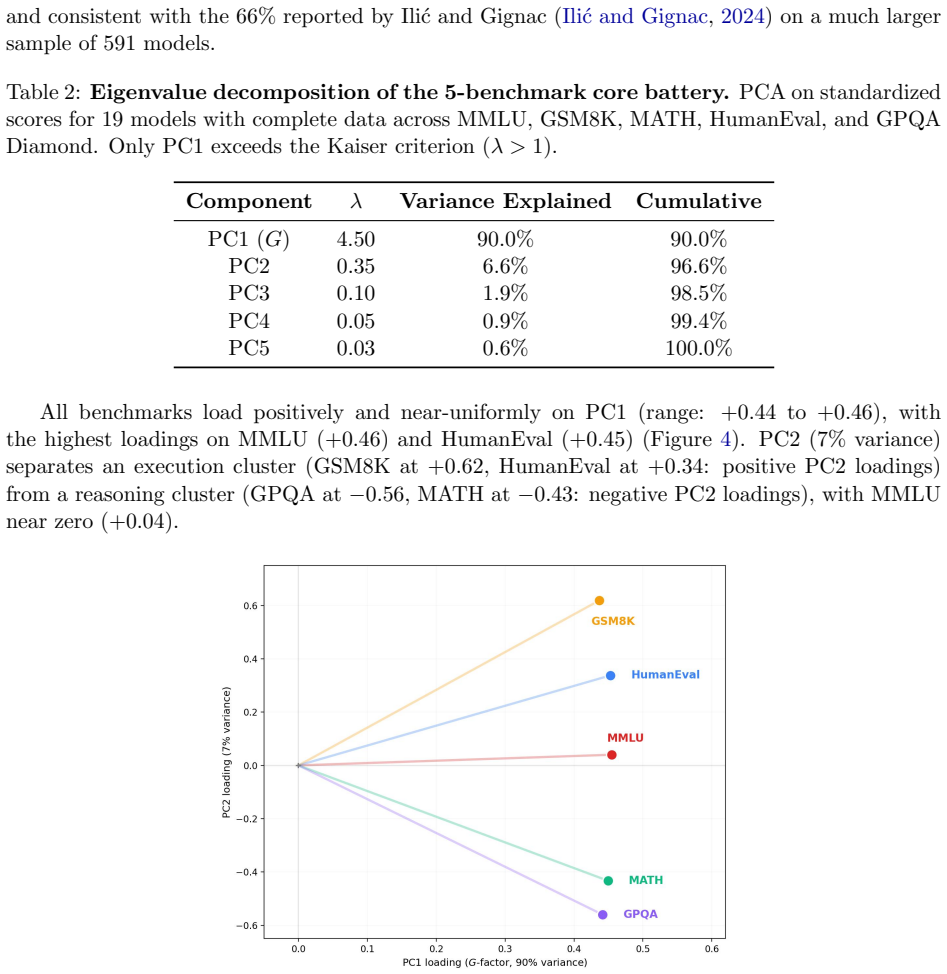
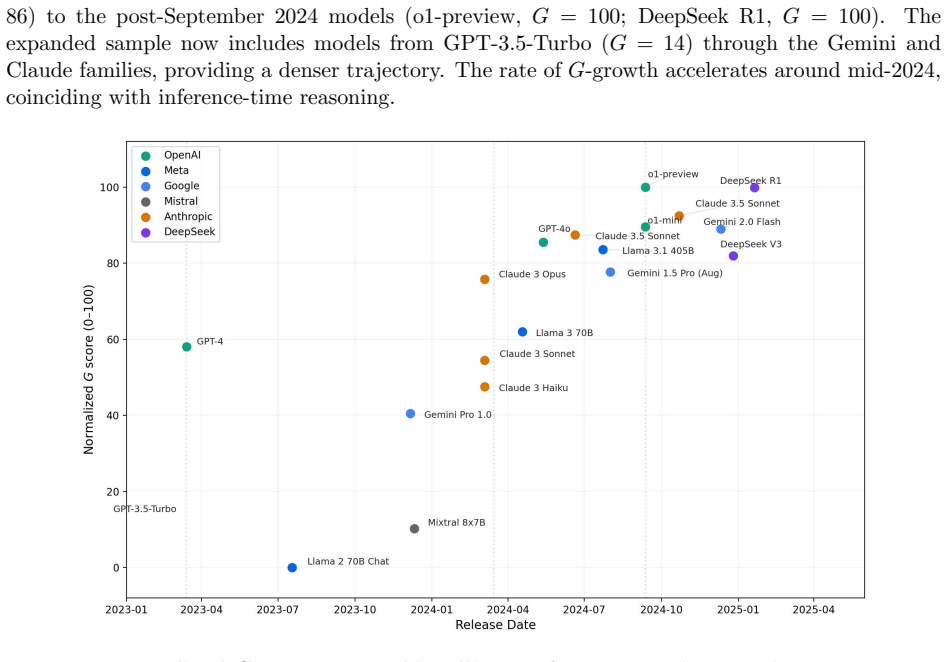
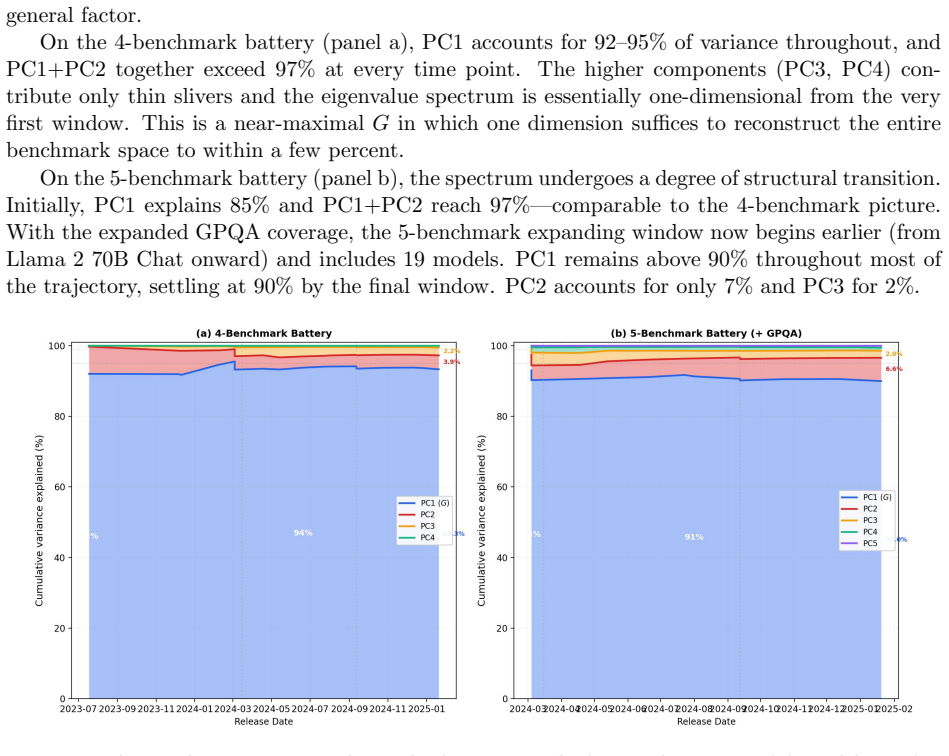
By constructing a models-by-benchmarks-by-time matrix for 39 models from 2019 to 2025 across 14 benchmarks, the analysis confirms a strong positive manifold with all 28 pairwise correlations positive on an 8-benchmark subset. Principal component analysis on a 5-benchmark core battery shows PC1 explaining 90 percent of variance, falling to 77 percent by 2024; on a four-benchmark battery PC1 peaks at 92 percent in 2023-2024 and drops to 64 percent with the arrival of reasoning-specialized models. Partial correlation matrices reveal increasing specialization beneath the manifold, supporting the claim that in psychometric terms AI models display general intelligence that suppresses specialized能力
What carries the argument
The G-factor obtained as the first principal component of the time-evolving benchmark correlation matrix, which quantifies the positive manifold and tracks its rotation toward specialization.
If this is right
- AI progress initially unifies performance across diverse benchmarks under a dominant general factor.
- Specialized intelligences emerge and reduce the explanatory power of the general factor once reasoning tools are integrated.
- Current LLM architectures follow a pattern of increasing hierarchical complexity instead of replacing complex mechanisms with simpler ones.
- The positive manifold of general intelligence encompasses multiple high-dimensional problem-solving systems that later differentiate.
Where Pith is reading between the lines
- Benchmark design may need to evolve to isolate the contribution of tool use versus intrinsic model capability.
- The observed pattern suggests that continued scaling alone will not sustain the same level of cross-benchmark generality.
- This dynamic could guide the creation of hybrid systems that deliberately preserve specialized modules alongside general ones.
Load-bearing premise
Benchmark performance scores can be treated as equivalent to human cognitive test scores, allowing direct psychometric factor analysis on model releases as subjects.
