Recognition: unknown
Regularized Entropy Information Adaptation with Temporal-Awareness Networks for Simultaneous Speech Translation
Pith reviewed 2026-05-10 17:09 UTC · model grok-4.3
The pith
Temporal context added to information-gain policies cuts audio over-reading in simultaneous speech translation and raises efficiency scores by up to 7.1 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
REINA policies that decide when to read more audio or begin writing rely on regularized entropy information gain but lack temporal context, causing them to read most of the source audio before translating. Adding a supervised alignment network (REINA-SAN) or a timestep-augmented network (REINA-TAN) supplies this missing context. Both extensions outperform the original REINA, eliminate observed instabilities, and improve the Pareto frontier of streaming efficiency. REINA-TAN yields a slightly better efficiency frontier; REINA-SAN is more resistant to read loops. On Whisper, the two methods raise Normalized Streaming Efficiency scores by up to 7.1 percent over existing baselines.
What carries the argument
REINA read/write policy based on regularized entropy information gain, augmented by either a supervised alignment network or a timestep-augmented network that injects temporal context into the read-versus-write decision.
If this is right
- Both REINA-SAN and REINA-TAN outperform the original REINA baseline and remove its stability problems.
- REINA-TAN achieves a modestly superior Pareto frontier for the quality-latency tradeoff.
- REINA-SAN provides greater robustness against read loops.
- When the methods are applied to Whisper, Normalized Streaming Efficiency scores rise by up to 7.1 percent over prior competitive baselines.
Where Pith is reading between the lines
- The same temporal-augmentation pattern could be tested on other streaming policy tasks where decisions must balance information gain against timing constraints.
- The differing robustness profiles of SAN and TAN suggest that practitioners can choose the variant according to whether peak efficiency or resistance to loops matters more in deployment.
- Applying the networks to longer or noisier audio streams would reveal whether the temporal correction remains effective when speaking rates and silence patterns differ from the training distribution.
Load-bearing premise
The observed tendency of REINA to read most of the audio before writing stems primarily from missing temporal context, and adding alignment or timestep information corrects this bias without creating new instabilities or lowering translation quality on unseen data.
What would settle it
A controlled experiment on a held-out simultaneous translation test set that measures average audio length before first write and NoSE scores; if REINA-SAN or REINA-TAN shows no reduction in read length or no NoSE gain relative to plain REINA, the claim that temporal awareness is the decisive fix is falsified.
Figures


read the original abstract
Simultaneous Speech Translation (SimulST) requires balancing high translation quality with low latency. Recent work introduced REINA, a method that trains a Read/Write policy based on estimating the information gain of reading more audio. However, we find that information-based policies often lack temporal context, leading the policy to bias itself toward reading most of the audio before starting to write. We improve REINA using two distinct strategies: a supervised alignment network (REINA-SAN) and a timestep-augmented network (REINA-TAN). Our results demonstrate that while both methods significantly outperform the baseline and resolve stability issues, REINA-TAN provides a slightly superior Pareto frontier for streaming efficiency, whereas REINA-SAN offers more robustness against 'read loops'. Applied to Whisper, both methods improve the pareto frontier of streaming efficiency as measured by Normalized Streaming Efficiency (NoSE) scores up to 7.1% over existing competitive baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces two temporal-awareness enhancements to the REINA read/write policy for Simultaneous Speech Translation: REINA-SAN (supervised alignment network) and REINA-TAN (timestep-augmented network). These address an observed bias in information-gain policies toward reading most of the audio before writing. Applied to Whisper, the authors claim both variants significantly outperform the REINA baseline, resolve stability issues such as read loops, and improve the Pareto frontier of streaming efficiency with Normalized Streaming Efficiency (NoSE) gains of up to 7.1% over competitive baselines.
Significance. If the reported gains hold under rigorous controls, the work offers a targeted, practical improvement to SimulST systems by mitigating a specific policy bias through temporal context. The distinction between SAN's robustness and TAN's efficiency edge, together with the NoSE metric for Pareto analysis, provides a useful framework for evaluating latency-quality trade-offs in streaming translation.
major comments (2)
- Abstract: the central claim of up to 7.1% NoSE improvement and resolution of stability issues is presented without any experimental details, baseline reimplementation descriptions, variance estimates, p-values, or ablation results. This prevents verification that the gains are attributable to SAN/TAN rather than differences in training regime or implementation.