What would settle it
A failure to observe a decline in the variance explained by the first principal component after 2024, or the appearance of negative pairwise benchmark correlations in later model cohorts, would falsify the falling-G claim.
Figures










read the original abstract
In the psychological literature the term `general intelligence' describes correlations between abilities and not simply the number of abilities. This paper connects Spearman's $g$-factor from psychometrics, measuring a positive manifold, to the implicit ``$G$-factor'' in claims about artificial general intelligence (AGI) performance on temporally structured benchmarks. By treating LLM benchmark batteries as cognitive test batteries and model releases as subjects, principal component analysis is applied to a models $\times$ benchmarks $\times$ time matrix spanning 39 models (2019--2025) and 14 benchmarks. Preliminary results confirm a strong positive manifold in which all 28 pairwise correlations positive across 8 benchmarks. By analyzing the spectrum of the benchmark correlation through time, PC1 explains 90\% of variance on a 5-benchmark core battery ($n=19$)) reducing to 77\% by 2024. On a four benchmark battery, PC1 is found to peak at 92\% of the variance between 2023--2024 and reduce to 64\% with the arrival of reasoning-specialized models in 2024. This is coincident with a rotation in the G-factor as models outsource `reasoning' to tools. The analysis of partial correlation matrices through time provides evidence for the evolution of specialization beneath the positive manifold of general intelligence (AI-hedgehog) encompassing diverse high dimensional problem solving systems (AI-foxes). In strictly psychometric terms, AI models exhibit general intelligence suppressing specialized intelligences. LLMs invert the ideal of substituting complicated models with parsimonious mechanisms, a `Ptolemaic Succession' of theories, with architectures of increasing hierarchical complication and capability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that principal component analysis applied to correlations among LLM benchmark scores across 39 models from 2019-2025 reveals a strong positive manifold, with the first principal component (interpreted as an AI G-factor analogous to Spearman's g) explaining a high proportion of variance (90% on 5-benchmark battery, 92% on 4-benchmark) that subsequently declines (to 77% and 64% respectively) as specialized reasoning models emerge in 2024. This decline, analyzed through time-varying correlation matrices, is interpreted as evidence that general intelligence suppresses specialized intelligences in AI systems, inverting traditional parsimony ideals in a 'Ptolemaic Succession' of increasingly complex architectures.
Significance. If validated with appropriate controls for confounding factors like model scale, this analysis provides a valuable empirical framework for applying psychometric methods to track the evolution of AI capabilities. It offers quantitative support for the idea that AI progress involves not just increasing general ability but also diversification and specialization, with potential implications for AGI development and evaluation. The temporal dimension and use of multiple benchmark subsets are strengths that allow observation of dynamic changes in the correlation structure.
major comments (3)
- [PCA results for 5-benchmark battery] In the section describing the PCA on the 5-benchmark core battery (n=19 models), the reported decline in PC1 variance from 90% to 77% is presented without any residualization of benchmark scores against model parameter count, training FLOPs, or release date prior to computing the correlation matrix. This is load-bearing for the central claim, as the positive manifold and its erosion could be artifacts of uncontrolled scaling rather than evidence for a latent g-factor independent of scale.
- [Four benchmark battery analysis] In the section on the four-benchmark battery analysis, the peak at 92% variance explained (2023-2024) and subsequent drop to 64% with reasoning-specialized models lacks a control PCA or partial correlation analysis that holds scale or compute fixed. Without this, the rotation in the G-factor and attribution to tool-use specialization cannot be distinguished from effects of benchmark diversification or increasing model heterogeneity.
- [Interpretation of partial correlation matrices] In the interpretation of partial correlation matrices through time, the conclusion that AI models exhibit 'general intelligence suppressing specialized intelligences' assumes the observed correlation structure is independent of the dominant scaling trend, but no alternative model (e.g., PCA on residuals after regressing out parameter count) or falsification test is reported. This directly affects the 'Ptolemaic Succession' framing.
minor comments (3)
- [Abstract] The abstract introduces terms such as 'AI-hedgehog' and 'AI-foxes' without definition or reference to the underlying analogy, which reduces clarity for readers outside the immediate subfield.
- [Data and methods] The data description lacks explicit details on preprocessing steps, including handling of missing benchmark values, score normalization across heterogeneous benchmarks, and criteria for model and benchmark inclusion.