- Results and evaluation sections: no evidence is provided that the original REINA policy was re-evaluated under identical conditions, seeds, or hyperparameter regimes as the proposed variants. Without such controls or statistical tests, the attribution of NoSE gains and stability improvements to the temporal-awareness components cannot be isolated.
Simulated Author's Rebuttal
Thank you for the constructive review. We address the concerns about experimental details, baseline controls, and statistical rigor point by point. We will revise the manuscript to incorporate additional information and strengthen the presentation of results.
read point-by-point responses
-
Referee: Abstract: the central claim of up to 7.1% NoSE improvement and resolution of stability issues is presented without any experimental details, baseline reimplementation descriptions, variance estimates, p-values, or ablation results. This prevents verification that the gains are attributable to SAN/TAN rather than differences in training regime or implementation.
Authors: We agree that the abstract, due to space constraints, summarizes claims without full experimental context. The full manuscript details the experimental protocol, baseline reimplementations, and evaluation in Section 4. In revision we will add a brief reference in the abstract to the evaluation setup and expand the results section with variance estimates, p-values, and ablations to isolate the contribution of the temporal-awareness components. revision: yes
-
Referee: Results and evaluation sections: no evidence is provided that the original REINA policy was re-evaluated under identical conditions, seeds, or hyperparameter regimes as the proposed variants. Without such controls or statistical tests, the attribution of NoSE gains and stability improvements to the temporal-awareness components cannot be isolated.
Authors: The original REINA policy was re-evaluated under identical conditions, using the same Whisper backbone, training data, seeds, and hyperparameters as the SAN and TAN variants; this shared setup is described in the experimental section. To make the controls explicit we will add a dedicated paragraph and table in the revised version documenting the identical re-evaluation protocol together with statistical significance tests. revision: yes
Circularity Check
No significant circularity; empirical training and evaluation
full rationale
The paper is an empirical contribution that trains supervised alignment networks (REINA-SAN) and timestep-augmented networks (REINA-TAN) on data to improve an existing Read/Write policy for simultaneous speech translation, then reports measured improvements in Normalized Streaming Efficiency (NoSE) scores. No equations, derivations, or self-referential quantities appear in the provided text; the central claims rest on experimental results rather than any reduction of predictions to fitted inputs or self-citations by construction. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neural networks trained with supervision can learn stable read/write policies that generalize beyond training data
Reference graph
Works this paper leans on
-
[1]
Introduction Simultaneous Speech Translation (SimulST) aims to generate target-language text in real-time while source speech is still unfolding. Unlike offline Speech-to-Text Translation (S2TT), SimulST systems must decide at each step whether to wait for more audio (READ) or emit the next target token (WRITE), inducing a fundamental trade-off between tr...
-
[2]
Related Work The transition from offline Speech-to-Text Translation (S2TT) to SimulST necessitates a read/write policy to balance quality and latency. Fixed policies, such as wait-k[5, 6], are simple to implement but lack the flexibility to handle varying speech rates and word reorderings across languages. Adaptive policies ad- dress this by dynamically d...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Preliminaries Simultaneous Speech Translation requires a policy to decide be- tween READ(consuming audio framea t+1) and WRITE(emit- ting tokens n+1) at step(t, n). REINA derives this policy from the principle of Information Maximization: the system should wait for more context if and only if doing so significantly re- duces uncertainty about the next tok...
-
[4]
read loop
Motivation: Analysis of Policy Instability 4.1. Analysis of REINA While the original REINA article [1] provides substantial theo- retical justification of the REINA loss, empirical analysis of the loss is limited. As shown in figure 1, we plot the estimated in- formation gain at train time given partial audio to understand vi- sually how the loss works. W...
-
[5]
Method We experiment with two methods to improve REINA’s temporal awareness and streaming efficiency: (i) A Supervised Align- ment Network that leverage LLM-generated alignments, and (ii) a Timestep Augmented Network that augments the policy network with a duration encoding. 5.1. Supervised-Alignment Network We introduce a secondary supervision signal der...
2000
-
[6]
Read Loop %
Experiments We experiment with augmenting REINA with weak supervision from LLM alignments as well as an audio duration encoding. We ultimately show that the latter (REINA-TAN) performs best, improving upon the previous state of the art for simulST. 6.1. Experimental Setup Model Variants.We build on top of a strong offline speech translation model: Whisper...
-
[7]
We use a temperature of 0.5 for REINA-SAN
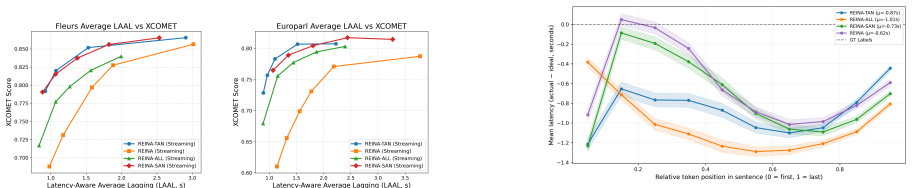
of beam size 3 with the same hyperparameters, and simulate streaming using incremental audio chunk sizes of 250ms. We use a temperature of 0.5 for REINA-SAN. 6.2. Results & Analysis We first show LAAL vs XCOMET results on combined lan- guages on FLEURS and Europarl in figure 3, and select op- erating points in table 1. REINA-TAN clearly outperforms all ot...
-
[8]
We pro- posed two architectural enhancements: REINA-TAN (continu- ous temporal embeddings) and REINA-SAN (weak monotonic supervision)
Conclusion This paper resolves the temporal drift that limits information- based SimulST policies on large foundation models. We pro- posed two architectural enhancements: REINA-TAN (continu- ous temporal embeddings) and REINA-SAN (weak monotonic supervision). The marked success of both methods confirms that a lack of explicit temporal grounding is indeed...
-
[9]
Reina: Reg- ularized entropy information-based loss for efficient simultaneous speech translation,
N. Hirschkind, J. Liu, X. Yu, and M. K. Nandwana, “Reina: Reg- ularized entropy information-based loss for efficient simultaneous speech translation,”arXiv preprint arXiv:2508.04946, 2025
-
[10]
S. Cheng, Z. Huang, T. Ko, H. Li, N. Peng, L. Xu, and Q. Zhang, “Towards achieving human parity on end-to-end si- multaneous speech translation via llm agent,”arXiv preprint arXiv:2407.21646, 2024
-
[11]
High-fidelity simultaneous speech-to-speech translation,
T. Labiausse, L. Mazar ´e, E. Grave, P. P ´erez, A. D ´efossez, and N. Zeghidour, “High-fidelity simultaneous speech-to-speech translation,”arXiv preprint arXiv:2502.03382, 2025
-
[12]
Simultaneous speech-to-speech translation without aligned data,
T. Labiausse, R. Fabre, Y . Est `eve, A. D ´efossez, and N. Zeghi- dour, “Simultaneous speech-to-speech translation without aligned data,”arXiv preprint arXiv:2602.11072, 2026
-
[13]
STACL: Simultaneous translation with implicit anticipation and controllable latency using prefix-to-prefix framework,
M. Ma, L. Huang, H. Xiong, R. Zheng, K. Liu, B. Zheng, C. Zhang, Z. He, H. Liu, X. Li, H. Wu, and H. Wang, “STACL: Simultaneous translation with implicit anticipation and controllable latency using prefix-to-prefix framework,” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, A. Korhonen, D. Traum, and L. M`arquez...
2019
-
[14]
SimulMT to SimulST: Adapting simultaneous text translation to end-to-end simultaneous speech translation,
X. Ma, J. Pino, and P. Koehn, “SimulMT to SimulST: Adapting simultaneous text translation to end-to-end simultaneous speech translation,” inProceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing, K.-F. Wong, K. Knight, and H. ...
2020
-
[15]
Efficient monotonic multihead attention,
X. Ma, A. Sun, S. Ouyang, H. Inaguma, and P. Tomasello, “Efficient monotonic multihead attention,” 2023. [Online]. Available: https://arxiv.org/abs/2312.04515
-
[16]
Monotonic infinite lookback attention for simultaneous machine translation,
N. Arivazhagan, C. Cherry, W. Macherey, C.-C. Chiu, S. Yavuz, R. Pang, W. Li, and C. Raffel, “Monotonic infinite lookback attention for simultaneous machine translation,” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, A. Korhonen, D. Traum, and L. M`arquez, Eds. Florence, Italy: Association for Computational Li...