- [Results] The reported variance percentages for PC1 lack accompanying statistical significance tests, bootstrap confidence intervals, or sensitivity analyses to different model subsets.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which identify key methodological gaps in controlling for scaling effects. We address each major comment below and will incorporate additional analyses in the revised manuscript to strengthen the claims.
read point-by-point responses
-
Referee: [PCA results for 5-benchmark battery] In the section describing the PCA on the 5-benchmark core battery (n=19 models), the reported decline in PC1 variance from 90% to 77% is presented without any residualization of benchmark scores against model parameter count, training FLOPs, or release date prior to computing the correlation matrix. This is load-bearing for the central claim, as the positive manifold and its erosion could be artifacts of uncontrolled scaling rather than evidence for a latent g-factor independent of scale.
Authors: We agree that residualization against scale metrics is necessary to isolate any latent g-factor from scaling trends. The temporal decline coincides with the 2024 emergence of specialized models, but this does not fully rule out scale confounds. In revision, we will regress benchmark scores on log(parameter count) and release date, then recompute the correlation matrix and PCA on the residuals. Results will be reported alongside the original analyses. revision: yes
-
Referee: [Four benchmark battery analysis] In the section on the four-benchmark battery analysis, the peak at 92% variance explained (2023-2024) and subsequent drop to 64% with reasoning-specialized models lacks a control PCA or partial correlation analysis that holds scale or compute fixed. Without this, the rotation in the G-factor and attribution to tool-use specialization cannot be distinguished from effects of benchmark diversification or increasing model heterogeneity.
Authors: We acknowledge this limitation. To address it, the revised manuscript will include a control PCA restricted to models within a narrow parameter-count range (e.g., 10B-100B) and partial correlation analyses controlling for log(parameter count). This will help separate specialization effects from heterogeneity or benchmark changes. revision: yes
-
Referee: [Interpretation of partial correlation matrices] In the interpretation of partial correlation matrices through time, the conclusion that AI models exhibit 'general intelligence suppressing specialized intelligences' assumes the observed correlation structure is independent of the dominant scaling trend, but no alternative model (e.g., PCA on residuals after regressing out parameter count) or falsification test is reported. This directly affects the 'Ptolemaic Succession' framing.
Authors: The referee correctly notes the absence of a direct falsification test. We will add PCA performed on residuals after regressing out parameter count (and, where available, FLOPs) from the benchmark scores. The revised text will discuss whether the suppression interpretation and Ptolemaic Succession framing remain supported after this control. revision: yes
Circularity Check
No circularity: direct empirical PCA on external benchmark data
full rationale
The paper applies principal component analysis to a models-by-benchmarks correlation matrix constructed from publicly available LLM benchmark scores across 39 models and 14 benchmarks. PC1 variance shares (90% to 77%, 92% to 64%) and the positive manifold are computed outputs of this matrix; no step renames a fitted parameter as a prediction, defines G in terms of itself, or reduces a claimed result to a self-citation chain. The psychometric analogy to Spearman's g is interpretive framing rather than a load-bearing derivation, and the temporal analysis of partial correlations is a straightforward data-driven observation without self-referential closure.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Benchmark scores can be treated as direct analogs to cognitive test scores for the purpose of extracting a general factor via PCA.
Reference graph
Works this paper leans on
-
[1]
J., Deary, I
Bartholomew, D. J., Deary, I. J., and Lawn, M. (2009). A new lease of life for Thomson’s bonds model of intelligence.Psychological Review, 116:567–579
2009
-
[2]
(2013).The hedgehog and the fox: An essay on Tolstoy’s view of history
Berlin, I. (2013).The hedgehog and the fox: An essay on Tolstoy’s view of history. Princeton University Press
2013
-
[3]
M., Schubiger, M
Burkart, J. M., Schubiger, M. N., and Van Schaik, C. P. (2017). The evolution of general intelligence. Behavioral and Brain Sciences, 40:e195
2017
-
[4]
Carroll, J. B. (1993).Human Cognitive Abilities: A Survey of Factor-Analytic Studies. Cambridge University Press, Cambridge
1993
-
[5]
Cattell, R. B. (1963). Theory of fluid and crystallized intelligence: A critical experiment.Journal of educational psychology, 54(1):1
1963
-
[6]
Brockman, G., et al. (2021). Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Chollet, F. (2019). On the measure of intelligence.arXiv preprint arXiv:1911.01547
work page internal anchor Pith review arXiv 2019
-
[8]
(1998).Being There: Putting Brain, Body, and World Together Again
Clark, A. (1998).Being There: Putting Brain, Body, and World Together Again. MIT Press
1998
-
[9]
Hilton, J., Nakano, R., Hesse, C., and Schulman, J. (2021). Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168. Epoch AI (2024). AI benchmarking hub
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
(1983).Frames of Mind: The Theory of Multiple Intelligences
Gardner, H. (1983).Frames of Mind: The Theory of Multiple Intelligences. Basic Books
1983
-
[11]
Gottfredson, L. S. (1997). Why g matters: The complexity of everyday life.Intelligence, 24:79–132
1997
-
[12]
Gottfredson, L. S. (2003). Dissecting practical intelligence theory: Its claims and evidence.Intel- ligence, 31(4):343–397
2003
-
[13]
Hendrycks, D., Bengio, Y., Song, D., Tegmark, M., Schmidt, E., et al. (2025). A definition of AGI. https://www.agidefinition.ai/paper.pdf
2025
-
[14]
Horn, J. L. (1965). A rationale and test for the number of factors in factor analysis.Psychometrika, 30:179–185
1965
-
[15]
Hutchins, E. (2000). Distributed cognition.International encyclopedia of the social and behavioral sciences, 138(1):1–10. 30 Ili´ c, D. and Gignac, G. E. (2024). Evidence of interrelated cognitive-like capabilities in large language models: Indications of artificial general intelligence or achievement?Intelligence, 106:101858
2000
-
[16]
Jensen, A. R. (1998).The g Factor: The Science of Mental Ability. Praeger
1998
-
[17]
Jensen, A. R. (2002). Psychometric g: Definition and substantiation. In Sternberg, R. J. and
2002
-
[18]
J., Krueger, R
Johnson, W., Bouchard Jr, T. J., Krueger, R. F., McGue, M., and Gottesman, I. I. (2004). Just one g: Consistent results from three test batteries.Intelligence, 32:95–107
2004
-
[19]
Johnson, W., te Nijenhuis, J., and Bouchard Jr., T. J. (2008). Still just 1 g: Consistent results from five test batteries.Intelligence, 36:81–95
2008
-
[20]
Jung, R. E. and Haier, R. J. (2007). The Parieto-Frontal Integration Theory (P-FIT) of intelligence: Converging neuroimaging evidence.Behavioral and Brain Sciences, 30:135–154
2007
-
[21]
and Conway, A
Kovacs, K. and Conway, A. R. A. (2016). Process overlap theory: A unified account of the general factor of intelligence.Psychological Inquiry, 27:151–177
2016
-
[22]
Gandhi, C. C. (2003). Individual differences in the expression of a “general” learning ability in mice.Journal of Neuroscience, 23(16):6423–6433
2003
-
[23]
(1986).Society of mind
Minsky, M. (1986).Society of mind. Simon and Schuster
1986
- [24]
-
[25]
Neubauer, S., Hublin, J.-J., and Gunz, P. (2018). The evolution of modern human brain shape. Science advances, 4(1):eaao5961
2018
-
[26]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
Rein, D., Hou, B. L., Stickland, A. C., Petty, J., Pang, R. Y., Dirani, J., Michael, J., and Bow- man, S. R. (2024). GPQA: A graduate-level Google-proof Q&A benchmark.arXiv preprint arXiv:2311.12022
work page internal anchor Pith review arXiv 2024
-
[27]
O., Marsman, M., van der Maas, H
Savi, A. O., Marsman, M., van der Maas, H. L. J., and Maris, G. K. J. (2019). The wiring of intelligence.Perspectives on Psychological Science, 14:1034–1061
2019
-
[28]
General intelligence,
Spearman, C. (1904). “General intelligence,” objectively determined and measured.American Journal of Psychology, 15:201–293
1904
-
[29]
Sternberg, R. J. (1985).Beyond IQ: A Triarchic Theory of Human Intelligence. Cambridge Uni- versity Press
1985
-
[30]
(2012).Masters of the Planet: The Search for Our Human Origins
Tattersall, I. (2012).Masters of the Planet: The Search for Our Human Origins. Palgrave Macmil- lan
2012
-
[31]
Thomson, G. H. (1916). A hierarchy without a general factor.British Journal of Psychology, 8:271–281. 31
1916
-
[32]
Thurstone, L. L. (1938).Primary Mental Abilities. Number 1 in Psychometric Monographs. University of Chicago Press, Chicago
1938
-
[33]
(2024).The AI mirror: How to reclaim our humanity in an age of machine thinking
Vallor, S. (2024).The AI mirror: How to reclaim our humanity in an age of machine thinking. Oxford University Press. van der Maas, H. L. J., Dolan, C. V., Grasman, R. P. P. P., Wicherts, J. M., Huizenga, H. M., and
2024
-
[34]
Raijmakers, M. E. J. (2006). A dynamical model of general intelligence: The positive manifold of intelligence by mutualism.Psychological Review, 113:842–861. 32
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.