2019
-
[17]
Sequence Transduction with Recurrent Neural Networks
A. Graves, “Sequence transduction with recurrent neural networks,”CoRR, vol. abs/1211.3711, 2012. [Online]. Available: http://arxiv.org/abs/1211.3711
work page Pith review arXiv 2012
-
[18]
Large- scale streaming end-to-end speech translation with neural transducers,
J. Xue, P. Wang, J. Li, M. Post, and Y . Gaur, “Large- scale streaming end-to-end speech translation with neural transducers,” inInterspeech, 2022. [Online]. Available: https: //api.semanticscholar.org/CorpusID:248118691
2022
-
[19]
Seed liveinterpret 2.0: End-to-end simultaneous speech-to-speech translation with your voice,
S. Cheng, Y . Bao, Z. Huang, Y . Lu, N. Peng, L. Xu, R. Yu, R. Cao, Y . Du, T. Hanet al., “Seed liveinterpret 2.0: End-to-end simultaneous speech-to-speech translation with your voice,”arXiv preprint arXiv:2507.17527, 2025
-
[20]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. Mcleavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inProceedings of the 40th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, Eds., vol. 202. PMLR, 23– ...
2023
-
[21]
Less is more: Accurate speech recog- nition & translation without web-scale data,
K. Puvvada, P. ˙Zelasko, H. Huang, O. Hrinchuk, N. Koluguri, K. Dhawan, S. Majumdar, E. Rastorgueva, Z. Chen, V . Lavrukhin, J. Balam, and B. Ginsburg, “Less is more: Accurate speech recog- nition & translation without web-scale data,” 09 2024, pp. 3964– 3968
2024
-
[22]
Owsm v3.1: Better and faster open whisper-style speech models based on e-branchformer,
Y . Peng, J. Tian, W. Chen, S. Arora, B. Yan, Y . Sudo, M. Shakeel, K. Choi, J. Shi, X. Chang, J.-W. Jung, and S. Watanabe, “Owsm v3.1: Better and faster open whisper-style speech models based on e-branchformer,” 09 2024, pp. 352–356
2024
-
[23]
SimulSpeech: End-to-end simultaneous speech to text translation,
Y . Ren, J. Liu, X. Tan, C. Zhang, T. Qin, Z. Zhao, and T.-Y . Liu, “SimulSpeech: End-to-end simultaneous speech to text translation,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault, Eds. Online: Association for Computational Linguistics, Jul. 2020, pp. 3787–37...
2020
-
[24]
Low-latency sequence-to- sequence speech recognition and translation by partial hypothesis selection,
D. Liu, G. Spanakis, and J. Niehues, “Low-latency sequence-to- sequence speech recognition and translation by partial hypothesis selection,” 10 2020, pp. 3620–3624
2020
-
[25]
Sasst: Leveraging syntax-aware chunking and llms for simultaneous speech translation,
Z. Yang, L. Wei, R. Koshkin, X. Chen, and S. Nakamura, “Sasst: Leveraging syntax-aware chunking and llms for simultaneous speech translation,”arXiv preprint arXiv:2508.07781, 2025
-
[26]
Divergence-guided simultaneous speech translation,
X. Chen, K. Fan, W. Luo, L. Zhang, L. Zhao, X. Liu, and Z. Huang, “Divergence-guided simultaneous speech translation,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 16, pp. 17 799–17 807, Mar. 2024. [Online]. Available: https://ojs.aaai.org/index.php/AAAI/article/view/29733
2024
-
[27]
Efficient and adaptive simultaneous speech translation with fully unidirectional architecture,
B. Fu, D. Yu, M. Liao, C. Li, Y . Chen, and K. Fan, “Efficient and adaptive simultaneous speech translation with fully unidirectional architecture,” 04 2025
2025
-
[28]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[29]
Cvss corpus and massively multilingual speech-to-speech translation,
Y . Jia, M. T. Ramanovich, Q. Wang, and H. Zen, “Cvss corpus and massively multilingual speech-to-speech translation,” inPro- ceedings of the Thirteenth Language Resources and Evaluation Conference, 2022, pp. 6691–6703
2022
-
[30]
Mls: A large-scale multilingual dataset for speech research,
V . Pratap, Q. Xu, A. Sriram, G. Synnaeve, and R. Collobert, “Mls: A large-scale multilingual dataset for speech research,” inProc. Interspeech 2020, 2020, pp. 2757–2761
2020
-
[31]
Gemma 2: Improving Open Language Models at a Practical Size
G. Team, M. Riviere, S. Pathak, P. G. Sessa, C. Hardin, S. Bhu- patiraju, L. Hussenot, T. Mesnard, B. Shahriari, A. Ram ´eet al., “Gemma 2: Improving open language models at a practical size,” arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
MetricX-24: The Google submission to the WMT 2024 metrics shared task,
J. Juraska, D. Deutsch, M. Finkelstein, and M. Freitag, “MetricX-24: The Google submission to the WMT 2024 metrics shared task,” inProceedings of the Ninth Conference on Machine Translation, B. Haddow, T. Kocmi, P. Koehn, and C. Monz, Eds. Miami, Florida, USA: Association for Computational Linguistics, Nov. 2024, pp. 492–504. [Online]. Available: https://...
2024
-
[33]
Whisperx: Time-accurate speech transcription of long- form audio,
M. Bain, J. Huh, T. Han, and A. Zisserman, “Whisperx: Time-accurate speech transcription of long- form audio,” inInterspeech, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:257255343
2023
-
[34]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, M. Li, P. Zhang, P. Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T. ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Fleurs: Few-shot learning evaluation of universal representations of speech,
A. Conneau, M. Ma, S. Khanuja, Y . Zhang, V . Axelrod, S. Dalmia, J. Riesa, C. Rivera, and A. Bapna, “Fleurs: Few-shot learning evaluation of universal representations of speech,” in2022 IEEE Spoken Language Technology Workshop (SLT), 2023, pp. 798– 805
2023
-
[36]
Europarl: A parallel corpus for statistical machine translation,
P. Koehn, “Europarl: A parallel corpus for statistical machine translation,” inProceedings of Machine Translation Summit X: Papers, Phuket, Thailand, Sep. 13-15 2005, pp. 79–86. [Online]. Available: https://aclanthology.org/2005.mtsummit-papers.11/
2005
-
[37]
Over-generation cannot be rewarded: Length-adaptive average lagging for simultaneous speech translation,
S. Papi, M. Gaido, M. Negri, and M. Turchi, “Over-generation cannot be rewarded: Length-adaptive average lagging for simultaneous speech translation,” inProceedings of the Third Workshop on Automatic Simultaneous Translation, J. Ive and R. Zhang, Eds. Online: Association for Computational Linguistics, Jul. 2022, pp. 12–17. [Online]. Available: https: //ac...
2022
-
[38]
A call for clarity in reporting BLEU scores,
M. Post, “A call for clarity in reporting BLEU scores,” in Proceedings of the Third Conference on Machine Translation: Research Papers, O. Bojar, R. Chatterjee, C. Federmann, M. Fishel, Y . Graham, B. Haddow, M. Huck, A. J. Yepes, P. Koehn, C. Monz, M. Negri, A. N ´ev´eol, M. Neves, M. Post, L. Specia, M. Turchi, and K. Verspoor, Eds. Brussels, Belgium: A...
2018
-
[39]
Available: https://aclanthology.org/W18-6319/
[Online]. Available: https://aclanthology.org/W18-6319/
-
[40]
xCOMET: Transparent machine translation evaluation through fine-grained error detection,
N. M. Guerreiro, R. Rei, D. v. Stigt, L. Coheur, P. Colombo, and A. F. T. Martins, “xCOMET: Transparent machine translation evaluation through fine-grained error detection,” Transactions of the Association for Computational Linguistics, vol. 12, pp. 979–995, 2024. [Online]. Available: https: //aclanthology.org/2024.tacl-1.54/
2024
-
[41]
Joint speech and text machine translation for up to 100 languages,
L. Barrault, Y .-A. Chung, M. C. Meglioli, D. Dale, N. Dong, P.-A. Duquenne, H. Elsahar, H. Gong, K. Heffernan, J. Hoffman, C. Klaiber, P. Li, D. Licht, J. Maillard, A. Rakotoarison, K. R. Sadagopan, G. Wenzek, E. Ye, B. Akula, P.-J. Chen, N. El Hachem, B. Ellis, G. M. Gonzalez, J. Haaheim, P. Hansanti, R. Howes, B. Huang, M.-J. Hwang, H. Inaguma, S. Jain...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.